En Couchbase, los datos siempre se particionan mediante el método hash coherente de la clave del documento en vbukets que se almacenan en los nodos de datos. Couchbase Índice Secundario Global (IGS) abstrae las operaciones de indexación y se ejecuta como un servicio distinto dentro de la plataforma de datos Couchbase. Cuando un único índice puede cubrir todo un tipo de documentos, todo va bien. Pero, hay casos en los que querrías particionar un índice.
- Capacidad: Desea aumentar la capacidad porque un solo nodo no puede contener un índice grande.
- Consultabilidad: Desea evitar reescribir la consulta para trabajar con la partición manual del índice utilizando un índice parcial.
- Rendimiento: El índice único no puede cumplir el SLA
Para solucionar esto, Couchbase 5.5 introduce la partición hash automática del índice. Estás acostumbrado a tener datos de bucket con hash en múltiples nodos. La partición del índice te permite hashear el índice en múltiples nodos también. Hay una buena simetría.
Crear el índice es fácil. Basta con añadir una cláusula PARTITION BY a la definición del índice CREATE.
|
1 2 3 4 5 |
CREATE INDEX ih ON customer(state, name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8} |
Esto como los siguientes metadatos en el sistema:índices. Nótese la nueva partición de campo con la expresión hash. El HASH(state) es la base sobre la que se basa el índice denominado lógicamente cliente.ih se divide en un número de particiones físicas de índice. Por defecto, el número de particiones del índice es 16 y se puede cambiar especificando el parámetro num_partition. En el ejemplo anterior, creamos 8 particiones para el índice cliente.ih.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
select * from system:indexes where keyspace_id = "customer" and name = "ih" ; { "indexes": { "condition": "(`type` = \"cx\")", "datastore_id": "https://127.0.0.1:8091", "id": "b3ce745f84256319", "index_key": [ "`state`", "`name`", "`zip`", "`status`" ], "keyspace_id": "customer", "name": "ih", "namespace_id": "default", "partition": "HASH(`state`)", "state": "online", "using": "gsi" } } |
Ahora, realice la siguiente consulta. No es necesario un predicado adicional sobre la clave hash para que la consulta utilice el índice. El escaneo del índice simplemente escanea todas las particiones del índice como parte del escaneo del índice.
|
1 2 3 4 5 6 7 |
SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051"; |
Sin embargo, si tiene un predicado de igualdad en la clave hash, el escaneo de índice detecta la partición de índice correcta que tiene el rango de datos correcto y elimina el resto de los nodos de índice del escaneo de índice. Esto hace que el escaneo de índices sea muy eficiente.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051" and state = "CA"; |
Ahora, veamos cómo este índice le ayuda con tres cosas que hemos mencionado antes: Capacidad, Consultabilidad y Rendimiento.
Capacidad
La consulta cliente.ih se particionará en un número especificado de particiones y cada partición se almacenará en uno de los nodos indexadores del clúster. El indexador utiliza un algoritmo de optimización estocástica para determinar cómo distribuir las particiones en el conjunto de nodos indexadores, basándose en los recursos libres disponibles en cada nodo. Alternativamente, para restringir el índice a un conjunto específico de nodos, utilice el parámetro nodos. Este índice creará ocho particiones de índice y almacenará cuatro de cada una en los cuatro nodos de índice especificados.
|
1 2 3 4 5 6 |
CREATE INDEX ih ON customer(state, name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8, "nodes":["172.23.125.32:9001", "172.23.125.28:9001", "172.23.93.82:9001","172.23.45.20:9001" ]} |
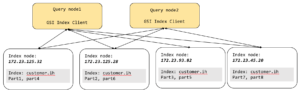
Así, con este índice particionado hash, un índice lógico (cliente.ih) se dividirá en un número de particiones físicas del índice (en este caso, 8 particiones) y dará a la consulta la ilusión de un índice único.
Dado que este índice utiliza los múltiples nodos físicos, el índice dispondrá de más recursos de disco, memoria y CPU. El mayor almacenamiento en estos nodos permite crear índices más grandes.
Escriba sus consultas, como de costumbre, requiriendo predicados sólo la cláusula WHERE (tipo = "cx") y al menos en una de las claves principales del índice (por ejemplo, nombre).
Consultabilidad
Limitaciones en la indexación de Couchbase 5.0:
Hasta Couchbase 5.0, podías particionar manualmente el índice como se muestra a continuación. Tenías que particionarlos manualmente usando la cláusula WHERE en el CREATE INDEX. Considera los siguientes índices, uno por estado. Usando el parámetro node, podrías colocarlos en nodos de índice específicos o el índice intentará repartirse automáticamente dentro de los nodos de índice.
|
1 2 3 4 5 6 |
CREATE INDEX i1 ON customer(name, zip, status) WHERE state = "CA"; CREATE INDEX i2 ON customer(name, zip, status) WHERE state = "NV"; CREATE INDEX i3 ON customer(name, zip, status) WHERE state = "OR"; CREATE INDEX i4 ON customer(name, zip, status) WHERE state = "WA"; |
Para una consulta simple con predicado equalify sobre el estado, todo funciona bien.
|
1 2 3 4 5 |
SELECT * FROM customer WHERE state = "CA" and name = "acme" and zip = "94051"; |
Hay dos problemas con esta partición manual.
