Seguro que ya lo ha oído antes: "Lo que se mide, se hace".
Es cierto: lo que observas y mides es lo que puedes mejorar.
La clave de cualquier mejora es identificar primero qué para medir y, a continuación, recopilar las métricas relacionadas. Con esas métricas puede ajustar el trabajo subyacente y analizar la eficacia de los cambios. A continuación, repite el ciclo hasta que hayas mejorado lo suficiente.
En Couchbase, necesitábamos mejorar algunas de nuestras operaciones diarias, así que creamos paneles de observabilidad para ayudarnos a identificar problemas y realizar un seguimiento de las mejoras. Utilizamos una combinación de Prometeoque simplifica el almacenamiento y la consulta de datos de series temporales, y Grafanacon el que se pueden crear impresionantes visualizaciones de datos. Además, utilizamos Couchbase para almacenar datos históricos para su uso posterior con su Búsqueda de texto completo y Analítica herramientas.
En este artículo, te mostraremos cómo crear tu propio panel de control de observabilidad utilizando Prometheus, Grafana y Couchbase.
Sus canales de fuentes de datos internos pueden variar, al igual que su software de visualización de datos. Sin embargo, los pasos que te mostraremos hoy deberían ser aplicables a varias herramientas e implementaciones.
Cuadro de mando genérico de observabilidad: Diseño y arquitectura
Para construir una herramienta reutilizable y escalable, es mejor trabajar a partir de diseños y plantillas comunes como primer paso. A partir de ahí, se puede personalizar según sea necesario. Con este enfoque, es rápido y fácil desarrollar futuros cuadros de mando.
El siguiente diagrama muestra la arquitectura genérica de los cuadros de mando de observabilidad que construiremos juntos:
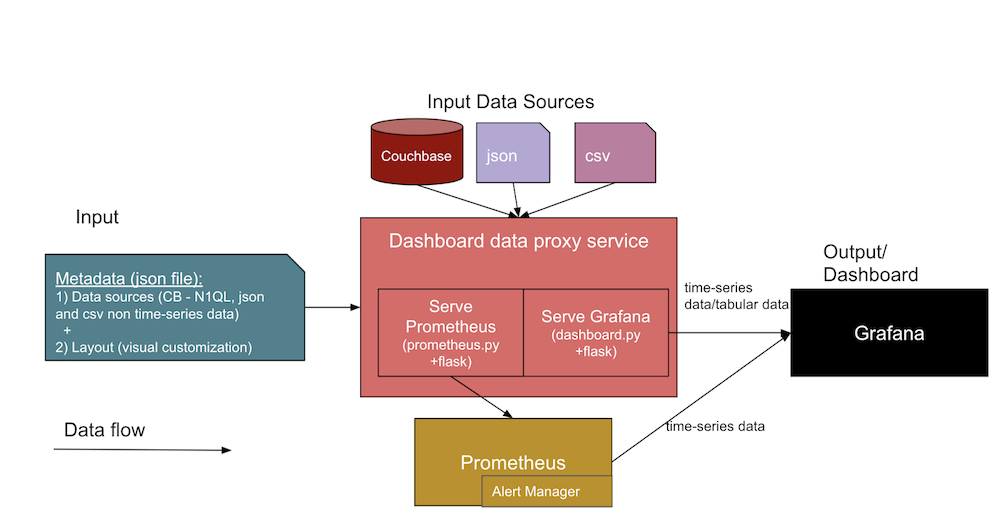
En esta arquitectura, dos entradas de datos diferentes forman una interfaz con el servicio de cuadro de mando. Veámoslas en detalle a continuación.
- Metadatos JSON sobre el cuadro de mandos
- Definiciones de fuentes de datos, incluyendo información sobre las fuentes de datos (como la URL de la base de datos, SQL, credenciales), las rutas de los archivos y las URL de los artefactos Jenkins.
- La plantilla de diseño de Grafana (o vista visual del dashboard), que diseñaremos primero y luego usaremos como plantillas para paneles en nuestros dashboards posteriores.
- Los archivos fuente de datos reales de
.jsony.csvy de Couchbase.- El diseño de estos cuadros de mando de observabilidad admite varias fuentes de datos como Couchbase Server, y archivos directos como Documentos JSON y archivos CSV (valores separados por comas). Puede ampliar el código del servicio proxy de la base de datos (en
salpicadero.py) para analizar otros formatos de datos según sea necesario.
- El diseño de estos cuadros de mando de observabilidad admite varias fuentes de datos como Couchbase Server, y archivos directos como Documentos JSON y archivos CSV (valores separados por comas). Puede ampliar el código del servicio proxy de la base de datos (en
El resultado esperado será una interfaz de usuario de cuadro de mando de Grafana y métricas recogidas en series temporales de Prometheus a partir de las dos entradas enumeradas anteriormente. La parte central del diagrama anterior muestra los diferentes servicios de la colección que soportan la creación de los cuadros de mando.
Veamos con más detalle las distintas facetas y servicios incluidos en el diagrama de arquitectura:
- Servicio proxy del salpicadero:
- Se trata de un servicio genérico de aplicación web Python Flask (
salpicadero.py) que interactúa con el servicio Grafana para servir los datos tabulares y otras APIs como/consulta,/añadir,/importary/exportarendpoints. Puede desarrollar uno similar para tener una plantilla genérica (JSON) para los paneles en Grafana y adjuntar los puntos de datos de gráficos y puntos de datos tabulares como JSON de destino para mostrar en su panel de Grafana.
- Se trata de un servicio genérico de aplicación web Python Flask (
- Servicio de exportación Prometheus:
- Se trata de un exportador personalizado de Prometheus (por ejemplo
prometheus.py) Servicio de aplicación web Flask que se conecta a las fuentes de datos y sirve las peticiones desde el propio Prometheus. A alto nivel, esto actúa como un puente entre Prometheus y las fuentes de datos. Tenga en cuenta que este servicio sólo es necesario cuando la fuente de datos debe mantenerse para series temporales (muchas tendencias lo necesitan).
