Conseguir que el servidor Couchbase funcione en tu PC o Mac implica unos sencillos pasos para descargar el software y poner en marcha un clúster con todos los servicios Couchbase que necesitas (https://docs.couchbase.com/server/6.0/getting-started/start-here.html). El software incluye cubos de muestras para que pueda empezar a utilizar el producto en cuestión de minutos.
Si necesita migrar su base de datos relacional a Couchbase, hay conectores disponibles (https://docs.couchbase.com/server/6.0/connectors/intro.html) que te permitiría alcanzar el objetivo. Sin embargo, si estás familiarizado tanto con RDBMS como con las herramientas de base de datos de Couchbase, podrías aprovechar tu herramienta de exportación de datos de base de datos, y luego utilizar Couchbase cbimport para cargar los datos en un bucket de Couchbase.
Con cualquiera de los dos métodos, tendrá que tomar algunas decisiones, debido a las diferencias entre las bases de datos:
- Tablas RDBMS frente a buckets Couchbase.
- Claves primarias de base de datos y claves de documento de bucket.
- Por último, pero no menos importante, cómo transformar tu esquema de base de datos relacional a una base de datos de documentos JSON de Couchbase.
En este blog, discutiré estas diferencias, y esbozaré las diferentes estrategias que podrías considerar para transformar el esquema de tu base de datos relacional a la base de datos NoSQL de Couchbase. Mientras que la técnica de migración se puede generalizar para muchos RDBMS, el proceso real de consulta de la base de datos de origen aprovecha sus API REST específicas. Por esta razón, usaré Oracle y su esquema de ejemplo de RRHH como datos de origen, y aprovecharé sus Servicios de Datos REST para la extracción de datos.
Qué herramientas necesita
Las técnicas de migración de este blog aprovechan los servicios básicos de la base de datos Oracle y el lenguaje de consulta N1QL de Couchbase. No necesitas nada más.
Cómo utilizar estas técnicas de migración
Los scripts N1QL proporcionados abordan las dos primeras cuestiones de tipo de documento y clave de documento. Para la transformación del esquema relacional a la base de datos JSON de Couchbase, los scripts cubren estos tres escenarios:
- Asignación directa de tabla a tipo de documento. No interviene ninguna transformación.
- Desnormalización del objeto padre en objeto hijo.
- Desnormalización de objetos hijos en el padre como un campo de matriz.
Los escenarios anteriores, con las soluciones de tipo de documento y clave de documento, deberían cubrir la mayoría de los casos de uso para transformar un esquema relacional en una base de datos de documentos JSON.
Requisitos previos
- Acceso a un servidor de base de datos Oracle con el esquema de ejemplo HR.
- Acceso a una base de datos Couchbase, donde deberá crear un bucket cbhr como destino para la migración del esquema Oracle HR.
Los pasos
- Habilite su esquema Oracle para el acceso a Servicios de datos REST.
- Configure un servidor Couchbase y configure el bucket para recibir los datos de Oracle HR.
- Decida las técnicas de transformación del modelo de datos para su requisito de migración.
- Edite y ejecute el script N1QL para migrar los datos.
