Un gráfico para gobernarlos a todos
Con el lanzamiento de Couchbase Autonomous Operator 2.0, los gráficos de Couchbase Operator y Cluster se han consolidado en un único gráfico. Este enfoque simplificado significa que ahora es posible instalar Autonomous Operator, Admission Controller, Couchbase Cluster y Sync Gateway con un solo comando..
Instalación mejorada de CustomResource
La nueva Carta Couchbase ahora instala todas las CustomResourceDefinitions (CRDs) que son gestionadas por el operador Autónomo. Esto supone una mejora con respecto a la versión anterior, que requería que los usuarios instalasen las CRD como un paso independiente antes de instalar Couchbase Chart.
Primeros pasos
Para desplegar rápidamente el controlador de admisión y Operator, así como un clúster de Couchbase Server:
Añade el repositorio de gráficos couchbase a helm:
|
1 2 |
$ helm repo add couchbase https://couchbase-partners.github.io/helm-charts/ $ helm repo update |
Instala el gráfico:
|
1 |
$ helm install default couchbase/couchbase-operator |
Véase Documentación de Couchbase Helm para obtener más información sobre la personalización y gestión de los gráficos.
Requisitos previos
A lo largo de este blog, utilizaremos gráficos de ejemplo del repositorio github de Couchbase Partners. Antes de continuar, vamos a clonar el repositorio:
|
1 |
$ git clone https://github.com/couchbase-partners/helm-charts |
También, Helm 3.1+ es necesario cuando se instala el gráfico oficial de Couchbase Helm.
|
1 2 3 4 |
# linux wget https://get.helm.sh/helm-v3.2.1-linux-amd64.tar.gz tar -zxvf helm-v3.2.1-linux-amd64.tar.gz mv linux-amd64/helm /usr/local/bin/helm |
Siga a Helm's trámites oficiales para instalar en su sistema operativo concreto.
Supervisión con Prometheus
Las métricas del servidor Couchbase pueden exportarse a Prometheus y organizarse en varios cuadros de mando dentro de Grafana. Helm hace que sea muy fácil empezar con una pila Couchbase-Prometheus, ya que es posible agrupar varios componentes en un solo gráfico.
El gráfico de monitorización tiene dependencias para Prometheus y Grafana, y como estamos instalando directamente desde un repositorio de github, el primer paso es construir el gráfico:
|
1 |
$ helm dependency build couchbase-prometheus/ |
Ahora el gráfico está listo para ser instalado. El siguiente comando crea un clúster Couchbase con cada nodo exportando métricas a Prometheus:
|
1 |
$ helm install monitor couchbase-prometheus/ |
La instalación devuelve alguna información sobre la gestión del gráfico junto con los comandos a ejecutar para ver el dashboard de grafana. Usted debe ver:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
NAME: monitor NAMESPACE: default STATUS: deployed ... == Monitoring # Prometheus kubectl port-forward --namespace default prometheus-monitor-prom-prometheus-0 9090:9090 # open localhost:9090 # Grafana kubectl port-forward --namespace default deployment/monitor-grafana 3000:3000 # open localhost:3000 # login admin:admin |
Ejecute el comando port-forward para Grafana para ver las métricas de Couchbase:
|
1 |
$ kubectl port-forward --namespace default deployment/monitor-grafana 3000:3000 |
Ahora abre https://localhost:3000 e inicia sesión como admin:admin. Haga clic en el botón Couchbase en la sección de cuadros de mando:
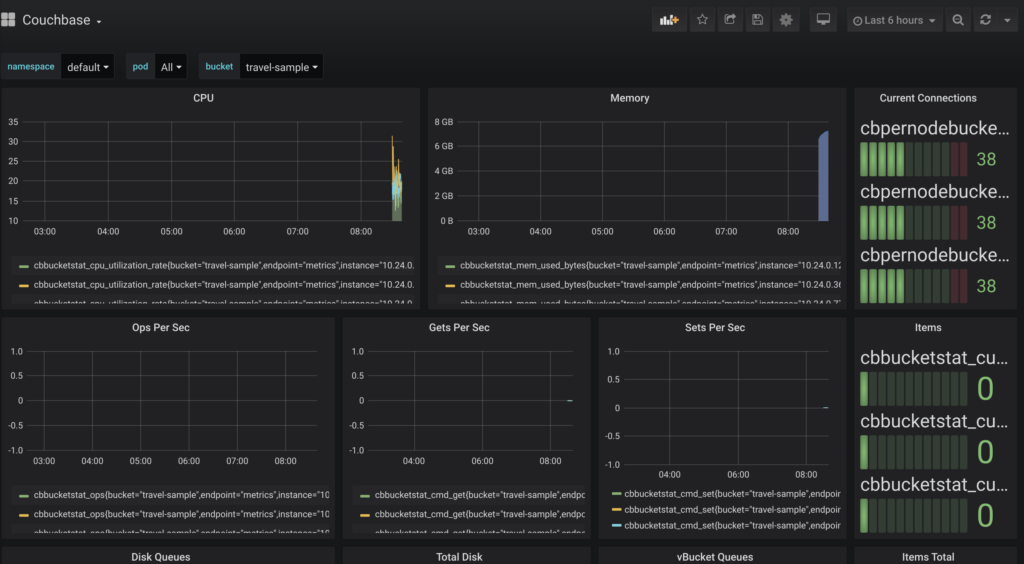
couchbase en grafana
Cambie el intervalo de tiempo de 6 horas a 5 minutos. Esto ayuda a visualizar las actualizaciones que se producen en los primeros minutos de la supervisión:
Ahora rellene el cluster con los datos del viaje de muestra:
|
1 |
kubectl create -f couchbase-prometheus/travel-sample.yaml |
Debería ver las operaciones establecidas junto con el número de elementos aumentando en el Panel de control. Consulte el Exportador Couchbase para descubrir estadísticas adicionales que pueden añadirse para personalizar aún más el cuadro de mandos.
¿Qué sigue?
Existen otros tutoriales y blogs escritos por Daniel Ma.
Además, consulte la documentación de Cuadro de mando de Couchbase para ver otras formas de personalizar Couchbase para su despliegue.
Agradecimientos
Gracias a Daniel Ma y Matt Ingenthron por contribuir a este artículo.
Hola Tommie, Gracias por compartir esto
En su opinión, ¿cuáles serían las métricas clave para supervisar el escalado automático/manual del clúster couchbase, especialmente en un entorno de nube?
Saludos
Gracias Purav,
La respuesta realmente varía en función de los objetivos de tu aplicación, pero en general siempre es bueno comprobar la cuota de bucket % utilizada. Cuando ese valor se acerque a 80% o a las marcas de aguas altas, el clúster empezará a expulsar elementos al disco, lo que provocará búsquedas que pueden causar latencia.
Para las cargas de trabajo de consulta, podría recopilar estadísticas y calcular el valor del percentil 99 de las consultas de larga duración como indicación de problemas de rendimiento.