Aparte de todas las discusiones recientes sobre Kubernetes y si deberías Dockerizar tu base de datos o no, hoy me gustaría mostrarte por qué esas dos cosas podrían ser buenas soluciones cuando la escalabilidad y la elasticidad son un gran requisito en tu arquitectura.
La salsa secreta es sencilla: Spring Boot con Kubernetes para desplegar tanto su aplicación como su base de datos utilizando NoSQL.
¿Por qué NoSQL y Spring Data?
Con las bases de datos de documentos, puede evitar muchas uniones innecesarias, ya que toda la estructura se almacena en un único documento. Por tanto, su rendimiento será más rápido que el de un modelo relacional a medida que crezcan los datos.
Si estás utilizando alguno de los lenguajes JVM, Spring Data y Spring Boot pueden ser algo bastante familiar para ti. Así, puedes empezar rápidamente con NoSQL incluso sin ningún conocimiento previo.
¿Por qué Kubernetes?
Kubernetes (K8s) le permite escalar hacia arriba y hacia abajo su aplicación sin estado en un entorno agnóstico de nube. En las últimas versiones, K8s también ha añadido la capacidad de ejecutar aplicaciones con estado, como bases de datos, que es una de las (muchas) razones por las que es un tema tan candente hoy en día.
He mostrado en mi anterior entrada en el blog cómo desplegar Couchbase en K8s y cómo hacerlo "elástico" escalando fácilmente hacia arriba y hacia abajo. Si aún no lo has leído, dedica unos minutos extra a leer la transcripción del vídeo, ya que es una parte importante de lo que vamos a hablar aquí.
Creación de un microservicio de perfil de usuario
En la mayoría de los sistemas, el usuario (y todas las entidades relacionadas) es el dato al que se accede con más frecuencia. En consecuencia, es una de las primeras partes del sistema que tiene que pasar por algún tipo de optimización a medida que sus datos crecen.
Añadir una capa de Caché es el primer tipo de optimización que se nos ocurre. Sin embargo, todavía no es la "solución final". Las cosas podrían complicarse un poco más si tienes miles de usuarios, o si necesitas almacenar entidades relacionadas con los usuarios también en memoria.
La gestión de cantidades masivas de perfiles de usuario es una buena opción para las bases de datos documentales. Basta con echar un vistazo a la Caso práctico de Pokémon Gopor ejemplo. Por lo tanto, la creación de un servicio de perfil de usuario altamente escalable y elástico parece ser un reto lo suficientemente bueno como para demostrar cómo diseñar un microservicio altamente escalable.
Lo que vas a necesitar:
- Couchbase
- JDK y el plugin de Lombok para Eclipse o Intellij
- Maven
- Un clúster Kubernetes - Estoy ejecutando este ejemplo en 3 nodos en AWS (no recomiendo usar minikube). Si no sabes cómo configurar uno, mira esto vídeo.
El Código
Puede clonar el proyecto completo aquí:
|
1 |
https://github.com/couchbaselabs/kubernetes-starter-kit |
Empecemos creando nuestra entidad principal llamada Usuario:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
@Document @Data @AllArgsConstructor @NoArgsConstructor @EqualsAndHashCode public class User extends BasicEntity { @NotNull @Id private String id; @NotNull @Field private String name; @Field private Address address; @Field private List<Preference> preferences = new ArrayList<>(); @Field private List<String> securityRoles = new ArrayList<>(); } |
En esta entidad tenemos dos propiedades importantes:
- securityRoles: Todos los roles que el usuario puede desempeñar dentro del sistema.
- preferencias: Todas las posibles preferencias que pueda tener el usuario, como idioma, notificaciones, moneda, etc.
Ahora, vamos a jugar un poco con nuestro Repositorio. Como estamos usando Spring Data, puedes usar casi todas sus capacidades aquí:
|
1 2 3 4 5 |
@N1qlPrimaryIndexed @ViewIndexed(designDoc = "user") public interface UserRepository extends CouchbasePagingAndSortingRepository<User, String> { List<User> findByName(String name); } |
Si quieres saber más sobre Couchbase y Spring Data, consulte este tutorial.