Base de datos Oracle con el esquema HR
El esquema Oracle HR está disponible en su instalación Oracle. Siga la documentación de Oracle para desplegar el esquema. https://docs.oracle.com/cd/E11882_01/server.112/e10831/installation.htm#COMSC001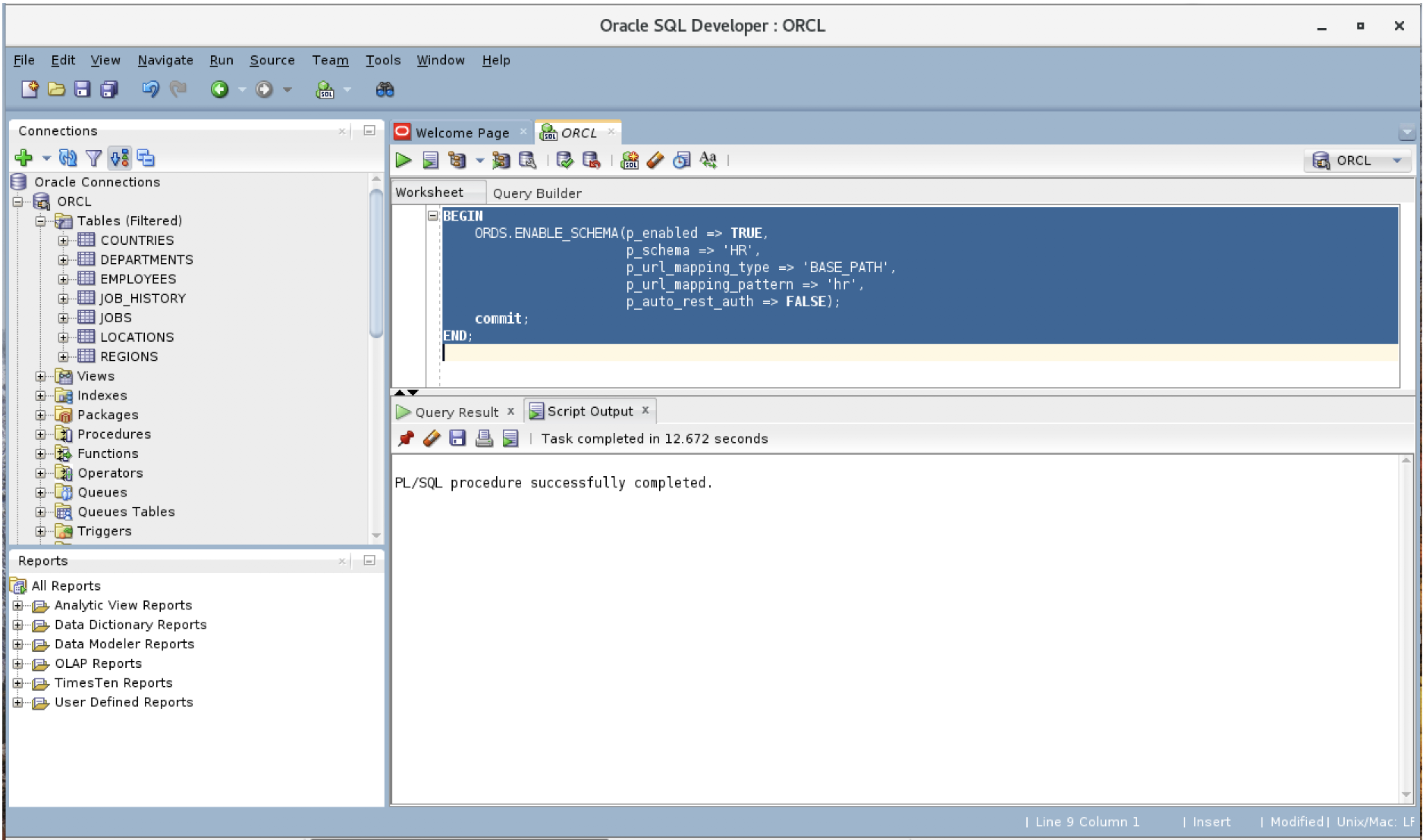
Habilitar esquema Oracle para servicios REST
Por defecto, el servicio de datos Oracle REST no está habilitado en el esquema. Deberá habilitarlo para el esquema HR.
