Como defensor de los desarrolladores en CouchbaseA menudo viajo y me encuentro con gente que no tiene ni idea de lo que es NoSQL, o lo que es más importante, de lo que es Couchbase. Para la gente que ya está familiarizada con NoSQL, Couchbase a menudo es comparado con otros sistemas NoSQL. Base de datos NoSQL como MongoDB y CouchDB, que no tienen ninguna relación con Couchbase.
Hace poco me encontré con una serie de comparaciones entre MongoDB y Couchbase realizada por un autor de la comunidad, Milan Milosevic. En primera parte y segunda parte de su serie explica su experiencia, como desarrollador experimentado de MongoDB, viniendo de MongoDB, a intentar usar Couchbase. Se comparten opiniones válidas, pero hay algunas cosas que pueden pasarse por alto.
Quiero aclarar algunas dudas sobre lo que hace que Couchbase sea una gran opción en el espacio NoSQL.
Cubos y el documento JSON
Cuando trabajas con datos en Couchbase, estás trabajando con ellos como datos formateados en JSON. Estos datos JSON pueden ser tan simples o tan complejos como quieras hacerlos. Por ejemplo, lo siguiente es un documento JSON muy válido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "firstname": "Nic", "lastname": "Raboy", "addresses": [ { "city": "San Francisco", "state": "California" }, { "city": "Mountain View", "state": "California" } ], "social": { "twitter": "https://www.twitter.com/nraboy", "blog": "https://www.thepolyglotdeveloper.com" } } |
¿Notas cómo en el documento anterior hay matrices de objetos anidadas, así como objetos anidados? Al trabajar con documentos JSON, tienes más flexibilidad cuando se trata de tus datos de la que tendrías en una base de datos relacional.
Cada documento JSON almacenado en Couchbase debe tener un valor id único, también conocido como clave. Couchbase no creará esta clave por ti, pero hay muchas soluciones disponibles cuando se trata del diseño de claves. Por ejemplo, aquí hay tres formas posibles de diseñar una clave:
Lectura humana
|
1 |
nraboy |
Generado por ordenador o incremental
|
1 |
caa80375-77e7-4714-b90a-1089e66a5fd5 |
Combinación o compuesto
|
1 |
nraboy::1 |
No hay formas correctas o incorrectas de crear una clave. En realidad, todo depende de cuáles sean tus necesidades en el documento concreto que estés guardando. Ser capaz de diseñar tu propia clave es útil cuando se trata de establecer relaciones de datos y consultar esos datos.
Cada documento JSON, con su clave única, se guarda en lo que se llama un Couchbase Bucket. Es probablemente seguro pensar en un Bucket como un cubo literal en el que puedes almacenar cosas. Puedes colocar cualquier cosa en este bucket sin importar su forma o tamaño. Lo mismo se aplica a un Couchbase Bucket. Por ejemplo, digamos que quiero guardar los siguientes dos documentos:
|
1 2 3 4 5 |
{ "type": "person", "firstname": "Nic", "lastname": "Raboy" } |
Podemos dar al documento anterior cualquier clave única, realmente no importa para este ejemplo. La misma regla se aplica al documento siguiente:
|
1 2 3 4 5 |
{ "type": "location", "city": "San Francisco", "state": "California" } |
En ambos documentos observará que cada uno tiene un tipo con un valor diferente. Además, el nombre de cada una de las otras propiedades es completamente distinto, lo que indica que estos documentos resuelven propósitos diferentes. Aunque no es completamente necesario, el tipo nos ayuda a consultar estos documentos.
¿Tener X tipos de documentos en un mismo cubo complica o desordena las cosas? En absoluto, porque lo que importa es la consulta, no la forma en que se almacenan los documentos.
Cuando se trata de MongoDB, almacenarías cada tipo de documento en su propia colección y lo mismo con un RDBMS donde almacenarías cada uno en su propia tabla. ¿Significa eso que MongoDB y una base de datos relacional como Oracle lo están haciendo mal o mejor que Couchbase? No, no es así, es sólo su forma de resolver el problema.
Couchbase Shell (CBQ) y el banco de trabajo de consultas
Así que con datos JSON en Couchbase, habrá una necesidad de consultarlos, o incluso crear más de ellos. Hay varias formas de consultar datos en Couchbase y con varias herramientas diferentes.
Con Couchbase Enterprise Edition y Community Edition tienes lo que se llama Workbench de consultaque es una herramienta gráfica para ejecutar consultas, similar a lo que encontrarías en phpMyAdmin o en SQL Developer de Oracle.
