Couchbase Server 6.5 aporta una serie de novedades [1] a la principal base de datos NoSQL. Una de las principales novedades del lenguaje de consulta N1QL es la compatibilidad con las funciones de ventana. Estas funciones se introdujeron originalmente en el estándar SQL:2003 y proporcionan una forma eficaz de responder a muchas consultas empresariales complejas. Las funciones de ventana se trataron anteriormente en la serie de puestos [2], [3], [4], y en esta entrega profundizaremos en su implementación en Couchbase Analytics.
En Servicio Couchbase Analytics [5está diseñado para gestionar consultas ad-hoc complejas en la plataforma de datos Couchbase. Su componente clave es el motor de consultas MPP, que se ejecuta en un conjunto separado de nodos del clúster para garantizar el aislamiento de la carga de trabajo de los nodos de datos operativos. Los datos se introducen en Analytics mediante el motor de consultas MPP. Protocolo de cambio de DCP [6] y se reparte entre todos los nodos Analytics disponibles. El procesador de consultas MPP divide una única consulta en subtareas y las programa para que se ejecuten en paralelo en todos los nodos, reparticionando los datos si es necesario. Encontrará más información sobre la arquitectura general del servicio en nuestra reciente publicación Ponencia del VLDB 2019 [7] y en nuestro canal de vídeo [8].
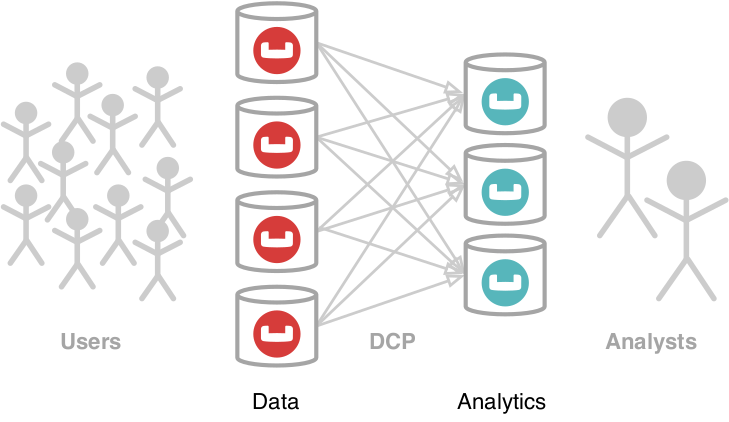
Figura 1: Servicio Couchbase Analytics
El motor de consulta de Analytics también evalúa las funciones de ventana de forma distribuida y paralela a las particiones. El compilador de consultas crea un plan de ejecución que contiene varios operadores que trabajan juntos para calcular el resultado de la llamada a la función ventana. A continuación, este plan de ejecución se envía a todos los nodos de Analytics del clúster, donde cada operador trabaja en una partición de los datos de entrada. El motor de ejecución coordina la ejecución de los operadores y entrega el resultado de la consulta al cliente. Por ejemplo, considere la siguiente consulta que clasifica a los empleados de cada departamento por sus salarios.
|
1 2 3 4 5 |
SELECT RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank, employee_id, department_id, salary FROM employee |
El procesador de consultas evalúa esta función en tres pasos, como se ilustra en la Figura 2.
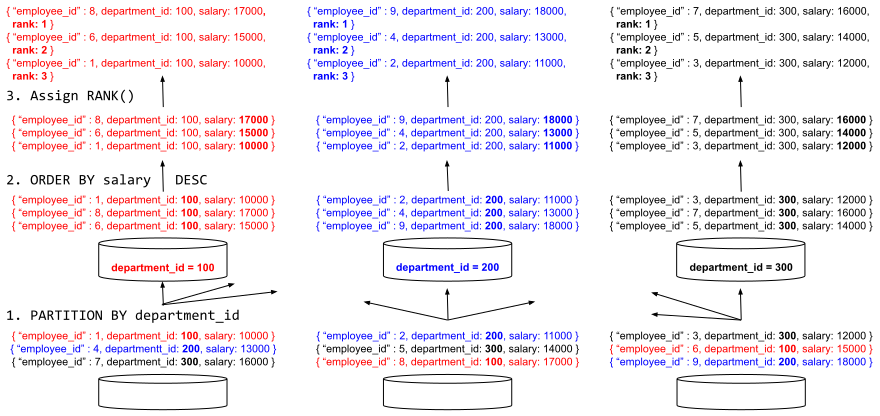
Figura 2: Ejecución distribuida y paralela de consultas de funciones ventana
- Una vez seleccionados los datos del conjunto de datos de empleados, se reparticionan de acuerdo con la subcláusula PARTITION BY de la cláusula OVER. La disposición inicial de los datos puede tener cada uno de los registros de departamento dispersos en diferentes particiones de almacenamiento en varios nodos Analytics. Tras el paso de repartición, todos los registros de empleados de un mismo departamento llegan a la misma partición de cálculo. El paso de repartición se ejecuta en paralelo en todos los nodos/particiones del clúster. En la configuración más común de Analytics existe una relación de uno a uno entre el número de particiones de datos y el número de núcleos de CPU disponibles en el clúster.