Inicie sesión como el usuario que realizará las llamadas REST. En este ejemplo, inicie sesión como hry ejecute el siguiente script.
|
1 2 3 4 5 6 7 8 |
BEGIN ORDS.ENABLE_SCHEMA( p_enabled => TRUE , p_schema => 'HR' , p_url_mapping_type => 'BASE_PATH' , p_url_mapping_pattern => 'hr' , p_auto_rest_auth => FALSE); commit; END; |
Referencia: https://blogs.oracle.com/oraclemagazine/get-your-rest-post-your-sql
Compruebe que puede consultar su Oracle con una llamada REST. https://:8080/ords/hrrest/employees/
Nota: de forma predeterminada, el servicio Oracle REST Enabled SQL está desactivado. Para configurar los ajustes del servicio REST Enabled SQL, consulte Configuración de los ajustes del servicio SQL habilitado para REST.
Prepare su servidor Couchbase
Hay dos pasos que debe completar en la configuración del servidor Couchbase.
- Crear un cubo con el nombre
cbhr. El tamaño del cubo dependerá del volumen de los datos que tenga previsto migrar. - Asegúrese de habilitar el acceso a la función CURL() en la configuración de Couchbase Server.

3. También tendrá que crear un índice primario en el archivo cbhr para permitir que N1QL consulte el bucket como parte de la migración.
|
1 |
CREATE PRIMARY INDEX `#primary` ON `cbhr` |
Transformación del modelo de datos
La migración de Relational a NoSQL es un gran paso, y este blog no cubre los pros y los contras de cada una de estas bases de datos. Sin embargo, debido a las diferencias en la forma en que se almacenan los datos, tendrá que tomar una decisión sobre cómo desea gestionar estos cambios. Los scripts N1QL de este blog transformarán el esquema de Oracle HR en el siguiente modelo de datos JSON de Couchbase, utilizando las siguientes estrategias:
- Regiones, Países, Localidades son entidades padre directas e indirectas de los Departamentos. Así que podríamos desnormalizar el padre/abuelo/tatarabuelo en la entidad Departamento. Esto reducirá la necesidad de JOINs cuando se necesite esta información en la consulta. Además, otras entidades asociadas como Employees y Job_History sólo tienen una referencia al department_id. Por esta razón, tendría sentido desnormalizar la información sobre la región, el país y la ubicación de un departamento en el objeto 'department' del modelo JSON de Couchbase.
