Alto rendimiento con Couchbase Server en Google Cloud
Couchbase Server es una base de datos distribuida NoSQL multimodelo de código abierto que incorpora una base de datos de documentos JSON y un almacén de valores clave. Couchbase Server se basa en una arquitectura centrada en la memoria diseñada para ofrecer un alto rendimiento, disponibilidad y escalabilidad constantes para aplicaciones web empresariales, móviles y del Internet de las Cosas. Couchbase Server también funciona muy bien en Google Compute Engine, ofreciendo una relación precio/rendimiento superior. Google ha publicado una serie de resultados en el blog de Google Cloud aquí y en este artículo me gustaría explicarles todas las pruebas que hemos realizado con la plataforma.
Durante el último año, los socios tecnológicos han informado de algunas estadísticas de rendimiento interesantes en Google Compute Engine, con Cassandra capaz de soportar 1 millón de escrituras por segundo. Nos lo tomamos como un reto y decidimos ver hasta dónde podíamos ampliar la escala y reducir la relación precio/rendimiento. Este artículo detalla los resultados de nuestros experimentos.
Antes de entrar en materia, quiero dar las gracias a David Haikney (Couchbase) y Dave Rigby (Couchbase) por todo el trabajo que han realizado en las mediciones de referencia y a Ivan Santa Maria Filho (Google) por toda la orientación que nos ha proporcionado.
Resumen
Couchbase Server fue capaz de soportar 1,1 millones de escrituras por segundo. El tamaño del conjunto de datos era de 3.000 millones de elementos con un tamaño de valor de 200 bytes. Las cargas de trabajo de escritura pura no son el único tipo de carga de trabajo interesante en bases de datos, pero es todo un reto. Numerosos clientes que desarrollan aplicaciones IoT (Internet de las cosas) se enfrentan a un reto similar. Los resultados de la prueba demuestran que Couchbase Server en Google Cloud Platform puede ser una gran opción para aplicaciones IoT que escriben datos a gran velocidad y en grandes volúmenes.