- Se trata de un exportador personalizado de Prometheus (por ejemplo
- Servicio Grafana:
- Se trata de la propia herramienta Grafana que se utiliza para crear paneles y mostrarlos como cuadros de mando.
- Servicio Prometheus:
- Se trata de la propia herramienta Prometheus que contiene sus métricas como datos de series temporales.
- Gestor de alertas:
- El Gestor de Alertas dispone de reglas de alerta personalizadas que reciben alertas cuando se alcanzan determinados umbrales.
- Otros servicios:
- Couchbase: Es posible que ya lo esté utilizando NoSQL pero si no, puedes instalarlo a través de un contenedor o directamente en un host diferente. Couchbase almacena tus datos como documentos JSON, o puedes hacer que almacene campos requeridos como documentos separados para tendencias históricas mientras preparas tus datos de salud o tendencias.
- Docker: Deberá instalar el software del agente Docker en el host para poder utilizar este despliegue de servicios en contenedores.
Ejemplo de estructura JSON del cuadro de mando
En la tabla siguiente, verá una muestra de la estructura tanto de los metadatos de entrada como de la fuente de datos de entrada.
| Estructura JSON de metadatos de entrada: | Estructura de las fuentes de datos de entrada: |
{ |
//Fuente de base de datos |
Despliegue de los servicios del panel de control de observabilidad
Utiliza el docker-compose para que aparezcan todos los servicios necesarios (p. ej., proxy de panel de control, Grafana, Prometheus, exportador, gestor de alertas) que aparecen en el diagrama de arquitectura anterior para nuestros paneles de control de observabilidad. Puedes instalar Couchbase en un host diferente para almacenar tu creciente volumen de datos.
Para subir: docker-compose up
A continuación, visite https://host:3000 para la página de Grafana.
Derribar: docker-compose down
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
version: "2" services: dashboard: restart: unless-stopped build: ../../ ports: - 5001:5000 environment: - GRAFANA_HOST=https://admin:password@grafana:3000 volumes: - ./config/targets.json:/app/targets.json grafana: image: grafana/grafana:8.0.1 restart: unless-stopped volumes: - ./config/grafana:/var/lib/grafana environment: GF_INSTALL_PLUGINS: "simpod-json-datasource,marcusolsson-csv-datasource,ae3e-plotly-panel" GF_AUTH_ANONYMOUS_ENABLED: "true" GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS: "ae3e-plotly-panel" GF_RENDERING_SERVER_URL: https://renderer:8081/render GF_RENDERING_CALLBACK_URL: https://grafana:3000/ ports: - 4000:3000 renderer: image: grafana/grafana-image-renderer:latest