Como mencioné en mi anterior post sobre cómo fracasar con los microserviciosdepurar un sistema distribuido es una tarea difícil. Muchas cosas pueden ir mal, y algunas de ellas están fuera de nuestro control, como la inestabilidad de la red, la falta de disponibilidad temporal, o incluso errores externos. Hoy vamos a discutir cómo se puede utilizar el patrón Event Sourcing / Event Logging para "volver atrás en el tiempo" y entender lo que salió mal.
Afortunadamente, existen multitud de herramientas para monitorizar la red y detectar y registrar eventos inesperados. Mallas de servicio son ahora una opción popular, y también puede utilizar herramientas como OpenTracing para el registro distribuido. Sin embargo, cuando hablamos de comprender el estado de nuestras entidades, no existe un marco rápido de plug-and-play.
Tus datos sobrevivirán potencialmente a tu código y, sin embargo, pasamos por alto cómo evolucionan con el tiempo. En la mayoría de los sistemas, incluso preguntas sencillas como "¿cómo llegó esta entidad a este estado?" o "¿cómo era mi estado hace un mes?" son imposibles de responder, ya que no se ha guardado ningún historial de cambios. Llevar un registro de esos cambios es crucial para un sistema sano, no sólo por motivos de seguridad o depuración, sino por su enorme valor empresarial (su Product Owner se alegrará).
La solución
Una forma excelente de añadir visibilidad a lo que está ocurriendo en tu servicio es a través de Event Sourcing | Event Logging. El concepto fundamental detrás de este patrón de 10 años de antigüedad es que cada cambio en el estado de una aplicación debe ser encapsulado en un objeto de evento y almacenado secuencialmente. Si esto te suena familiar, puede ser porque cualquier versión de sistemas de control o registros de transacciones de bases de datos es un usuario intensivo de este patrón de eventos.
Pero profundicemos para entender cómo funciona. Suponiendo que estamos construyendo un Servicio de pedidos para un comercio electrónico, veamos cómo serían el estado y los eventos de nuestra aplicación:
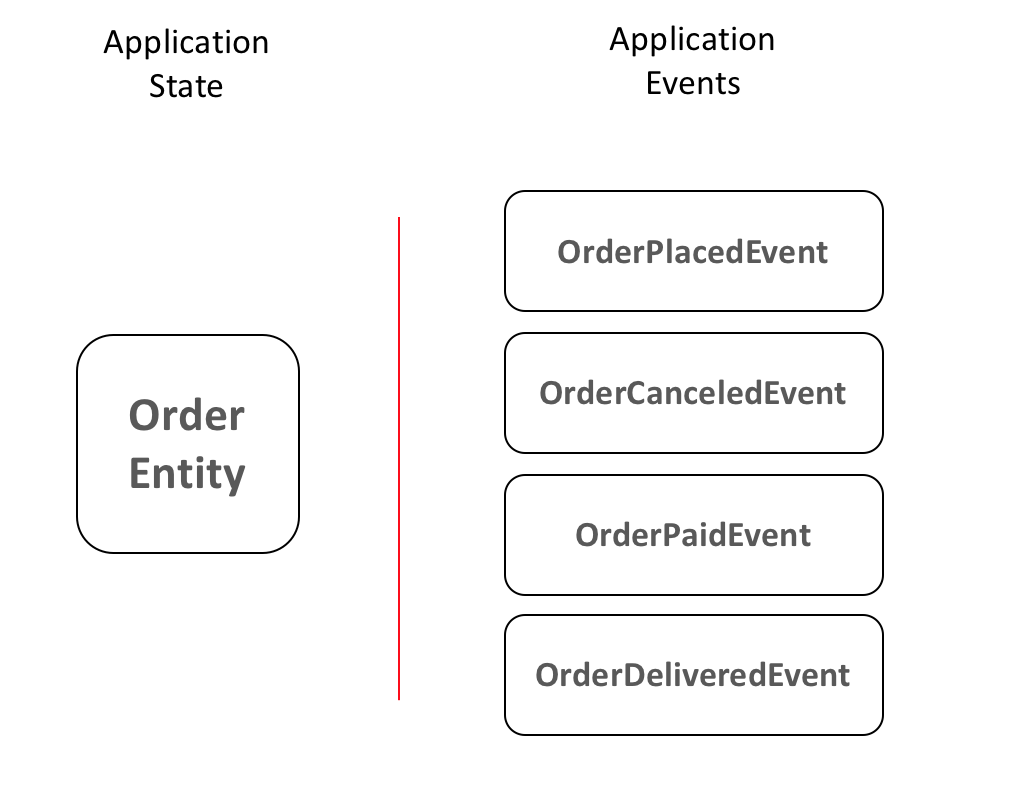
Numerosos autores definen tres reglas principales para el sistema de event sourcing/logging:
- Los acontecimientos son siempre inmutables;
- Los eventos son siempre algo que ha sucedido en el pasado. Algunos desarrolladores confunden órdenes (ej: PlaceOrder) con eventos (ej: OrderPlaced)
- En teoría, en cualquier momento se puede abandonar el estado actual y reconstruir todo el sistema con sólo volver a procesar todos los mensajes recibidos.