Datos de referencia
En nuestro viaje, hemos probado 2 configuraciones principales de puntos de referencia.
- Criterio A: esta configuración de referencia operaba sobre 3B elementos. Esta medición simulaba la configuración publicada en Cassandra en Google Cloud.
- Objetivo B: Esta segunda medición se realizó con un conjunto de datos más pequeño de 100 millones de elementos. En esta medición se simuló la configuración publicada por Aerospike en Google Cloud.
Antes de entrar en más detalles, puedes probar estos puntos de referencia por ti mismo, o simplemente echar un vistazo a los scripts para obtener más detalles. Aquí está nuestro repositorio github.
Criterio A:
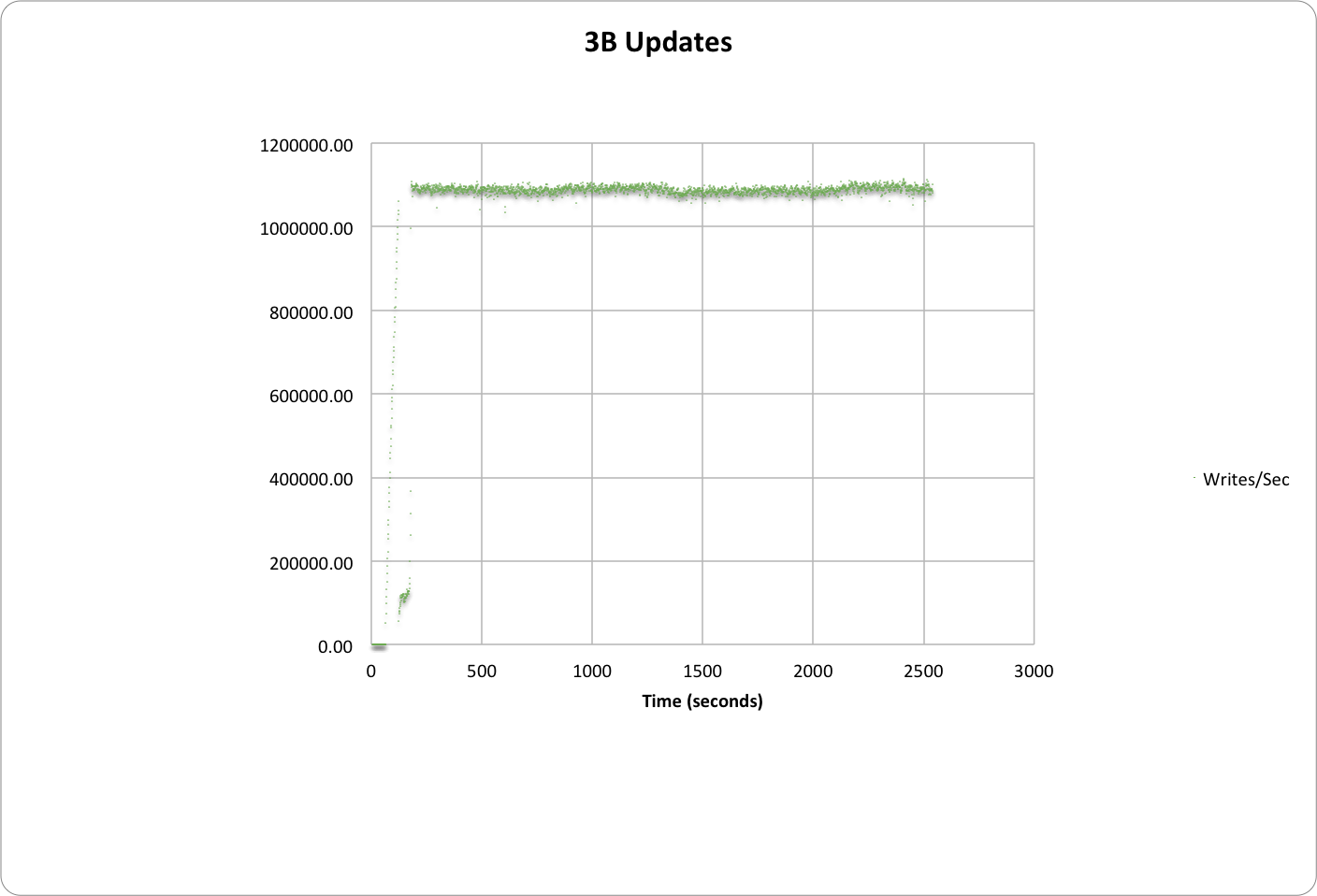
1,1 millones de escrituras/seg. en 3B elementos con 50 nodos (n1-estándar-16)
- 1,1 millones de escrituras/seg con 3.000 millones de elementos en total
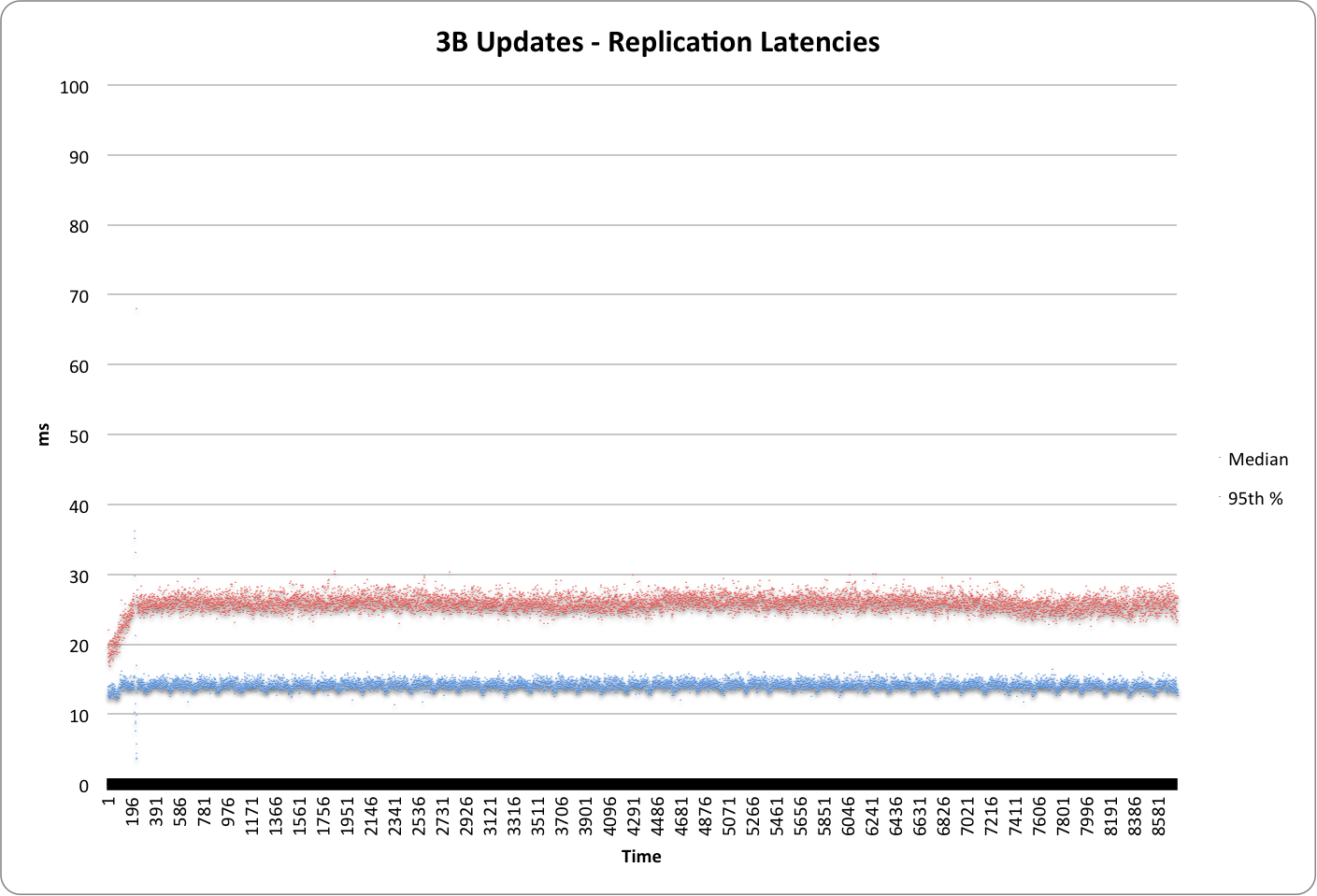
- La latencia media fue de 15 ms
- La latencia 95% fue de 27 ms.
- El coste total de ejecutar el benchmark durante una hora es de $56,3/hora.
El gráfico siguiente muestra el calentamiento y las escrituras sostenidas en el tiempo hasta alcanzar 1,1M.
El siguiente gráfico muestra la mediana y la latencia del 95% durante la ejecución de la prueba
Conjunto de datos de base y configuración de los cubos
- Carga de trabajo operada sobre un total de 3.000 millones de artículos
- Cada elemento tiene exactamente 200 bytes de valor.
Configuración del servidor Couchbase:
- Debian fue el sistema operativo elegido para esta ejecución (Debian Wheezy Backports).
- Configuración del clúster
- La cuota de RAM del servidor se fijó en 50 GB
- La capacidad de la cola de disco se fijó en 5 millones de elementos.
- Los hilos IO eran 4 de escritor y 1 de lector.