prometheus: restart: unless-stopped image: prom/prometheus volumes: - ./config/prometheus.yml:/etc/prometheus/prometheus.yml - ./config/alert.rules.yml:/etc/prometheus/alert.rules.yml exporter: restart: unless-stopped build: ../../exporter volumes: - ./config/queries.json:/app/queries.json alertmanager: restart: unless-stopped image: prom/alertmanager ports: - 9093:9093 volumes: - ./config/alertmanager.yml:/etc/alertmanager/alertmanager.yml - ./config/alert_templates:/etc/alertmanager/templates |
El contenido de los archivos de referencia de servicios anteriores -o fragmentos para abreviar- puede encontrarse en la sección de aplicación.
Con estas herramientas, puede crear una amplia variedad de cuadros de mando que se adapten a sus necesidades. Le mostraremos tres ejemplos de cuadros de mando para que se haga una idea de las posibilidades.
Ejemplos de cuadros de mando: Visión general
| # | Cuadro de mandos | Medidas | Métricas |
| 1 | Cuadros de mando de los ciclos de pruebas de regresión funcionales | Tendencias entre los ciclos de pruebas de regresión funcional tanto a nivel de construcción como de componentes | total de pruebas, superadas, fallidas, abortadas, tiempo total, tiempo de ejecución nuevo, etc. |
| 2 | Paneles de uso de Infra VMs, incluyendo VMs estáticas y VMs dinámicas | Utilización e historia de los recursos | recuento activo, recuento disponible, cálculo de horas/máx/creadas por día, semana, mes |
| 3 | Infra VMs Health dashboards, Static Servers, Jenkins Slaves VMs | Supervisión del estado de las máquinas virtuales, alertas y seguimiento del historial de las máquinas virtuales | ssh_fail, pool_os vs real_os, usos de cpu-memory-disk-swap, descriptores de archivo, reglas de firewall, pool_mac_address vs real_mac_address, días de arranque, procesos totales y de producto, versiones de aplicaciones y servicios instalados, etc. |
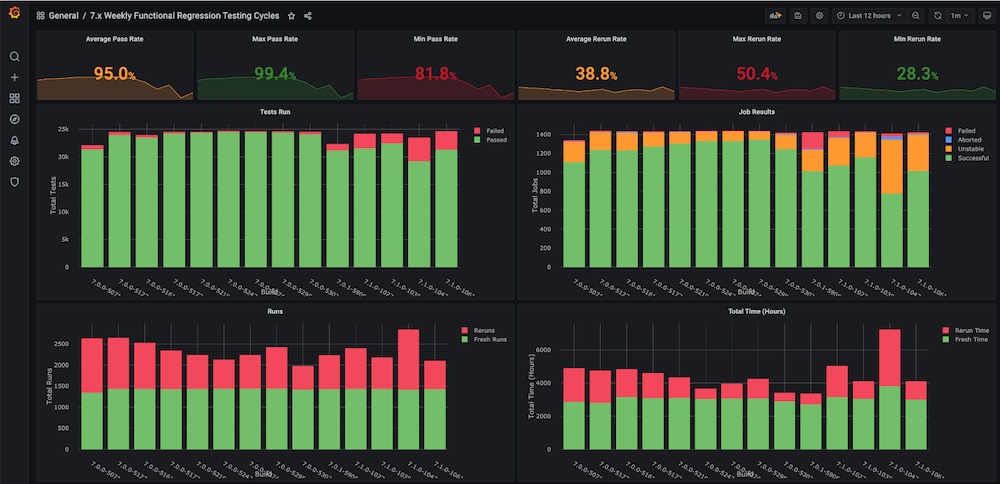
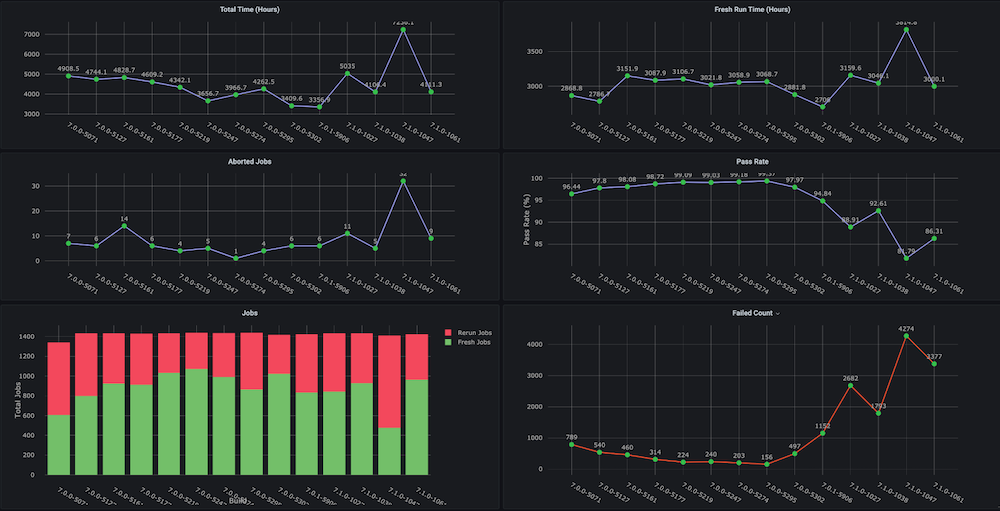
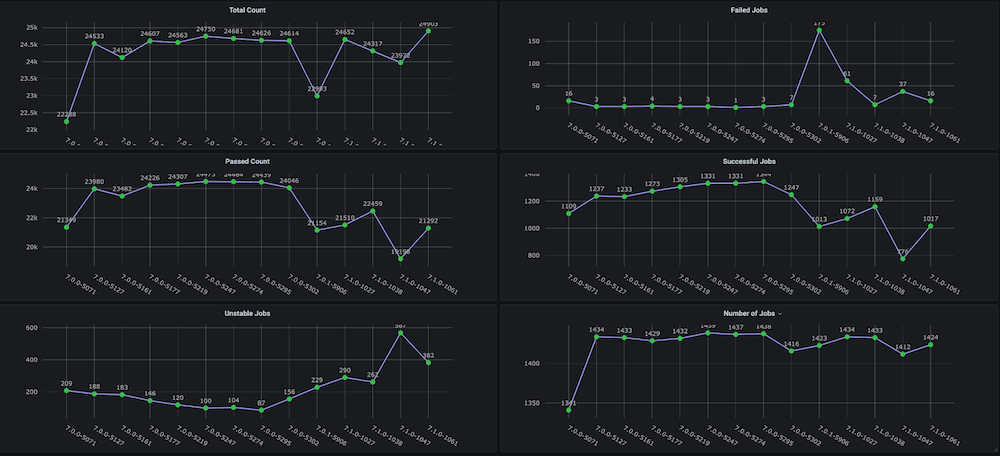
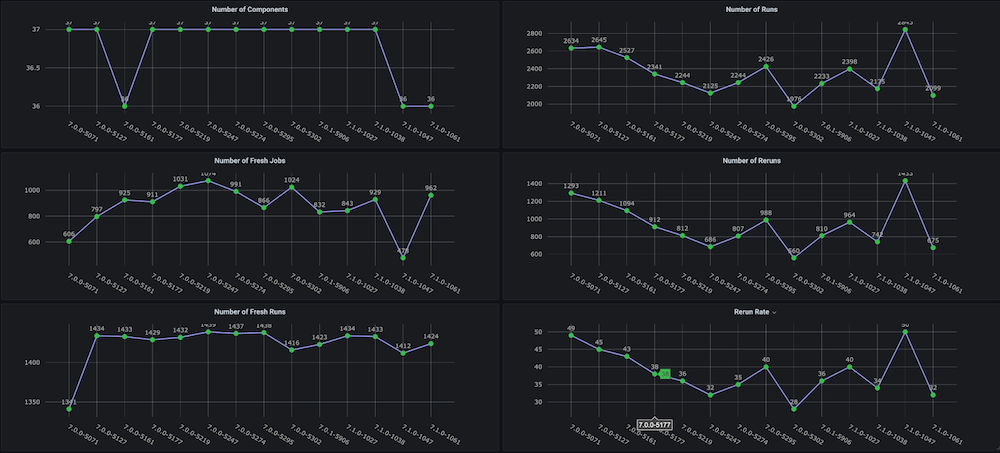
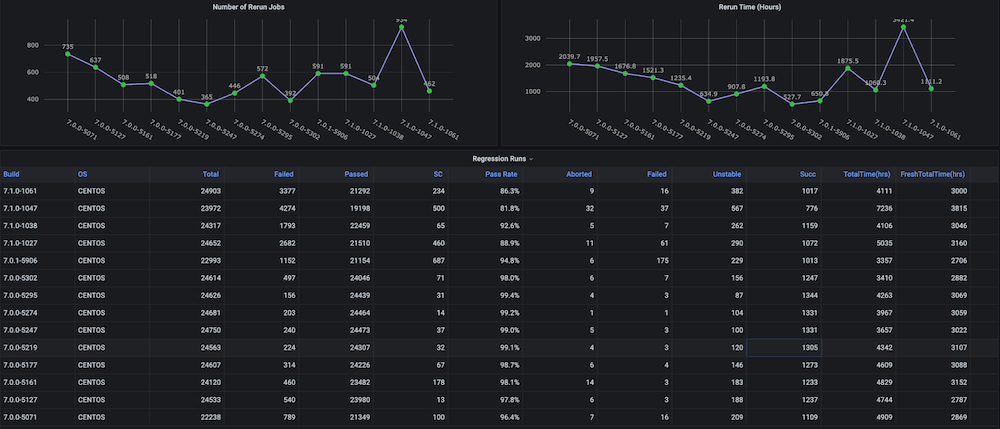
Cuadro de mando #1: Tablero de ciclos de pruebas de regresión funcional
Problema: Antes de crear este cuadro de mandos para nosotros, no existían gráficos de tendencias sobre los ciclos de pruebas de regresión con métricas como el tiempo total empleado, la tasa de aprobados, las nuevas ejecuciones frente a las repetidas (por ejemplo, debido a problemas de infraestructura), el número incoherente de abortos y fallos, ni tampoco tendencias separadas a nivel de componentes o módulos.
