Introducción
Couchbase Full Text Search (FTS) es ideal para indexar múltiples arrays y ejecutar consultas con múltiples filtros predicados en arrays. En este artículo, demostraré las ventajas de usar FTS sobre GSI (Global Secondary Index) para la indexación de arrays mientras trabajo a través de un caso de uso de ejemplo que requiere la consulta de múltiples arrays. Crearemos un índice multi-array FTS y consultaremos el índice con N1QL usando la nueva función SEARCH() introducida en Couchbase Server 6.5.
Cubo de muestras de viaje
En este artículo, haremos referencia a la función Viajes Conjunto de datos de muestra disponible para instalar en cualquier instancia de Couchbase Server. El bucket travel-sample tiene varios tipos de documentos distintos: aerolínea, ruta, aeropuerto, punto de referencia y hotel. El modelo de documento para cada tipo de documento contiene:
- Una clave que actúa como clave primaria
- Un campo id que identifica el documento
- Un campo de tipo que identifica el tipo de documento
En los ejemplos de este artículo se utilizarán los documentos de un hotel. El documento de ejemplo que figura a continuación le dará una idea de la estructura de un documento de hotel:

Figura 1 - Ejemplo de documento hotelero
El problema
Nuestro ejemplo es un caso de uso en el que un usuario puede buscar hoteles que hayan sido reseñados o que le hayan gustado a una persona con un nombre concreto. Para ello, es necesario consultar los documentos del hotel en función de las opiniones y los gustos públicos, que son matrices dentro del modelo de documentos del hotel:

Figura 2 - Matrices "public_likes" y "reviews" en el documento de ejemplo del hotel
Veamos primero cómo implementar este caso de uso con N1QL y GSI (Global Secondary Index). Para encontrar hoteles que hayan gustado o hayan sido reseñados por alguien llamado Ozella, la consulta podría ser la siguiente:
|
1 2 3 4 5 6 |
SELECCIONE nombre, dirección, ciudad, país, teléfono, me gusta_público, reseñas DESDE `viaje-muestra` DONDE tipo="hotel" Y (CUALQUIER l EN me gusta_público SATISFACE l COMO "%Ozella%" FIN O CUALQUIER r EN reseñas SATISFACE r.autor COMO "%Ozella%" FIN); |
Necesitamos crear un índice apropiado para esta consulta. Tal vez algo como esto que indexa ambas matrices de interés para los documentos del hotel:
|
1 2 3 4 |
CREAR ÍNDICE idx_hotel_public_likes_review_author EN `viaje-muestra` (DISTINTO ARRAY `l` PARA l EN `me gusta_público` FIN, DISTINTO ARRAY `r`.`autor` PARA r EN `reseñas` FIN) DONDE `tipo` = hotel; |
Esto no funciona, y obtenemos el error que se muestra en la Figura 3:
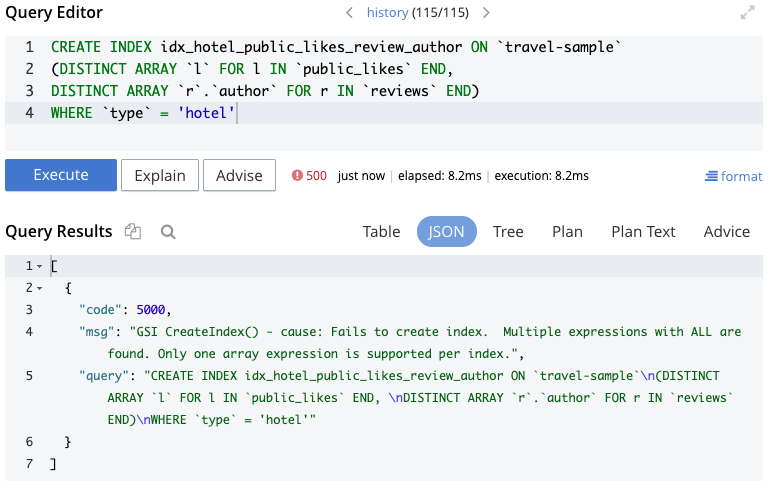 Figura 3 - Error al crear un índice con varias matrices
Figura 3 - Error al crear un índice con varias matrices
Como escribió Keshav Murthy en su blog Búsqueda y Rescate: 7 razones para que los desarrolladores de N1QL (SQL) utilicen la búsqueda (problema #6), con N1QL en Couchbase, "para obtener el mejor rendimiento durante la búsqueda dentro de matrices, es necesario crear índices con claves de matriz. El índice de matriz tiene una limitación: cada índice de matriz sólo puede tener una clave de matriz por índice. Por lo tanto, cuando tienes un objeto cliente con varios campos de matriz, no puedes buscar en todos ellos utilizando un único índice... lo que provoca consultas costosas." Como señala Keshav en ese artículo, se trata de una limitación de los índices b-tree en las bases de datos en general.