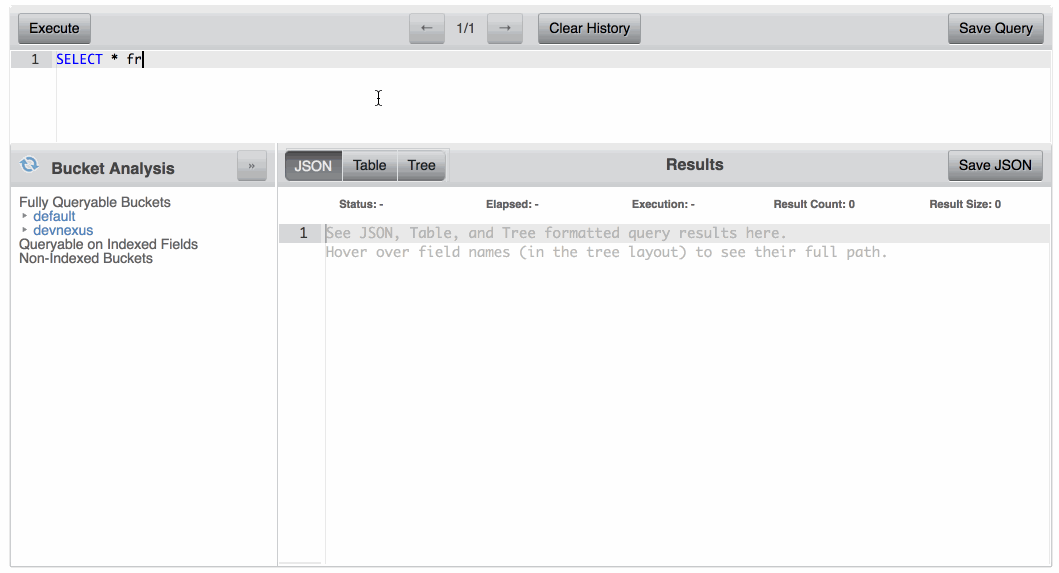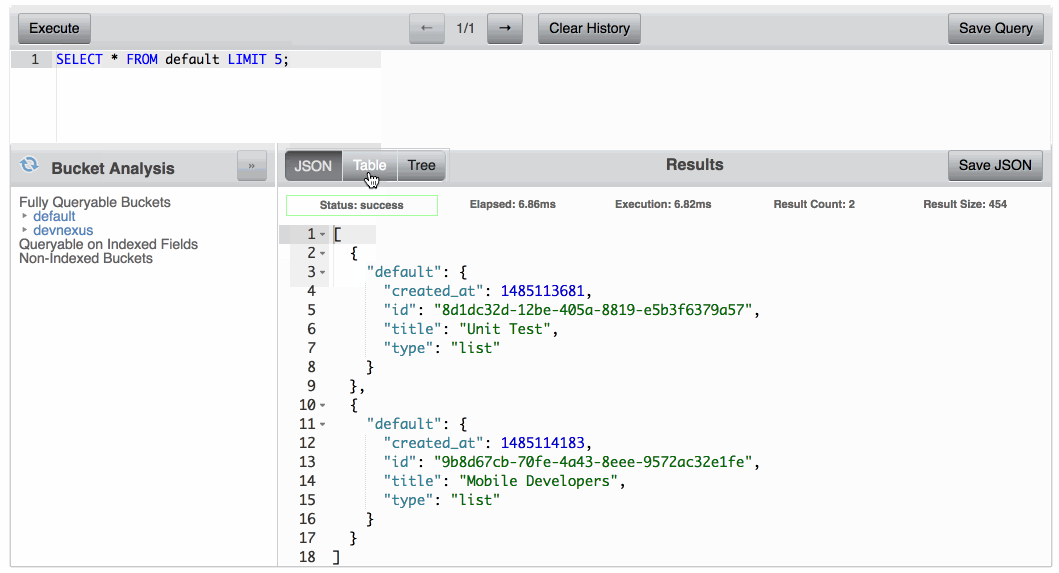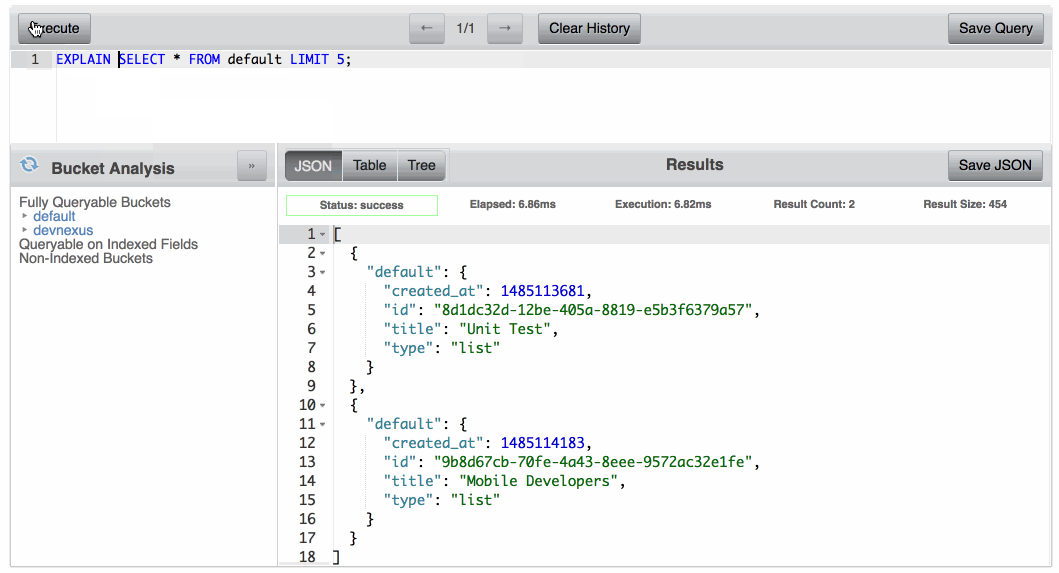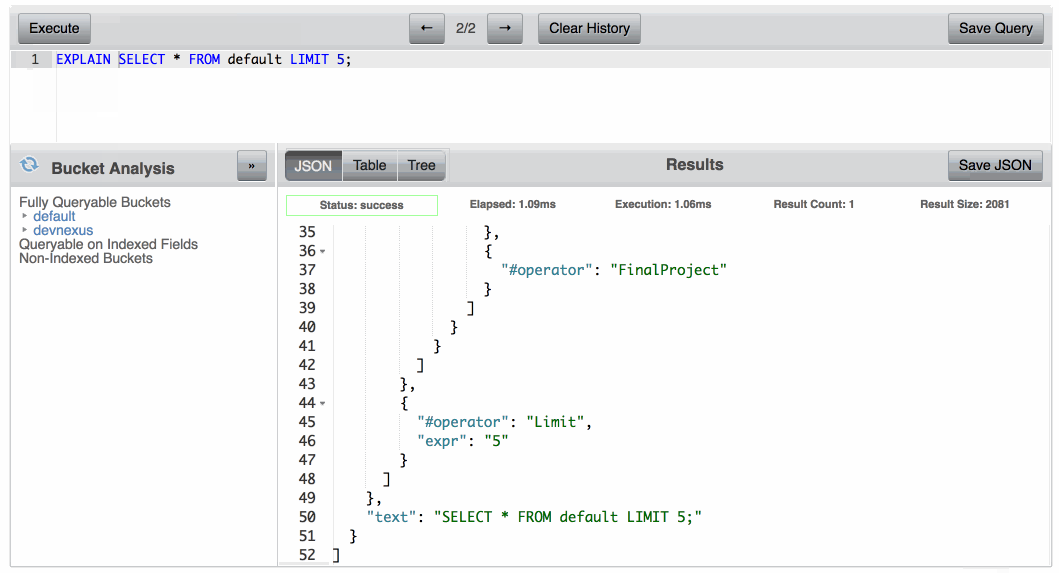
Con Query Workbench puedes ejecutar consultas Couchbase N1QL contra documentos encontrados en cada uno de tus Buckets. Estas consultas pueden incluir SELECCIONE, INSERTARo cualquier otro comando de consulta popular en lenguajes basados en SQL. Por ejemplo, la siguiente consulta devolverá todas las propiedades de todos los documentos encontrados en el Bucket de Couchbase llamado por defecto:
|
1 |
SELECT * FROM default; |
Aunque cada tecnología NoSQL tiene sus propios métodos para consultar datos, N1QL no sólo es fácil de usar, sino que resulta más cómodo para quienes se alejan de una base de datos relacional y ya tienen experiencia con SQL.
¿Y qué pasa con los desarrolladores que prefieren usar un cliente shell? Aquí es donde entra en juego Couchbase Shell (CBQ).