- Los registros de cada departamento se ordenan según la subcláusula ORDER BY de la cláusula OVER. Una vez que los registros de cada departamento han llegado a sus particiones de cálculo correspondientes, el procesador de consultas comienza a ordenar los datos. Este paso de ordenación también se realiza en paralelo en todos los nodos Analytics.
- La función RANK() se calcula a partir de los registros ordenados de cada departamento. Esta función en particular solo necesita mirar el registro actual y compararlo con el anterior, por lo que puede evaluarse de forma continua sin necesidad de materializar datos adicionales.
La ejecución de estos pasos en paralelo en todos los nodos disponibles permite a Analytics utilizar todos los recursos informáticos del clúster. Esto permite a Analytics lograr una escalabilidad lineal a medida que se añaden más nodos para alcanzar los objetivos de rendimiento requeridos.
Veamos cómo se pueden identificar las etapas anteriores dentro de un plan de ejecución de consulta. La función Analytics explain plan se describió en un entrada anterior [9], por lo que aquí sólo nos centraremos en el fragmento del plan relacionado con la evaluación de la función ventana. (Recordemos que los planes de consulta de Analytics deben leerse de abajo arriba).
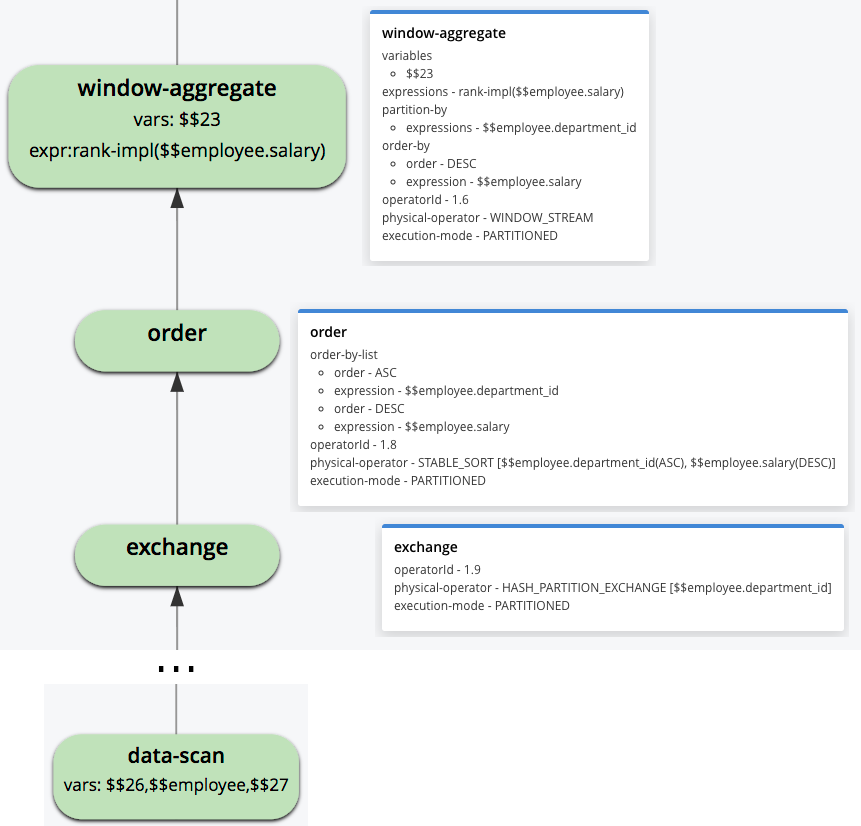
Figura 3: Fragmento del plan de ejecución de la consulta
El operador "data-scan" lee los datos del conjunto de datos de los empleados y los pasa al operador "exchange", que se encarga de repartirlos. El campo de repartición es "department_id", tal y como se solicita en la subcláusula PARTITION BY. A continuación, el operador "order" ordena los datos según la subcláusula ORDER BY. Por último, el operador "window-aggregate" calcula la función RANK(). Obsérvese que el valor "physical-operator" de este operador es "WINDOW_STREAM", lo que significa que el operador funciona en flujo y no requiere ninguna materialización adicional de los datos. El campo "execution-mode" se establece en "PARTITIONED" para todos los operadores, por lo que se ejecutarán en todas las particiones de cálculo disponibles en el clúster.