- Configuración del cubo:
- Todos los elementos 3B se configuraron para residir en un único cubo.
- Se mantuvieron 2 copias de los datos en 2 nodos separados para redundancia. La configuración del cubo especificaba 1 réplica además de la copia maestra.
- La política de desalojo de cubos se estableció en "desalojo de valores"
- La cuota de RAM del cubo se fijó en 50 GB por nodo.
- Compactación desactivada
Configuración de la máquina virtual
- Recuento de VM: 50
- Tamaño VM: n1-estándar-16
Había muchas opciones para elegir en los tamaños de VM. Sin embargo, hemos encontrado el n1-estándar-16 con 16 núcleos para ser un gran ajuste para un rendimiento óptimo precio. La prueba se ejecutó con 50, n1-estándar-16 VM con un total de 60 GB de RAM en cada nodo.
- Almacenamiento: Discos persistentes SSD de 500 GB
El almacenamiento en Google Cloud funcionó muy bien con Couchbase Server. Usamos la opción de almacenamiento persistente no efímero para hacer de este un despliegue realista para cargas de producción. El rendimiento más óptimo con Couchbase Server se logró con la oferta de disco persistente SSD. Couchbase Server usó 500GB SSD Disco persistente como volumen de datos. Couchbase Server no utilizó el volumen raíz de 10GB para operaciones de base de datos. Journaling estaba deshabilitado (noatime) en el volumen de datos.
- Coste por nodo: $1,12 / hr.
- Coste total con 50 nodos: $56,30 / hr
Propiedades de la carga de trabajo y durabilidad añadida con la bandera "ReplicateTo
La carga se generó utilizando la herramienta pillowfight. Para proporcionar la garantía de durabilidad añadida, la herramienta pillowfight fue modificada para añadir la bandera "ReplicateTo" a cada escritura. La opción asegura que las escrituras son reconocidas sólo después de que la operación de escritura alcanza ambas copias de los datos mantenidos por Couchbase Server.
