Couchbase mejora aún más la alta disponibilidad para despliegues de misión crítica y reduce la intervención del operador. Couchbase mejora la detección de fallos de disco comunes y falla automáticamente sobre el nodo con discos defectuosos, ahorrando tiempo y energía a los operadores. También gestiona múltiples fallos de servidor basándose en el recuento de réplicas para evitar la pérdida de datos, y puede fallar sobre un grupo de servidores completo si un rack o zona no está disponible.
Ahora los usuarios pueden configurar la conmutación por error automática para disco, nodo múltiple y grupo de servidores completo (zona de bastidor) en Servidor Couchbase 5.5.
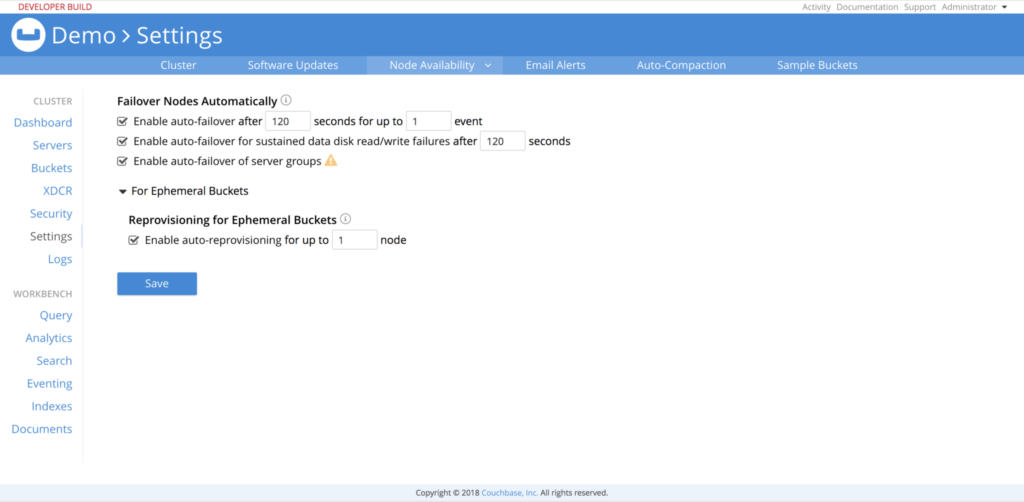
Veamos en detalle cada una de esas mejoras.
Auto-FailOver en problemas de disco
Antes de Couchbase Server 5.5, el gestor de cluster no realizaba automáticamente la conmutación por error cuando encontraba problemas relacionados con el disco en un nodo. El nodo sigue funcionando durante un tiempo, hasta que se queda sin memoria o se encuentra con algún otro problema.
Sin embargo, el gestor de clústeres dispone de alertas integradas para "cuando se detecta un fallo de disco durante la persistencia de datos en disco" y "El espacio en disco utilizado para el almacenamiento persistente ha alcanzado al menos 90% de capacidad".

En Couchbase Server 5.5, los usuarios podrán configurar los siguientes ajustes en la Configuración de Disponibilidad de Nodo en la Consola Web de Couchbase o a través de la CLI/REST API.
-
- Activación de la recuperación automática de fallos de lectura/escritura de disco de datos sostenidos
- Habilitar la recuperación automática de nodos para activar esta función
- Estará desactivado por defecto.
- El periodo de tiempo en segundos
- El mínimo puede ajustarse a 5 segundos, el máximo a 3600 segundos y el valor por defecto es 120 segundos.
- Activación de la recuperación automática de fallos de lectura/escritura de disco de datos sostenidos
¿Cómo funciona?
El gestor de Couchbase Cluster mantiene monitorizadas dos estadísticas -
- Número de fallos al intentar escribir elementos en el disco.
- Número de fallos al intentar leer de un disco.
Si estas estadísticas siguen aumentando durante el tiempo de espera de la conmutación por error automática y la opción "conmutación por error automática en caso de problemas de disco" está activada, el administrador del clúster conmutará por error automáticamente el nodo.
Las estadísticas anteriores están disponibles en la página de Estadísticas como -.
- Fallos de lectura del disco #
- Fallos de escritura del disco #
Nota - Es posible que aumente una estadística y no la otra. Por ejemplo, cuando el disco está lleno, las escrituras fallarán causando "fallos de escritura" para crecer, pero las lecturas todavía pueden pasar.