La evaluación de algunas funciones de ventana puede requerir información relativa a toda una partición lógica (su número total de tuplas para las funciones NTILE() y PERCENTILE_RANK(), por ejemplo) o múltiples iteraciones sobre toda la partición (cuando se calculan marcos de ventana para funciones agregadas). Tales funciones son procesadas por operadores de ventana de no flujo. Un operador de ventana no secuencial se identifica por el valor "physical-operator" de "WINDOW" en el plan de ejecución de la consulta. El operador materializa una partición lógica cada vez e inicia el cálculo de la función ventana para cada tupla de esa partición. Para manejar cantidades arbitrarias de datos entrantes, el operador sigue el modelo de gestión de memoria del motor de ejecución de Analytics. El planificador de consultas asigna un presupuesto de memoria a cada operador. Este presupuesto no puede superarse durante la ejecución de la consulta. Los datos operativos que superan el presupuesto son volcados al disco por cada operador y leídos de nuevo más tarde, cuando la memoria vuelve a estar disponible. Una consulta suele constar de varios operadores y, por tanto, tiene un presupuesto de memoria global que no puede superarse en tiempo de ejecución. El procesador de consultas Analytics implementa un control de carga basado en recursos para las consultas entrantes, admitiendo únicamente aquellas que pueden ejecutarse dentro de la memoria disponible en todos los nodos.
N1QL for Analytics también impone menos restricciones al contexto sintáctico de las llamadas a funciones ventana. A diferencia de SQL, las consultas en N1QL for Analytics permiten funciones de ventana en las cláusulas WHERE y HAVING, así como en las cláusulas LET específicas de N1QL.
Nuestra consulta original, por ejemplo, puede modificarse fácilmente para devolver sólo el empleado mejor clasificado en cada departamento:
|
1 2 3 4 5 |
SELECT employee_id, department_id, salary FROM employee WHERE RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) = 1 |
Para concluir, las funciones de ventana en Analytics proporcionan un poderoso mecanismo para el análisis paralelo de datos y la generación de informes. El lenguaje de consulta N1QL de Couchbase permite a los usuarios evaluar fácilmente esas funciones directamente en los datos JSON de su aplicación, evitando así el complejo procesamiento ETL.
Descargar Couchbase Server 6.5 hoy mismo y póngase en contacto con nosotros en el Foros para cualquier pregunta o comentario.
Referencias
[1] Anuncio de Couchbase Server 6.5 GA - Novedades y mejoras
https://www.couchbase.com/blog/announcing-couchbase-server-6-5-0-whats-new-and-improved/
[2] A la par con las funciones de ventana
https://www.couchbase.com/blog/on-par-with-window-functions-in-n1ql/
[3] Obtenga una visión más amplia con las funciones de ventana y CTE de N1QL
https://www.couchbase.com/blog/get-a-bigger-picture-with-n1ql-window-functions-and-cte/
[4] Funciones de ventana en Couchbase Analytics
https://www.couchbase.com/blog/window-functions-in-couchbase-analytics/
[5] Anuncio de Couchbase Server 6.0 con Analytics
https://www.couchbase.com/blog/announcing-couchbase-6-0/
[6] Historia de todo en Couchbase: DCP
https://www.couchbase.com/blog/couchbases-history-everything-dcp/
[7] Murtadha Al Hubail, Ali Alsuliman, Michael Blow, Michael Carey, Dmitry Lychagin, Ian Maxon y Till Westmann. Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis. PVLDB, 12(12): 2275-2286, 2019
https://www.vldb.org/pvldb/vol12/p2275-hubail.pdf
[8] Couchbase Analytics: Under the Hood - Connect Silicon Valley 2018
https://www.youtube.com/watch?v=1dN11TUj58c
[9] Analytics Explain Plan - Parte 1
https://www.couchbase.com/blog/analytics-explain-plan-part-1/
¡Buen post!