Couchbase Server utiliza una réplica maestra activa para todas sus escrituras y mantiene réplicas secundarias para redundancia. Couchbase Server viene con una potente tecnología de replicación llamada DCP (database change protocol). DCP transmite los cambios a las réplicas secundarias. Couchbase puede mantener latencias por debajo del milisegundo en su modelo de escritura por defecto con su eficiente caché en memoria. Sin embargo, la escritura replicada proporciona la durabilidad firme bajo un fallo de nodo y asegura que no se pierdan datos en caso de un failover.
Configuración de generación de carga:
Para la generación de carga se utilizaron 32 clientes con n1-highcpu-8 VMs.
A continuación se muestra la opción de línea de comandos utilizada para la ejecución de 1 instancia de cliente con pillowfight
./cbc-pillowfight -min-size=200 -max-size=200 -num-threads=2 -num-items=93750000 -set-pct=100 -spec=couchbase://cb-server-1/charlie -batch-size=50 -num-cycles=468750000 -sequential -no-population -rate-limit=20000 -tokens=275 -durability
Objetivo B:
1M de escrituras/seg. en 100 millones de elementos con 40 nodos (n1-estándar-8)
- 1M de escrituras/seg con 100M de elementos totales
- La latencia media fue de 18 ms
- La latencia 95% fue de 36 ms.
- El coste total del funcionamiento del benchmark durante una hora es de $21,28/hora.
Conjunto de datos de base y configuración de los cubos
- Carga de trabajo operada en 100 millones de artículos totales
- Cada elemento tiene exactamente 200 bytes de valor.
Configuración del servidor Couchbase:
- Debian fue el sistema operativo elegido para esta ejecución (Debian Wheezy Backports).
- Configuración del clúster
- La cuota de RAM del servidor se fijó en 24 GB
- La capacidad de la cola de disco se fijó en 5 millones de elementos.
- Los hilos IO eran 2 de escritor y 1 de lector.
- Configuración del cubo:
- Los 100 millones de elementos se configuraron para residir en un único bucket.
- Se mantuvieron 2 copias de los datos en 2 nodos separados para redundancia. La configuración del cubo especificaba 1 réplica además de la copia maestra.
- La política de desalojo de cubos se estableció en "desalojo de valores"
- La cuota de RAM de los cubos se fijó en 24 GB por nodo.
- Compactación desactivada
Configuración de la máquina virtual
- Recuento de VM: 40
- Tamaño de la máquina virtual: n1-estándar-8
Para este menor número de elementos, hemos comprobado que el n1-standard-8 con 8 núcleos es el que mejor se adapta para un rendimiento óptimo del precio. La prueba se ejecutó con 40x n1-standard-8 VM con un total de 30 GB de RAM en cada nodo.
- Almacenamiento: Disco persistente estándar de 500 GB
El almacenamiento en Google Cloud funcionó muy bien con Couchbase Server. Usamos la opción de almacenamiento persistente no efímero para hacer de este un despliegue realista para cargas de producción. El precio/rendimiento óptimo con Couchbase Server se consiguió con la oferta de Disco Persistente Estándar. Couchbase Server usó 500GB Disco persistente como volumen de datos. Couchbase Server no utilizó el volumen raíz de 10GB para operaciones de base de datos. Journaling estaba deshabilitado (noatime) en el volumen de datos.
- Coste por nodo: $0,53 / hr.
- Coste total con 40 nodos: $21,28 / hr
Propiedades de la carga de trabajo y durabilidad añadida con la bandera "ReplicateTo
La carga se generó utilizando la herramienta pillowfight. Para proporcionar la garantía de durabilidad añadida, la herramienta pillowfight fue modificada para añadir la bandera "ReplicateTo" a cada escritura. La opción asegura que las escrituras son reconocidas sólo después de que la operación de escritura alcanza ambas copias de los datos mantenidos por Couchbase Server.
Couchbase Server utiliza una réplica maestra activa para todas sus escrituras y mantiene réplicas secundarias para redundancia. Couchbase Server viene con una potente tecnología de replicación llamada DCP (database change protocol). DCP transmite los cambios a las réplicas secundarias. Couchbase puede mantener latencias por debajo del milisegundo en su modelo de escritura por defecto con su eficiente caché en memoria. Sin embargo, la escritura replicada proporciona la durabilidad firme bajo un fallo de nodo y asegura que no se pierdan datos en caso de un failover.