- Considere lo siguiente con un predicado ligeramente complejo sobre el estado. Dado que el predicado (state IN ["CA", "OR"]) no es un subconjunto de ninguna de las cláusulas WHERE del índice, no se puede utilizar ninguno de los índices para la consulta siguiente.
|
1 2 3 4 5 6 |
SELECT * FROM customer WHERE state IN ["CA", "OR"] and name = ACME; SELECT * FROM customer WHERE state > "CA" and name = ACME; |
2. Si los datos pasan a un nuevo estado, hay que tenerlo en cuenta y crear el índice con antelación.
|
1 2 3 |
SELECT * FROM customer WHERE state = "CO" and name = ACME |
Si el campo es numérico, puede utilizar la función MOD().
|
1 2 3 4 5 6 |
CREATE INDEX ix1 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 0); CREATE INDEX ix2 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 1); CREATE INDEX ix3 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 2); CREATE INDEX ix4 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 3); |
Incluso en este caso, cada bloque de consulta sólo puede utilizar un índice y requiere que las consultas se redacten cuidadosamente para que coincidan con uno de los predicados de la cláusula WHERE.
Solución:
Como puede verse en la figura anterior, la interacción entre la consulta y el índice se realiza a través del cliente GSI que se encuentra dentro de cada nodo de consulta. Cada cliente GSI da la ilusión de un único índice lógico (cliente.ih) sobre ocho particiones de índice físicas.
El cliente GSI toma toda la solicitud de exploración del índice y, a continuación, utilizando el predicado, intenta ver si puede identificar cuál de las particiones del índice tiene los datos necesarios para la consulta. Este es el proceso de poda de particiones (también conocido como eliminación de particiones). Para el esquema de particionado basado en hash, los predicados de igualdad y de la cláusula IN se benefician de la poda de particiones. Todas las demás expresiones utilizan el método de dispersión. Tras la eliminación lógica, el cliente GSI envía la solicitud a los nodos restantes, obtiene el resultado, lo fusiona y lo devuelve a la consulta. La gran ventaja de esto es que las consultas pueden escribirse sin preocuparse de la expresión de partición manual.
La consulta de ejemplo siguiente ni siquiera tiene un predicado sobre la clave hash, state. La siguiente consulta no se beneficia de la eliminación de particiones. Por lo tanto, el cliente GSI escanea cada partición del índice en paralelo y luego fusiona el resultado de cada escaneo del índice. La gran ventaja de esto es que las consultas se pueden escribir sin preocuparse por la expresión de partición manual para que coincida con la expresión de índice parcial y seguir utilizando toda la capacidad de los recursos del clúster.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE INDEX ih1 ON customer(name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8} SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051"; |
El predicado adicional sobre la clave hash (estado = "CA") en la consulta siguiente se beneficiará de la poda de particiones. Para el procesamiento de consultas, para consultas simples con predicados de igualdad en la clave hash, se obtiene una distribución uniforme de la carga de trabajo en estas particiones múltiples del índice. En el caso de consultas complejas que incluyan la agrupación y la agregación de las que hemos hablado anteriormente, los escaneos y las agregaciones parciales se realizan en paralelo, lo que mejora la latencia de la consulta.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051" and state = "CA"; |
Puede crear índices mediante hashing en una o más claves, cada una de las cuales puede ser una expresión. He aquí algunos ejemplos.
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx1 ON customer(name) PARTITION BY HASH(META().id); CREATE INDEX idx2 ON customer(name) PARTITION BY HASH(name, zip); CREATE INDEX idx3 ON customer(name) PARTITION BY HASH(SUBSTR(name, 5, 10)); CREATE INDEX idx3 ON customer(name) PARTITION BY HASH(SUBSTR(META().id, POSITION(META().id, "::")+2), zip) |
Rendimiento
Para la mayoría de las funciones de bases de datos, el rendimiento lo es todo. Sin un gran rendimiento, demostrado por buenas pruebas comparativas, las funciones no son más que bonitos diagramas sintácticos.
La partición de índices mejora el rendimiento de dos maneras.
- Escalabilidad. Las particiones se distribuyen en varios nodos, lo que aumenta la disponibilidad de CPU y memoria para la exploración de índices.
- Escaneo paralelo. Predicado correcto que proporciona a las consultas el beneficio de la poda de particiones. Incluso después del proceso de poda, los escaneos de todos los índices se realizan en paralelo.