Otra cosa buena de este patrón es que te empuja a pensar en los eventos de tu sistema antes de pensar en cómo será la estructura real. Puede ser contraintuitivo al principio, ya que hemos aprendido a diseñar un sistema dibujando entidades y propiedades, pero está bien alineado con otra recomendación común de DDD: pensar primero en cómo se comunicarán tus servicios entre sí para identificar fácilmente dominios.
Origen de eventos | Flujo de registro de eventos
El flujo más habitual para el aprovisionamiento de eventos es similar al siguiente:
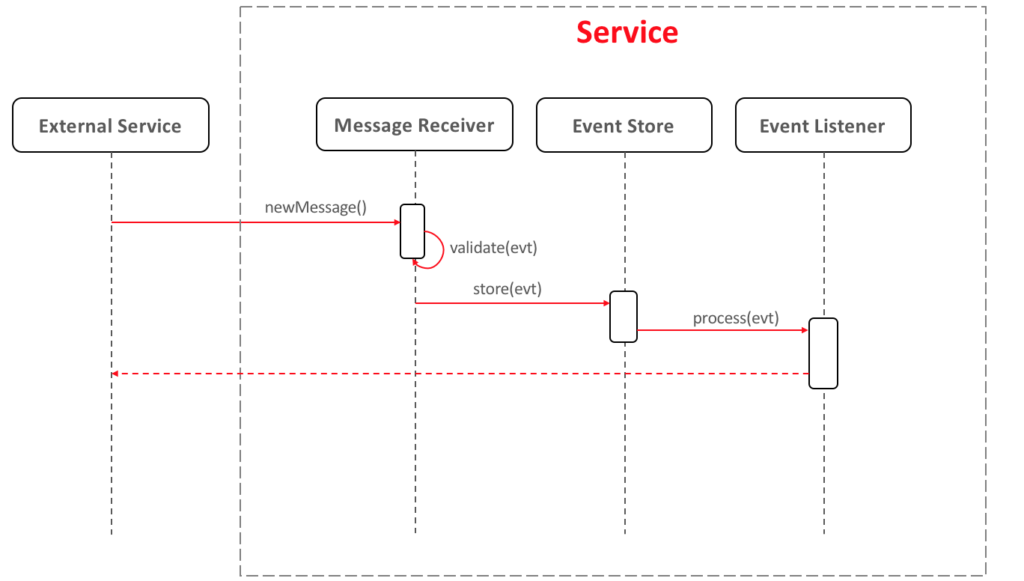
- Receptor de mensajes se encarga de convertir la solicitud entrante en un evento y validarlo.
- Tienda de eventos es responsable de almacenar los eventos secuencialmente y notificar a los oyentes.
- Escuchador de eventos: Como podrás adivinar, este es el código encargado de ejecutar la lógica de negocio correspondiente según cada tipo de evento.