- La entidad Empleos incluye la información sobre la escala salarial. Podría tratarse de datos sensibles. Por esta razón, utilizaremos una migración directa de este objeto sin ninguna transformación.
- La entidad Empleados incluye otra información asociada, como job_id y department_id, que son atributos importantes para un empleado. Tendría sentido desnormalizar el Título del puesto y el Nombre del departamento en el objeto 'empleado'.
- La entidad Job_History es en realidad un objeto hijo de la entidad Employees. Por lo tanto, tendría sentido incluir el historial laboral del empleado en el objeto 'empleado'.
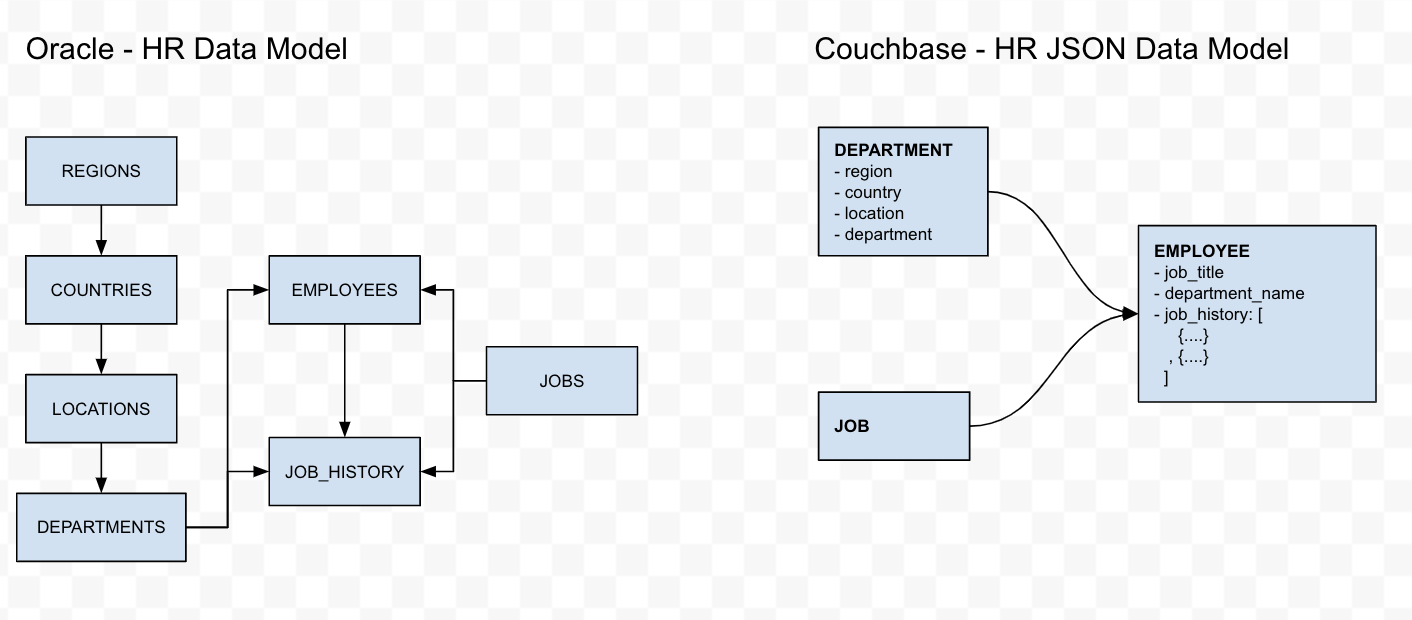
Tabla vs. Tipo de documento
En Couchbase no se aplica el concepto de tabla. Todos los documentos pueden ser almacenados en un único bucket con el uso de un tipo para diferenciar el tipo de documento. Esto es posible porque no hay restricciones de esquema entre diferentes documentos en la base de datos NoSQL de Couchbase.
El script incluido se encarga de esto incluyendo un tipo_doc con el valor del nombre de la tabla de origen.
|
1 |
SELECT 'employee' doc_type ... FROM hr.employees... |
Asignación de claves primarias
Una tabla Oracle normalmente tendría una clave primaria, y puedes verlo en el esquema HR. Los documentos de Couchbase también necesitan una clave primaria. Sin embargo, como todos los datos de la tabla Oracle residirán en un único bucket de Couchbase, necesitamos una forma de diferenciar entre los valores clave de estos tipos de documentos en Couchbase.
La secuencia de comandos incluida se encarga de esto mediante la construcción del archivo doc_key utilizando el nombre de la tabla Oracle HR y su valor de clave primaria.
|
1 |
SELECT 'employee:' ||e.employee_id doc_key FROM hr.employees ... |
Documento JSON de Relational a Couchbase
No hay una regla rígida y rápida sobre cómo debe transformar su esquema relacional a NoSQL. Podrías migrar todas las tablas a un bucket de Couchbase, cada una con su propia tipo_doc campo.
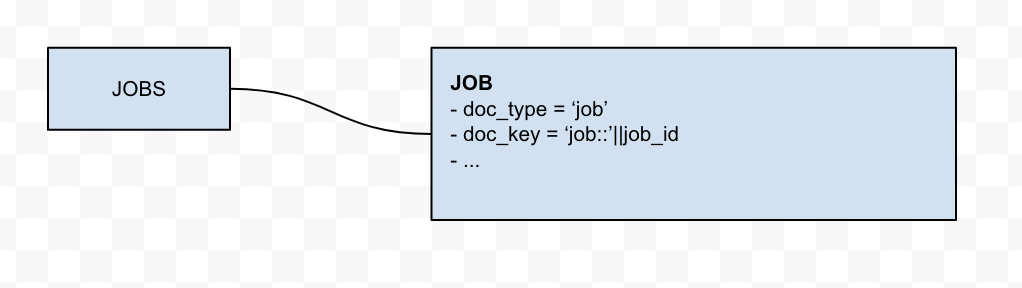
Tabla directa al documento
Este es el caso más sencillo, en el que sólo el tipo_doc y doc_key se añaden al documento Couchbase. El objeto relacional no requiere ninguna transformación durante el proceso de migración.
