Aaron Benton es un arquitecto experimentado especializado en soluciones creativas para desarrollar aplicaciones móviles innovadoras. Tiene más de 10 años de experiencia en desarrollo full stack, incluyendo ColdFusion, SQL, NoSQL, JavaScript, HTML y CSS. Aaron es actualmente Arquitecto de Aplicaciones para Shop.com en Greensboro, Carolina del Norte y es un Campeón de la comunidad Couchbase.

FakeIt Series 4 de 5: Trabajar con datos existentes
Hasta ahora, en nuestro FakeIt serie hemos visto cómo podemos Generar datos falsos, Compartir datos y dependenciasy utilice Definiciones para modelos más pequeños. Hoy vamos a ver la última característica importante de FakeIt, que es trabajar con datos existentes a través de entradas.
Como desarrolladores, rara vez tenemos la ventaja de trabajar en aplicaciones totalmente nuevas, ya que nuestros dominios suelen estar compuestos por diferentes bases de datos y aplicaciones heredadas. A medida que modelamos y creamos nuevas aplicaciones, necesitamos referenciar y utilizar estos datos existentes. FakeIt le permite proporcionar datos existentes a sus modelos a través de archivos JSON, CSV o CSON. Estos datos se exponen como una variable de entrada en cada una de las funciones *run y *build de los modelos.
Modelo de usuario
Empezaremos con nuestro modelo users.yaml que actualizamos en nuestro post reciente utilizar Dirección y Teléfono definiciones.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 |
name: Users type: object key: _id data: min: 1000 max: 2000 properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: "`user_${this.user_id}`" doc_type: type: string description: The document type data: value: "user" user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() addresses: type: object description: An object containing the home and work addresses for the user properties: home: description: The users home address schema: $ref: '#/definitions/Address' work: description: The users work address schema: $ref: '#/definitions/Address' main_phone: description: The users main phone number schema: $ref: '#/definitions/Phone' data: post_build: | delete this.main_phone.type