Cada punto de referencia plantea algunas preguntas y responde otras. Así que con cada punto de referencia, es necesario tamizar a través de los datos para obtener la primicia completa. He estado haciendo benchmarking durante un tiempo, empezando en la era TPC con las guerras de benchmark y no aquí en Couchbase, donde impulsamos el rendimiento en profundidad en el producto a través de benchmarks internos y externos con muchos de nuestros clientes y socios.
Espero que algunos de vosotros ya hayáis visto los resultados del benchmark de Avalon comparando MongoDB 3.2 y Couchbase Server 4.5. Podéis encontrar la divulgación completa aquí. Voy a profundizar en algunos detalles del benchmark e intentar explicar por qué Couchbase Server es más rápido tanto en la ejecución de consultas (YCSB Workload E) como en el acceso a valores clave (YCSB Workload A). Bien, vamos a desmenuzar los resultados:
Carga de trabajo E: Consulta de conversaciones hilvanadas
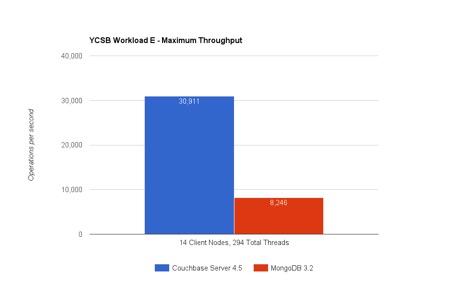
Carga de trabajo E en YCSB simula una conversación hilada y el objetivo es recuperar lo más rápido posible una consulta de rango que busca ~50 conversaciones (ítems). También hay una ligera carga de trabajo de inserción que acompaña a la consulta (%5 de las operaciones son INSERT). Así que ¿Cómo es que Couchbase Server es capaz de ejecutar >3.7 veces más consultas/seg vs MongoDB?
#1 Ejecución de consultas con índices globales en Couchbase Server
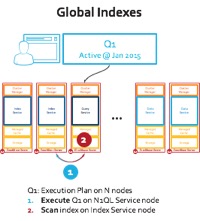
La distribución (sharding) tanto de Couchbase como de MongoDB permite que los datos se distribuyan uniformemente entre los nodos. Cada nodo toma una porción igual del total de elementos. Esta prueba tiene 150 millones de elementos distribuidos en 9 nodos. La consulta de escaneo de rango de la carga de trabajo E opera sobre un índice. Los índices de MongoDB particionan para alinearse con los datos de cada nodo. Es decir, cada nodo obtiene una partición de índice que indexa localmente los datos. En esta prueba, Couchbase Server usa índices globales en su lugar. Los índices globales particionan independientemente el índice.
¿Por qué es esto importante? Esto significa que la ejecución de consultas MongoDB requiere una dispersión a través de los 9 nodos de servidor que tiene: ver la imagen del índice local a continuación. En cambio, el motor N1QL de Couchbase Server utiliza 1 de los índices para hacer un único salto de red para realizar el escaneo de rango: ver la imagen del índice global a continuación.
 |
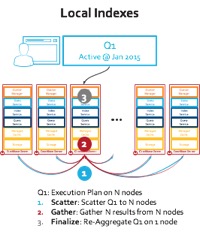 |
Figura: Ejecución de consultas con distribución global y local de índices
Aquí hay un problema fundamental con la arquitectura de índice local: En el paso#1 la consulta de rango llega se distribuye a todos los nodos. En este modelo, ningún nodo del clúster puede responder a la pregunta, ya que el índice utilizado para la ejecución de la consulta se distribuye alineado con la distribución de datos. Cada nodo tiene que ejecutar el mismo escaneo de rango (por cierto, la consulta en YCSB Workload E ejecuta un escaneo de rango con "order by" y "limit 50") y coger los elementos que caen dentro del rango. Esto significa que tiene un número de nodos*50 elementos que viajan al nodo coordinador. Esta prueba ejecuta miles de consultas y los residuos se replican hasta que la red se satura. Pero ese no es el problema más grave de los índices locales...
Supongamos que añadimos un nuevo nodo o ampliamos este clúster a 100 nodos, cada nuevo nodo tiene que realizar la consulta. No se puede escalar la consulta añadiendo nodos. De hecho, las cosas empeoran a medida que la red se satura entre nodos. Además, se desperdicia una gran cantidad de capacidad de CPU y todos los nodos están ocupados todo el tiempo.