|
1 2 3 4 5 6 7 8 9 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("https://<your_server_ip>:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'job' doc_type, 'job:'||j.job_id doc_key, j.* FROM jobs j" , "user":'HR:oracle'} ) r UNNEST r.items[0].resultSet.items as ndoc |
Notas:
- UPSERT se utiliza para que la consulta se pueda volver a ejecutar sin afectar al resultado en el bucket de Couchbase.
- El comando N1QL CURL llama a un endpoint REST en Oracle Rest Data Services, con una consulta que será procesada por el servidor Oracle.
- El CURL N1QL devuelve un documento JSON con el resultado de la consulta en el campo array r.items[0].resultSet.items.
- La consulta N1QL utiliza el comando UNNEST para aplanar el archivo r.items[0].resultSet.items devolviendo cada registro de Oracle como un documento JSON independiente.
- N1QL UPSERT inserta cada documento en Couchbase cbhr cubo.
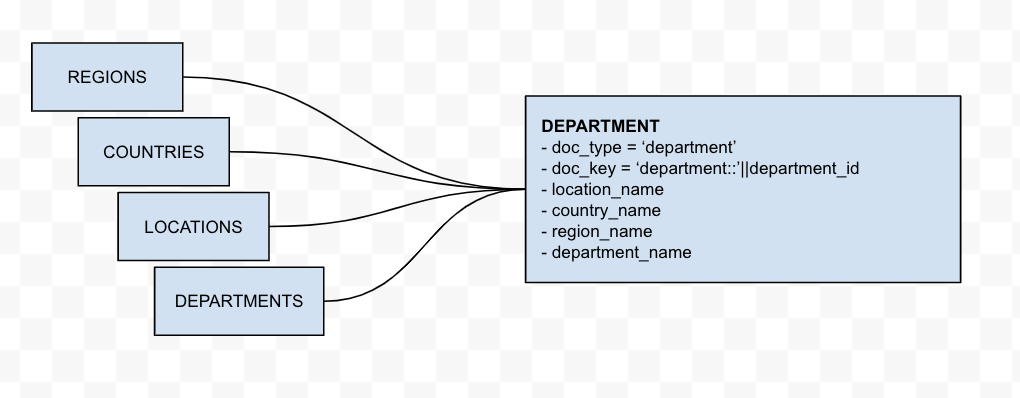
Desnormalización
Esta transformación combina varias tablas de Oracle en un único objeto. En este ejemplo, las tablas Regiones, Países y Ubicaciones tienen una relación directa padre-hijo, lo que permite añadir los campos padre al objeto hijo. El resultado final es un único objeto Departamento que incluye su ubicación, país y región. Esta transformación es un proceso de un solo paso.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
UPSERT INTO cbhr (KEY doc_key, VALUE ndoc) SELECT ndoc.doc_key , ndoc FROM CURL( "<your_database_server_ip>:8080/ords/hr/_/sql" , { "request":"POST","header":"Content-Type: application/sql" , "data": "SELECT 'department' doc_type, 'department:' ||d.department_id doc_key, d.department_id, d.department_name, d.manager_id , l.* , c.country_name, r.* FROM departments d INNER JOIN locations l ON d.location_id=l.location_id INNER JOIN countries c ON l.country_id = c.country_id INNER JOIN REGIONS r ON c.region_id = r.region_id" ,"user":'HR:oracle'} ) res UNNEST res.items[0].resultSet.items as ndoc |
Notas:
- UPSERT se utiliza para que la consulta se pueda volver a ejecutar sin afectar al resultado en el bucket de Couchbase.
