Tanto si eres nuevo en Couchbase o veterano, es probable que haya oído hablar de los ámbitos de aplicación y las colecciones. Si estás listo para probarlos por ti mismo, este artículo te ayudará a hacerlo realidad.
Los ámbitos y las colecciones son una nueva función introducida en la versión 7.0 de Couchbase Server que te permite organizar lógicamente los datos dentro de Couchbase. Para saber más, lea la siguiente introducción a Ámbitos y colecciones.
Deberías aprovechar Scopes y Collections si quieres mapear tu RDBMS heredado a una base de datos de documentos o si estás intentando consolidar cientos de microservicios y/o tenants en un único Couchbase (lo que se traduce en un coste total de propiedad mucho menor).
En este artículo repasaré cómo puedes planificar tu migración desde una versión anterior de Couchbase al uso de Scopes y Collections en Couchbase 7.0.
Pasos de migración de alto nivel
Los siguientes son los pasos de alto nivel para migrar a Scopes y Collections en Couchbase 7.0.
No todos los pasos son esenciales: todo depende de tu caso de uso y de tus requisitos tecnológicos particulares. En las secciones siguientes te explicaré en detalle cada uno de estos pasos.
- Actualización a Couchbase Server 7.0
- Planifique su estrategia de ámbitos y colecciones: Determine qué cubos, ámbitos, colecciones e índices necesita. Determine la correspondencia entre los antiguos cubos y los nuevos cubos/ámbitos/colecciones. Escribir scripts para crear ámbitos, colecciones e índices.
- Migre el código de su aplicación: Este código de aplicación es tu código SDK de Couchbase incluyendo consultas N1QL.
- Migración de datos: Determine si una estrategia fuera de línea funciona para su implantación o si necesita una migración en línea. Actúe en consecuencia.
- Planifique y aplique su estrategia de seguridad de bases de datos: Determine qué asignaciones de Usuarios y Funciones necesita. Cree scripts para gestionar estas asignaciones.
- Ponga en marcha su nueva aplicación Collections-aware
- Configurar XDCR y copia de seguridad de su base de datos Couchbase
Actualización a Couchbase 7
Esto es lo que debe saber sobre la actualización a Servidor Couchbase 7.0:
-
- Cada Cubo en 7.0+ tiene un
Por defectoAlcance con unPor defectoColección en él. - La actualización a Couchbase 7.0 mueve todos los datos del Bucket al archivo
Por defectoRecogida del cubo. - Hay sin impacto en las aplicaciones existentes. Por ejemplo, una referencia SDK 2.7 a Bucket
Bse resuelve automáticamente enB._por defecto(en referencia a laPor defectoÁmbito y Colección, respectivamente).
- Cada Cubo en 7.0+ tiene un
El siguiente diagrama ilustra cómo se organizan los datos en Buckets, Scopes y Collections después de migrar los datos de Couchbase 6 a Couchbase 7.
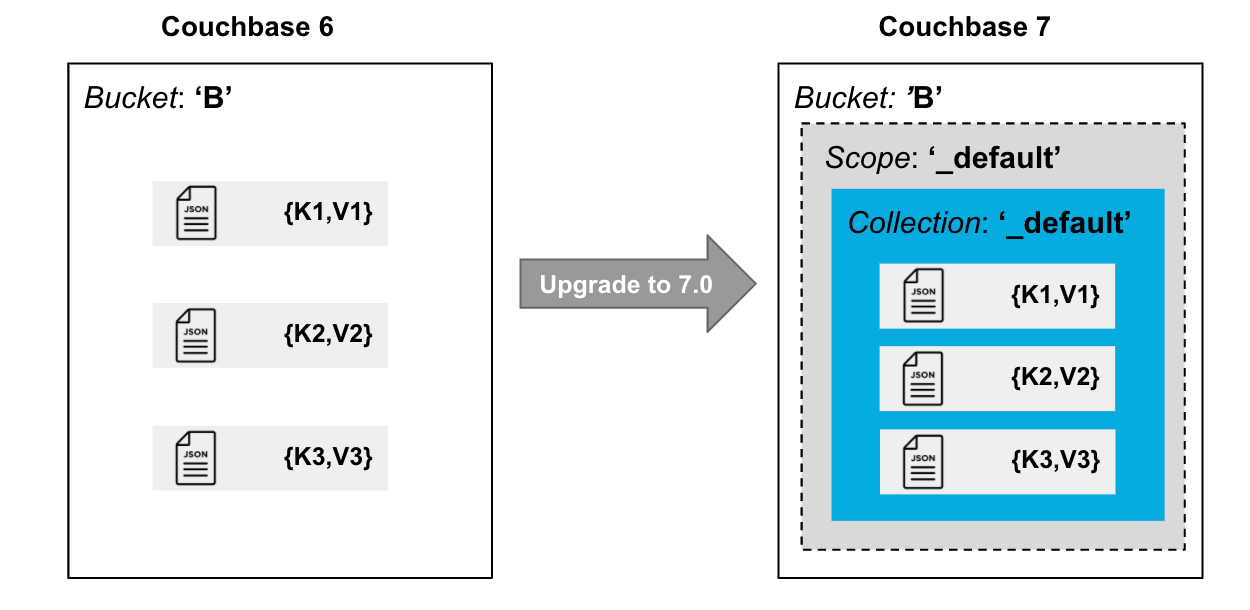
Si no desea utilizar ámbitos y colecciones con nombre, deténgase aquí.