En el caso de una ejecución de consulta en N1QL con índice global, el panorama es muy diferente. N1QL empuja hacia abajo "ordenar por" y "límite" al índice y trae sólo 50 elementos. No hay sobrecarga en la red... De hecho N1QL añade una recuperación más eficiente usando un conjunto de resultados comprimido (RAW). Usted puede agregar un nodo o ampliar a 100 nodos, y verá beneficios reales en el rendimiento. De hecho puedes repetir la prueba YCSB Workload E con 20 o 30 nodos, yo esperaría ver una mayor diferencia entre los rendimientos de Couchbase Server y MongoDB.
#2 Índices optimizados para memoria
Los índices globales son geniales, pero su mantenimiento es complicado. El índice global que reside en uno de los nodos se mantiene al día de las actualizaciones que se producen en todo el clúster, o al menos de todas las mutaciones relevantes para el índice. Necesitas una estructura de índices extremadamente eficiente que pueda mantenerse al día con las actualizaciones de los datos mientras realiza escaneos de alta velocidad.
Couchbase Server 4.5 introdujo una nueva arquitectura de almacenamiento para índices globales llamada índices optimizados para memoria (MOI). MOI optimiza el almacenamiento en memoria, ocupa menos espacio en memoria y utiliza una lógica de mantenimiento de índices sin bloqueos para indexar actualizaciones pesadas de datos con un paralelismo masivo. MongoDB utiliza una versión de un índice B-Tree que es bastante clásico entre muchas bases de datos relacionales y NoSQL. Couchbase Server viene con HB+Tree y algunos índices HB+Trie también. Se utilizan con el modo de almacenamiento estándar de índices y en Map-Reduce Views. Lo que encontramos sin embargo es esta nueva estructura skiplist y el enfoque libre de bloqueo aumenta el mantenimiento del índice y el rendimiento de escaneo en gran medida en el caso de los índices globales.
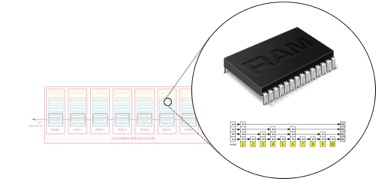
Figura: Indexación sin bloqueo Skiplist con índices globales optimizados en memoria
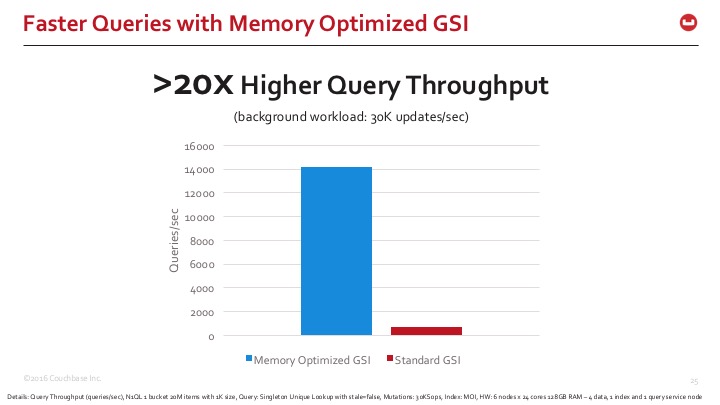
Para darte una idea rápida de la diferencia que estamos viendo, aquí está la comparación de Couchbase Server Indexing con los modos de almacenamiento de índices estándar y optimizado para memoria. Los índices optimizados para memoria son >20x más rápidos en tiempos de respuesta de consulta.
Aunque algunas de estas características no se utilizan en el benchmark, vale la pena mencionar que Couchbase Server puede indexar estructuras de array con anidamiento multinivel. Por ejemplo, películas y horarios pueden ser normalizados en 2 tablas separadas en el mundo relacional, sin embargo, tanto MongoDB como Couchbase modelan los datos con un único documento "película" que contiene una matriz de horarios. Para actualizar los horarios de una única película, se realiza una única actualización. Sin embargo, un índice de matriz recibiría muchas actualizaciones, ya que indexa cada hora de proyección individual. La tasa de actualización para el índice se amplifica igual al tamaño de la matriz... Así que todo esto significa una cosa: Incluso los sistemas que pueden tener una baja tasa de actualización de elementos, pueden necesitar índices de matrices que necesitan mantenerse al día con 10x, 20x o 100x la cantidad de actualizaciones, dependiendo del tamaño de las matrices incrustadas en los documentos. MOI ayuda en gran medida en estas condiciones, ya que puede mantenerse al día con >100Ks de actualizaciones con suficientes recursos computacionales.