Solución: El plan era crear un script analizador de ejecución que analice los datos de prueba que ya están almacenados en el bucket de Couchbase. Después de eso, obtenemos los datos de la serie temporal de los últimos n número de compilaciones y métricas objetivo para cada compilación.
Instantáneas del cuadro de mandos:
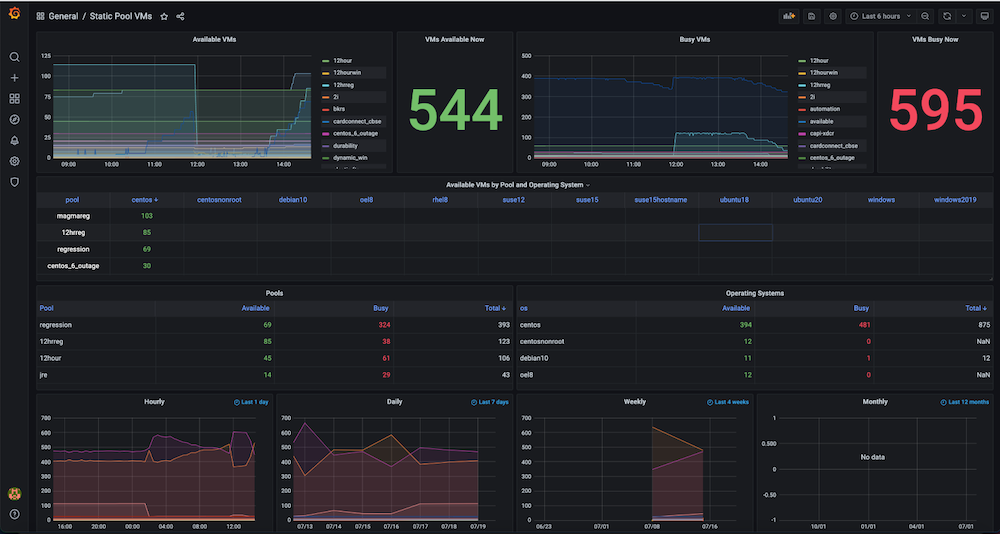
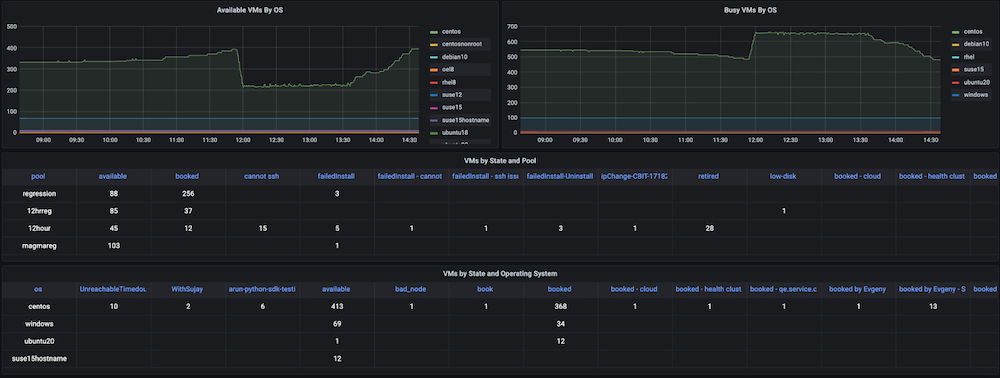
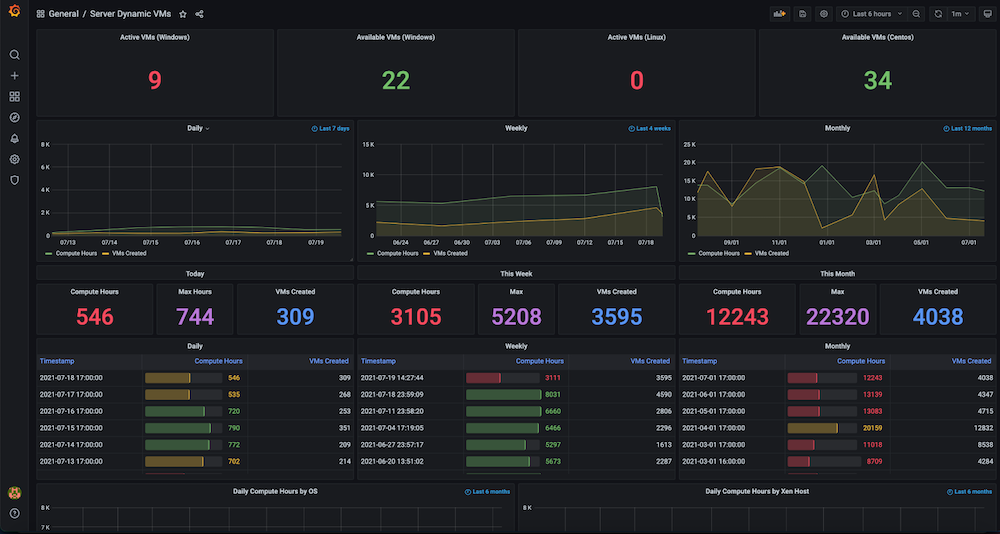
Cuadro de mando #2: Cuadro de mando de uso de recursos de infraestructura / máquinas virtuales
Problema: Antes de crear este cuadro de mandos, teníamos un gran número de máquinas virtuales estáticas y dinámicas, pero no había seguimiento de cómo se utilizaban los recursos de hardware. No teníamos información sobre métricas como las máquinas virtuales activas utilizadas en ese momento, el recuento disponible, el tiempo de máquina utilizado o las horas de computación diarias, semanales o mensuales.