Auto-FailOver más de un nodo
Antes de Couchbase Server 5.5, el recuento de auto-failover o la cuota se establece en 1, es decir, sólo un nodo puede fallar automáticamente antes de requerir la intervención del usuario. Esto era una restricción para prevenir un fallo en cadena de múltiples o todos los nodos del cluster.
Sin embargo, el gestor de clústeres proporcionó alertas integradas "Node was auto-failed-over" en el primer nodo y "Se ha alcanzado el número máximo de nodos auto-failed-over".

En Couchbase Server 5.5, los usuarios podrán configurar la conmutación por error de varias instancias si todos los buckets del clúster están configurados con más de 1 réplica, en cuyo caso se podrá conmutar por error automáticamente un máximo de 3 instancias. sin que requiere intervención manual, como restablecer la cuota de recuperación automática.
Ahora los usuarios pueden configurar siguientes ajustes en la Configuración de Disponibilidad de Nodo en la Consola Web de Couchbase o a través de la CLI/REST API.
-
- Habilitar auto-failover para hasta 1 evento por defecto y un máximo de 3 eventos
- Esto habilitará la función y sólo se puede activar cuando está activada la recuperación automática.
- Estará desactivado por defecto.
- El periodo de tiempo en segundos
- El mínimo puede ajustarse a 5 segundos, el máximo a 3600 segundos y el valor por defecto es 120 segundos.
- Puede ser editado por el usuario en cualquier momento
- Habilitar auto-failover para hasta 1 evento por defecto y un máximo de 3 eventos
¿Cómo funciona?
El gestor de clústeres valida el número de réplicas configuradas para todos los buckets del clúster. En caso de que haya distintos buckets con distintas réplicas configuradas, el gestor de clústeres solo tendrá en cuenta el número máximo de réplicas configuradas en todos los buckets.
Por ejemplo - Si un cluster tiene
-
- un bucket con 1 réplica y otro con 2 réplicas, entonces permitir auto-failover de hasta sólo 1 nodo.
- dos cubos con 2 réplicas, entonces permite auto-failover de hasta 2 nodos.
- tres buckets con 2 réplicas, 2 réplicas y 3 réplicas configuradas, entonces permite auto-failover de hasta 2 nodos.
La cuota máxima de recuperación automática se aplica a todos los nodos del clúster, incluidos los nodos de datos, consulta, índice y búsqueda.
Si dos o más nodos fallan exactamente al mismo tiempo, el auto-failover no funcionará (independientemente del número máximo establecido por el usuario) con la excepción del auto-failover de grupo de servidores que se discutirá más adelante. Esta restricción se aplica para evitar que una partición de red provoque que dos o más mitades de un clúster fallen entre sí. Protege la integridad y consistencia de los datos.
Nota - Si fallan varios nodos, aumentará la carga del clúster. Los usuarios que deseen permitir la conmutación por error automática de más de un nodo, deben asegurarse de que tienen capacidad suficiente para gestionar los fallos.
Grupos de servidores Auto-FailOver (Rack-Zone Awareness)
Rack-Zone Awareness permite agrupaciones lógicas de servidores en un cluster donde cada grupo de servidores pertenece físicamente a un rack o Zona de Disponibilidad.
En Couchbase Server 5.5, los usuarios podrán configurar los siguientes ajustes en la Configuración de Disponibilidad de Nodo en la Consola Web de Couchbase o a través de la CLI/REST API.
- Activar la recuperación automática de grupos de servidores
- Habilitar la recuperación automática de nodos para activar esta función
- Será fuera de por defecto.
¿Cómo funciona?
Para que funcione la recuperación automática de grupos de servidores -
- Los clusters requieren un mínimo de 3 grupos de servidores en el momento del fallo. Esta restricción es necesaria porque si solo hay dos grupos de servidores y hay una partición de red entre ellos, ambos grupos de servidores podrían intentar conmutar por error entre sí.
- Todos los nodos del grupo de servidores han fallado. Esto indica un fallo correlacionado que probablemente ha afectado a toda la zona o rack.
- Todos los nodos que fallan pertenecen al mismo grupo de servidores. Esto evita que una partición de red provoque que dos o más mitades de un clúster fallen entre sí.
Recursos adicionales
- Descargar Couchbase Server 5.5
- Documentación de Couchbase Server 5.5
- Contenedor Docker Couchbase Server 5.5
- Comparta su opinión sobre el Foros de Couchbase
Cuando estamos haciendo auto-failover más de un nodo. Estamos comprobando el mínimo común denominador del recuento de réplicas y en base a eso podemos hacer que muchas conmutaciones por error de nodo?