La matriz es LA diferencia entre el modelo relacional y el modelo JSON. - Gerald Sangudi
Resumen
JSON array te da flexibilidad en el tipo de elementos, número de elementos, tamaño de los elementos, y la profundidad de los elementos. Esto se suma a la flexibilidad de las bases de datos operacionales JSON como Couchbase y MongoDB. El rendimiento de las consultas con un predicado de matriz en bases de datos operativas depende de los índices de matriz. Sin embargo, los índices de matrices en estas bases de datos vienen con importantes limitaciones. Por ejemplo, sólo se permite una clave de matriz por índice. Los índices de arrays, incluso cuando se crean, sólo pueden procesar predicados AND eficientemente. La próxima versión de Couchbase 6.6 elimina estas limitaciones de JSON usando un índice invertido integrado para indexar y consultar arrays en N1QL. Este artículo explica los antecedentes y el funcionamiento de esta novedosa implementación.
Introducción
Un array es un tipo básico integrado en JSON definido como En matriz es una colección ordenada de valores. Un array empieza por [soporte izquierdo y termina con ]soporte derecho. Los valores están separados por ,coma. Una matriz le ofrece flexibilidad porque puede contener un número arbitrario de valores escalares, vectoriales y de objeto. Un perfil de usuario puede tener un array de aficiones, un perfil de cliente un array de coches, un perfil de miembro un array de amigos. Couchbase N1QL proporciona un rico conjunto de operadores para manipular matrices; MongoDB tiene una lista de operadores para manejar matrices también.
Antes de empezar a consultar, necesitas modelar tus datos en arrays. Todas las bases de datos de documentos JSON como Couchbase, MongoDB te recomiendan desnormalizar tu modelo de datos para mejorar tu rendimiento y appdev. Lo que eso significa es, transformar tu relación 1:N en un único documento incrustando el N en 1. En JSON, harías eso usando un array. En el ejemplo de abajo, el documento(1) contiene 8 (N) gustos. En lugar de almacenar una referencia de clave externa a otra tabla, en JSON, almacenamos los datos en línea.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
"public_likes": [ "Julius Tromp I", "Corrine Hilll", "Jaeden McKenzie", "Vallie Ryan", "Brian Kilback", "Lilian McLaughlin", "Ms. Moses Feeney", "Elnora Trantow" ], |
Los valores aquí son matrices de cadenas. En JSON, cada elemento puede ser de cualquier tipo JSON válido: escalares (numéricos, cadenas, etc.) u objetos o vectores (matrices). Cada documento de hotel contiene una matriz de reseñas. Este es el proceso de desnormalización. Conversión de múltiples relaciones 1:N en un único objeto hotel que contiene N public_likes y M reviews. Con esto, el objeto hotel contiene dos matrices: public_likes y reviews. Puede haber cualquier número de valores de cualquier tipo bajo estas matrices. Este es el factor clave que contribuye a la flexibilidad del esquema JSON. Cuando necesites añadir nuevos gustos o comentarios, simplemente añade un nuevo valor o un objeto a esto.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
"reviews": [ { "author": "Ozella Sipes", "content": "This was our 2nd trip here...", "date": "2013-06-22 18:33:50 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 5, "Value": 4 } }, { "author": "Barton Marks", "content": "We found the hotel ...", "date": "2015-03-02 19:56:13 +0300", "ratings": { "Business service (e.g., internet access)": 4, "Check in / front desk": 4, "Cleanliness": 4, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 3, "Value": 5 } } ], |
Al igual que el objeto del hotel anterior, si desnormalizas tu modelo de datos en JSON, puede haber muchas matrices para cada objeto. Los perfiles tienen matrices para aficiones, coches, tarjetas de crédito, preferencias, etc. Cada una de ellas puede ser escalar (simples valores numéricos/cadenas/booleanos) o vectores (matrices de otros escalares, matrices de objetos, etc.).
