JMH (Java Microbenchmarking Harness) se ha convertido en una de mis herramientas inestimables para cuantificar (y en última instancia justificar) una optimización de rendimiento dentro del SDK Java de Couchbase y sus proyectos relacionados. Ya que veo a muchos usuarios y clientes luchando con preguntas similares, pensé que podría ser una buena idea mostrarte cómo puedes usar JMC (Java Mission Control) en combinación con JMH para guiar sus decisiones de perfilado y pruebas de optimización del rendimiento de JMC utilizando datos reales en lugar de conjeturas descabelladas.
Puedes simplemente leer a lo largo y hurgar en el código fuente en el lado, pero si quieres reproducir lo que te voy a mostrar, necesitas un reciente Oracle JDK (para JMH, estoy usando 1.8.0_51). Además, no voy a mostrar todos los detalles menores como la forma de importar un proyecto en su IDE o similares. Si usted lucha con los conceptos básicos de perfiles de rendimiento de Java, este post probablemente no es para usted de inmediato.
El problema con la mayoría de las aplicaciones reales y las bibliotecas es que no hay fruta madura obvia. Si encuentras algo, te das una palmadita en la espalda y vas a arreglarlo, esas oportunidades son escasas. Muy a menudo hay que hacer un montón de pequeñas mejoras para obtener mejores resultados. En el SDK de Java, nos preocupamos por aumentar el rendimiento y minimizar la latencia en la medida de lo posible. Dado que ambas propiedades no se aman especialmente, sólo hay unas pocas cosas que puedes hacer para que ambas sean más felices al mismo tiempo:
- Reduzca la cantidad de CPU que su aplicación necesita para realizar cálculos
- Minimizar los puntos de contención y sincronización
- Evitar las asignaciones de objetos para que la GC haga menos
En este ejemplo verás el número 3 (y uno) en acción. He estado ejecutando el siguiente código en el proyecto core-io:
Si has visto algunas de mis charlas, siempre le digo a la gente que algo como esto no es un benchmark adecuado - así que ¿por qué lo hago aquí? La gran diferencia es que cuando como usuario estás evaluando Couchbase como un todo, esto no es una carga de trabajo realista que imite tu sistema de producción. Como desarrollador de librerías, quiero encontrar rutas de código calientes y hacerlas más rápidas, así que ejecutar el mismo código una y otra vez expone mejor esas rutas en el perfilador JVM (Java).