Probemos ahora con dos índices de array distintos. Los índices para soportar esta consulta podrían parecerse a estos, que fueron creados usando el método Asesor de índices N1QL de Couchbaseuna nueva característica (DP) en Couchbase 6.5:
|
1 2 3 4 5 6 7 8 |
CREAR ÍNDICE adv_DISTINCT_public_likes_type EN `viaje-muestra`(DISTINTO ARRAY `l` PARA l en `me gusta_público` FIN) DONDE `tipo` = hotel; CREAR ÍNDICE adv_DISTINCT_reviews_author_type EN `viaje-muestra`(DISTINTO ARRAY `r`.`autor` PARA r en `reseñas` FIN) DONDE `tipo` = hotel; |
Con estos 2 índices, nuestra consulta se ejecuta correctamente con 5 resultados (hotel_26020, hotel_10025, hotel_5081, hotel_20425, hotel_25327) y el siguiente plan de ejecución:

Figura 4 - Plan de ejecución con índices múltiples (GSI)
Mismo plan en JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 |
{ "#operator": "Secuencia", "#stats": { "#phaseSwitches": 1, "execTime": "1.321µs" }, "~niños": [ { "#operator": "Autorizar", "#stats": { "#phaseSwitches": 3, "execTime": "3.034µs", "servTime": "1.037859ms" }, "privilegios": { "Lista": [ { "Objetivo": "por defecto:muestra-viaje", "Priv": 7 } ] }, "~niño": { "#operator": "Secuencia", "#stats": { "#phaseSwitches": 1, "execTime": "2.235µs" }, "~niños": [ { "#operator": "UnionScan", "#stats": { "#itemsIn": 1646, "#itemsOut": 904, "#phaseSwitches": 5107, "execTime": "1.32474ms", "kernTime": "113.495553ms" }, "escaneos": [ { "#operator": "DistinctScan", "#stats": { "#itemsIn": 4004, "#itemsOut": 813, "#phaseSwitches": 9641, "execTime": "1.381997ms", "kernTime": "69.065425ms" }, "escanear": { "#operator": "IndexScan3", "#stats": { "#itemsOut": 4004, "#phaseSwitches": 16021, "execTime": "19.678094ms", "kernTime": "30.973177ms", "servTime": "17.461885ms" }, "índice": "adv_DISTINCT_public_likes_type", "index_id": "288083a758973630", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "vanos": [ { "rango": [ { "alto": "[]", "inclusión": 1, "bajo": "\"\"" } ] } ], "usando": "gsi", "#ime_normal": "00:00.037", "#iempo_absoluto": 0.037139979000000004 }, "#ime_normal": "00:00.001", "#iempo_absoluto": 0.0013819969999999998 }, { "#operator": "DistinctScan", "#stats": { "#itemsIn": 4104, "#itemsOut": 833, "#phaseSwitches": 9881, "execTime": "2.475034ms", "kernTime": "80.914158ms" }, "escanear": { "#operator": "IndexScan3", "#stats": { "#itemsOut": 4104, "#phaseSwitches": 16421, "execTime": "8.610445ms", "kernTime": "52.02497ms", "servTime": "22.586149ms" }, "índice": "adv_DISTINCT_reviews_author_type", "index_id": "cca7f912cab1a4c6", "proyección_índice": { "clave_primaria": verdadero }, "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "vanos": [ { "rango": [ { "alto": "[]", "inclusión": 1, "bajo": "\"\"" } ] } ], "usando": "gsi", "#ime_normal": "00:00.031", "#iempo_absoluto": 0.031196594 }, "#ime_normal": "00:00.002", "#iempo_absoluto": 0.002475034 } ], "#ime_normal": "00:00.001", "#iempo_absoluto": 0.00132474 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 904, "#itemsOut": 904, "#phaseSwitches": 3733, "execTime": "2.887995ms", "kernTime": "8.826606ms", "servTime": "170.010321ms" }, "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "#ime_normal": "00:00.172", "#iempo_absoluto": 0.172898316 }, { "#operator": "Paralelo", "#stats": { "#phaseSwitches": 1, "execTime": "6.134µs" }, "copias": 2, "~niño": { "#operator": "Secuencia", "#stats": { "#phaseSwitches": 2, "execTime": "3.621µs" }, "~niños": [ { "#operator": "Filtro", "#stats": { "#itemsIn": 904, "#itemsOut": 5, "#phaseSwitches": 1824, "execTime": "279.461548ms", "kernTime": "85.245883ms" }, "condición": "(((`travel-sample`.`type`) = \"hotel\") and (any `l` in (`travel-sample`.`public_likes`) satisfies (`l` like \"%Ozella%\") end or any `r` in (`travel-sample`.`reviews`) satisfies ((`r`.`author`) like \"%Ozella%\") end))", "#ime_normal": "00:00.279", "#iempo_absoluto": 0.279461548 }, { "#operator": "ProyectoInicial", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "7.156613ms", "kernTime": "357.453351ms" }, "result_terms": [ { "expr": "(`viaje-muestra`.`nombre`)" }, { "expr": "(`viaje-muestra`.`dirección`)" }, { "expr": "(`viaje-muestra`.`ciudad`)" }, { "expr": "(`viaje-muestra`.`país`)" }, { "expr": "(`viaje-muestra`.`teléfono`)" }, { "expr": "(`viaje-muestra`.`gustos_públicos`)" }, { "expr": "(`viaje-muestra`.`reseñas`)" } ], "#ime_normal": "00:00.007", "#iempo_absoluto": 0.007156613 }, { "#operator": "ProyectoFinal", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "12.167µs", "kernTime": "98.849µs" }, "#ime_normal": "00:00.000", "#iempo_absoluto": 0.000012167 } ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.000003621 }, "#ime_normal": "00:00.000", "#iempo_absoluto": 0.000006134 } ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0000022349999999999998 }, "#ime_normal": "00:00.001", "#iempo_absoluto": 0.0010408930000000002 }, { "#operator": "Corriente", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "939.145µs", "kernTime": "182.523171ms" }, "#ime_normal": "00:00.000", "#iempo_absoluto": 0.000939145 } ], "~versiones": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.000001321 } |
En el cluster de un solo nodo que se utiliza para estos ejemplos, el tiempo transcurrido de la consulta es de unos 190-200 milisegundos para devolver los 5 documentos resultantes. Como se puede ver en el plan, hay dos operadores IndexScan3 que utilizan cada uno de los dos índices de array que hemos creado, seguidos de un DistinctScan para los resultados de cada escaneo de índice y, a continuación, un UnionScan. El UnionScan muestra un valor de #itemsIn de 1646 documentos y un valor de #itemsOut de 904 documentos, el operador Fetch también obtiene 904 documentos, y finalmente con el operador Filter obtenemos un valor de #ItemsOut de 5. La obtención de 904 documentos es un despilfarro si tenemos en cuenta que al final la consulta nos devuelve 5 documentos, y de hecho unos 170 milisegundos del tiempo total transcurrido se emplean en obtener los 905 documentos cuando sólo se necesitan 5.