Pero si estás listo para utilizar esta nueva función de organización de datos, sigue leyendo.
Planifique sus ámbitos y su estrategia de recogida
A continuación se presentan los escenarios de migración de bases de datos más comunes que me he encontrado. Su escenario de migración puede ser diferente y el kilometraje puede variar.
Consolidación: De múltiples cubos a colecciones en un solo cubo
Una situación habitual es cuando se intenta reducir el coste total de propiedad (TCO) consolidando varios buckets en uno solo.
Un clúster sólo puede tener hasta 30 Buckets, mientras que puedes tener 1000 Collections por clúster, lo que permite una densidad mucho mayor. Este es un escenario común para la consolidación de microservicios.
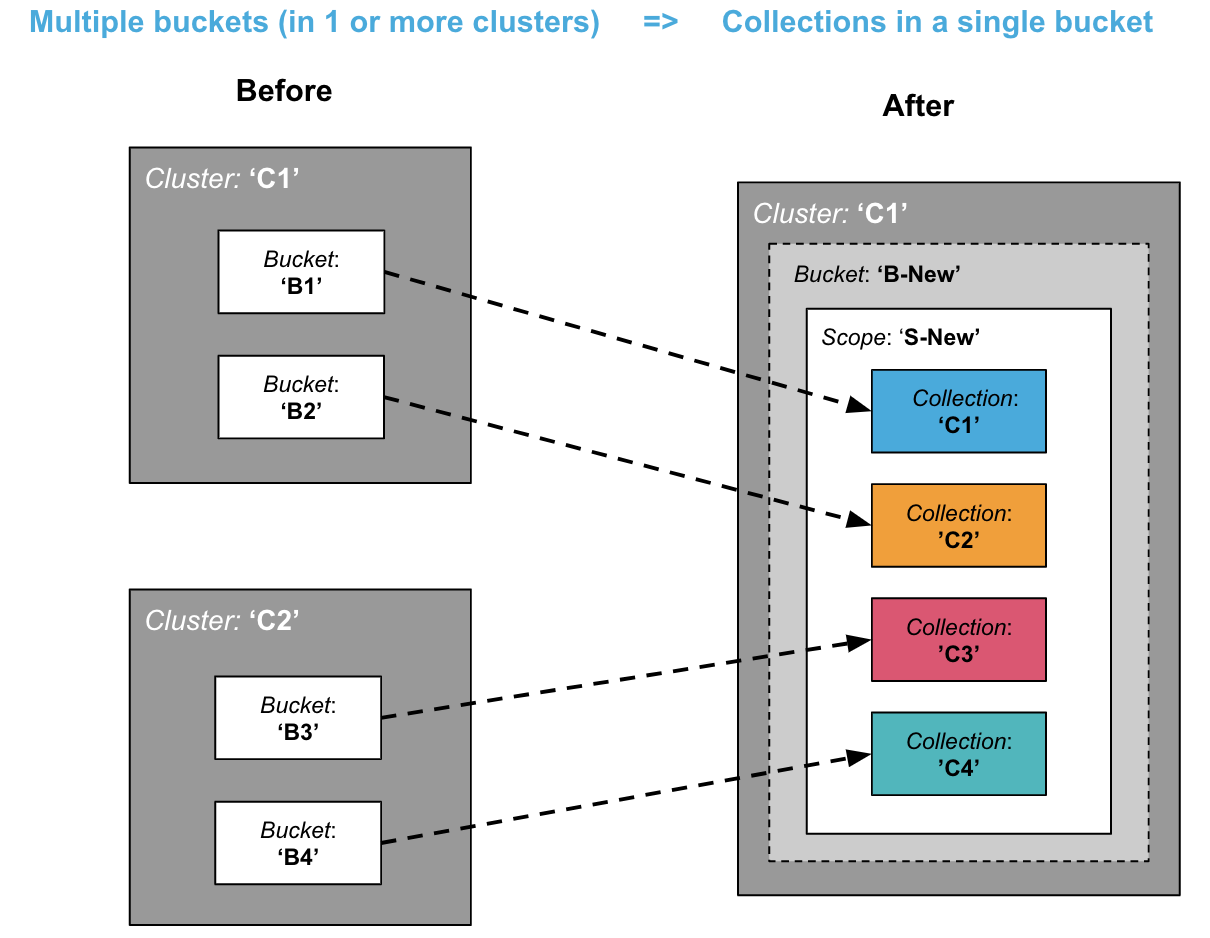
El diagrama anterior muestra todas las colecciones de destino pertenecientes al mismo ámbito. Sin embargo, las colecciones de destino podrían pertenecer a ámbitos diferentes.