Una vez modelados y almacenados los datos, hay que procesarlos: seleccionar, unir, proyectar. Couchbase N1QL (SQL para JSON) proporciona un lenguaje expresivo para hacer esto y mucho más. Estos son los casos de uso más comunes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
1. Find all the documents with a simple value can be done by either of the following queries. SELECT * FROM `travel-sample` WHERE type = "hotel" AND ANY p IN public_likes SATISFIES p = "Vallie Ryan" END SELECT t FROM `travel-sample` t UNNEST t.public_likes AS p WHERE t.type = "hotel" AND p = "Vallie Ryan" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
2. Find all the documents that match a range. In this case, we try to find all the documents that have atleast one rating has “Overall” > 4 SELECT COUNT(1) FROM `travel-sample` WHERE type = "hotel" AND ANY r IN reviews SATISFIES r.ratings.Overall > 4 END SELECT COUNT(1) FROM `travel-sample` t UNNEST reviews AS r WHERE t.type = "hotel" AND r.ratings.Overall > 4 GROUP BY t.type |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
3. Find all the documents where every rating for “Overall” > 4 SELECT * FROM `travel-sample` WHERE type = ‘hotel’ AND ANY AND EVERY r in reviews SATISFIES r.Overall > 4 END SELECT COUNT(1) FROM `travel-sample` WHERE type = "hotel" AND ANY AND EVERY r IN reviews SATISFIES r.ratings.Overall > 4 END SELECT reviews[*].ratings[*].Overall FROM `travel-sample` WHERE type = "hotel" AND ANY AND EVERY r IN reviews SATISFIES r.ratings.Overall > 4 END limit 10; [ { "Overall": [ 5 ], "name": "The Bulls Head" }, { "Overall": [ 5, 5, 5, 5, 5 ], "name": "La Pradella" }, { "Overall": [ 5, 5, 5 ], "name": "Culloden House Hotel" }, { "Overall": [ 5 ], "name": "Auberge-Camping Bagatelle" }, { "Overall": [ 5, 5 ], "name": "Avignon Hotel Monclar" } ] |
Indexación de matrices:
La indexación de matrices es un reto para los índices basados en árboles B. Sin embargo, la base de datos JSON tiene que hacerlo para cumplir los requisitos de rendimiento: MongoDB lo hace; Couchbase lo hace. Sin embargo, ambos tienen sus limitaciones. Sólo se puede tener una clave de matriz dentro de un índice. Esto es verdadero de MongoDBesto es verdadero de Couchbase N1QL. La razón principal de esta limitación es que, cuando se indexan elementos de una matriz, se necesitan entradas de índice separadas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
Consider the array: Document key: “bob” { “Id”: “bob123” “A”: [1, 2, 3, 4] “B”: [521, 4892, 284] } Indexing of the field “id” simply requires 1 entry in the index: “bob123”:bob Indexing of the field “a” requires 4 entries in the index: “1”:”bob”, 2:”bob”, 3:”bob”, 4:”bob” Indexing of the composite index (id, a) requires 4 entries: “bob123”, 1: bob “bob123”, 2: bob “bob123”, 3: bob “bob123”, 4: bob Indexing of the composite index (id, a, b) requires the following 12 entries: “bob123”, 1, 521: bob “bob123”, 1,4982: bob “bob123”, 1, 284: bob “bob123”, 2, 521: bob “bob123”, 2,4982: bob “bob123”, 2, 284: bob “bob123”, 3, 521: bob “bob123”, 3,4982: bob “bob123”, 3, 284: bob “bob123”, 4, 521: bob “bob123”, 4,4982: bob “bob123”, 4, 284: bob |
El tamaño del índice crece exponencialmente como el número de claves del array en el índice y el número de elementos del array en el índice. De ahí la limitación. Las implicaciones de esta limitación son:
- Introduce sólo un predicado de matriz en el escaneo del índice y maneja otros predicados después del escaneo del índice.
- Esto significa que las consultas con múltiples predicados de matriz pueden ser lentas.