La solución
Por el contrario, un índice invertido FTS se puede crear fácilmente para múltiples matrices y es muy adecuado para los casos en los que se necesita buscar campos en múltiples matrices. Vamos a crear un índice FTS en documentos de hotel tanto para la matriz public_likes como para el campo author de la matriz reviews.
Pasos para la creación de índices:
- En la interfaz de búsqueda de texto completo, haga clic en "Añadir índice".
- Especifique un nombre de índice, por ejemplo "hotel_mult_arrays", y seleccione el bucket de muestras de viajes.
- Dado que cada documento del bucket de muestras de viajes tiene un campo "type" que indica el tipo de documento, deje "JSON type field" establecido en "type".
- En asignaciones de tipos:
- Haga clic en "+ Añadir asignación de tipos" y especifique "hotel" como nombre del tipo, ya que el requisito es buscar en todos los documentos de hoteles.
- Se puede acceder a una lista de analizadores disponibles mediante el menú desplegable situado a la derecha del campo de nombre de tipo. Para este caso de uso, deje seleccionado "heredar" para que la asignación de tipos herede el analizador por defecto del índice.
- Dado que el requisito es buscar en los gustos públicos del hotel y revisar los campos del autor, marque "indexar sólo campos especificados". Con esta opción marcada, sólo los campos especificados por el usuario del documento se incluirán en el índice para el mapeo del tipo de hotel (el mapeo no será dinámico, lo que significa que todos los campos se considerarán disponibles para la indexación).
- Haga clic en Aceptar.
- Sitúe el ratón sobre la fila con la asignación del tipo de hotel, haga clic en el botón + y, a continuación, en "insertar campo hijo". Esto permitirá que la matriz public_likes se incluya individualmente en el índice. Especifique lo siguiente:
- campo: Introduce el nombre del campo a indexar, "public_likes".
- tipo: Deja esto establecido en texto para la matriz public_likes.
- buscable como: Déjelo igual que el nombre del campo para el caso de uso actual. Puede utilizarse para indicar un nombre de campo alternativo.
- analizador: Como se hizo para el mapeo de tipos, para este caso de uso, dejar seleccionado "heredar" para que que la asignación de tipos hereda el analizador por defecto.
- índice: Déjela marcada para que el campo se incluya en el índice. Si desmarca la casilla, el campo se eliminará explícitamente del índice.
- almacenar: Marque esta opción para incluir el contenido del campo en los resultados de la búsqueda, lo que permite resaltar las expresiones coincidentes en los resultados. Esto es útil para probar el índice, pero no se recomienda en Prod si el resaltado no es necesario, ya que aumenta el tamaño del índice.
- casilla "incluir en _todos los campos": Déjela marcada ya que el requisito del caso de uso es buscar en varios campos.
- casilla "incluir vectores de términos": Déjela marcada también durante el desarrollo y las pruebas de nuestro índice para poder resaltar los resultados.
- casilla docvalues: Desmarque esta opción. Esta configuración almacena los valores de campo en el índice, lo que proporciona soporte para las Facetas de búsqueda y para la ordenación de los resultados de búsqueda basados en los valores de campo, ninguno de los cuales necesitamos en este caso de uso.
- Haga clic en Aceptar.
- Sitúe el ratón sobre la fila con la asignación del tipo de hotel, haga clic en el botón + y, a continuación, en "insertar asignación de hijos". Esto permitirá que la matriz de subdocumentos de revisión se incluya en el índice. Introduzca el nombre de la propiedad "revisiones", deje seleccionado "heredar" en el desplegable del analizador, marque "sólo indexar campos especificados" y haga clic en Aceptar.
- Sitúe el ratón sobre la fila con la asignación de los hijos de las revisiones, haga clic en el botón + y, a continuación, haga clic en "insertar campo hijo". Esto permitirá incluir en el índice el campo autor de la matriz de subdocumentos de revisión. Especifique lo siguiente:
- campo: Introduce el nombre del campo a indexar, "autor".