Profundización en los resultados de YCSB Workload E
One consolidated view that tells the whole story is the %95th latency and throughput overlaid graph. This is how I view all performance results personally. – If you are the benchmarking type, you know the saying: “no tiene sentido considerar la latencia sin el rendimiento y viceversa".
A continuación se presenta un desglose detallado de los rendimientos y latencias de ejecución de las consultas de la carga de trabajo E.
-Las barras representan el rendimiento. azul es Couchbase y verde es MongoDB. Eje Y es el número de rendimiento.
-Las líneas representan la latencia - azul es Couchbase y naranja es MongoDB. El eje Y secundario de la derecha representa los números de latencia, con una línea de latencia descendente que representa una latencia peor o mayor. En otras palabras, el eje secundario de latencia es descendente. eje (las líneas discontinuas representan una mayor latencia).
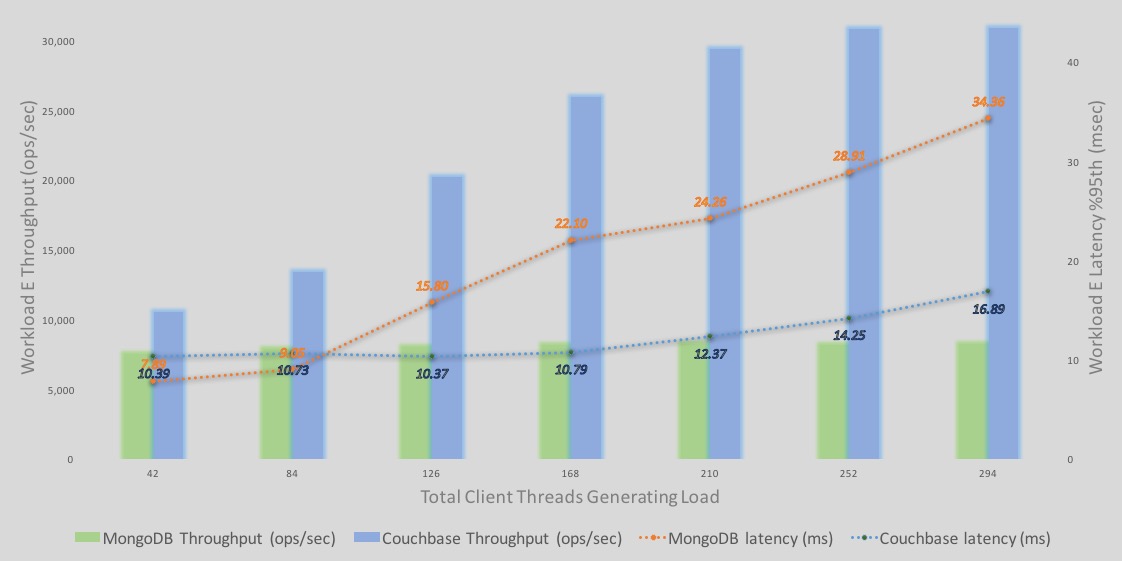
Algunas observaciones;
–Rendimiento: El rendimiento de Couchbase Server sigue aumentando con más carga. El rendimiento de MongoDB también aumenta, pero solo un poco antes de estabilizarse rápidamente.
–Latencia para Couchbase son superiores a las de MongoDB (42 y 84 clientes). Sin embargo, el rendimiento de Couchbase Server es mayor con cargas de 42 y 84 clientes. Apostaría que bajo el mismo rendimiento, las latencias en ambos motores pueden ser similares bajo esta carga ligera. Sin embargo, a medida que la carga aumenta, las latencias aumentan. Sin embargo, con el efecto de los índices globales y MOI, Couchbase empuja mejor rendimiento hasta que llegamos a >250 clientes. Couchbase Server también se nivela en este punto.
Carga de trabajo A: Grabación y lectura de sesiones de usuario
Carga de trabajo A en YCSB simula una carga de trabajo que captura y lee acciones recientes del usuario con 50% lecturas y 50% actualizaciones. Se trata de una carga de trabajo clave/valor básica. Observará que las operaciones/segundo son mucho mayores aquí. Esto se debe a que cada operación se ocupa de un único elemento. Por otro lado, la carga de trabajo E maneja 50 elementos por consulta.