También aplicamos otros dos métodos:
|
1 2 3 4 5 6 |
@Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and ANY preference IN " + " preferences SATISFIES preference.name = $1 END") List<User> findUsersByPreferenceName(String name); @Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and meta().id = $1 and ARRAY_CONTAINS(securityRoles, $2)") User hasRole(String userId, String role); |
- hasRole: Comprueba si un usuario tiene un rol especificado:
- findUsersByPreferencyName: Como su nombre indica, busca todos los usuarios que contienen una preferencia determinada.
Observe que estamos utilizando la sintaxis N1QL en el código anterior, ya que hace que las cosas sean mucho más sencillas de consultar que utilizando JQL simple.
Además, puede ejecutar todas las pruebas para asegurarse de que todo funciona correctamente:
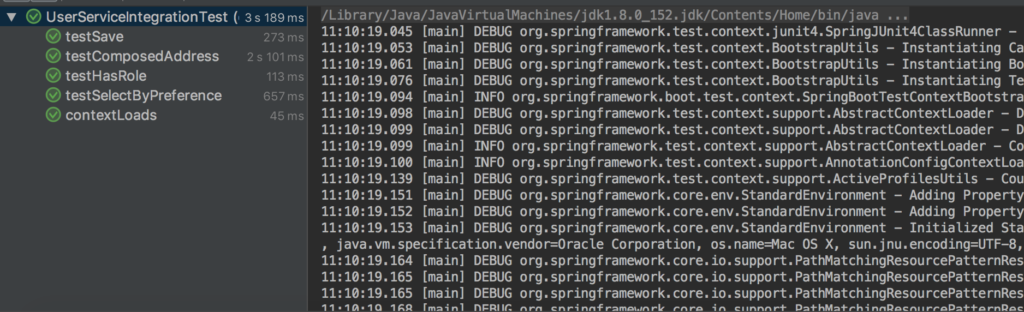
No olvides cambiar tu application.properties con las credenciales correctas de tu base de datos:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=localhost spring.couchbase.bucket.name=test spring.couchbase.bucket.password=couchbase spring.data.couchbase.auto-index=true |
Para probar nuestro microservicio, he añadido algunos puntos finales Restful:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
@RestController @RequestMapping("/api/user") public class UserServiceController { @Autowired private UserService userService; @RequestMapping(value = "/{id}", method = GET, produces = APPLICATION_JSON_VALUE) public User findById(@PathParam("id") String id) { return userService.findById(id); } @RequestMapping(value = "/preference", method = GET, produces = APPLICATION_JSON_VALUE) public List<User> findPreference(@RequestParam("name") String name) { return userService.findUsersByPreferenceName(name); } @RequestMapping(value = "/find", method = GET, produces = APPLICATION_JSON_VALUE) public List<User> findUserByName(@RequestParam("name") String name) { return userService.findByName(name); } @RequestMapping(value = "/save", method = POST, produces = APPLICATION_JSON_VALUE) public User findUserByName(@RequestBody User user) { return userService.save(user); } } |
Dockerización de microservicios
En primer lugar, cambie su aplicación.propiedades para obtener las credenciales de conexión de las variables de entorno:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=${COUCHBASE_HOST} spring.couchbase.bucket.name=${COUCHBASE_BUCKET} spring.couchbase.bucket.password=${COUCHBASE_PASSWORD} spring.data.couchbase.auto-index=true |
Y ahora podemos crear nuestro Dockerfile:
|
1 2 3 4 5 6 |
FROM openjdk:8-jdk-alpine VOLUME /tmp MAINTAINER Denis Rosa <denis.rosa@couchbase.com> ARG JAR_FILE ADD ${JAR_FILE} app.jar ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"] |
A continuación, construimos y publicamos nuestra imagen en Docker Hub:
- Crea tu imagen:
|
1 |
./mvnw install dockerfile:build -DskipTests |
- Inicie sesión en Docker Hub desde la línea de comandos
|
1 |
docker login |

- Tomemos el imageId de nuestra imagen recién creada:
1docker images

- Crea tu nueva etiqueta utilizando el imageId:
|
1 2 |
//docker tag YOUR_IMAGE_ID YOUR_USER/REPO_NAME docker tag 3f9db98544bd deniswsrosa/kubernetes-starter-kit |
- Por último, empuja tu imagen:
1docker push deniswsrosa/kubernetes-starter-kit
 Tu imagen debería estar ahora disponible en Docker Hub:
Tu imagen debería estar ahora disponible en Docker Hub:

Configurar la base de datos
Escribí un artículo entero sobre ello aquípero para ser breves. Simplemente ejecute los siguientes comandos dentro del directorio kubernetes.