Existen muchas implementaciones posibles de este patrón, una de las cuales es mediante el uso de la función Servicio de concursosintroducido en Couchbase 5.5. En resumen, te permite escribir funciones que se activan cada vez que se inserta/actualiza/elimina un documento. El mecanismo de eventos también te permite hacer rizo por lo que cada vez que un documento determinado se almacena en la base de datos, puede desencadenar un endpoint en su aplicación para procesarlo. Veamos cómo quedaría utilizando eventing:
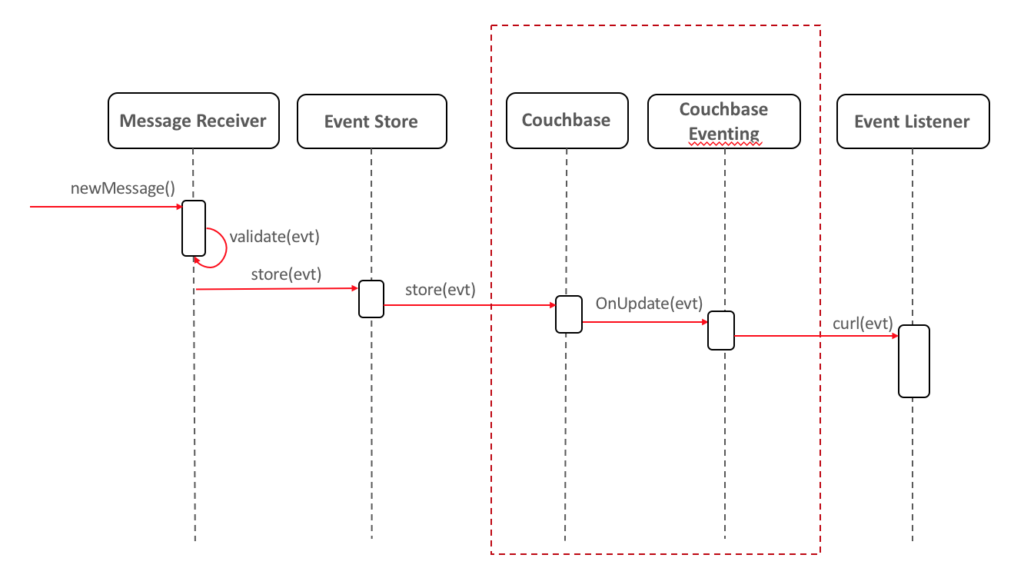
Si quiere leer más sobre el tema, consulte el documentación oficial de couchbase eventing.
Couchbase Eventing es asíncrono, por lo que la implementación anterior sólo te sirve si tu aplicación sólo recibe llamadas asíncronas. También puede actuar como una capa extra de seguridad para activar una notificación, por ejemplo, si alguien intenta actualizar un evento manualmente.
En algunos sistemas, los campos y la estructura de los eventos pueden diferir bastante entre sí, y la estructura fija de los RDBM dificulta el modelado del almacén de eventos. Por este motivo, los desarrolladores suelen almacenar sus eventos en forma de Cadena JSON en un varchar campo. Este enfoque tiene un problema importante: Hace que sus eventos sean difíciles de encontrar, ya que la mayoría de sus consultas serán lentas, complicadas y llenas de 'gustos. Una de las posibles soluciones es utilizar bases de datos de documentos, ya que la mayoría de ellas almacenan los documentos como JSON y disponen de un lenguaje similar a SQL para su consulta, como por ejemplo N1QL.