División: De un cubo único a varias colecciones en un cubo
Otro escenario común es migrar los datos que residen dentro de un único Bucket y dividirlos en múltiples Colecciones (dentro del mismo Bucket).
Es posible que previamente haya calificado diferentes tipos de datos con un tipo = foo o con un prefijo clave como clave_foo. Ahora estos tipos de datos pueden vivir cada uno en su propia colección, lo que le ofrece las ventajas del aislamiento lógico, el aislamiento de seguridad, la replicación y el control de acceso.
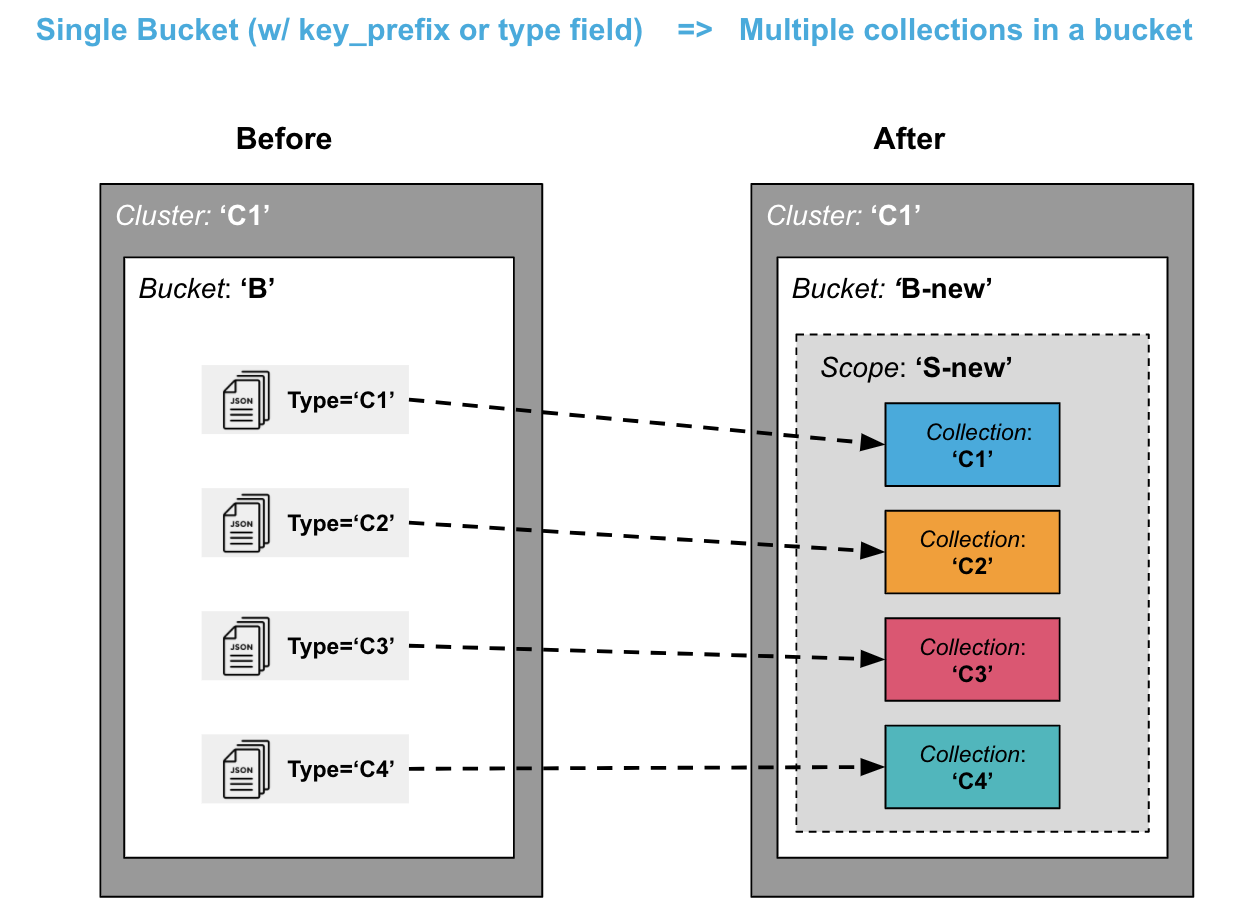
Este escenario puede ser un poco más complejo que el escenario de "consolidación" anterior, especialmente si desea deshacerse del prefijo de clave o del campo de tipo. Para una migración más sencilla, es posible que desee dejar los prefijos de clave y los campos de datos de tipo tal como están, aunque puedan ser algo redundantes con Colecciones.