return this.main_phone additional_phones: type: array description: The users additional phone numbers items: $ref: '#/definitions/Phone' data: min: 1 max: 4 definitions: Phone: type: object properties: type: type: string description: The phone type data: build: faker.random.arrayElement([ 'Home', 'Work', 'Mobile', 'Other' ]) phone_number: type: string description: The phone number data: build: faker.phone.phoneNumber().replace(/[^0-9]+/g, '') extension: type: string description: The phone extension data: build: chance.bool({ likelihood: 30 }) ? chance.integer({ min: 1000, max: 9999 }) : null Address: type: object properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
Actualmente, nuestro Dirección es generar un país al azar. ¿Y si nuestro sitio de comercio electrónico sólo admite un pequeño subconjunto de los 195 países? Digamos que, para empezar, admitimos seis países: US, CA, MX, UK, ES, DE. Podríamos actualizar la propiedad country de las definiciones para obtener un elemento de matriz aleatorio:
(En aras de la brevedad, se han omitido las demás propiedades de la definición del modelo)
|
1 2 3 4 5 6 |
... country: type: string description: The country code data: build: faker.random.arrayElement(['US', 'CA', 'MX', 'UK', 'ES', 'DE']); |
Si bien esto funcionaría, ¿qué pasa si tenemos otros modelos que dependen de esta misma información del país, tendríamos que duplicar esta lógica. Podemos conseguir lo mismo creando un fichero countries.json, y añadiendo una propiedad inputs a la propiedad data que puede ser una ruta absoluta o relativa a nuestra entrada. Cuando se genere el modelo, nuestro fichero countries.json será expuesto a cada una de las funciones de construcción del modelo a través del argumento inputs como inputs.countries
(En aras de la brevedad, se han omitido las demás propiedades de la definición del modelo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Users type: object key: _id data: min: 1000 max: 2000 inputs: ./countries.json properties: ... definitions: ... country: type: string description: The country code data: build: faker.random.arrayElement(inputs.countries); countries.json [ "US", "CA", "MX", "UK", "ES", "DE" ] |