|
1 2 3 4 |
./rbac/cluster_role.sh kubectl create -f secret.yaml kubectl create -f operator.yaml kubectl create -f couchbase-cluster.yaml |
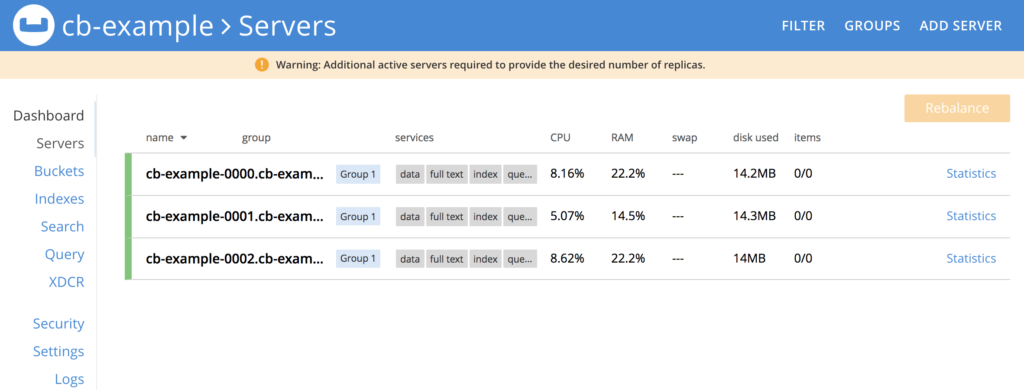
Después de un rato, las 3 instancias de nuestra base de datos deberían estar funcionando:

Reenviemos el puerto de la Consola Web a nuestra máquina local:
|
1 |
kubectl port-forward cb-example-0000 8091:8091 |
Y ahora podemos acceder a la consola web en https://localhost:8091. Puede iniciar sesión con el nombre de usuario Administrador y la contraseña contraseña
Ir a Seguridad -> AÑADIR USUARIO con las siguientes propiedades:
- Nombre de usuario: couchbase-sample
- Nombre completo: couchbase-sample
- Contraseña: couchbase-sample
- Verifica la contraseña: couchbase-sample
- Funciones: Según la imagen siguiente:
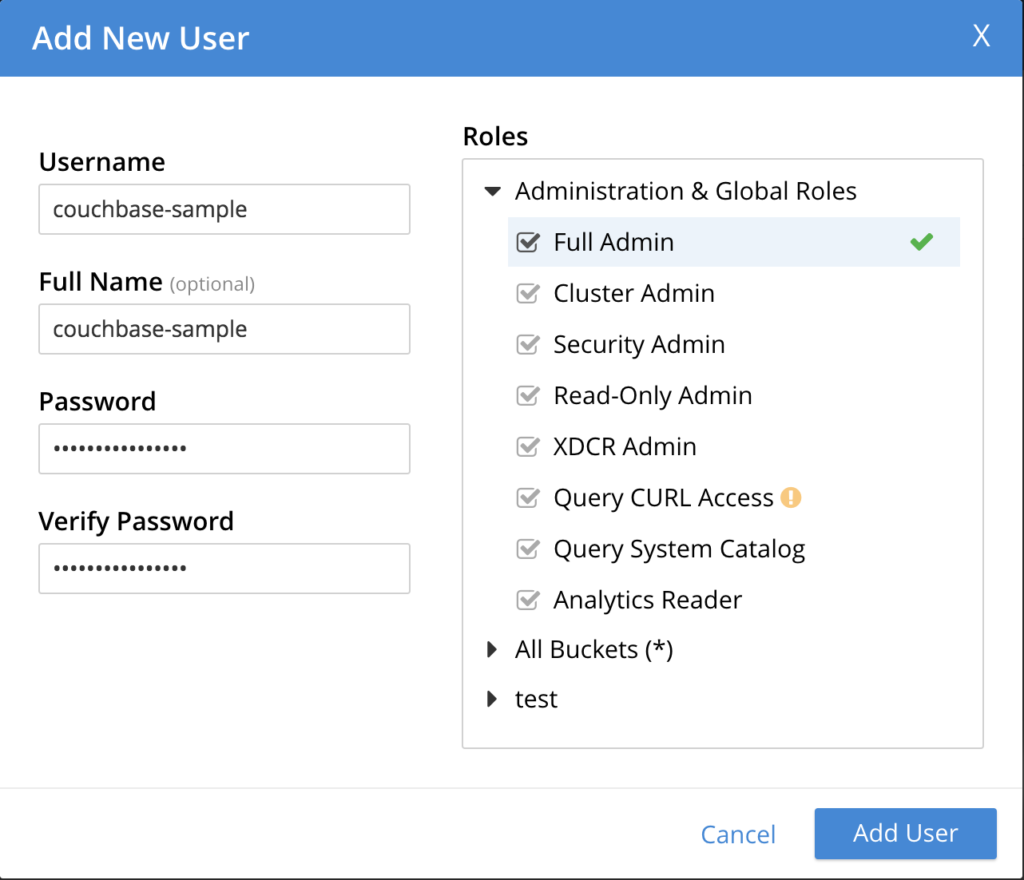
OBS: En un entorno de producción, por favor, no agregue su aplicación como un administrador
Despliegue del microservicio
En primer lugar, vamos a crear un secreto de Kubernetes donde almacenaremos la contraseña para conectarnos a nuestra base de datos:
|
1 2 3 4 5 6 7 |
apiVersion: v1 kind: Secret metadata: name: spring-boot-app-secret type: Opaque data: bucket_password: Y291Y2hiYXNlLXNhbXBsZQ== #couchbase-sample in base64 |
Ejecute el siguiente comando para crear el secreto:
|
1 |
kubectl create -f spring-boot-app-secret.yaml |