Creación de ámbitos, colecciones e índices
Una vez que haya planificado qué Ámbitos, Colecciones e índices desea tener, necesita crear scripts para la creación de estas entidades. Puede utilizar el SDK de Couchbase de su elección, el couchbase-cli, las API REST directamente, o incluso scripts N1QL para hacerlo.
A continuación se muestra un ejemplo de uso de la CLI (couchbase-cli y cbq shell) para crear un Scope, una Collection y un índice.
|
1 2 3 4 5 6 7 8 |
// create a Scope called 'myscope' using couchbase-cli ./couchbase-cli collection-manage -c localhost -u Administrator -p password --bucket testBucket --create-scope myscope // create a Collection called mycollection in myscope ./couchbase-cli collection-manage -c localhost -u Administrator -p password --bucket testBucket --create-collection myscope.mycollection // create an index on mycollection using cbq ./cbq --engine=localhost:8093 -u Administrator -p password --script="create index myidx1 on testBucket.myscope.mycollection(field1,field2);" |
Tenga en cuenta que el creación de índices La declaración no requieren que se califiquen los datos con un tipo = foo o cláusula de cualificación de prefijo de clave.
Migrar el código de su aplicación
Para utilizar Ámbitos y Colecciones con nombre, el código de su aplicación (incluyendo Consultas N1QL).
Si anteriormente utilizaba campos de tipo o prefijos de clave (como en el caso de la división), deberá no ya no los necesitan.
Ejemplo de código SDK
En su código SDK, tiene que conectarse a un clúster, abrir un Bucket y obtener una referencia a un objeto Collection para almacenar y recuperar documentos. Antes de Collections, todas las operaciones clave-valor se realizaban directamente en el Bucket.
Nota: Si has migrado a Couchbase SDK 3.0, ya has hecho parte del trabajo de empezar a usar Colecciones (aunque hasta ahora sólo podías usar la Colección por defecto).
A continuación se presenta una sencilla SDK de Java fragmento de código para almacenar y recuperar un documento en una colección:
|
1 2 3 4 5 6 7 8 9 10 |
Cluster cluster = Cluster.connect("127.0.0.1", "Administrator", "password"); Bucket bucket = cluster.bucket("bucket-name"); Scope scope = bucket.scope("scope-name"); Collection collection = scope.collection("collection-name"); JsonObject content = JsonObject.create().put("author", "mike"); MutationResult result = collection.upsert("document-key", content); GetResult getResult = collection.get("document-key"); |
Consultas N1QL
Ahora bien, si desea ejecutar una consulta N1QL en la colección del ejemplo Java anterior, haga lo siguiente:
|
1 2 3 |
//run a N1QL using the context of the Scope scope.query("select * from collection-name"); |
Observe que puede realizar consultas directamente en un Scope. La consulta anterior sobre el objeto Scope se asigna automáticamente a select * from nombre-cubo.nombre-ámbito.nombre-colección.
Otra forma de proporcionar contexto de ruta a N1QL es establecerlo en Opciones de consulta. Por ejemplo:
|
1 2 |
QueryOptions qo = QueryOptions.queryOptions().raw("query_context", "bucket-name.scope-name"); cluster.query("select * from collection-name", qo); |
Un ámbito puede tener varias colecciones, y puede unirlas directamente haciendo referencia al nombre de la colección dentro del ámbito. Si necesita realizar una consulta entre ámbitos (o entre cubos), es mejor utilizar el objeto clúster para realizar la consulta.
Tenga en cuenta que las consultas N1QL ya no necesitan calificar un tipo = foo (o prefijo_clave calificador), si procede.