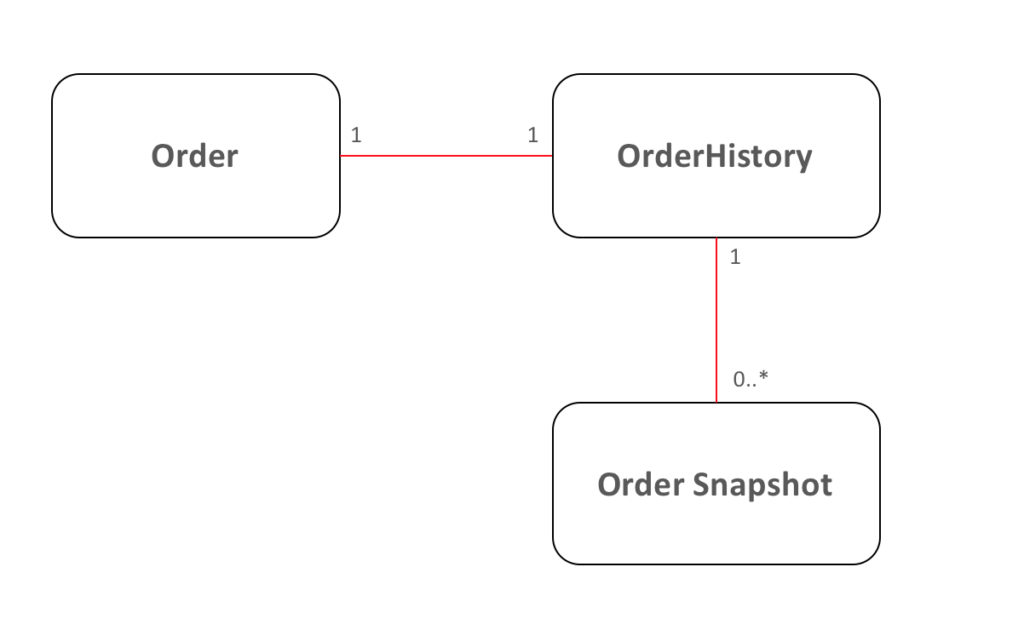
Snapshotting - Versionado a su estado
La adición de versiones/historial a su estado se denomina a veces "snapshotting" en el mundo del aprovisionamiento de eventos. Es esencial para evitar reprocesar todos los eventos siempre que necesites saber cuál era tu estado hace N días. También ayuda con la depuración, ya que puede reconocer rápidamente el punto en el tiempo en el que el estado de la aplicación es diferente de lo que se espera después de procesar un evento.
El snapshotting es útil, barato, fácil de implementar y excelente para informes temporales. Si ha decidido implementar patrones de Event Sourcing, haga un pequeño esfuerzo adicional para implementar también snapshotting.
Corregir incoherencias
Aquí es donde todos tus esfuerzos dan sus frutos. Una vez que haya implementado el registro/abastecimiento de eventos y el Snapshotting, puede utilizar una versión ligeramente modificada de la función Evento retroactivo para corregir incoherencias.
En resumen, si ha corregido un error y ahora también necesita ajustar el estado de las entidades afectadas, en lugar de actualizarlo manualmente, puede establecer el estado de su entidad al que tenía antes del error y reproducir todos los eventos relacionados desde entonces. Esto corregirá automáticamente su estado sin manual intervención.
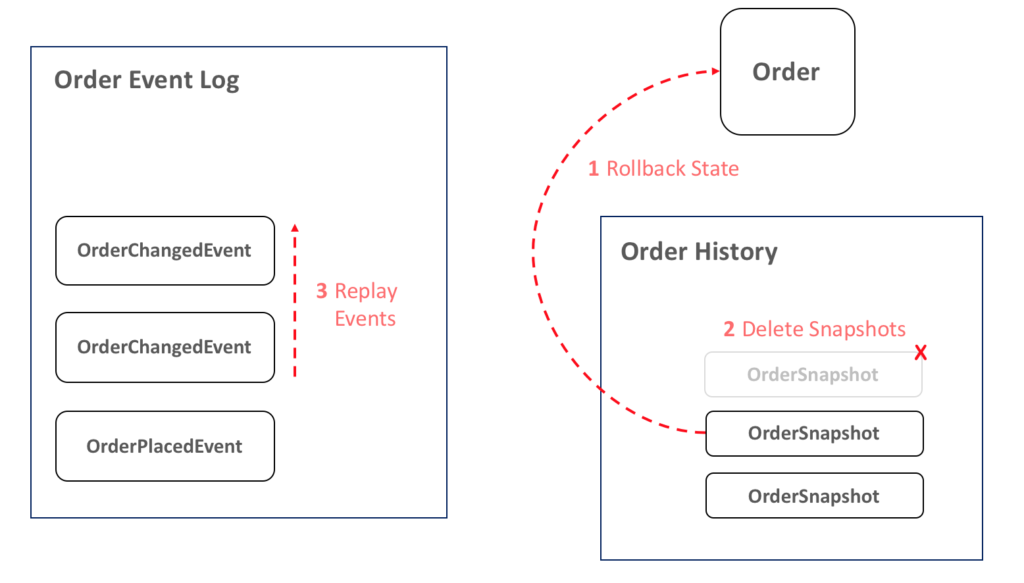
- Estado de retroceso: revierte el estado de una entidad al que tenía antes del fallo. Puede evitar Pasos 1 y 2 simplemente reprocesando todos los eventos. En este caso, sin embargo, estamos restaurando un estado anterior porque queremos evitar reprocesarlo todo.