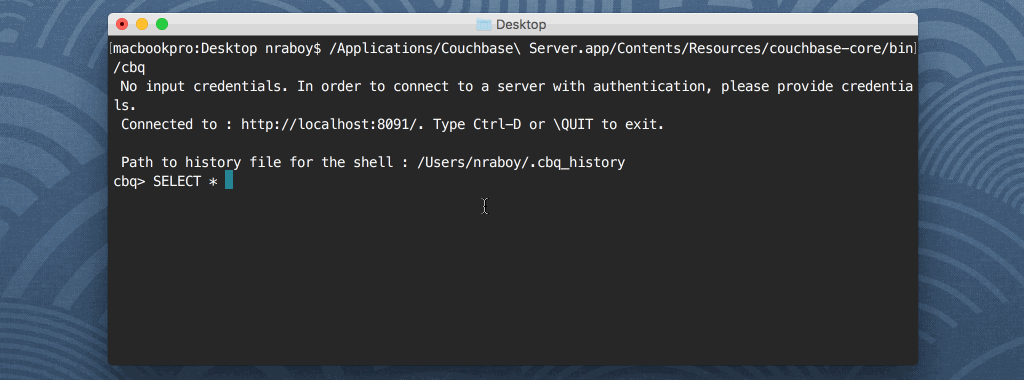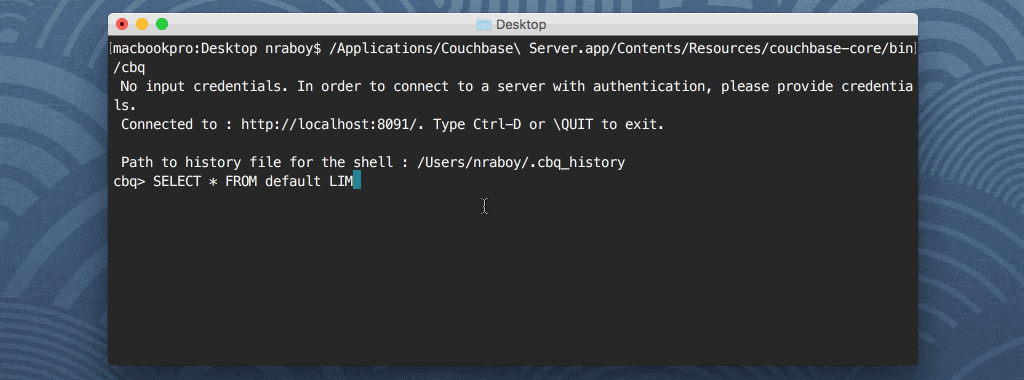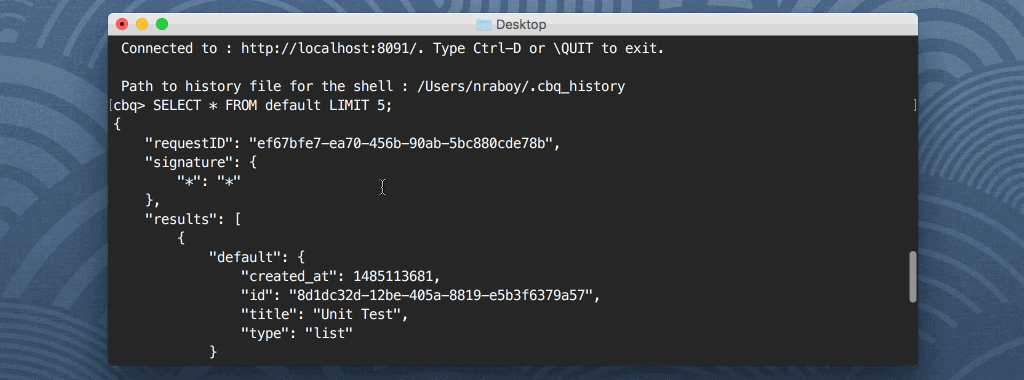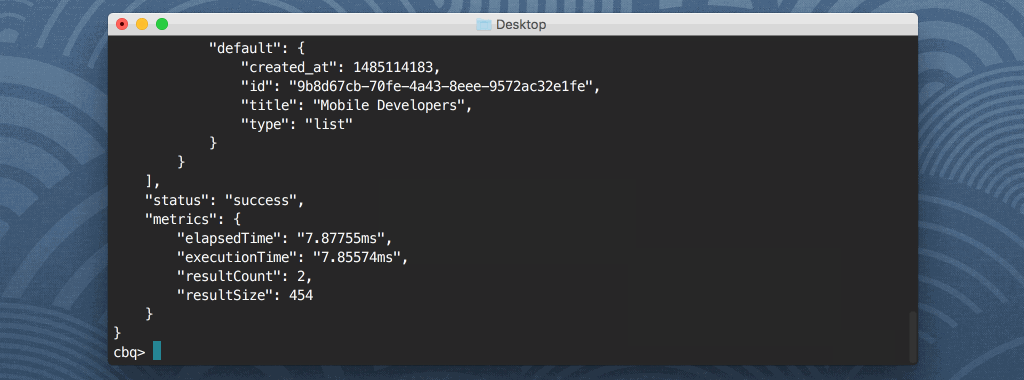
El cliente shell es similar al que encontrarías en MongoDB o en cualquiera de las tecnologías de bases de datos relacionales. ¿Qué pasaría si quisieras guardar los resultados de tu consulta en un archivo, en lugar de mostrarlos en el shell? Podrías hacer algo como esto:
|
1 |
echo "SELECT * FROM default;" | /Applications/Couchbase Server.app/Contents/Resources/couchbase-core/bin/cbq -u Administrator -p password -o ~/Desktop/output.txt |
Con CBQ no te limitas estrictamente a la ejecución de consultas. También dispone de funciones de conexión y gestión de la seguridad. En la página documentación así como esta entrada del blog Había escrito anteriormente.