Solución: Nuestro plan consistía en recopilar primero los datos de todas las máquinas virtuales, como la asignación y liberación dinámicas de IP, las horas exactas de creación y liberación, así como cualquier agrupación, como pools, etc. La mayoría de estos datos ya existían en Servidor Couchbase (gestionados por los respectivos gestores de servicios). Utilizando la flexibilidad de el lenguaje de consulta SQL (también conocido como N1QL), pudimos extraer esos datos en un formato adecuado para los gráficos que queríamos mostrar en este panel de observabilidad.
Instantáneas del cuadro de mandos:
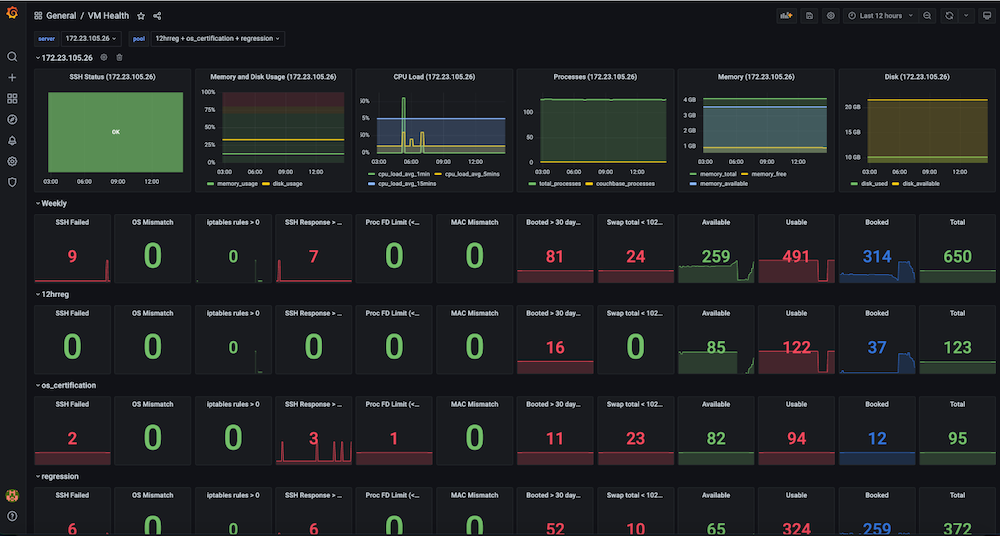
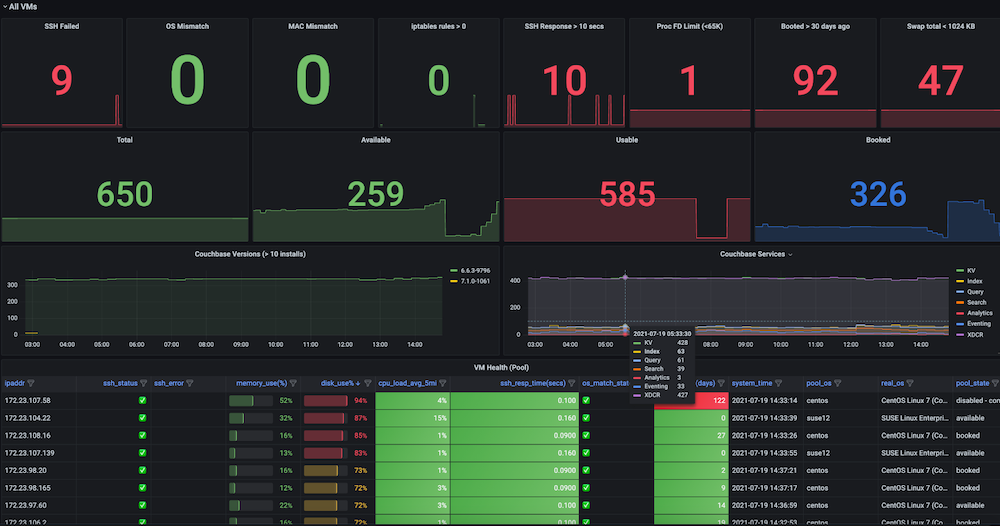
Cuadro de mando #3: Cuadro de mando del estado de las máquinas virtuales de infraestructura
Problema: Antes de disponer de este panel de control, las pruebas de regresión fallaban de forma incoherente y había problemas de poca importancia con las máquinas virtuales. Algunos de los problemas eran fallos de SSH, desajustes de SO, cambios de IP de las máquinas virtuales, demasiados archivos abiertos, problemas de swap, necesidad de reinicios, IP duplicadas entre varias ejecuciones, uso elevado de memoria, disco lleno (/ o /datos), las reglas del cortafuegos que detenían la conexión del punto final, los problemas de los esclavos debidos a la gran cantidad de memoria y el uso del disco eran habituales. No había ningún panel de control de observabilidad para mirar y observar estas métricas, ni tampoco comprobaciones y alertas para la salud de la infraestructura de pruebas.
Solución: Decidimos crear una comprobación periódica automática de la salud que captura datos métricos de las máquinas virtuales seleccionadas, como por ejemplo ssh_fail, pool_os vs real_os, cpu-memory-disk-swap usos, descriptores de archivos, reglas de cortafuegos, dirección_mac_pool vs dirección_mac_realdías de arranque, total y procesos de Couchbase, versión de Couchbase instalada y servicios. (En suma, capturamos ~50 métricas). Estas métricas se exponen como un endpoint de Prometheus que se muestra en Grafana, y la información también se guarda en Couchbase para futuros análisis de datos. También se crearon alertas para monitorear las métricas de salud clave en busca de problemas para permitir una intervención rápida y finalmente lograr una mayor estabilidad de las ejecuciones de prueba.