Por ejemplo, esta antigua consulta N1QL...
|
1 2 3 4 5 6 |
SELECT r.destinationairport FROM Travel a JOIN Travel r ON a.faa = r.sourceairport AND r.type = "route" WHERE a.city = "Toulouse" AND a.type = "airport"; |
...ahora se convierte:
|
1 2 3 4 |
SELECT r.destinationairport FROM Airport a JOIN Route r ON a.faa = r.sourceairport WHERE a.city = "Toulouse"; |
Migración de datos a colecciones
A continuación, debe migrar los datos existentes a los nuevos ámbitos y colecciones.
Lo primero que tiene que determinar es si puede permitirse hacer una migración offline (en la que su aplicación está fuera de línea durante unas horas), o si necesita hacer una migración mayoritariamente online con un tiempo mínimo de inactividad de la aplicación.
Una migración fuera de línea podría ser más rápida en general y requerir menos recursos adicionales en términos de espacio en disco o nodos adicionales.
Migración fuera de línea
Si decide realizar la migración sin conexión, puede utilizar N1QL o Backup/Restore. Vamos a ver más detenidamente ambas opciones.
Uso de N1QL para una migración sin conexión
Requisito previo: El clúster debe disponer de espacio libre en disco y utilizar el servicio de consulta.
Siguiendo este planteamiento, su migración sería algo parecido a lo siguiente:
- Crear nuevos ámbitos, colecciones e índices.
- Desconecte la aplicación antigua.
- Para cada Colección nombrada:
- Insertar-Seleccionar de
Por defectoColección a Colección con nombre (utilizando los filtros adecuados). - Borrar datos de
Por defectoColección que se migró en el paso anterior (para ahorrar espacio; o si el espacio no es un problema, puede hacerlo al final).
- Insertar-Seleccionar de
- Verifique los datos migrados.
- Tirar cubos viejos.
- En línea su nueva solicitud.
Utilizar la copia de seguridad/restauración para una migración sin conexión
Requisito previo: Necesitas espacio en disco para almacenar los archivos de copia de seguridad.
Con este enfoque, tu migración tendría este aspecto:
- Crear nuevos ámbitos, colecciones e índices
- Desconectar la aplicación
- Haga copias de seguridad (
cbbackupmgr) de 7,0 cluster - Restauración mediante asignación explícita a colecciones con nombre. Utilice
--claves de filtroy--map-data(véanse los ejemplos 1 y 2). - En línea su nueva solicitud.
Ejemplo 1: Sin filtrado durante la restauración
Este ejemplo desplaza todo el Por defecto a una colección con nombre. (Este es el caso probable para el escenario de consolidación).
|
1 2 3 4 5 6 7 8 |
// Backup the default Scope of a Bucket upgraded to 7.0 cbbackupmgr config -a backup -r test-01 --include-data beer-sample._default cbbackupmgr backup -a backup -r test-01 -c localhost -u Administrator -p password // Restore above backup to a named Collection cbbackupmgr restore -a backup -r test-01 -c localhost -u Administrator -p password --map-data beer-sample._default._default=beer-sample.beer-service.service_01 |
Ejemplo 2: Restauración con filtrado
Este ejemplo desplaza partes de Por defecto a colecciones con nombres diferentes (este es el caso más probable para el escenario de división).
|
1 2 3 4 5 6 7 8 9 10 |
// Backup the travel-sample Bucket from a cluster upgraded to 7.0 cbbackupmgr config -a backup -r test-02 --include-data travel-sample cbbackupmgr backup -a backup -r test-02 -c localhost -u Administrator -p password // Restore type=’airport’ documents to a Collection travel.booking.airport cbbackupmgr restore -a backup -r test-02 -c localhost -u Administrator -p password --map-data travel-sample._default._default=travel.booking.airport --auto-create-buckets --filter-values '"type":"airport"' // Restore key_prefix =’airport’ documents to a Collection travel.booking.airport cbbackupmgr restore -a backup -r test-02 -c localhost -u Administrator -p password --map-data travel-sample._default._default=travel.booking.airport --auto-create-buckets --filter-keys airport_* |
Migración en línea con XDCR
Para realizar una migración principalmente en línea, es necesario utilizar la replicación entre centros de datos (XDCR).
Dependiendo de la capacidad disponible en el clúster existente, puede hacer autoXDCR (donde el origen y el destino Bucket están en el mismo clúster), o puede configurar un clúster independiente para replicar a.
Estos son los pasos que debes seguir:
- Configure XDCR desde su clúster de origen a su clúster de destino (puede hacer autoXDCR si dispone de espacio en disco y recursos informáticos de sobra en el clúster original).
- Crear nuevos Cubos, Ámbitos y Colecciones.