- Tipo: Deje esto establecido en texto para el campo de autor.
- buscable como: Déjelo igual que el nombre del campo para el caso de uso actual. Puede utilizarse para indicar un nombre de campo alternativo.
- analizador: Como se hizo para el mapeo de tipos, para este caso de uso, dejar seleccionado "heredar" para que que la asignación de tipos hereda el analizador por defecto.
- índice: Déjela marcada para que el campo se incluya en el índice. Si desmarca la casilla, el campo se eliminará explícitamente del índice.
- almacenar: Marque esta opción para incluir el contenido del campo en los resultados de la búsqueda, lo que permite resaltar las expresiones coincidentes en los resultados. Esto es útil para probar el índice, pero no se recomienda en Prod si el resaltado no es necesario, ya que aumenta el tamaño del índice.
- casilla "incluir en _todos los campos": Déjela marcada ya que el requisito del caso de uso es buscar en varios campos.
- casilla "incluir vectores de términos": Déjela marcada también durante el desarrollo y las pruebas de nuestro índice para poder resaltar los resultados.
- casilla docvalues: Desmarque esta opción. Esta configuración almacena los valores de campo en el índice, lo que proporciona soporte para las Facetas de búsqueda y para la ordenación de los resultados de búsqueda basados en los valores de campo, ninguno de los cuales necesitamos en este caso de uso.
- Haga clic en Aceptar.