El expediente spring-boot-app.yaml es el responsable de desplegar nuestra aplicación. Echemos un vistazo a su contenido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
apiVersion: apps/v1beta1 kind: Deployment metadata: name: spring-boot-deployment spec: selector: matchLabels: app: spring-boot-app replicas: 2 # tells deployment to run 2 pods matching the template template: # create pods using pod definition in this template metadata: labels: app: spring-boot-app spec: containers: - name: spring-boot-app image: deniswsrosa/kubernetes-starter-kit imagePullPolicy: Always ports: - containerPort: 8080 name: server - containerPort: 8081 name: management env: - name: COUCHBASE_PASSWORD valueFrom: secretKeyRef: name: spring-boot-app-secret key: bucket_password - name: COUCHBASE_BUCKET value: couchbase-sample - name: COUCHBASE_HOST value: cb-example |
Me gustaría destacar algunas partes importantes de este expediente:
- réplicas: 2 -> Kubernetes lanzará 2 instancias de nuestra aplicación
- imagen: deniswsrosa/kubernetes-starter-kit -> La imagen docker que hemos creado antes.
- contenedores: nombre: -> Aquí es donde definimos el nombre del contenedor que ejecuta nuestra aplicación. Utilizarás este nombre en Kubernetes siempre que quieras definir cuántas instancias deben ejecutarse, estrategias de autoescalado, equilibrio de carga, etc.
- env: -> Aquí es donde definimos las variables de entorno de nuestra aplicación. Ten en cuenta que también estamos haciendo referencia al secreto que creamos antes.