Cuando ejecuto este código contra mi nodo local de Couchbase Server, obtengo alrededor de 9k ops/s. No estoy interesado en aumentar el throuhgput en este punto, estoy tratando de reducir las asignaciones de objetos en la ruta de código caliente en primer lugar. Arrancando JMC y apuntandolo a mi JVM a traves de JFR (Java Flight Recorder) y luego dejando la maquina sola por 5 minutos mientras perfilaba me dio lo siguiente:
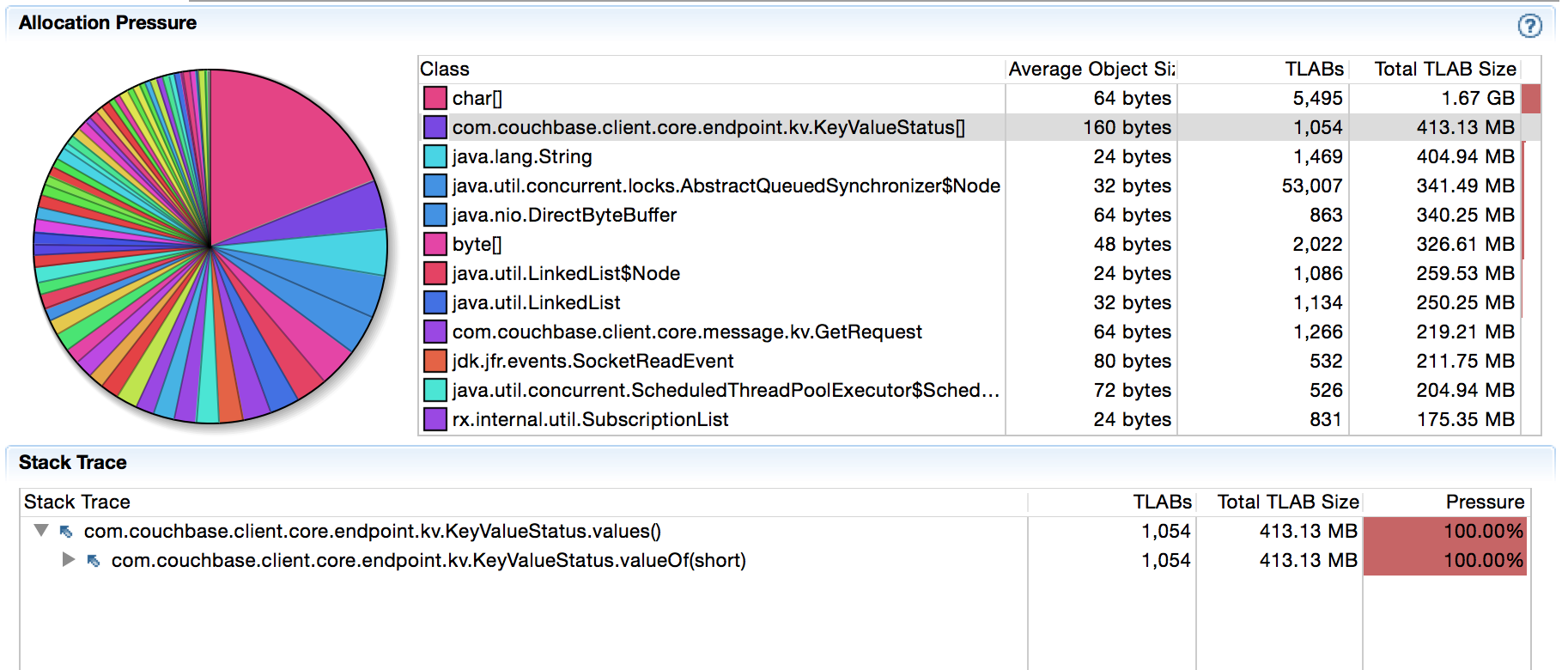
Hay 400MB asignados en 5 minutos para objetos KeyValueStatus[]. Ahora bien, esto puede no ser obvio para usted, pero sé que recientemente hemos cambiado algo en ese codepath (ver aquí) y no había visto antes este tipo concreto de asignaciones. Después de una rápida investigación estaba claro que el sospechoso está en el siguiente codepath (nótese cómo JFR nos guía al lugar correcto):
Cada vez que llega una respuesta, la comparamos con el enum KeyValueStatus para establecer el estado de respuesta adecuado. Uno de mis colegas hizo que el código se viera bien durante la refactorización, pero también introdujo sutilmente sobrecarga de GC. Como muestra la información de perfil, values() siempre crea un array para que podamos iterar sobre él y encontrar el código coincidente. No es mucho, pero se acumula con el tiempo. Pero lo más importante: es basura innecesaria.
Resulta que algunas respuestas son (mucho) más probables que otras, así que podemos optimizar para el caso común (siempre una buena idea). No voy a aburrirte con todas las cosas de bajo nivel, pero en el caso GET normalmente obtendrás un SUCCESS si el documento existe o un NOT_FOUND si el documento no existe. Así que una cosa que podemos hacer es lo siguiente:
Cambiando el código y ejecutando de nuevo el JFR las asignaciones de array han desaparecido:
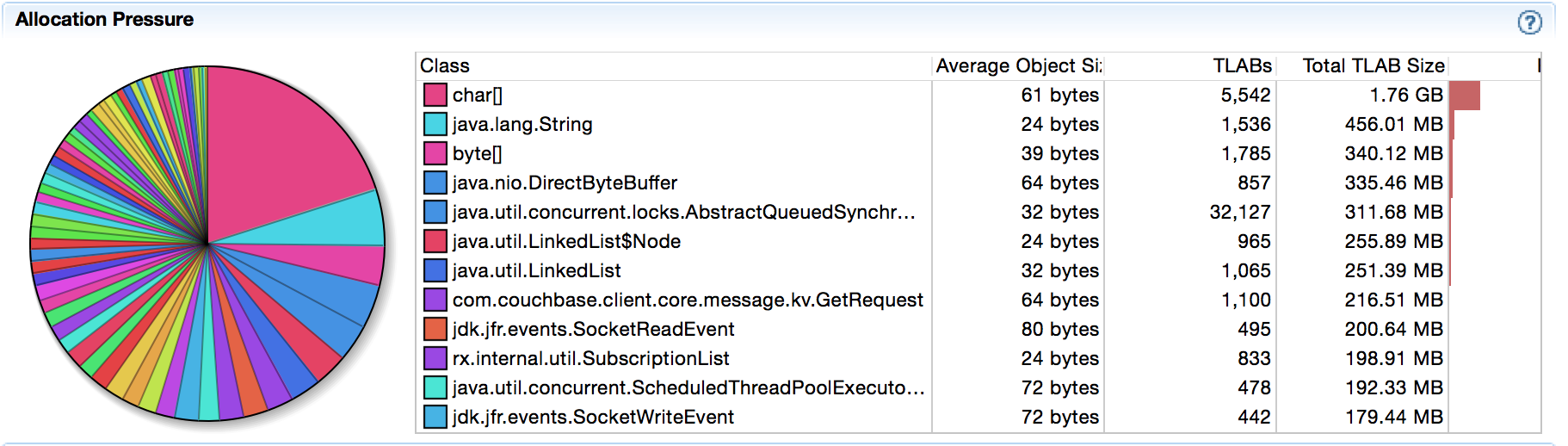
La mayoría de las veces los desarrolladores tienden a detenerse en este punto, pero te recomiendo que sigas leyendo. El hecho de que hayamos evitado las asignaciones de array (lo cual es bueno) no significa que sea más rápido, ¿verdad? En general uno creería que sí, pero me he sorprendido demasiadas veces en el pasado como para creerlo sin más. Incluso si estamos en lo cierto, hacer un rápido microbenchmark JMH para averiguarlo es algo bueno. También nos permitirá cuantificar cualquier mejora para el N°1 desde arriba, no sólo para el N°3 que ya hemos comprobado.