- Por último, desmarque la casilla situada junto a la correspondencia de tipos "por defecto". Si se deja activada la correspondencia por defecto, todos los documentos del bucket se incluirán en el índice, independientemente de si el usuario especifica activamente correspondencias de tipos. Sólo se requieren los documentos del hotel, que se incluyen mediante la correspondencia de tipos del hotel añadida anteriormente.
- Los valores por defecto son suficientes para el resto de paneles contraídos (Analizadores, Filtros personalizados, Analizadores de fecha/hora y Avanzado).
- Las réplicas de índice pueden establecerse en 1, 2 ó 3, siempre que el clúster esté ejecutando el servicio de búsqueda en n+1 nodos. Con un entorno de desarrollo de un solo nodo, mantenga el valor predeterminado de 0.
- Para Tipo de índice, el valor por defecto de "Versión 6.0 (Scorch)" es apropiado para cualquier índice recién creado. Scorch reduce el tamaño del índice en disco y proporciona un rendimiento mejorado de MongoDB en el operador para la indexación y la gestión de mutaciones.
- Las particiones de índice pueden dejarse en el valor predeterminado de 6.
- En este punto, la página de creación del índice debería tener el siguiente aspecto el último fotograma capturado en Figura 5. Haga clic en "Crear índice" para completar el proceso.
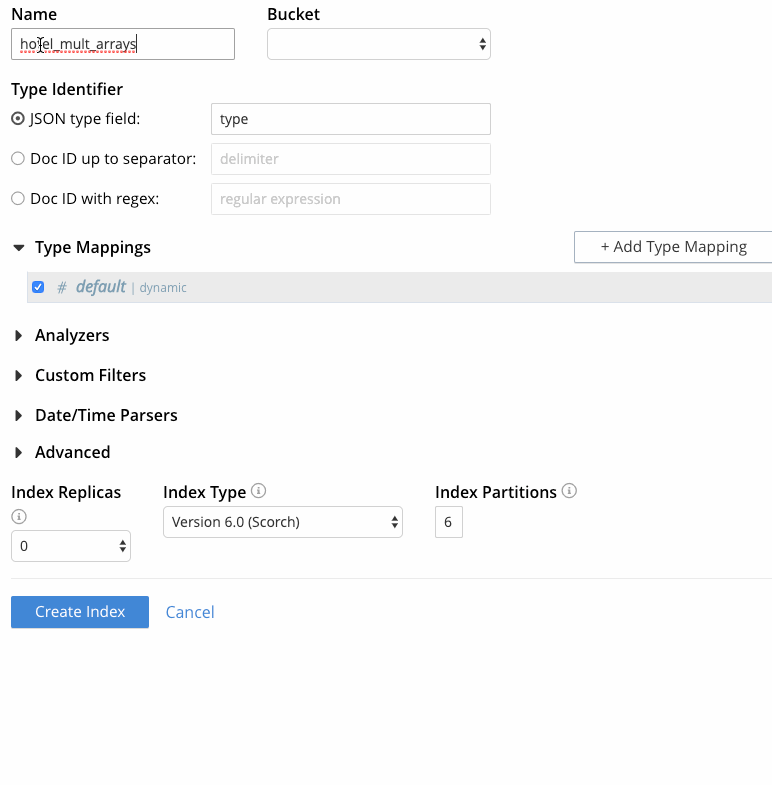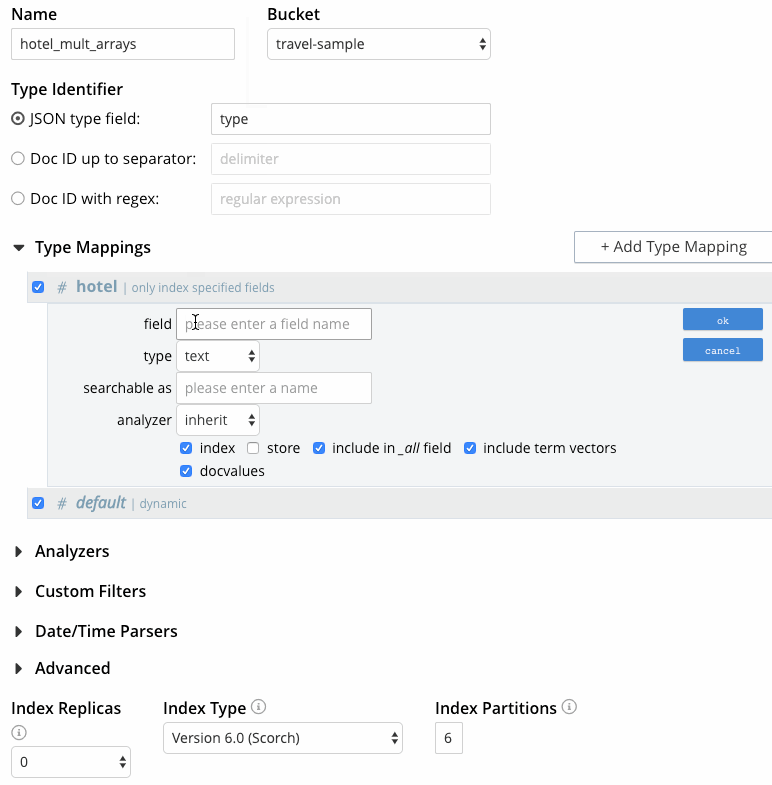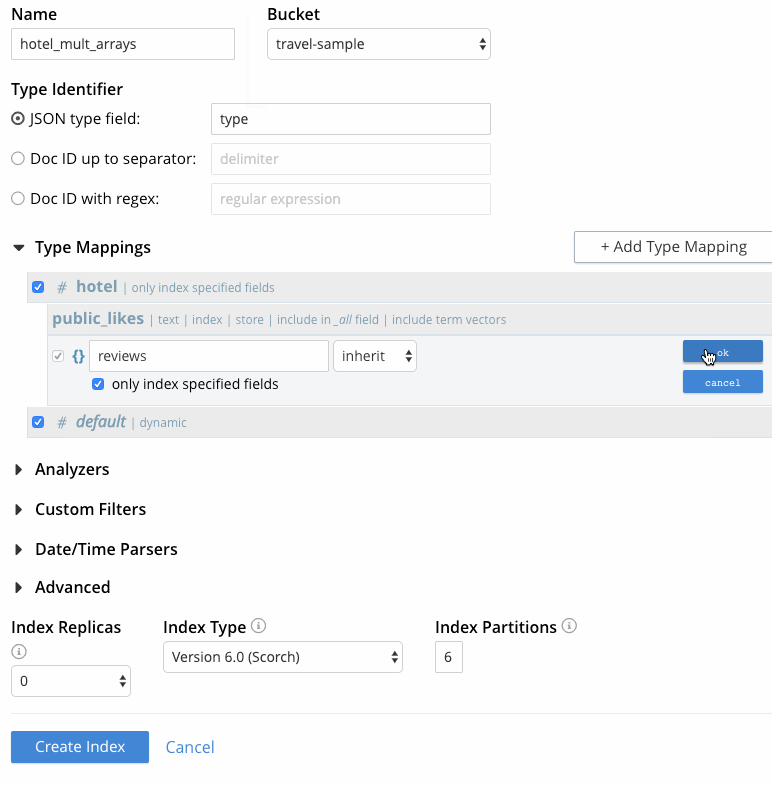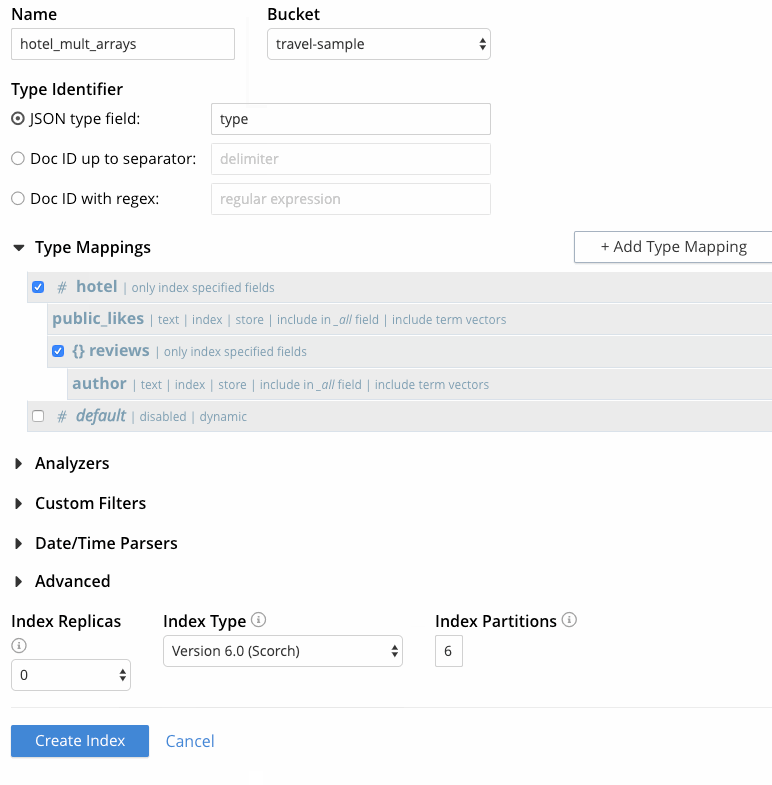
Figura 5 - Creación de un índice FTS con varias matrices
Nota: Consulte en el Apéndice la carga útil JSON utilizada para crear este índice a través de la API REST.