Ejecute el siguiente comando para desplegar nuestra aplicación:
|
1 |
kubectl create -f spring-boot-app.yaml |
En unos segundos, observará que las dos instancias de su aplicación ya se están ejecutando:
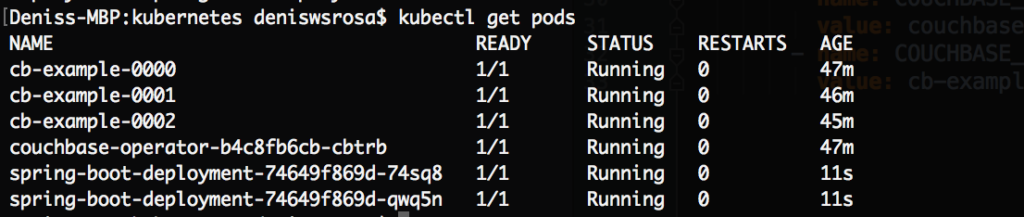
Por último, expongamos nuestro microservicio al mundo exterior. Hay docenas de posibilidades diferentes de cómo se puede hacer. En nuestro caso, vamos a crear simplemente un Load Balancer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: Service metadata: name: spring-boot-load-balancer spec: ports: - port: 8080 targetPort: 8080 name: http - port: 8081 targetPort: 8081 name: management selector: app: spring-boot-app type: LoadBalancer |
El selector es una de las partes más importantes del archivo anterior. Es donde definimos los contenedores a los que se redirigirá el tráfico. En este caso, sólo estamos apuntando a la aplicación que hemos desplegado antes.