- Establecer réplicas directamente de un Cubo a un
bucket.scope.collectiono utilizando el modo de migración (más abajo se muestran los detalles) si la colección predeterminada de un solo cubo debe dividirse en varias colecciones. - Se pueden especificar reglas de asignación explícitas para cada destino con el fin de especificar subconjuntos de datos.
- Una vez que los destinos de replicación estén al día, desconecte su antigua aplicación.
- Conecte su nueva aplicación dirigiéndola al nuevo cluster (o al nuevo Bucket si utiliza self-XDCR).
- Elimine su antiguo cluster (o su antiguo Bucket si utiliza self-XDCR).
Uso de XDCR para migrar de varios cubos a uno solo
Estos pasos son para el escenario de consolidación.
La configuración XDCR será algo parecido a lo siguiente:
-
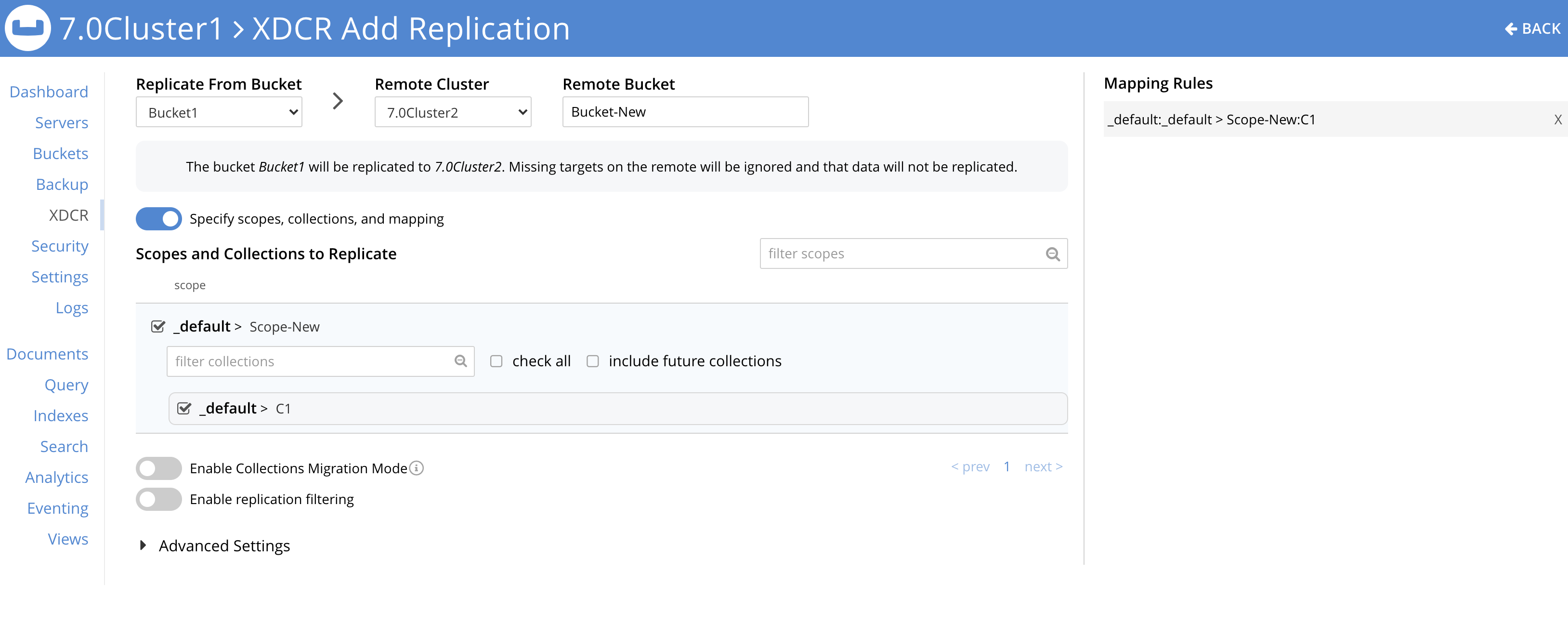
- Para cada Bucket de origen, configure una replicación a la Colección nombrada en el Bucket de destino y Alcance
La siguiente captura de pantalla muestra la configuración XDCR para una fuente Bucket:
Uso de XDCR para dividir varias colecciones en un mismo cubo
Estos pasos son para el escenario de división.
Para asignar la fuente Por defecto a varias colecciones de destino, debe utilizar el modo de migración proporcionado por XDCR.