Pruebas de consultas sobre el índice:
- En la interfaz de búsqueda de texto completo, espere a que el progreso de indexación muestre 100% y, a continuación, haga clic en el nombre del índice "hotel_mult_arrays".
- Para buscar cualquier hotel con "me gusta" o "opiniones" de alguien llamado "Ozella", en el cuadro de texto "buscar en este índice...", introduce "Ozella" y haz clic en Buscar. No es necesario delimitar el campo de la búsqueda porque ambos campos indexados están incluidos en el campo por defecto "todos".
- Los resultados se muestran (de forma similar a la Figura 6) con la clave de cada documento coincidente y los campos coincidentes resaltados. Los ID de los documentos devueltos son los mismos que los de nuestra consulta N1QL anterior.
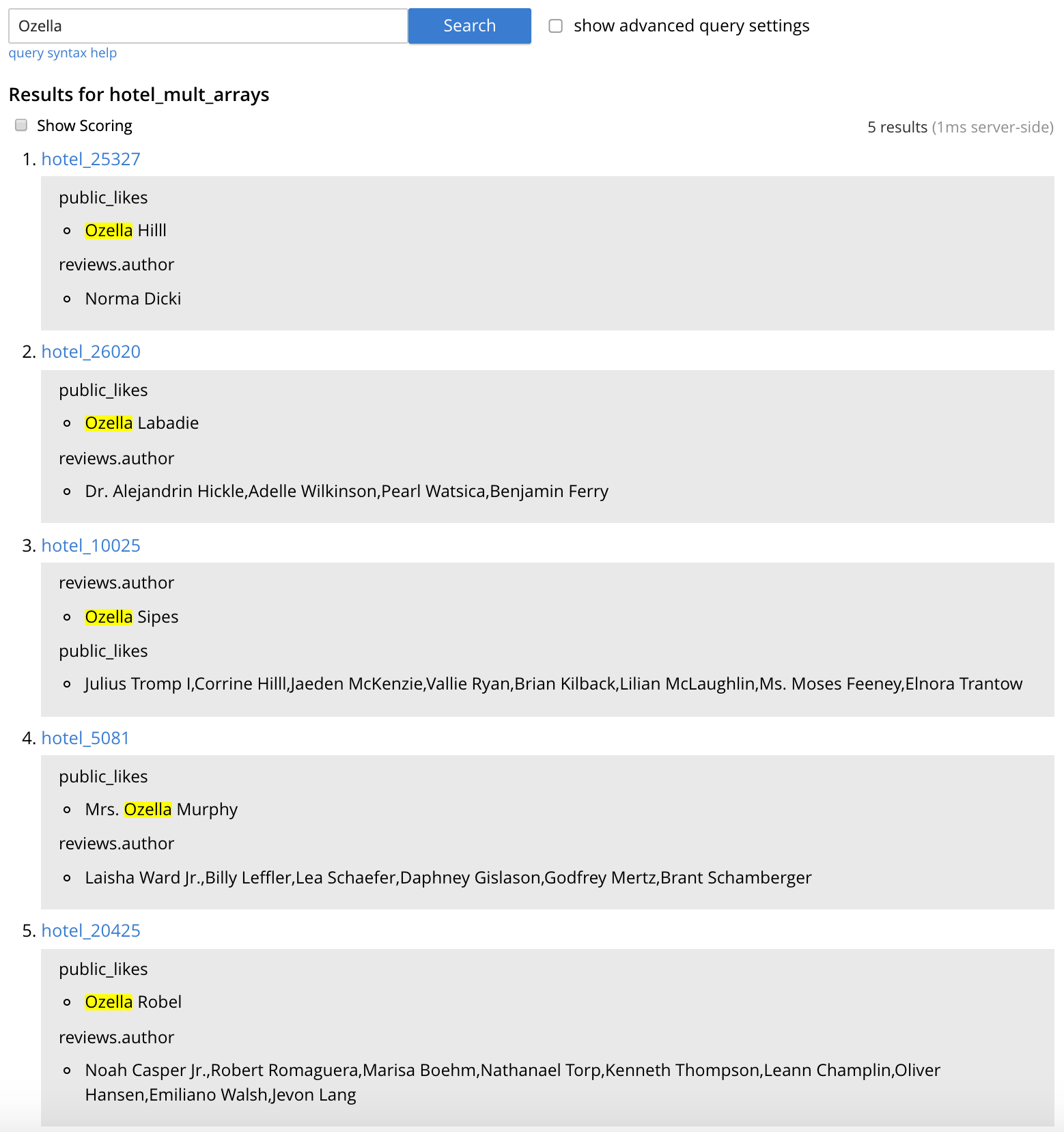
Figura 6 - Resultados de la búsqueda "hotel_mult_arrays" de "Ozella" en el índice
Este es un índice único en 2 claves de array, que, como se mencionó anteriormente, es algo que nunca se podría hacer en un índice basado en b-tree. Ahora aprovechemos este índice FTS en una consulta N1QL usando la función SEARCH(). Nuestra consulta podría verse así:
|
1 2 3 4 5 |
SELECCIONE nombre, dirección, ciudad, país, teléfono, me gusta_público, reseñas DESDE `viaje-muestra` AS t UTILICE ÍNDICE(hotel_mult_arrays USO DE FTS) DONDE t.tipo="hotel" Y BUSCAR(t, {"consulta": {"match":"Ozella"}}, {"índice":"hotel_mult_arrays"}); |
Algunas cosas a tener en cuenta sobre la consulta:
- La cláusula USE INDEX...USING FTS especifica que debe utilizarse el índice FTS en lugar de un índice GSI, por lo que esta consulta no utiliza el servicio de índices. (Documentación)
- Dado que nuestro índice FTS utiliza una asignación de tipos personalizada, la consulta debe tener el tipo coincidente especificado en la cláusula WHERE (t.type="hotel").