- El comando N1QL CURL llama a un endpoint REST en Oracle Rest Data Services, con una consulta que será procesada por el servidor Oracle.
- El CURL N1QL devuelve un documento JSON con el resultado de la consulta en el campo array r.items[0].resultSet.items.
- La consulta N1QL utiliza el comando UNNEST para aplanar el archivo r.items[0].resultSet.items devolviendo cada registro de Oracle como un documento JSON independiente.
- N1QL UPSERT inserta cada documento en Couchbase cbhr cubo.
Desnormalización - Añadir registros hijos como un campo de matriz al objeto padre
Una de las características clave de una base de datos NoSQL es el uso de arrays. La base de datos NoSQL de Couchbase almacena documentos en formato JSON, en el que un campo puede ser un array. Para este ejercicio, añadiremos la tabla JOB_HISTORY a la tabla EMPLOYEES. Esto añade una nueva tabla historial_trabajo al documento EMPLEADO.
Esta transformación es una proceso en dos etapas. El primer paso consiste en migrar los datos de los empleados. El segundo paso fusiona los empleado que ya están en Couchbase cbhr con la consulta Oracle de historial_trabajo.
El documento principal
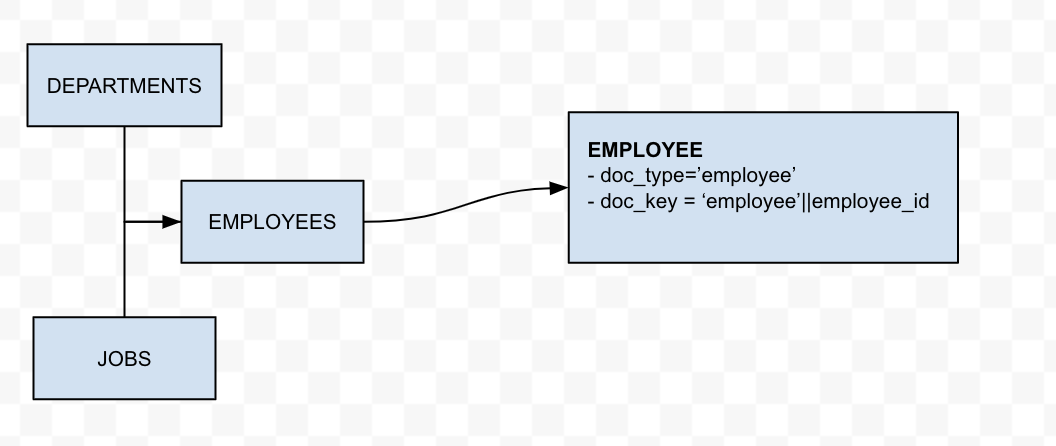
|
1 2 3 4 5 6 7 8 9 10 11 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("https://192.168.1.117:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'employee' doc_type, 'employee:' ||e.employee_id doc_key, e.* , j.job_title, d.department_name FROM employees e INNER JOIN jobs j ON e.job_id = j.job_id INNER JOIN departments d ON e.department_id = d.department_id" , "user":'HR:oracle' }) r UNNEST r.items[0].resultSet.items as ndoc |
Los registros hijos como campo de matriz en el documento padre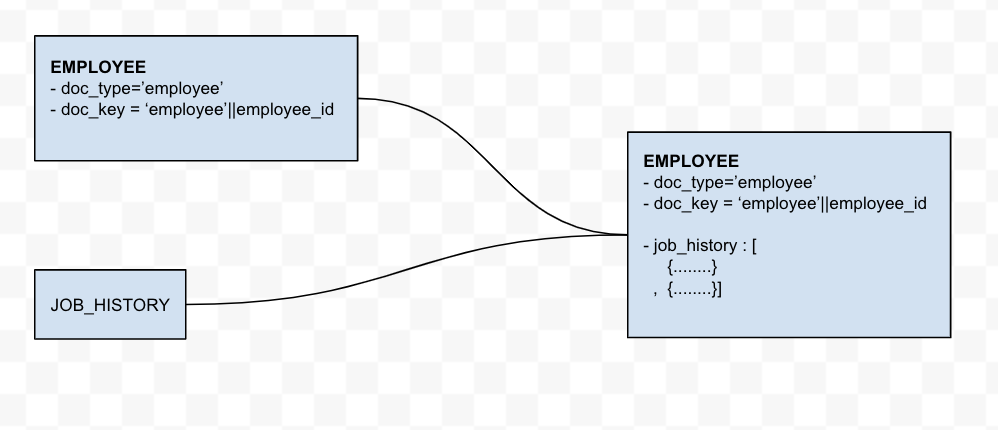
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MERGE INTO cbhr e USING ( SELECT ndoc.employee_id, ARRAY_AGG(ndoc) all_jobs FROM CURL( "https://<your_database_server>:8080/ords/hr/_/sql" , {"request":"POST","header":"Content-Type: application/sql" , "data": "SELECT h.employee_id, h.start_date,h.end_date, h.job_id, j.job_title, h.department_id FROM job_history h INNER JOIN jobs j ON h.job_id=j.job_id" , "user":'HR:oracle' } ) res UNNEST res.items[0].resultSet.items as ndoc GROUP BY ndoc.employee_id ) source ON KEY 'employee:'||to_string(source.employee_id) WHEN MATCHED THEN UPDATE SET e.job_history = source.all_jobs |