Ejecute el siguiente comando para crear nuestro equilibrador de carga:
|
1 |
kubectl create -f spring-boot-load-balancer.yaml |
El balanceador de carga tardará unos minutos en estar levantado y redirigiendo tráfico a nuestros pods. Puede ejecutar el siguiente comando para comprobar su estado:
|
1 |
kubectl describe service spring-boot-load-balancer |
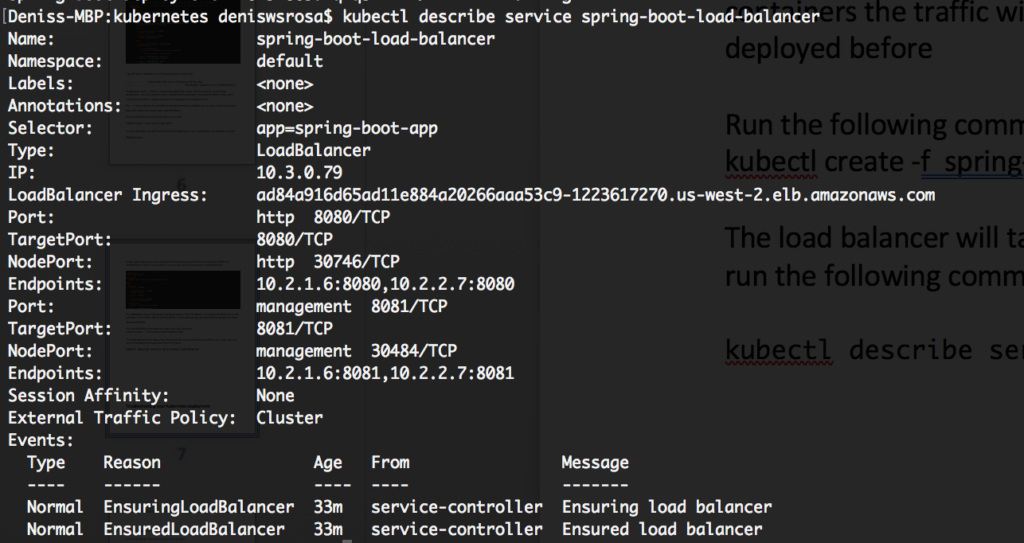
Como puede ver en la imagen anterior, nuestro Load Balancer es accesible en ad84a916d65ad11e884a20266aaa53c9-1223617270.us-west-2.elb.amazonaws.com, y el targetPort 8080 redirigirá el tráfico a dos endpoints: 10.2.1.6:8080 y 10.2.2.7:8080
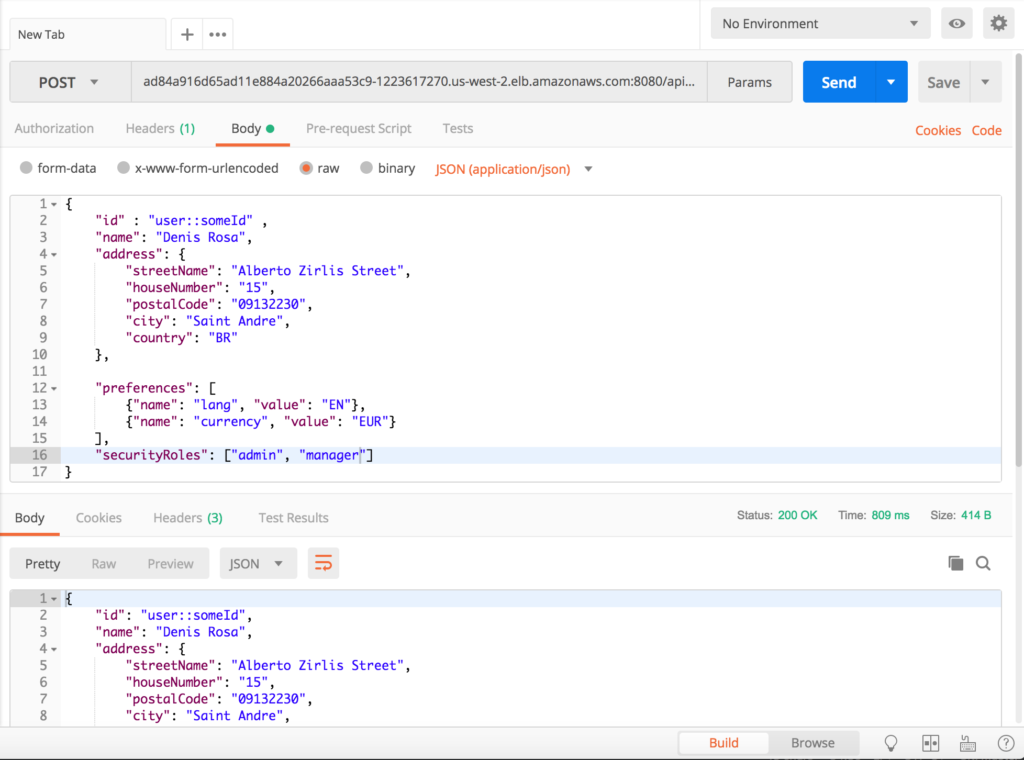
Por último, podemos acceder a nuestra aplicación y empezar a enviarle peticiones:
- Insertar un nuevo usuario:
- Búsqueda de usuarios:
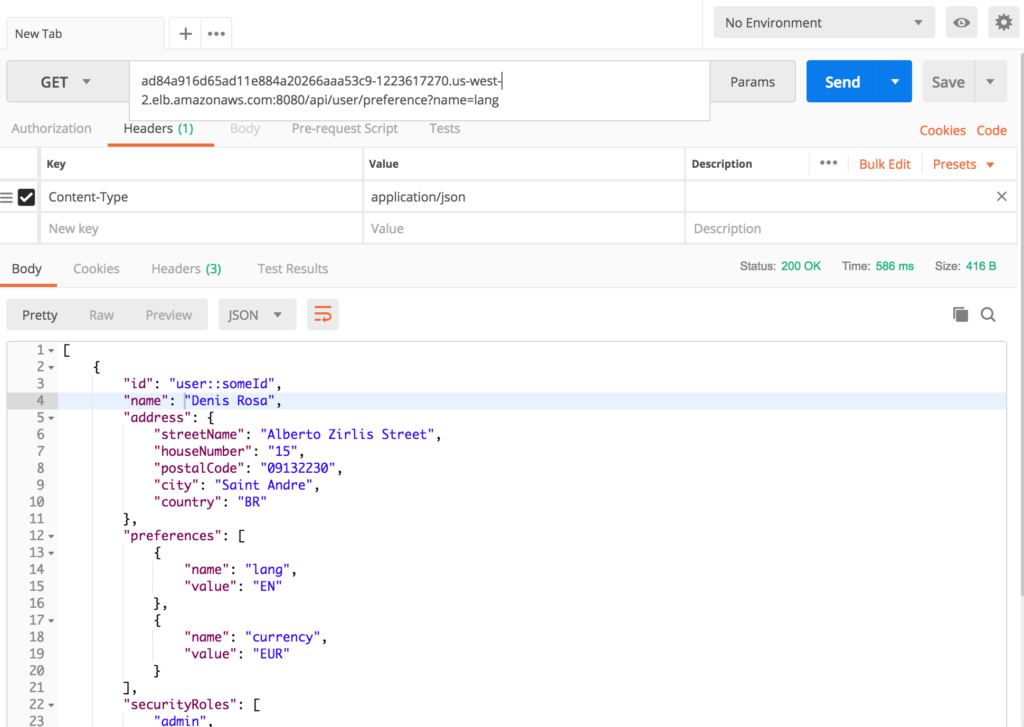
¿Qué hay de ser elástico?