- El nombre del índice FTS se especifica en el campo "index" de la función SEARCH() como pista, pero es opcional, ya que la cláusula USE INDEX tiene prioridad sobre una pista proporcionada en el campo "index". (Documentación)
Utilizando el índice FTS que hemos creado, nuestra consulta N1QL se ejecuta correctamente y devuelve 5 resultados (hotel_5081, hotel_26020, hotel_10025, hotel_20425, hotel_25327) y el siguiente plan de ejecución:

Figura 7 - Plan de ejecución con índices múltiples (FTS)
Mismo plan en JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
{ "#operator": "Secuencia", "#stats": { "#phaseSwitches": 1, "execTime": "18.8µs" }, "~niños": [ { "#operator": "Autorizar", "#stats": { "#phaseSwitches": 3, "execTime": "32.1µs", "servTime": "3.421ms" }, "privilegios": { "Lista": [ { "Objetivo": "por defecto:muestra-viaje", "Priv": 7 } ] }, "~niño": { "#operator": "Secuencia", "#stats": { "#phaseSwitches": 1, "execTime": "122.8µs" }, "~niños": [ { "#operator": "IndexFtsSearch", "#stats": { "#itemsOut": 5, "#phaseSwitches": 23, "execTime": "239.3µs", "kernTime": "84.5µs", "servTime": "3.9146ms" }, "como": "t", "índice": "hotel_mult_arrays", "index_id": "7a28a8346fad6118", "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "search_info": { "campo": "\"\"", "opciones": "{\"index\": \"hotel_mult_arrays\"}", "outname": "fuera", "consulta": "{\"query\": {\"match\": \Ozella".} }, "usando": "fts", "#ime_normal": "00:00.004", "#iempo_absoluto": 0.0041539 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "334,8µs", "kernTime": "4.4328ms", "servTime": "1.5272ms" }, "como": "t", "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "#ime_normal": "00:00.001", "#iempo_absoluto": 0.001862 }, { "#operator": "Paralelo", "#stats": { "#phaseSwitches": 1, "execTime": "21.1µs" }, "copias": 2, "~niño": { "#operator": "Secuencia", "#stats": { "#phaseSwitches": 2, "execTime": "49.1µs" }, "~niños": [ { "#operator": "Filtro", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 26, "execTime": "6.8953ms", "kernTime": "14.8149ms" }, "condición": "(((`t`.`type`) = \"hotel\") and search(`t`, {\"query\": {\"match\": \Ozella", "index": \"hotel_mult_arrays\"}))", "#ime_normal": "00:00.006", "#iempo_absoluto": 0.0068953 }, { "#operator": "ProyectoInicial", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "2.3597ms", "kernTime": "20.7458ms" }, "result_terms": [ { "expr": "(`t`.`nombre`)" }, { "expr": "(`t`.`dirección`)" }, { "expr": "(`t`.`ciudad`)" }, { "expr": "(`t`.`país`)" }, { "expr": "(`t`.`phone`)" }, { "expr": "(`t`.`public_likes`)" }, { "expr": "(`t`.`reviews`)" } ], "#ime_normal": "00:00.002", "#iempo_absoluto": 0.0023597 }, { "#operator": "ProyectoFinal", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "300µs", "kernTime": "375.9µs" }, "#ime_normal": "00:00", "#iempo_absoluto": 0 } ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0000491 }, "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0000211 } ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0001228 }, "#ime_normal": "00:00.003", "#iempo_absoluto": 0.0034531 }, { "#operator": "Corriente", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "1.3409ms", "kernTime": "14.8586ms" }, "#ime_normal": "00:00.001", "#iempo_absoluto": 0.0013409 } ], "~versiones": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0000188 } |
En el cluster de un solo nodo que se utiliza para estos ejemplos, el tiempo transcurrido de la consulta es de unos 20 milisegundos para devolver los mismos 5 documentos. Como se puede ver en el plan, hay un operador IndexFtsSearch pero no hay operadores IndexScan3, DistinctScan, UnionScan o IntersectScan. La consulta global es mucho más eficiente sin estos costosos operadores GSI. El operador IndexFtsSearch envía los 5 documentos coincidentes del índice FTS al operador Fetch, que sólo obtiene esos 5 documentos. La obtención es mucho más eficiente aquí que en la consulta anterior, ya que sólo obtiene 5 documentos frente a 904. Esto también puede observarse en la comparación de los tiempos totales transcurridos (y el servTime de los operadores de obtención: 170 ms en la consulta 1 y 1,5 ms en la consulta 2) entre las consultas.