Las pantallas XDCR que aparecen a continuación muestran el Modo Migración que se está utilizando:
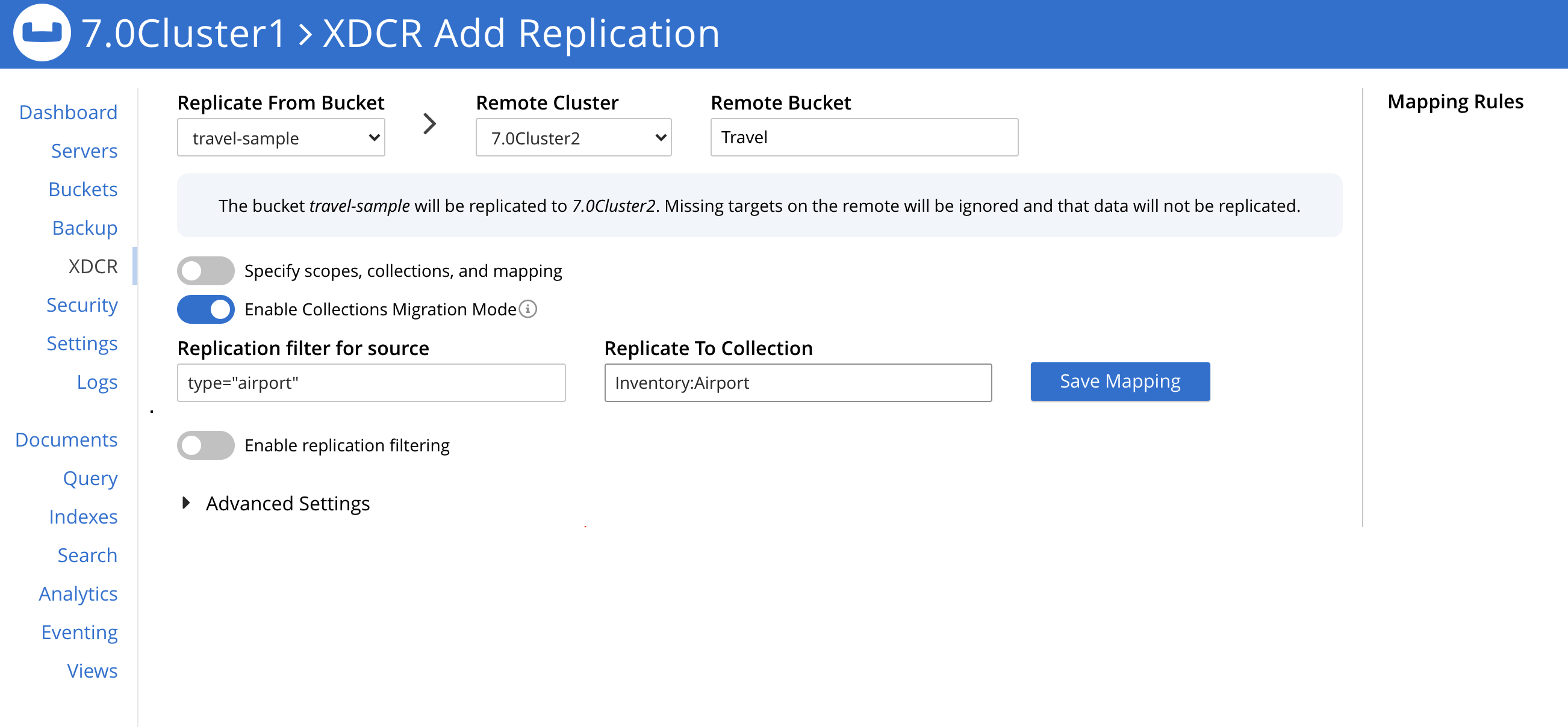
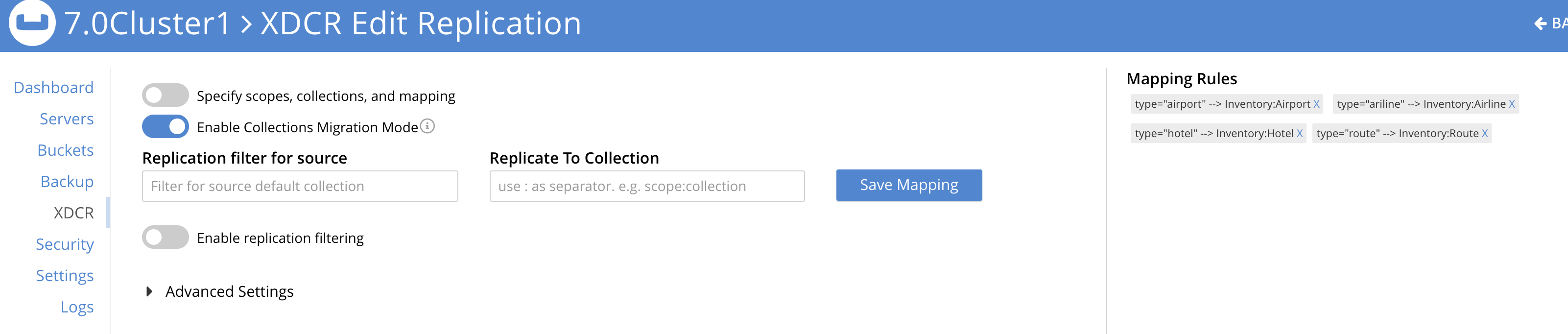
Hay cuatro filtros que debe configurar: (Viaje-muestra._por-defecto._por-defecto es la fuente. Se crea un nuevo cubo llamado Viajar es el objetivo).