Instantáneas del cuadro de mandos:
Aplicación
Hasta ahora, has visto la arquitectura de alto nivel de los cuadros de mando de observabilidad, qué servicios se requieren, qué tipo de cuadros de mando puedes necesitar, y también cómo desplegar estos servicios. Ahora, es el momento de ver algunos detalles de implementación.
Nuestra primera parada es la recopilación y almacenamiento de métricas y la visualización de datos de los cuadros de mando. La mayoría de los pasos de almacenamiento y visualización de datos son similares para todos los casos de uso, pero la recopilación de datos de métricas depende de las métricas que elijas como objetivo.
Cómo obtener datos sanitarios para sus cuadros de mando
Para el caso de uso de la monitorización de infraestructuras, hay que recopilar diversas métricas de estado de cientos de máquinas virtuales para crear una infraestructura estable.
Para este paso, creamos un script en Python que realiza la conexión SSH a las VMs en paralelo (pool multiproceso) y recoge los datos necesarios. En nuestro caso, también tenemos un trabajo Jenkins que ejecuta periódicamente este script y recoge los datos de salud (CSV), y luego los guarda en la base de datos Couchbase.
La razón por la que creamos este script personalizado -en lugar del exportador de nodos fácilmente disponible proporcionado por Prometheus- es que algunas de las métricas necesarias no eran compatibles. Además, esta solución era más sencilla que desplegar y mantener el nuevo software en más de 1000 servidores. El siguiente fragmento de código muestra algunas de las comprobaciones que se realizan a nivel de máquina virtual.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def check_vm(os_name, host): client = SSHClient() client.set_missing_host_key_policy(AutoAddPolicy()) ... cpus = get_cpuinfo(client) meminfo = get_meminfo(client) diskinfo = get_diskinfo(client) uptime = get_uptime(client) ... return ssh_status, '', ssh_resp_time, real_os_version, cpus, meminfo, diskinfo, uptime, uptime_days, systime, cpu_load, cpu_total_processes, fdinfo, \ iptables_rules_count, mac_address, swapinfo, cb_processes, cb_version, cb_running_serv, cb_ind_serv def get_cpuinfo(ssh_client): return ssh_command(ssh_client,"cat /proc/cpuinfo |egrep processor |wc -l") def get_meminfo(ssh_client): return ssh_command(ssh_client,"cat /proc/meminfo |egrep Mem |cut -f2- -d':'|sed 's/ //g'|xargs|sed 's/ /,/g'|sed 's/kB//g'") def get_diskinfo(ssh_client): return ssh_command(ssh_client,"df -ml --output=size,used,avail,pcent / |tail -1 |sed 's/ \+/,/g'|cut -f2- -d','|sed 's/%//g'") def get_uptime(ssh_client): return ssh_command(ssh_client, "uptime -s") def get_cpu_users_load_avg(ssh_client): return ssh_command(ssh_client, "uptime |rev|cut -f1-4 -d','|rev|sed 's/load average://g'|sed 's/ \+//g'|sed 's/users,/,/g'|sed 's/user,/,/g'") def get_file_descriptors(ssh_client): return ssh_command(ssh_client, "echo $(cat /proc/sys/fs/file-nr;ulimit -n)|sed 's/ /,/g'") def get_mac_address(ssh_client): return ssh_command(ssh_client, "ifconfig `ip link show | egrep eth[0-9]: -A 1 |tail -2 |xargs|cut -f2 -d' '|sed 's/://g'`|egrep ether |xargs|cut -f2 -d' '") def get_mac_address_ip(ssh_client): return ssh_command(ssh_client, "ip a show `ip link show | egrep eth[0-9]: -A 1 |tail -2 |xargs|cut -f2 -d' '|sed 's/://g'`|egrep ether |xargs|cut -f2 -d' '") |
El siguiente fragmento de código muestra cómo conectarse a Couchbase utilizando Python SDK 3.x con operaciones clave-valor, obteniendo un documento o guardando un documento en la base de datos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
try: self.cb_cluster = Cluster("couchbase://"+self.cb_host, ClusterOptions(PasswordAuthenticator(self.cb_username, self.cb_userpassword), \ timeout_options=ClusterTimeoutOptions(kv_timeout=timedelta(seconds=10)))) self.cb_b = self.cb_cluster.bucket(self.cb_bucket) self.cb = self.cb_b.default_collection() except Exception as e: print('Connection Failed: %s ' % self.cb_host) print(e) def get_doc(self, doc_key, retries=3): # .. return self.cb.get(doc_key) def save_doc(self, doc_key, doc_value, retries=3): #... self.cb.upsert(doc_key, doc_value) #... |
Implantación del servicio proxy del cuadro de mandos
Para los casos de uso de observabilidad de pruebas, los datos están en una URL de artefacto de Jenkins y también en Couchbase Server. Para unir estas múltiples fuentes de datos (CSV, DB), creamos un servicio API proxy que aceptaría peticiones de Grafana y devolvería el formato de datos entendido por Grafana.
Los siguientes fragmentos de código muestran los detalles de implementación y preparación del servicio.
salpicadero.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Dashboard API service @app.route("/query", methods=['POST']) def query(): """ /query responds to a Grafana data request and is formatted as either data points for time series data or rows and columns for tabular data """ for target in request.json['targets']: data_type = target['type'] if data_type == "timeseries": datapoints = calculate_datapoints(target) elif data_type == "table": datapoints = calculate_rows_and_columns(target) ... def calculate_datapoints(target): """ Returns data in a time series format datapoints is formatted as a list of 2 item tuples in the format [value, timestamp] """ ... if target['source'] == "couchbase": ... elif target['source'] == "json": ... elif target['source'] == "csv": |
Dockerfile
|
1 2 3 4 5 6 7 8 9 10 11 |
FROM ubuntu:latest ENV DEBIAN_FRONTEND "noninteractive" RUN apt-get update -y && apt-get install -y python3-dev python3-pip python3-setuptools cmake build-essential RUN mkdir /app COPY ./requirements.txt /app WORKDIR /app RUN pip3 install -r requirements.txt COPY ./dashboard.py /app COPY ./entrypoint.sh /app ENTRYPOINT ["./entrypoint.sh"] |
entrypoint.sh
|
1 2 |
#!/bin/bash python3 dashboard.py $GRAFANA_HOST |
requisitos.txt
|
1 2 3 |
couchbase==3.0.7 Flask==1.1.2 requests==2.24.0 |
Cómo obtener los datos tabulares en Grafana
Grafana es una gran herramienta para visualizar datos de series temporales. Sin embargo, a veces quieres mostrar algunos datos de series no temporales en la misma interfaz.