- Ignorar instantáneas: todas las instantáneas posteriores a la restaurada deben marcarse como ignorado para evitar restaurar una instantánea inconsistente en el futuro.
- Eventos de reconstrucción: reconstruye todos los eventos desde el objetivo en adelante.
Pero, ¿y si el evento contiene datos erróneos o no debería haberse activado nunca? ¿Podemos actualizar o eliminar el evento y volver a procesarlo?
Si recuerdas, la primera regla del aprovisionamiento de eventos es que "Los eventos son siempre inmutables" y eso es por una muy buena razón; necesitas confiar en el registro que estás viendo. Pero eso no responde a nuestra pregunta; sólo la modifica ligeramente: ¿cómo podemos cambiar el registro de eventos sin cambiar el evento?
Una forma sencilla de resolver este problema es marcar los eventos como ignorable para que podamos ignorarlos durante el proceso de reconstrucción:
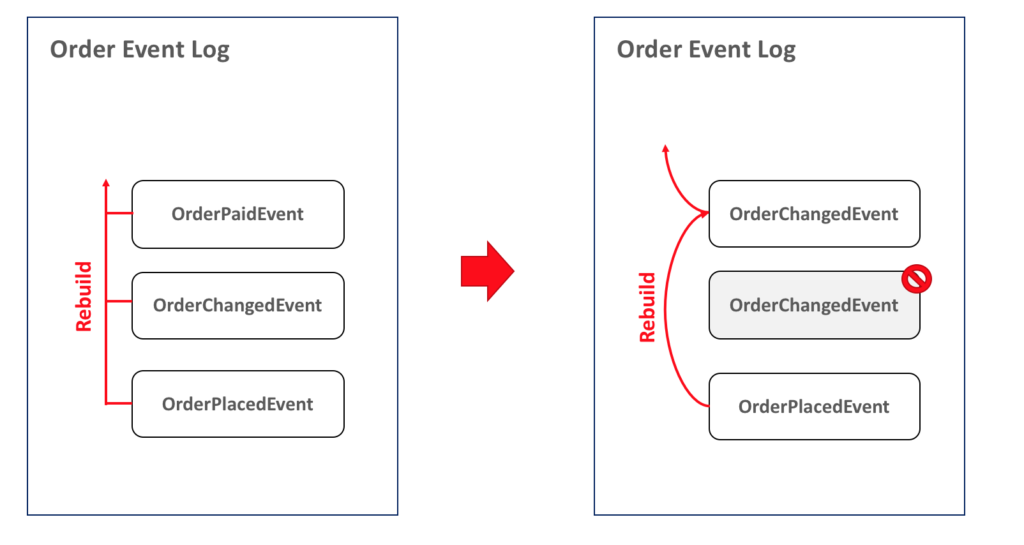
¿Qué ocurre si un evento se ha disparado con datos erróneos o en el orden equivocado? Usando este enfoque, todo lo que tenemos que hacer es marcar el evento como ignorable y añadir uno nuevo con los valores correctos o en la posición correcta, de la siguiente manera:
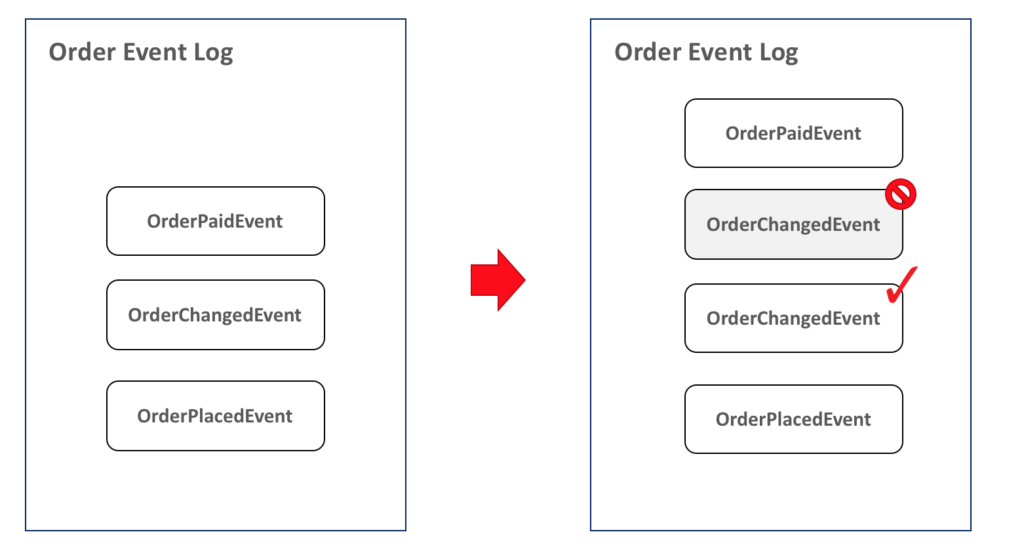
Genial, ¿verdad? Pero aquí hay una tarea extra complicada: ¿cómo podemos construir una secuencia de eventos que permita añadir eventos en el medio?