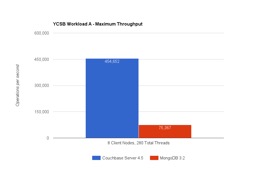
Puede que pongas los ojos en blanco y pienses que una simple lectura y escritura de más de 1K de datos no supone un gran reto. Sin embargo, hacer esto de manera eficiente es difícil. Muchas bases de datos se ajustan a la lectura o a la escritura, pero no a ambas. Cuando se juntan ambas cosas, resulta difícil mantener el ritmo. Pero ¿Cómo es Couchbase Server capaz de ejecutar 6 veces más operaciones en el mismo HW (9 nodos c3.8xlarge en Amazon Web Services) vs MongoDB?
#3 Acceso más rápido a los datos de la caché
Una de las razones importantes por las que Couchbase puede hacer la lectura/escritura más rápido (por debajo del milisegundo) es por su utilización del caché integrado. Muchas bases de datos, incluyendo otras en las que trabajé en el pasado, te dirían que pusieras un nivel de caché delante de la base de datos para no sobrecargarla. Sin embargo, Couchbase Server nunca se despliega con un nivel de caché separado. Tiene memcached para acceder rápidamente a los datos. También podemos almacenar en caché las partes del documento que necesitemos, a veces sólo sus metadatos, a veces con sus datos.
#4 Comunicación cliente-servidor eficiente y sin proxy
Couchbase Server viene con un cliente inteligente que es capaz de almacenar en caché la topología del cluster y su mapa de distribuciones. Esto significa que los clientes ya conocen el nodo exacto del Servidor Couchbase con el que hablar cuando obtienen el valor de la clave. No hay saltos en la comunicación. Sin intermediarios, sin desvíos... Esto hace que la comunicación sea eficiente.
Hay características adicionales que tienen un efecto indirecto en la comunicación de Couchbase Server: Lecturas parciales y actualizaciones de documentos. Si aquí se modifica la carga de trabajo para leer y actualizar un subconjunto del documento, se podrían ver mejoras en los resultados al utilizar la nueva función API.
Profundización en los resultados de la carga de trabajo A de YCSB
Here is the the %95th latency and throughput overlaid graph.
A continuación se muestra un desglose detallado de los rendimientos y latencias de ejecución de lectura/escritura de la carga de trabajo A.
-Las barras representan el rendimiento. azul es Couchbase y verde es MongoDB. Eje Y es el número de rendimiento.
-Las líneas representan la latencia - azul es Couchbase y naranja es MongoDB. El eje Y secundario de la derecha representa los números de latencia, con una línea de latencia descendente que representa una latencia peor o mayor. En otras palabras, el eje secundario para la latencia es un eje descendente.
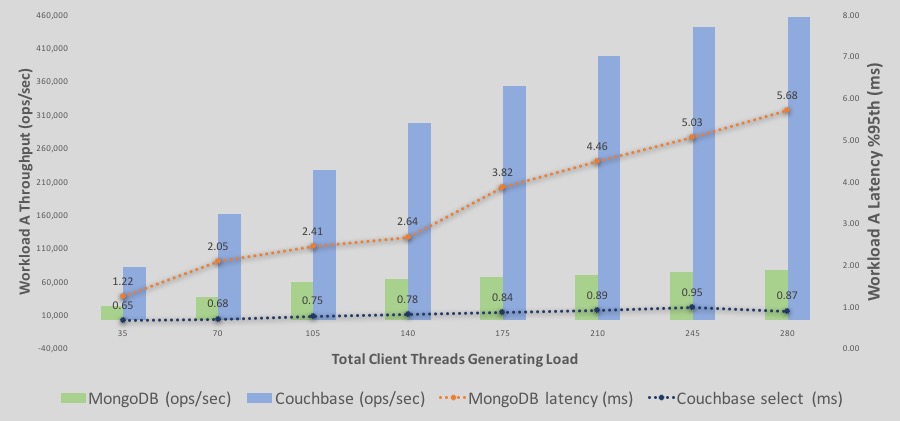
Algunas observaciones;
–Rendimiento: El rendimiento de Couchbase Server sigue aumentando con más carga. El rendimiento de MongoDB también aumenta con una pendiente más lenta hasta 140 clientes. Sin embargo, a partir de >210 hilos se estabiliza.
–Latencia para Couchbase empiezan siendo inferiores a las de MongoDB y siguen así. Al final, Couchbase todavía está en el rango de latencia por debajo del milisegundo mientras que MongoDB llega a >5ms de latencia para una latencia de 95%.
Soy consciente de que todo benchmark puede suscitar escepticismo, pero os animo a todos a que probéis Couchbase Server y nos contéis qué veis en vuestras ejecuciones personalizadas de YCSB. Si no veis los resultados que esperabais, hacédnoslo saber.