- Agrupación y agregación paralelas. El artículo de DZone Comprender la agrupación y agregación de índices en las consultas N1QL de Couchbase explica la mejora fundamental del rendimiento de la agrupación y agregación mediante índices.
- El paralelismo de la exploración paralela del índice (y la agrupación, agregación) viene determinado por el parámetro max_paralelismo parámetro. Este parámetro puede establecerse por nodo de consulta y/o por solicitud de consulta.
Considere el siguiente índice y consulta:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX ih1 ON customer(name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8} select zip, count(1) zipcount from customer where type = "cx" and name is not missing group by zip; |
El índice está particionado por HASH(state), pero el predicado state no aparece en la consulta. Para esta consulta, no podemos realizar la poda de particiones ni crear grupos dentro de los escaneos individuales de las particiones del índice. Por lo tanto, necesitará una fase de fusión después de la agregación parcial con la consulta (no se muestra en la explicación). Recuerda que estas agregaciones parciales se realizan en paralelo y, por tanto, reducen la latencia de la consulta.
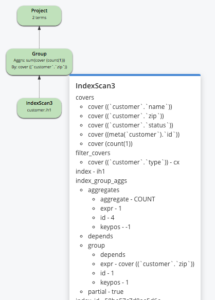
Considere el siguiente índice y consulta:
|
1 2 3 4 5 |
CREATE INDEX ih2 ON customer(state, city, zip, status) PARTITION BY HASH(zip) WHERE type = "cx" WITH {"num_partition":8} |
Ejemplo a:
|
1 2 3 4 5 6 |
select state, count(1) zipcount from customer where state is not missing group by state, city, zip; |
En el ejemplo anterior, el grupo por está en las claves principales (estado, ciudad, código postal) del índice y la clave hash (código postal) forma parte de la cláusula de grupo por. Esto ayudará a la consulta a escanear el índice y crear de forma sencilla los grupos necesarios.
Ejemplo b:
|
1 2 3 4 5 6 7 8 |
select zip, count(1) zipcount from customer where type = "cx" and city = "San Francisco" and state = "CA" group by zip; |
En el ejemplo anterior, el grupo por está en la tercera clave (zip) del índice y la clave hash (zip) forma parte de la cláusula de grupo por. En la cláusula de predicado (cláusula WHERE), hay un único predicado de igualdad en las claves de índice anteriores a la clave zip (estado y ciudad). Por lo tanto, incluimos implícitamente las claves (estado, ciudad) en el grupo por sin afectar al resultado de la consulta. Esto ayudará a la consulta a escanear el índice y crear de forma sencilla los grupos necesarios.
Ejemplo c:
|
1 2 3 4 5 6 7 8 |
select zip, count(1) zipcount from customer where type = "cx" and city like "San%" and state = "CA" group by zip; |
En el ejemplo anterior, el grupo por está en la tercera clave (zip) del índice y la clave hash (zip) forma parte de la cláusula de grupo por. En la cláusula de predicado (cláusula WHERE), hay un predicado de rango sobre la ciudad. La clave del índice (ciudad) está antes de la clave hash (código postal). Por lo tanto, creamos agregados parciales como parte de la exploración del índice y, a continuación, la consulta combinará estos agregados parciales para crear el conjunto de resultados final.
Resumen:
La partición de índices te proporciona una mayor capacidad para tu índice, mejor consultabilidad y mayor rendimiento para tus consultas. Al aprovechar la arquitectura de escalabilidad horizontal de Couchbase, los índices mejoran la capacidad, la consultabilidad, el rendimiento y el coste total de propiedad.
Referencia:
- Documentación de Couchbase: https://developer.couchbase.com/documentation/server/5.5/indexes/gsi-for-n1ql.html
- Documentación de Couchbase N1QL: https://developer.couchbase.com/documentation/server/5.5/indexes/gsi-for-n1ql.html#
Estimado Keshav , Gracias por proporcionar siempre grandes artículos .
Algunas preguntas: si usamos "num_partition":8 al crear un índice de partición por hash, ¿significa que necesitamos tener 8 nodos indexadores presentes en el cluster? o este # puede ser mutuamente excluyente y no correlacionarse con esto y sólo correlacionarse con la configuración de max_parallelism en admin?
Además, ¿podría ayudarnos si aumentar los "Servidores" en la configuración de administración puede suponer alguna diferencia en el rendimiento de la consulta?
gracias por su ayuda
Cada nodo puede tener múltiples particiones de un índice. No es necesario tener 8 nodos de índice para tener un índice con 8 particiones.
El parámetro servicers restringe el número máximo de consultas concurrentes en un nodo de consulta. Sólo mejorará el rendimiento (throughput) si te quedan CPUs y aumentas el número de consultas concurrentes. No mejora el rendimiento de una sola consulta.
Además, tenemos un foro activo. Siéntase libre de hacer preguntas allí. https://www.couchbase.com/forums/