Aquí es donde las cosas se ponen realmente interesantes. ¿Y si necesitamos escalar todo nuestro microservicio? Digamos que se acerca el Black Friday y necesitamos preparar nuestra infraestructura para soportar este flujo masivo de usuarios que llegan a nuestra web. Bien, ese es un problema fácil de resolver:
- Para ampliar nuestra aplicación, sólo tenemos que cambiar el número de réplicas en el archivo spring-boot-app.yaml archivo.
12345678910...spec:selector:matchLabels:app: spring-boot-appreplicas: 6 # tells deployment to run 6 pods matching the templatetemplate: # create pods using pod definition in this templatemetadata:labels:...
Y luego, ejecute el siguiente comando:
|
1 |
kubectl replace -f spring-boot-app.yaml |
¿Falta algo? Sí. ¿Y nuestra base de datos? Deberíamos ampliarla también:
- Cambie el atributo de tamaño en el couchbase-cluster.yaml file:
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: false servers: - size: 6 name: all_services services: - data - index ... |
Por último, ejecute el siguiente comando:
|
1 |
kubectl replace -f couchbase-cluster.yaml |
¿Cómo puedo reducirlo?
Reducir la escala es tan fácil como aumentarla; sólo tiene que cambiar ambos couchbase-cluster.yaml y spring-boot-app.yaml:
- couchbase-cluster.yaml
|
1 2 3 4 5 6 7 8 9 |
... enableIndexReplica: false servers: - size: 1 name: all_services services: - data - index ... |
- spring-boot-app.yaml:
|
1 2 3 4 5 6 7 8 9 10 |
... spec: selector: matchLabels: app: spring-boot-app replicas: 1 template: metadata: labels: ... |
Y ejecuta los siguientes comandos:
|
1 2 |
kubectl replace -f couchbase-cluster.yaml kubectl replace -f spring-boot-app.yaml |
Autoescalado de microservicios en Kubernetes