JMH forma parte del proyecto OpenJDK y no es tan difícil de usar. Puedes configurar un proyecto usando el comando mvn archetype:generate que puedes encontrar en su página principal. Una vez que tengas el esqueleto del proyecto, tienes dos opciones: o bien añadir el SDK de Java como una dependencia (se le hará sombra automáticamente) o simplemente copiar el enum. Dependiendo del tamaño de tus pruebas y de lo que quieras probar, debes elegir una de las dos opciones. Dado que nuestras pruebas actuales son autónomas, podemos copiar el ENUM en el proyecto. Esto tiene la ventaja de que podemos modificarlo sobre la marcha, añadir nuevos métodos para probar cosas y similares.
He copiado la clase KeyValueStatus de la versión 2.2.0 y he cambiado el código para que podamos llamar a dos variantes al mismo tiempo:
Ahora podemos escribir nuestro (simple) benchmark JMH:
A continuación compilamos el código y lo ejecutamos en la línea de comandos. Primero ejecuta "mvn clean install" y luego inícialo mediante "java -jar target/benchmarks.jar -wi 10 -f1 -i 10 -bm avgt -tu ns".
Si eso es demasiado arcano para ti, sólo significa que queremos medir la latencia media en nanosegundos y realizar 10 iteraciones de calentamiento, así como 10 iteraciones medidas en una bifurcación. ¿Sientes curiosidad? Aquí tienes los resultados:
Todas las operaciones están en el rango inferior de nanosegundos, así que la JVM hace un buen trabajo optimizando el bucle - pero no puede superar las simples operaciones de comparar y devolver. Como el código optimizado tiene un fallback, puedes ver en el código 134 que vuelve al bucle. Lo que se puede ver además en las ejecuciones "originales" es que también importa dónde se colocan los elementos en el ENUM una vez que se hace el bucle sobre él. 0 y 1 están más o menos en la parte superior, mientras que 134 está en la parte inferior. Así que incluso la reordenación para el caso común tiene sentido.
Así que a estas alturas estamos bastante convencidos de que tiene sentido aplicar ese cambio. Reduce las asignaciones y es más rápido de ejecutar. Además, no hace que el código sea más complejo. En la práctica, sin embargo, necesitamos más códigos en el camino optimizado, ya que esos dos no son suficientes. De la larga lista de enum, son:
- ÉXITO
- ERR_NOT_FOUND
- ERR_EXISTS
- ERR_NOT_MY_VBUCKET
- ERR_BUSY
- ERR_TOO_BIG
- ERR_TEMP_FAIL
Así que queda por responder una última pregunta: ¿deberíamos utilizar if/elseif para ellos o un simple bloque switch()? ¿Tiene alguna importancia? Otra prueba de JMH:
Y aquí están los resultados:
Ahora hemos incluido los tres parámetros en nuestro código de ruta rápida, por lo que ya no hay ningún valor atípico. También se puede ver que no hay ninguna diferencia práctica en absoluto para nuestro caso de uso. Así que tanto case como if/else funcionan bien y pueden elegirse en función de las preferencias y la claridad del código.
Eso es todo por hoy. Reduciendo las asignaciones de objetos y haciendo el código más rápido como efecto secundario usando herramientas como JMH y JFR para mediciones educadas en lugar de conjeturas salvajes. Feliz hacking y sin condiciones de carrera a todos.
¡Buen artículo!
Mi primer intento habría sido simplemente almacenar en caché el resultado de values() como VALUES en el KeyValueStatus2 y, como segundo paso, reordenar los valores del enum para el caso común.
En mis resultados esto es sólo 1-2 ns detrás de su versión para el caso común, pero es un poco mejor para el caso de borde - tal vez un candidato optimización adicional ;-)
Hola Thomas,
Gran idea, gracias por los comentarios. Lo intentaré, quizá también reordenándolos según la frecuencia con la que aparecen en el campo.
¡Qué bien! ¿Alguna posibilidad de conseguir la grabación? :)