Configuración de generación de carga:
Para la generación de carga se utilizaron 32 clientes con n1-highcpu-8 VMs.
A continuación se muestra la opción de línea de comandos utilizada para la ejecución de 1 instancia de cliente con pillowfight
./cbc-pillowfight -min-size=200 -max-size=200 -num-threads=2 -num-items=93750000 -set-pct=100 -spec=couchbase://cb-server-1/charlie -batch-size=50 -num-cycles=468750000 -sequential -no-population -rate-limit=20000 -tokens=275 -durability
Conclusión
1M de escrituras/seg es una cantidad impresionante de escrituras y muchos de ustedes puede que nunca alcancen este tipo de rendimiento en sus sistemas, pero es reconfortante saber que usted puede hacer este 1M de escrituras/seg sobre 3B elementos en tan sólo 50 nodos en Google Cloud con 6 veces mejor precio/rendimiento en comparación con Cassandra con escrituras totalmente replicadas.
¿Por qué se desactiva la compactación?
Si se pone en marcha y empieza a funcionar, será difícil que alcance a la antigua base de datos, que se llena con 1 millón de documentos nuevos por segundo, lo que provoca una duplicación de la base de datos.
No estaría mal en este caso, pero supongo que la CPU es un gran problema aquí para romper la barrera de 1 metro.
Dejamos la compactación fuera de las 2 ejecuciones para ver el rendimiento bruto. Estamos realizando más experimentos y también probaremos la compactación.
Además, el benchmark A está ejecutando RF=2 en lugar de 3 (el # utilizado para Cassandra)
Disculpas por el retraso en la respuesta. Nos estamos preparando para la próxima conferencia en la zona de la bahía.
Cassandra en un cluster de 300 nodos recomienda RF=3. Recomendamos réplicas adicionales en grandes cantidades de nodos también en Couchbase Server. La razón es: las posibilidades de fallo de "más de 1 nodo" aumentan con el número de nodos. Usted podría argumentar esto de cualquier manera, pero dado el número de nodos Couchbase es mucho menor (50 couchbase server), la protección que se obtiene de 2 réplicas es mayor que un clúster de 6 veces el tamaño (300 nodos en cassandra).
¿Por qué no usas nodos más pequeños? n1-highmem-4 en lugar de n1-standard-16.
Sus latencias son relativamente altas en comparación con aerospike benchmark ...
Quizá debería tener mejor rendimiento con 100 nodos más pequeños y reducir también el precio.
También puede utilizar SSD local para tener la misma configuración que aerospike benchmark :-)
¿ Puedes hacer el mismo benchmark con la versión beta de Couchbase con ForestDB ? *_*
Resultados impresionantes. Sin embargo, debo discrepar con tu introducción donde afirmas: \"Google publicó una serie de resultados en el blog de Google Cloud". La realidad es que *tú* escribiste la entrada del blog de Google como autor invitado. No dudo de tus números, pero la forma en que lo pones hace que suene como si Google se hubiera propuesto probar el rendimiento de Couchbase en su plataforma, dando así un aire de legitimidad (adicional) a los resultados. Deberías ser más claro al respecto.
¿Puedes compartir el benchmark con la compactación activada?
¡Sí!
estas pruebas NO son realistas en absoluto.
sólo la "carga inicial", no el uso real.
En la vida real te quedarías sin espacio de almacenamiento en un santiamén.
Pulgares abajo.
La utilidad cbc-pillowfight utiliza una carga útil muy fácil de comprimir.
Aquí la carga útil de 2000 fue reducida a 111 bytes por libsnappy.
Esto es completamente incorrecto para probar el rendimiento de escritura en dicha carga útil, Cihan.
/opt/couchbase/bin/couch_dbdump 451.couch.28 |head
Descargando "451.couch.28\":
Número de documento: 45380
id: 00000000000000643031
rev: 24
content_meta: 131
tamaño (en disco): 111
cas: 41835853675421190, caducidad: 0, flags: 0, tipo de datos: 0
tamaño: 2000
datos: (snappy) ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?ᆳ?
Número de documento: 47573
id: 00000000000000069855
(añadido https://issues.couchbase.com/b... sobre la aleatoriedad de la carga útil de cbc-pillowfight)
¿Puede proporcionar cómo el número de nodos y tamaños se traducirá en # de nodos ec2 y los tamaños de instancia en AWS?
[...] Бенчмарк один, бенчмарк два, бенчмарк три [PDF]; [...]