Conclusión
Con GSI puede mezclar y combinar múltiples índices de matrices en una sola consulta, pero con FTS puede mezclar y combinar múltiples matrices en un solo índice FTS (y con FTS no hay problema de clave principal como en GSI con respecto al orden de los campos en el índice). Como hemos demostrado en este sencillo ejemplo de consulta de 2 matrices en los documentos del hotel, la utilización de la nueva función SEARCH() en N1QL puede dar lugar a consultas de matrices más sencillas y eficaces. El mismo concepto podría aplicarse a las consultas que utilizan varias matrices, lo que tendría resultados aún más favorables sobre las consultas N1QL que utilizan múltiples índices de matrices GSI. Este enfoque utiliza menos recursos del sistema y proporciona un mayor rendimiento, lo que se traduce en un aumento de la eficiencia general del sistema.
Este es sólo un ejemplo de los beneficios de la integración entre N1QL y FTS, y otros beneficios están documentados en las entradas de blog en la sección de referencias a continuación.
Referencias
- Recursos de búsqueda de Couchbase: https://www.couchbase.com/products/full-text-search
- Documentación de Couchbase FTS: https://docs.couchbase.com/server/current/fts/full-text-intro.html
- Documentación de búsqueda N1QL de Couchbase: https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
- Entradas en el blog de Couchbase FTS: https://www.couchbase.com/blog/category/full-text-search/
- Formación online de Couchbase FTS: https://learn.couchbase.com/store/509465-cb121-intro-to-couchbase-full-text-search-fts
Anexo
Índice Definición JSON: hotel_mult_arrays
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
{ "#operator": "Secuencia", "#stats": { "#phaseSwitches": 1, "execTime": "18.8µs" }, "~niños": [ { "#operator": "Autorizar", "#stats": { "#phaseSwitches": 3, "execTime": "32.1µs", "servTime": "3.421ms" }, "privilegios": { "Lista": [ { "Objetivo": "por defecto:muestra-viaje", "Priv": 7 } ] }, "~niño": { "#operator": "Secuencia", "#stats": { "#phaseSwitches": 1, "execTime": "122.8µs" }, "~niños": [ { "#operator": "IndexFtsSearch", "#stats": { "#itemsOut": 5, "#phaseSwitches": 23, "execTime": "239.3µs", "kernTime": "84.5µs", "servTime": "3.9146ms" }, "como": "t", "índice": "hotel_mult_arrays", "index_id": "7a28a8346fad6118", "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "search_info": { "campo": "\"\"", "opciones": "{\"index\": \"hotel_mult_arrays\"}", "outname": "fuera", "consulta": "{\"query\": {\"match\": \Ozella".} }, "usando": "fts", "#ime_normal": "00:00.004", "#iempo_absoluto": 0.0041539 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "334,8µs", "kernTime": "4.4328ms", "servTime": "1.5272ms" }, "como": "t", "espacio clave": "viaje-muestra", "espacio de nombres": "por defecto", "#ime_normal": "00:00.001", "#iempo_absoluto": 0.001862 }, { "#operator": "Paralelo", "#stats": { "#phaseSwitches": 1, "execTime": "21.1µs" }, "copias": 2, "~niño": { "#operator": "Secuencia", "#stats": { "#phaseSwitches": 2, "execTime": "49.1µs" }, "~niños": [ { "#operator": "Filtro", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 26, "execTime": "6.8953ms", "kernTime": "14.8149ms" }, "condición": "(((`t`.`type`) = \"hotel\") and search(`t`, {\"query\": {\"match\": \Ozella", "index": \"hotel_mult_arrays\"}))", "#ime_normal": "00:00.006", "#iempo_absoluto": 0.0068953 }, { "#operator": "ProyectoInicial", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "2.3597ms", "kernTime": "20.7458ms" }, "result_terms": [ { "expr": "(`t`.`nombre`)" }, { "expr": "(`t`.`dirección`)" }, { "expr": "(`t`.`ciudad`)" }, { "expr": "(`t`.`país`)" }, { "expr": "(`t`.`phone`)" }, { "expr": "(`t`.`public_likes`)" }, { "expr": "(`t`.`reviews`)" } ], "#ime_normal": "00:00.002", "#iempo_absoluto": 0.0023597 }, { "#operator": "ProyectoFinal", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "300µs", "kernTime": "375.9µs" }, "#ime_normal": "00:00", "#iempo_absoluto": 0 } ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0000491 }, "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0000211 } ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0001228 }, "#ime_normal": "00:00.003", "#iempo_absoluto": 0.0034531 }, { "#operator": "Corriente", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "1.3409ms", "kernTime": "14.8586ms" }, "#ime_normal": "00:00.001", "#iempo_absoluto": 0.0013409 } ], "~versiones": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#ime_normal": "00:00.000", "#iempo_absoluto": 0.0000188 } |