- Evite los índices compuestos con claves de matriz para evitar índices enormes.
- Esto significa que las consultas con predicados complejos sobre claves de matrices serán lentas.
Buenas noticias de la CAMPO IZQUIERDO.
El índice de búsqueda de texto completo se diseñó para gestionar la búsqueda de patrones de texto basada en la relevancia. Lo hace tokenizando cada campo. En este ejemplo, cada documento se analiza para obtener tokens:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
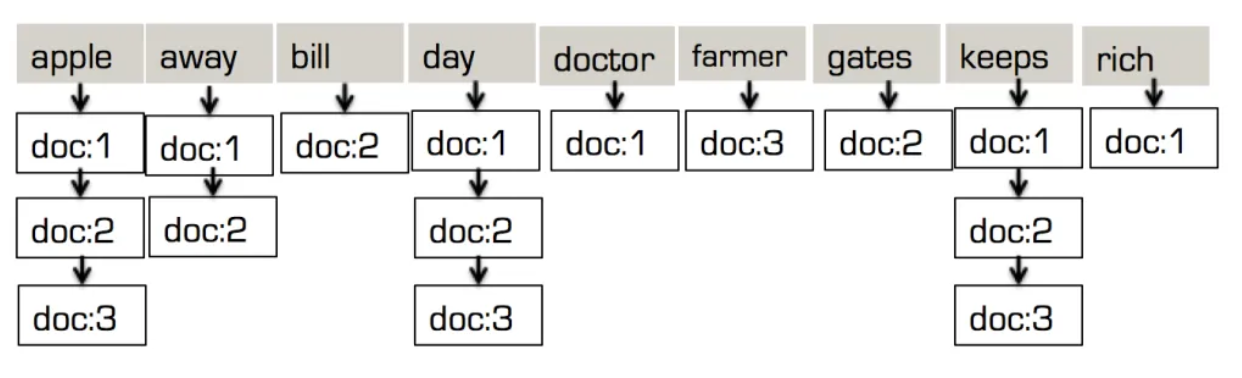
“doc:1”->”desc”: {“desc”: “an appel a day, keeps the doctor away.”} “doc:2”->”desc”: {“desc”:”an appel a day, keeps Billl Gates away.”} “doc:3”->”desc”: {“desc”: “an apple a dday, keeps the apple farmer rich.”} “doc:1”->”desc”: [“apple”, “day”, “keep”, “doctor”, “away”] “doc:2”->”desc”: [“apple”, “day”, “keep”, “bill”, “gates”, “away”] “doc:3”->”desc”: [“apple”, “day”, “keep”, “farmer”, “rich”] This then is combined to get a single array of tokens: [“apple”, “away”, “bill”, “day”, “doctor”, “farmer”, “gates”, “keep”, “rich”] |
Para cada token, guarda la lista de documentos en los que está presente. Esta es la estructura de árbol invertida. A diferencia de un índice basado en un árbol B, evita repetir el mismo valor de token N veces, una por cada documento en el que está presente. Cuando se tienen millones o miles de millones de documentos, el ahorro es enorme.
La segunda cosa a tener en cuenta aquí es, el índice invertido utilizado para ¡un ARRECIBO DE TOKENS! De hecho, la estructura de árbol invertido de la búsqueda de texto completo es ideal para indexar y buscar valores de matrices, especialmente cuando estos valores tienen duplicados.