Query Workbench y CBQ tienen ambos su propósito, pero en la mayoría de los casos usted consultará sus documentos utilizando uno de los muchos SDK para desarrolladores dentro de su aplicación. Con soporte de lenguajes para tecnologías de desarrollo populares como Java, .NET, Node.js y Golang, está totalmente cubierto cuando se trata de usar NoSQL dentro de su aplicación.
Indexación en Couchbase Server
Consultar Couchbase requiere que se creen índices dentro de tu cluster de Couchbase. Hay varios tipos de índices que se pueden crear, y se hacen en función de las necesidades de tu aplicación.
Tomemos por ejemplo el índice local. Cuando se crean índices locales en el clúster, cada nodo indexa los datos que posee localmente. Esta es una solución que funciona bien para un despliegue de un solo nodo, pero a medida que se empieza a aumentar el número de nodos en el clúster, la latencia de la consulta empieza a resentirse. Esto se debe a que la recopilación dispersa tiene que producirse entre los nodos disponibles antes de devolver los datos al cliente.
A medida que se crea un clúster multinodo, tiene más sentido empezar a utilizar índices secundarios globales (GSI). En este escenario, el índice se sitúa lejos de los nodos de datos y existe en menor cantidad. En lugar de utilizar scatter gather en cada índice local, la consulta va contra el índice global que conoce los datos que queremos y los devuelve. Esto mejora significativamente la latencia de la consulta.
¿Cómo se crea un índice secundario global en el clúster? Intente ejecutar algo como lo siguiente:
|
1 |
CREATE INDEX people ON default(firstname, lastname) WHERE type = "person" USING GSI; |
Tanto los índices locales como los índices secundarios globales pueden leerse en un gran entrada en el blog.
Esto nos lleva a una de las nuevas características de indexación de Couchbase. A partir de Couchbase 4.5, existen lo que se conoce como índices secundarios globales optimizados en memoria (MOI).
Ahora, en lugar de que los índices existan en disco y funcionen a velocidades de disco, pueden existir en memoria con un rendimiento mucho mayor. Más información sobre índices optimizados en memoria en esta entrada del blog.
¿Cómo saber qué índices utilizan las consultas? Tiene sentido ejecutar un EXPLICAR en una de sus consultas:
|
1 |
EXPLAIN SELECT firstname, lastname FROM default WHERE type = "person"; |
Los resultados sobre la EXPLICAR indican qué índice utilizó la consulta, así como información métrica diversa sobre lo que se hizo en el proceso. Si se utiliza el índice que he creado para esta consulta, el campo EXPLICAR debería decir que estamos utilizando el gente índice.
Preparado para la producción con el respaldo de un cliente potente
Tanto Couchbase Community como Enterprise Edition están listos para la producción y son utilizados activamente por organizaciones muy conocidas. Prepárate para escuchar algunos nombres.
Empresas enormes y muy respetadas como, entre otras, LinkedIn, PayPal, eBay, United, Marriott, GE y Verizon utilizan miles de nodos Couchbase para alimentar la capa de datos de su organización. Algunas de estas empresas han hablado en Couchbase Connect y las grabaciones se pueden ver a través de YouTube.
Para obtener una lista de más clientes de Couchbase, consulte la lista aquí.
Conclusión
Couchbase es una base de datos de documentos NoSQL rica en características que está sin duda lista para la producción. Con la capacidad de utilizar un modelo de datos JSON flexible y consultas y herramientas avanzadas, Couchbase se convierte en una base de datos perfecta para casi cualquier escenario.
Para obtener más información sobre el uso de Couchbase, consulte la página Portal para desarrolladores de Couchbase para consultar tutoriales y otra documentación.