Logramos este objetivo utilizando el Plugin Plotly que es una biblioteca de gráficos de JavaScript. Nuestro caso de uso principal era ilustrar las tendencias a través de una variedad de métricas importantes para nuestras pruebas de regresión semanales. Algunas de las métricas más importantes que queríamos rastrear eran la tasa de aprobación, el número de pruebas, trabajos abortados, y el tiempo total se toma. Desde el lanzamiento de Grafana 8, hay un soporte limitado para los gráficos de barras. En el momento de escribir esto, la funcionalidad de gráficos de barras todavía está en beta y no ofrece todas las características que necesitamos, como el apilamiento.
Nuestro objetivo era admitir archivos CSV/JSON genéricos o una consulta SQL++ de Couchbase y ver los datos como una tabla en Grafana. Para lograr la máxima portabilidad, queríamos tener un único archivo que definiera tanto las fuentes de datos como el diseño de la plantilla de Grafana.
Para mostrar los datos tabulares, a continuación se presentan las dos opciones viables.
- Escribir un plugin de interfaz de usuario para Grafana
- Proporcionar un proxy JSON utilizando el método Plugin de fuentes de datos JSON
Elegimos la opción 2 para nuestra implementación, ya que parecía más sencillo que intentar aprender las herramientas del plugin de Grafana y crear un plugin de interfaz de usuario independiente para la configuración.
Tenga en cuenta que desde que terminó este proyecto, un nuevo plugin que te permite añadir datos CSV a Grafana directamente. Si la visualización de datos tabulares de un CSV es su único requisito, entonces este plugin es una buena solución.
Implantación del servicio Prometheus
prometheus.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Prometheus global config global: scrape_interval: 1m # Set the scrape interval to every 15 seconds. Default is every 1 minute. scrape_timeout: 30s # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093 rule_files: - "alert.rules.yml" - job_name: "prometheus" static_configs: - targets: ["localhost:9090"] - job_name: "automation_exporter" static_configs: - targets: ["exporter:8000"] |
alert.rules.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
groups: - name: alert.rules rules: - alert: PoolVMDown expr: vm_health_ssh_status == 0 for: 1m annotations: title: "Server Pool VM {{ $labels.ipaddr }} SSH Failed" description: "{{ $labels.ipaddr }} SSH failed with error: {{ $labels.ssh_error }}." labels: severity: "critical" - alert: PoolVMHighDiskUsage expr: disk_usage >= 95 for: 1m annotations: title: "Server Pool VM {{ $labels.ipaddr }} high disk usage" description: "{{ $labels.ipaddr }} has disk usage of {{ $value }}%" labels: severity: "critical" |
Cómo obtener métricas personalizadas a través del exportador de Prometheus
Muchos servicios nativos de la nube se integran directamente con Prometheus para permitir la recopilación centralizada de métricas para todos sus servicios.
Queríamos ver cómo podíamos utilizar esta tecnología para supervisar nuestra infraestructura existente. Si tienes servicios que no exponen directamente un punto final de métricas de Prometheus, la forma de resolverlo es utilizar un exportador. De hecho, hay incluso un exportador Couchbase para exponer todas las métricas importantes de su clúster. (Nota: En Servidor Couchbase 7.0Couchbase 7 utiliza Prometheus para la recopilación y gestión de las estadísticas del servidor para dar servicio a los usuarios de Couchbase. la interfaz web).
Al crear nuestros paneles de observabilidad, teníamos varios datos almacenados en archivos JSON, en archivos CSV y en buckets de Couchbase. Queríamos una forma de exponer todos estos datos y mostrarlos en Grafana tanto en formato tabular como en forma de datos de series temporales mediante Prometheus.
Prometheus espera una salida de texto simple basada en líneas. He aquí un ejemplo de nuestra monitorización de grupos de servidores:
|
1 2 |
available_vms{pool="12hrreg"} 1 available_vms{pool="regression"} 16 |
Veamos con más detalle cómo implementar fuentes de datos tanto desde archivos CSV como desde Couchbase directamente.
Archivos CSV como fuente de datos
Cada vez que Prometheus sondea el punto final, obtenemos el CSV y, para cada columna, exponemos una métrica, añadiendo etiquetas para varias filas si se proporciona una etiqueta en la configuración.
Para el ejemplo anterior, el CSV tiene el siguiente aspecto:
|
1 2 3 |
pool,available_count 12hrreg,1 regression,16 |
Couchbase como fuente de datos
Cada vez que Prometheus sondea el endpoint, ejecutamos las consultas SQL++ definidas en la configuración, y para cada consulta, exponemos una métrica, añadiendo etiquetas para múltiples filas si se proporciona una etiqueta en la configuración.