Indexar matrices utilizando el índice invertido será el mismo proceso, excepto que no hay tokenización. Volvamos a indexar nuestro documento "bob", con documentos adicionales, "Sam" y "Neill"
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
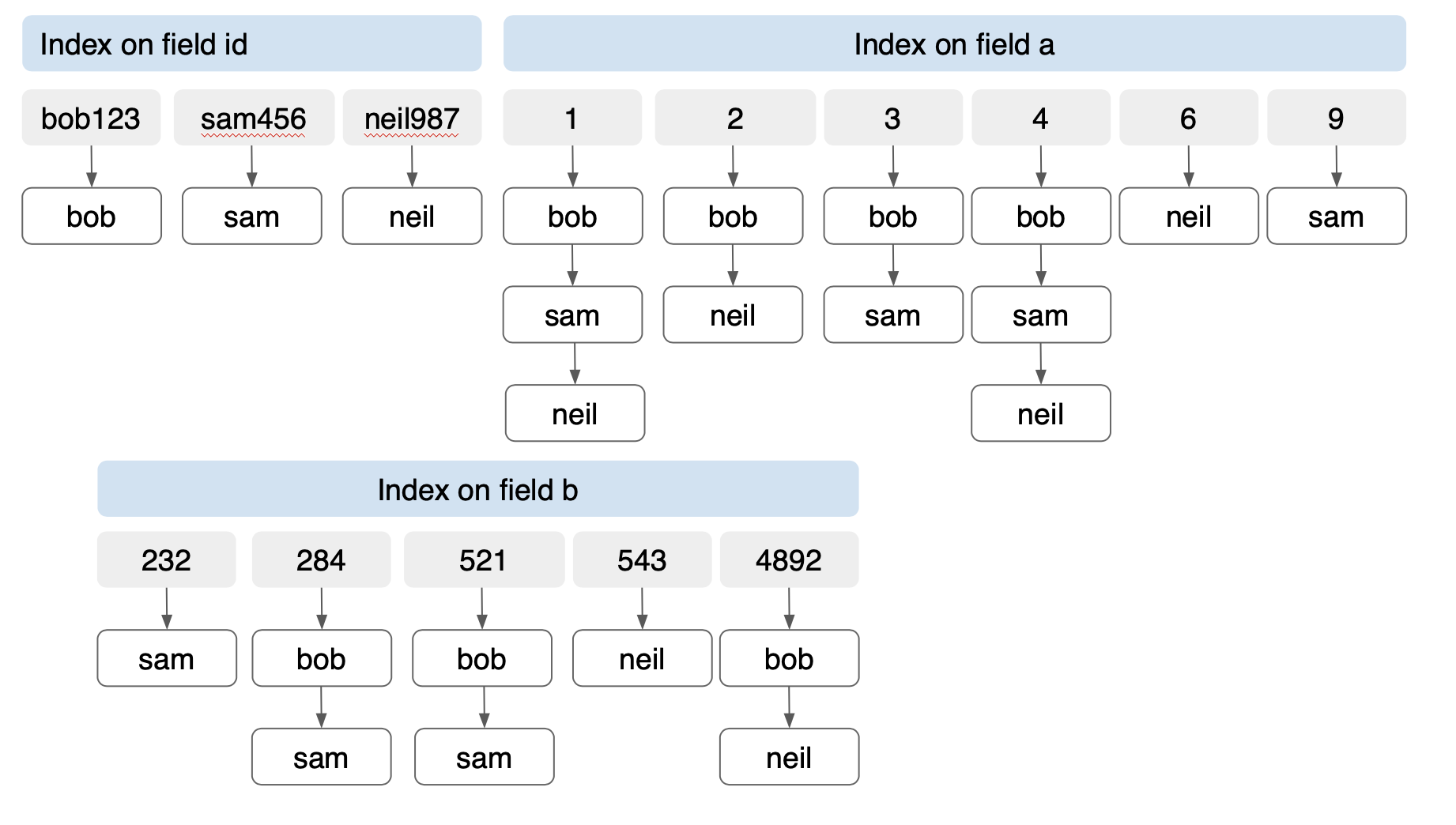
Document key: “bob” { id”: “bob123” “a”: [1, 2, 3, 4] “b”: [521, 4892, 284] } Document key: “sam” { “id”: “sam456” “a”: [1,3, 4, 9] “b”: [521, 232, 284] } Document key: “neil” { “id”: “neil987” “A”[1, 2, 4, 6] “b”: [521, 4892, 543] } |
En Couchbase FTS tiene un analizador llamado analizador de palabras clave. Esto indexa los valores tal cual en lugar de tratar de encontrar su raíz por stemming. Básicamente, el valor es el token. Para la indexación de valores de matrices, podemos utilizar este índice y explotar las eficiencias de un índice invertido. Construyamos un índice FTS en los documentos bob, sam, neil. En el caso del árbol invertido, cada campo tiene su propio árbol invertido: uno para id, uno para a y uno para b. Al tratarse de árboles individuales, no crecen exponencialmente como el índice compuesto del árbol B. El número de entradas del índice es proporcional al número de elementos únicos de cada campo. En este caso, tenemos 14 entradas para los 3 documentos con tres campos de un total de 24 valores. La creación de un índice de árbol B en (id, a, b) para el mismo documento creará ¡36 entradas!