-
- filtro
type="aeropuerto"replicar aInventario:Aeropuerto - filtro
type="compañía aérea"replicar aInventario:Aerolínea - filtro
type="hotel"replicar aInventario:Hotel - filtro
type="ruta"replicar aInventario:Ruta
- filtro
Planifique y aplique su estrategia de seguridad de bases de datos
Ahora que tiene todos sus datos en ámbitos y colecciones con nombre, tiene un control más preciso sobre los datos a los que puede asignar privilegios. Antes sólo podías hacerlo a nivel de Bucket.
Para obtener más información sobre la seguridad del control de acceso basado en funciones (RBAC) para ámbitos y colecciones, lea este artículo: Introducción a la seguridad RBAC para colecciones o consulte el documentación sobre RBAC.
Los siguientes roles están disponibles a nivel de Scope y Collection en Couchbase 7.
Funciones administrativas:
-
- La función Administrador de ámbito está disponible a nivel de ámbito. Un administrador de ámbito puede administrar las colecciones de su ámbito.
Funciones del lector de datos:
-
- Lector de datos
- Redactor de datos
- Lector DCP de datos
- Supervisión de datos
Funciones de consulta:
-
- Buscador FTS
- Seleccionar consulta
- Actualización de consultas
- Insertar consulta
- Consulta Borrar
- Consulta Gestionar índice
- Funciones de gestión de consultas
- Funciones de ejecución de consultas
Conclusión
Espero que esta guía te ayude a migrar con éxito a Scopes y Collections en Couchbase 7.
Para más información sobre la versión 7.0, consulte la documentación sobre Novedades o leer las notas de la versión.
¿Qué opina de la nueva función Ámbitos y colecciones? Espero sus comentarios sobre los foros de Couchbase.
Descubra Couchbase 7 hoy mismo
@Shivani, ¿es posible configurar el ámbito y las colecciones que se van a sincronizar en la pasarela de sincronización? Me gustaría restringir los documentos sincronizados sólo de un ámbito/colección en particular.
La compatibilidad con Sync Gateway llegará más adelante. Así pues, con la versión 7.0 también podrá recibir documentos de la colección predeterminada mediante Sync Gateway.
Perdón por el error. Me refería a que con la versión 7.0 sólo se pueden recibir documentos de la colección predeterminada mediante Sync Gateway.
He planeado categorizar una aplicación multi-tenant usando ámbitos y colecciones. Me hubiera gustado que sync gateway permitiera la sincronización basada en colecciones o ámbitos. ¿Para cuándo está prevista la compatibilidad con Sync Gateway?
Un par de preguntas más
1. ¿Puede un mismo documento formar parte de una colección por defecto y de otra personalizada?
2. ¿Pueden varios ámbitos referirse a la colección por defecto?
El plazo de compatibilidad con Sync Gateway está por determinar.
1) El "mismo" documento en dos colecciones diferentes (por defecto y personalizada, o dos personalizadas diferentes) es esencialmente dos documentos diferentes. Si se pregunta si la misma clave de documento puede utilizarse en dos colecciones diferentes, la respuesta es Sí.
2) No entiendo esta pregunta. La colección por defecto sólo existe en el ámbito por defecto. Ningún otro ámbito tiene una colección por defecto. Como usuario no puedes crear una colección por defecto (sólo la crea Couchbase).
@Shivani, ¿hay alguna actualización sobre la disponibilidad de la compatibilidad con scope&collection en Sync Gateway?
Como usuario @GaneshN, estamos diseñando una aplicación multi-tenant usando Couchbase server 7.0 y necesitamos implementar la sincronización de clientes basada en esa característica.
GaneshN post es casi 1 año de edad, realmente espero en buenas noticias.