Notas:
- La consulta N1QL utiliza el comando MERGE para combinar los documentos de la base de datos cbhr cubo cuyo tipo_doc es empleado con el resultado del SELECT de la lectura CURL REST de Oracle historial_trabajo.
- La consulta utiliza el ARRAY_AGG de N1QL para agrupar todos los trabajos por empleado_id.
- El MERGE utiliza empleado:'||to_string(source.employee_id) como clave para emparejar los dos conjuntos de resultados.
Limitaciones
Tenga en cuenta que existe una limitación en cuanto a la cantidad de datos que N1QL CURL() puede recuperar. Actualmente el tamaño máximo está fijado en 64MB, que no puede ser modificado. Esto no es mucho si planeas migrar grandes tablas de Oracle. Dicho esto, Oracle tiene soporte para OFFSET y FETCH NEXT, lo que le permitiría dividir el proceso de migración en trozos más pequeños.
Además, la razón principal de este blog es destacar lo que hay que tener en cuenta a la hora de migrar un esquema relacional a una base de datos de documentos JSON de Couchbase, y cómo N1QL puede ayudar a transformar tu esquema relacional directamente en el proceso de migración.
Si tiene alguna pregunta o comentario, envíeme un mensaje a continuación.
Hola Binh , Esto es bueno y muy útil, pero conociendo las limitaciones de CURL en el dimensionamiento me interesaría saber cómo manejar gran volumen de tarea de migración de datos como carga por lotes de Oracle a Couchbase cuando 10 uniones diferentes existen en el modelo OLAP. Por favor, ayúdenme a compartir sus ideas al respecto. Tratando de replicar el proceso de uso de Oracle ORDS pero con OFFSET y FETCH no estoy seguro de cómo manejar esto.
gracias
Debashis,
Gracias por tu interés en el blog. Para aprovechar la cláusula "OFFSET and FETCH {FIRST |NEXT} .." de Oracle, deberías usar un lenguaje de scripting, por ejemplo Python y el SDK de Couchbase. Aquí iterarás a través del conjunto de registros de Oracle. Por favor, consulta este post del foro https://www.couchbase.com/forums/t/oracle-to-couchbase/22044 para obtener sugerencias sobre cómo conseguirlo mediante programación.
Gracias,
-binh