Observe que para tres documentos con dos entradas de índice la diferencia es de 157%. A medida que aumenta el número de documentos y el número de matrices, también aumenta el ahorro al utilizar un índice invertido.
Índice invertido en tres campos.
Sin embargo, tenemos un problema. ¿Cómo se procesan los predicados?
|
1 2 3 4 5 6 7 |
WHERE id between "ada" and "tate" AND ANY x IN a SATISFIES x = 3 END AND ANY y in b SATISFIES y = 521 END |
El índice B-Tree almacena todos los valores de (id, a y b) juntos, el índice invertido en FTS tiene árboles distintos para cada campo. Por lo tanto, aplicar predicados múltiples no es tan fácil. Esto se aplica tanto al procesamiento de matrices como al de texto. En el tratamiento de textos es habitual hacer preguntas del tipo: buscar todos California residentes con Esquí como su hobby.
Para procesar esto, FTS aplica el predicado en cada campo individualmente para obtener la lista de claves de documento para cada predicado. A continuación, aplica el predicado booleano Y encima. Esta capa utiliza el famoso paquete bitmap rugiente para crear y procesar el mapa de bits de ids de documentos para finalizar el resultado. Sí, hay un procesamiento adicional aquí en comparación con un índice basado en B-TREE más simple, pero esto hace que sea posible indexar muchas matrices y procesar la consulta en un tiempo razonable.

Árbol invertido: Un árbol que sigue dando.
El índice compuesto B-Tree combina la exploración y la aplicación del predicado AND. El enfoque de árbol invertido separa ambos. Indexar y escanear cada campo es diferente de procesar el predicado compuesto. Debido a esta separación, la capa de mapa de bits puede procesar los predicados OR, NOT junto con los predicados AND. Cambiar el AND del ejemplo anterior por OR es simplemente una instrucción al procesamiento del mapa de bits en la calificación y deduplicación del documento
|
1 2 3 4 5 6 7 |
WHERE id BETWEEN "ada" AND "tate" OR ANY x IN a SATISFIES x = 3 END OR ANY y in b SATISFIES y = 521 END<b></b> |
Liberación de COUCHBASE:
Couchbase 6.6 soportará el uso de índices FTS para procesar predicados de arrays complejos. Esto mejora el coste total de propiedad de la gestión de arrays y permite a los desarrolladores y diseñadores utilizar, indexar y consultar arrays según sus necesidades sin limitaciones. Esté atento a los próximos anuncios, documentación, blogs de características, etc.
Referencias
- Trabajando con Arrays JSON en N1QL
- Utilización de matrices: Modelización, consulta e indexación
- Operadores de recogida N1QL de Couchbase
- MongoDB: Consulta de un arrray
- Couchbase FTS
- GRATUITO Formación interactiva sobre Couchbase
- FTS BLogs: https://www.couchbase.com/blog/tag/fts/
- Operadores de recogida
- Indexación ARRAY
- Saca el máximo partido a tus arrays... con N1QL Array Indexing
- Aproveche al máximo sus matrices... con índices de matrices de cobertura y mucho más.
- Indexación de Couchbase
- NEST y UNNEST: normalización y desnormalización de JSON sobre la marcha