Una solución ingenua es añadir un contador flotante para cada entidad. Te permitirá añadir elementos en el medio infinitamente según la teoría de supertareas (en la práctica, estás limitado por el tamaño máximo float/double), que normalmente es espacio más que suficiente para añadir todos los eventos necesarios para fijar tu estado:
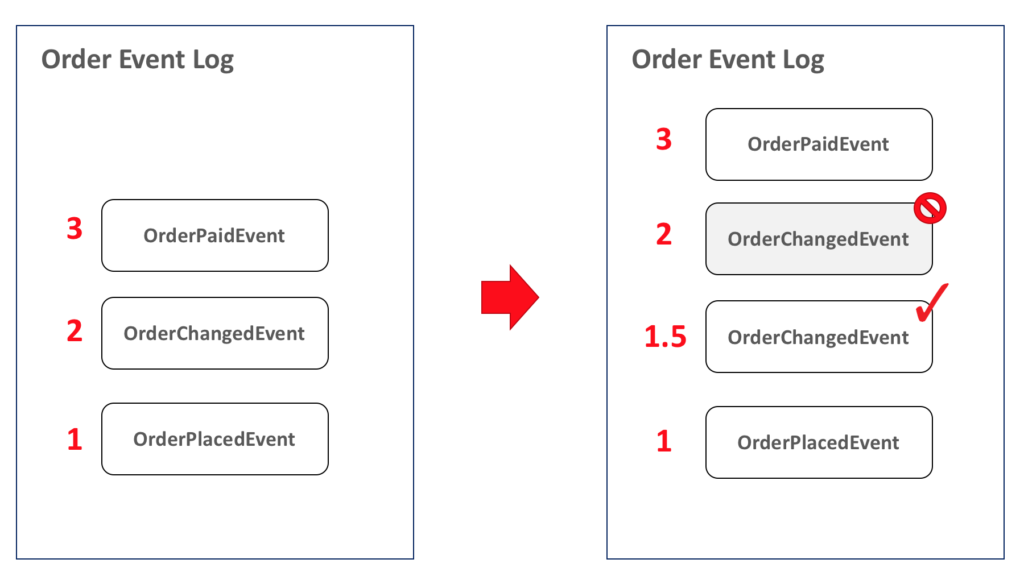
Por supuesto, el enfoque anterior tiene un montón de defectos, pero es ridículamente simple de implementar, fácil de consultar, y funciona bastante bien para la mayoría de los casos. Si necesitas construir una estructura más robusta, considera almacenar tus eventos en una estructura de Lista Enlazada:
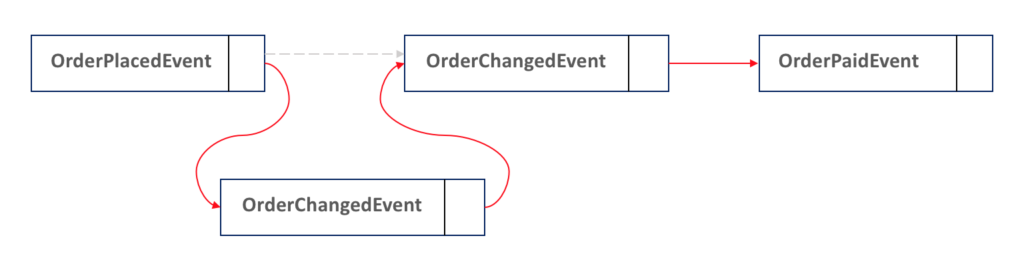
¿Qué pasa con los sistemas externos y otros microservicios?