A continuación se muestra un ejemplo de respuesta SQL++ que produce las métricas anteriores:
|
1 2 3 4 5 6 7 8 |
[{ “pool”, “12hrreg”, “count”: 1 }, { “pool”, “regression”, “count”: 16 }] |
Este servicio Python exportador expone un archivo /métricas que se utilizará en Prometheus. Estas métricas se definen en consultas.json y definir qué consultas y columnas CSV deben exponerse como métricas. Consulte el siguiente fragmento de JSON (reducido para abreviar) como ejemplo.
consultas.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
{ "clusters": { "static_vms": { "host": "<ip-address>", "username": "Administrator", "password": "xxxx" }, ... }, "queries": [ { "name": "available_vms", "cluster": "static_vms", "query": "SELECT poolId as `pool`, COUNT(*) AS count FROM (SELECT poolId FROM `QE-server-pool` WHERE IS_ARRAY(poolId)=FALSE and state='available' UNION ALL SELECT poolId FROM `QE-server-pool` UNNEST poolId where `QE-server-pool`.state = 'available' ) AS pools group by poolId", "description": "Available VMs for each server pool", "value_key": "count", "labels": ["pool"] }, ... ], "csvs": { "vm_health": "https://<jenkins-host-job-url>/lastSuccessfulBuild/artifact/vm_health_info.csv/", ... }, "columns": [ { "name": "memory_usage", "csv": "vm_health", "description": "Memory usage", "column": "memory_use(%)", "labels": ["ipaddr"] }, { "name": "disk_usage", "csv": "vm_health", "description": "Disk usage", "column": "disk_use%", "labels": ["ipaddr"] }, { "name": "cpu_load_avg_5mins", "csv": "vm_health", "description": "CPU load average (5mins)", "column": "cpu_load_avg_5mins", "labels": ["ipaddr"] }, { "name": "vm_health_ssh_status", "csv": "vm_health", "description": "SSH Status", "column": "ssh_status", "labels": ["ipaddr", "ssh_error", "pool_state", "couchbase_version", "pool_ids"] }, ... ] } |
exportar.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
for options in settings['queries'] + settings["columns"]: log.info("Registered metrics collection for {}".format(options['name'])) def get_labels(row, options): rename_map = options.get("rename", {}) return ["{}=\"{}\"".format(rename_map[label] if label in rename_map else label, row[label]) for label in options["labels"]] def collect_cb(clusters, metrics, options): rows = clusters[options["cluster"]].query(options["query"]).rows() for row in rows: if len(options["labels"]) > 0: labels = get_labels(row, options) metrics.append("{}{{{}}} {}".format( options["name"], ",".join(labels), row[options["value_key"]])) else: metrics.append("{} {}".format( options["name"], row[options["value_key"]])) def collect_csv(metrics, options) csvfile = requests.get(csvs[options["csv"]]).text.splitlines() reader = DictReader(csvfile) for row in reader: if options["column"] not in row or row[options["column"]] == "": continue if len(options["labels"]) > 0: labels = get_labels(row, options) metrics.append("{}{{{}}} {}".format( options["name"], ",".join(labels), row[options["column"]])) else: metrics.append("{} {}".format( options["name"], row[options["column"]])) @app.route("/metrics") def metrics(): metrics = [] clusters = {} for [cluster_name, options] in settings['clusters'].items(): if cluster_name not in clusters: try: clusters[cluster_name] = Cluster('couchbase://'+options['host'], ClusterOptions( PasswordAuthenticator(options['username'], options['password']))) except Exception as e: log.warning("Couldn't connect to cluster {}".format(e)) log.debug("Connected to {}".format(options['host'])) for options in settings["queries"] + settings["columns"]: log.debug("Collecting metrics for {}".format(options["name"])) try: if "cluster" in options: collect_cb(clusters, metrics, options) elif "csv" in options: collect_csv(metrics, options) else: raise Exception("Invalid type") except Exception as e: log.warning("Error while collecting {}: {}".format( options["name"], e)) return Response("\n".join(metrics), mimetype="text/plain") |
Implementación del servicio de gestión de alertas
Prometheus también admite alertas en las que realiza un seguimiento de métricas específicas a lo largo del tiempo. Si esa métrica empieza a dar resultados, se activará una alerta.
En el ejemplo anterior podría añadir una alerta para cuando el pool de regresión no tenga servidores disponibles. Si especifica la consulta como available_vms{pool="regresión"} == 0 que devolverá una serie cuando haya 0 disponible. Una vez añadido, Prometheus realiza el seguimiento por usted (por defecto, cada minuto). Si eso es todo lo que hace, puede visitar la interfaz de usuario de Prometheus y la pestaña de alertas le mostrará qué alertas se están disparando.
Con el Gestor de Alertas, puede ir un paso más allá y conectar servicios de comunicaciones para que Prometheus le avise por correo electrónico o un canal de Slack, por ejemplo, cuando se dispare una alerta. Esto significa que puede ser informado inmediatamente a través de su método preferido cuando algo va mal. En Couchbase, configuramos alertas para ser notificados de un alto uso de disco en los servidores, así como cuando no se podía acceder a los servidores a través de SSH. Mira el ejemplo de abajo:
alertmanager.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
global: resolve_timeout: 1m smtp_from: qa@couchbase.com smtp_smarthost: mail-com.mail.protection.outlook.com:25 route: group_by: ["alertname"] group_wait: 10s group_interval: 10s repeat_interval: 24h receiver: "infra-email" matchers: - alertname =~ PoolVMDown|PoolVMOSMismatch|PoolVMHighDiskUsage|SlaveVMHighDiskUsage|SlaveVMHighDiskUsageData receivers: - name: "infra-email" email_configs: - to: jake.rawsthorne@couchbase.com,jagadesh.munta@couchbase.com |
Conclusión
En conclusión, esperamos que puedas aprender de nuestra experiencia en la creación de cuadros de mando de observabilidad que te ayuden a afinar en las métricas que más importan en tu implementación o caso de uso con el poder de la visualización de datos.
En nuestro caso, este esfuerzo nos permitió detectar problemas de infraestructura de servidores y de estabilidad de las pruebas. La creación de cuadros de mando también redujo el número de pruebas fallidas, así como el tiempo total de regresión de varias versiones del producto.
Esperamos que este tutorial le ayude a crear mejores cuadros de mando de observabilidad en el futuro.
También nos gustaría agradecer especialmente a Raju y al equipo de QE sus comentarios sobre la mejora de las métricas específicas.

Hola este es un muy buen blog pero parece su incompleta en muchas etapas como la forma de ejecutar . Por favor, ayúdame con el código git como quiero probar esta ejecución .muy menos información sobre cómo utilizar couchbase y qué forma se utiliza para publicar en su código . Por favor, ayudar o sugerir si tiene código git en algún repositorio y completa instrctions