Profundizaré en este tema en la parte 2 de este artículo. Mientras tanto, puedes ver este vídeo sobre el autoescalado de pods.
Resolución de problemas en la implantación de Kubernetes
Si sus Pods no se inician, hay muchas formas de solucionar el problema. En el siguiente caso, ambas aplicaciones no se iniciaron:
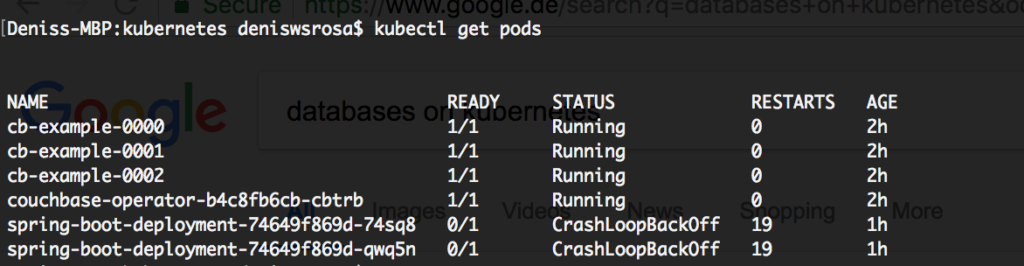
Puesto que forman parte del despliegue, vamos a describir el despliegue para intentar comprender lo que está ocurriendo:
|
1 |
kubectl describe deployment spring-boot-deployment |
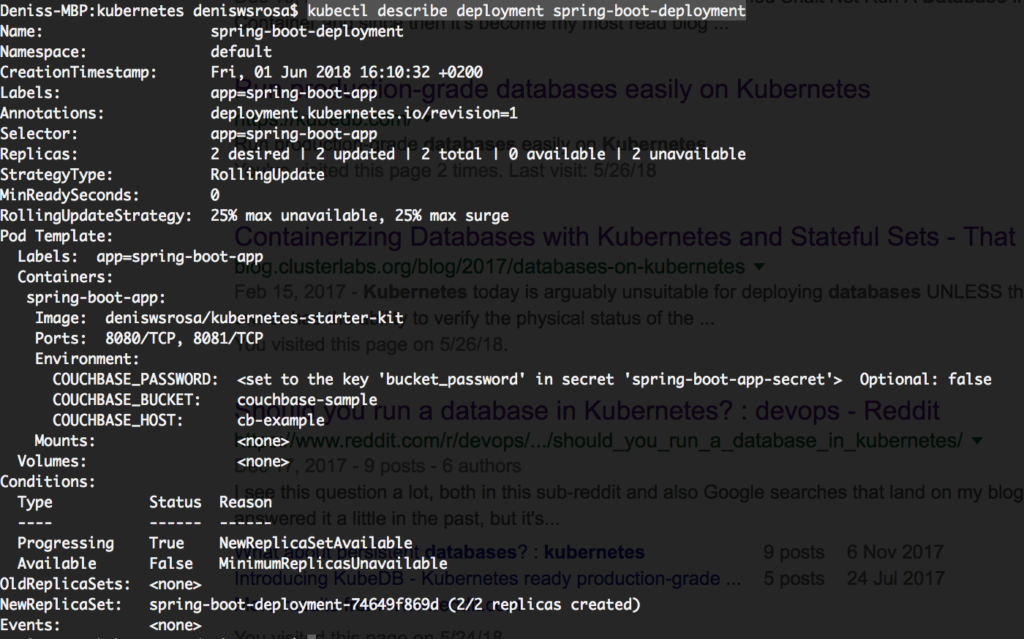
Bueno, nada es realmente relevante en este caso. Veamos entonces uno de los registros de la cápsula:
|
1 |
kubectl log spring-boot-deployment-74649f869d-74sq8 |
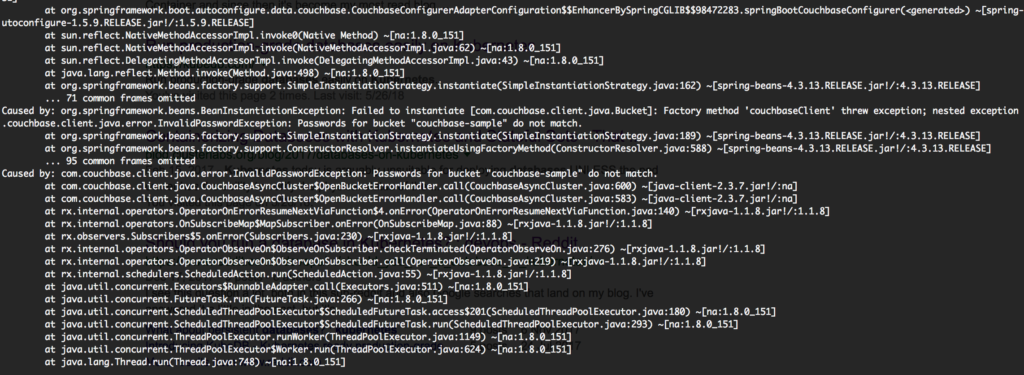
¡Te pillé! La aplicación no arrancó porque olvidamos crear el usuario en Couchbase. Con sólo crear el usuario, los pods arrancarán en unos segundos:
Conclusión
Las bases de datos son aplicaciones con estado, y escalarlas no es tan rápido como escalar las que no tienen estado (y probablemente nunca lo será), pero si necesitas hacer una arquitectura verdaderamente elástica, deberías planear escalar todos los componentes de tu infraestructura. De lo contrario, sólo estarás creando un cuello de botella en otro lugar.
En este artículo, he tratado de mostrar sólo una pequeña introducción acerca de cómo usted puede hacer su aplicación y base de datos en Kubernetes elástica. Sin embargo, todavía no es una arquitectura lista para producción. Hay un montón de otras cosas a considerar todavía, y voy a abordar algunos de ellos en los próximos artículos.
Mientras tanto, si tienes alguna pregunta, envíame un tweet a @deniswsrosa o deje un comentario a continuación.