Un microservicio no es una isla, así que es razonable pensar que uno de los efectos secundarios de reproducir eventos es que tu servicio puede enviar mensajes a otros externos. Esos mensajes podrían desencadenar incoherencias o propagar errores en otros sistemas, lo que potencialmente puede empeorar la situación.
Desgraciadamente, debido a la variedad de posibilidades, no existe una solución milagrosa para resolver este problema, y cada caso debe tratarse individualmente. Algunas de las soluciones convencionales son:
- Cambiar la configuración temporalmente para no enviar ningún mensaje externo o añadir un interceptor que permita configurar qué mensajes deben enviarse;
- Redirigir peticiones específicas a un servicio falso (un escenario típico si está utilizando el patrón Service Mesh).
- Permitir que otros servicios reconozcan que una determinada operación ya se ha ejecutado en el pasado con los mismos parámetros, y entonces, en lugar de lanzar un error, simplemente devolver el mismo mensaje de éxito que antes.
Naturalmente, hay un número considerable de casos en los que no podrá corregir las incoherencias externas de forma automática, en este escenario se espera de otros sistemas que impriman un error legible por humanos y/o activen una notificación para que alguien intervenga.
Ventajas de la contratación de eventos
Aunque se trata de un patrón sencillo, tiene muchas ventajas:
- El registro de sucesos tiene un gran valor empresarial;
- Funciona bastante bien con DDD y arquitecturas basadas en eventos.
- Audición del origen de todos los cambios en el estado de su aplicación;
- Permite reproducir los eventos fallidos;
- Fácil depuración, ya que puedes copiar todos los eventos de una entidad de destino a tu máquina y depurar cada evento para entender cómo la aplicación alcanzó un estado específico (ignora las implicaciones de seguridad de copiar datos de producción);
- Permite utilizar el Evento retroactivo patrón para reconstruir/arreglar su estado.
Muchos autores también incluyen como ventaja la capacidad de realizar consultas temporales, pero considero que la consulta de múltiples eventos posteriores no es una tarea trivial. Por lo tanto, suelo percibir la consultas temporales como ventaja del patrón de instantáneas.
Inconvenientes de la contratación de eventos
- Es un poco menos intuitivo trabajar con llamadas síncronas, ya que primero tendrás que transformar la petición en un evento.
- Cada vez que implante un cambio de última hora, se verá obligado a migrar también su historial de eventos si quiere ser compatible con versiones anteriores (también conocido como actualización de eventos).
- Algunas implementaciones podrían necesitar un trabajo extra para comprobar el estado de los últimos eventos y asegurarse de que todos ellos han sido procesados.
- Los eventos pueden contener datos privados, así que no olvides asegurarte de que tu registro de eventos está debidamente protegido.
Conclusión
He mostrado una versión ligeramente modificada del patrón Event Sourcing / Event Logging que me ha funcionado bien en los últimos años. La primera vez que oí hablar de él fue hace casi 10 años en el famosa entrada en el blog de Martin Fowler (de lectura obligada). Desde entonces, me ha ayudado mucho a que el estado de mis microservicios sea casi inquebrantable, por no hablar de todas las capacidades de generación de informes.
Sin embargo, no es algo que deba utilizarse indiscriminadamente en todos sus servicios. Personalmente, creo que sólo los más importantes merecen la pena. Probablemente no necesites guardar el historial de todas las veces que el usuario ha cambiado su propio nombre en el sistema, por ejemplo.
Si tiene alguna pregunta, no dude en tuitearme en @deniswsrosa
Buen artículo con consejos muy útiles, Denis.
He utilizado Couchbase como almacén de eventos y puedo ver cómo el Servicio de Eventos simplificará la creación de instantáneas y ayudará con las tareas de limpieza y mantenimiento del almacén de eventos. Pero incluso sin snapshots, recuperar y reproducir eventos es muy rápido con Couchbase.