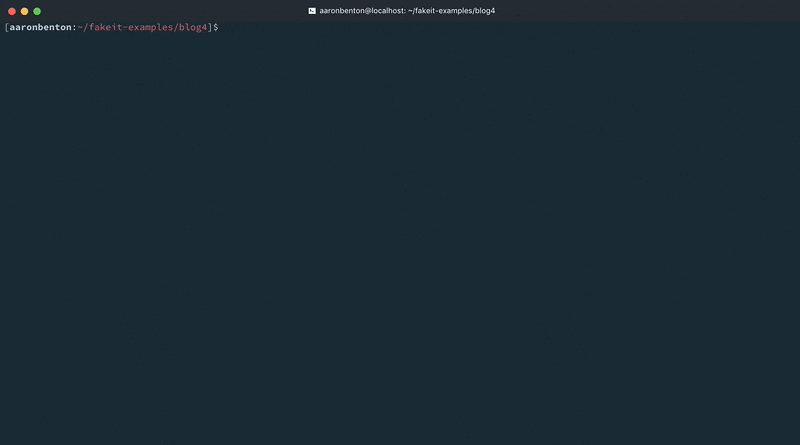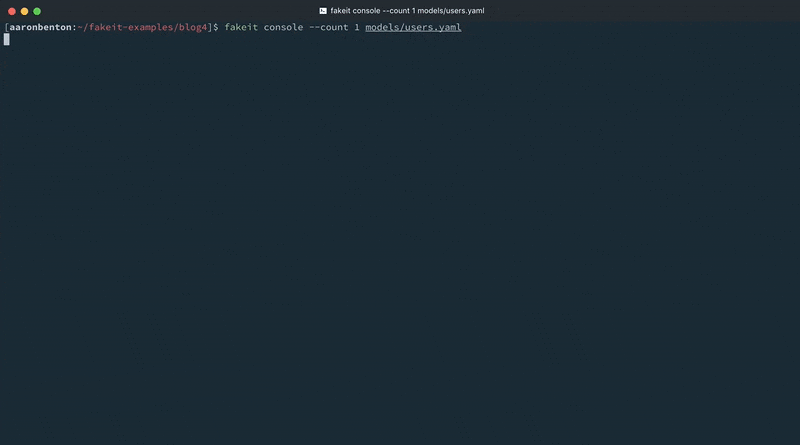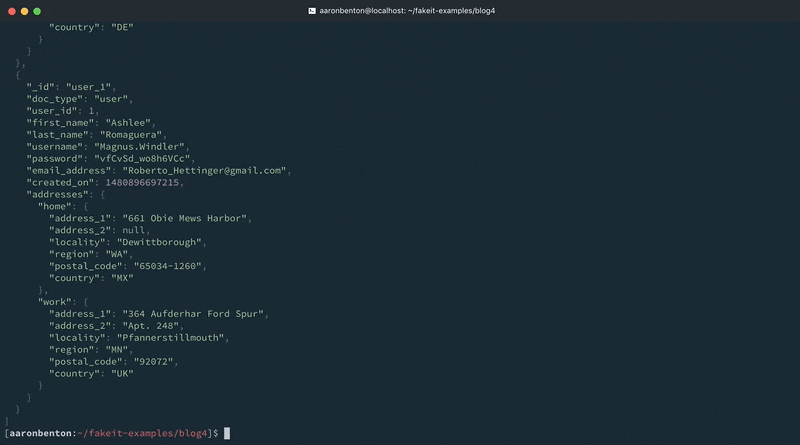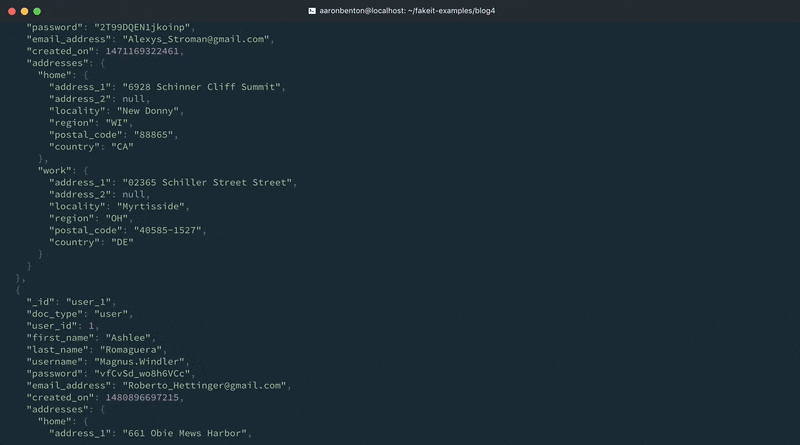
Cambiando una línea existente y añadiendo otra línea en el modelo hemos proporcionado datos existentes a nuestro modelo de Usuarios. Aún podemos generar un país aleatorio, basado en los países que soporta nuestra aplicación. Vamos a probar nuestros cambios utilizando el siguiente comando:
|
1 |
fakeit console --count 1 models/users.yaml |
Productos Modelo
Nuestra aplicación de comercio electrónico está utilizando un sistema separado para la categorización, necesitamos exponer esos datos a nuestros productos generados aleatoriamente para que estemos utilizando información de categoría válida. Comenzaremos con el products.yaml que definimos en la sección FakeIt Serie 2 de 5: Datos compartidos y dependencias puesto.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
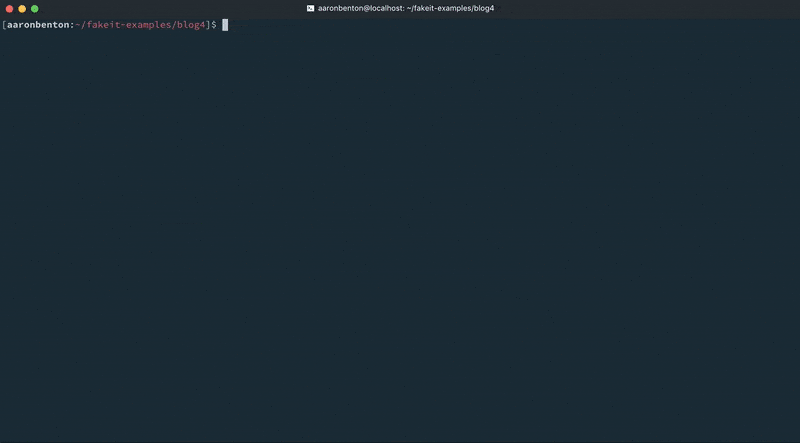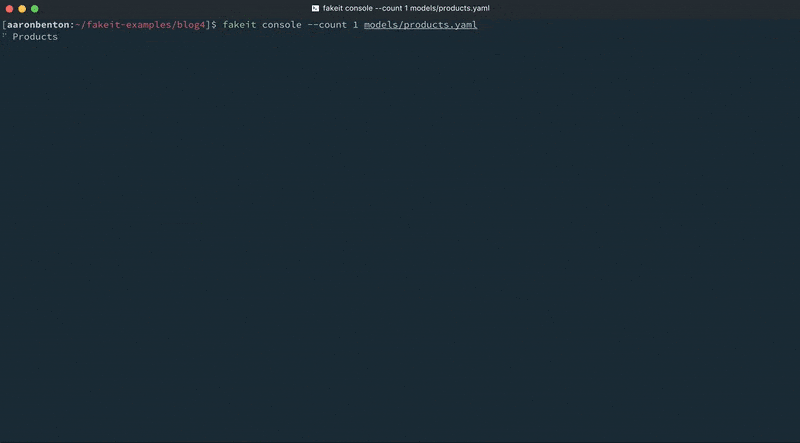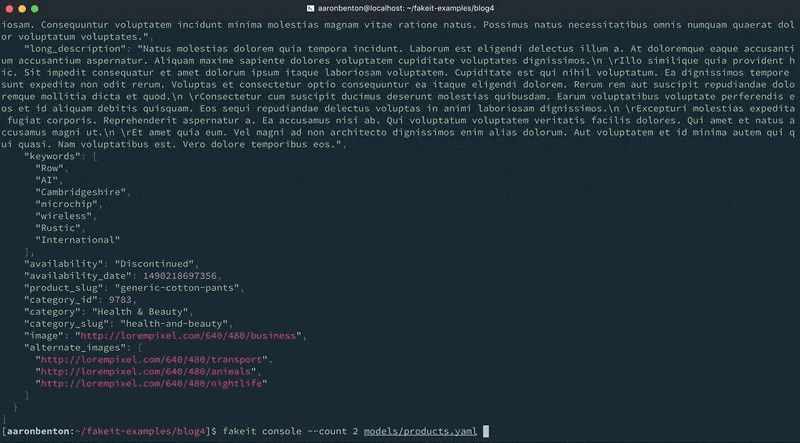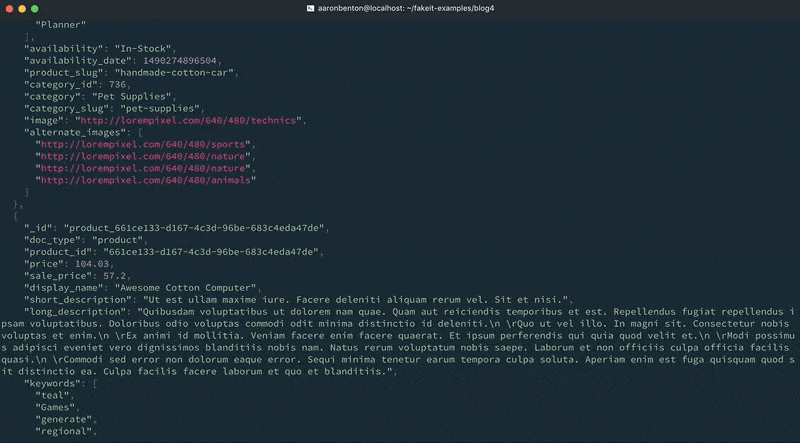
products.yaml name: Products type: object key: _id data: min: 4000 max: 5000 properties: _id: type: string description: The document id data: post_build: `product_${this.product_id}` doc_type: type: string description: The document type data: value: product product_id: type: string description: Unique identifier representing a specific product data: build: faker.random.uuid() price: type: double description: The product price data: build: chance.floating({ min: 0, max: 150, fixed: 2 }) sale_price: type: double description: The product price data: post_build: | let sale_price = 0; if (chance.bool({ likelihood: 30 })) { sale_price = chance.floating({ min: 0, max: this.price * chance.floating({ min: 0, max: 0.99, fixed: 2 }), fixed: 2 }); } return sale_price; display_name: type: string description: Display name of product. data: build: faker.commerce.productName() short_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(1) long_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(5) keywords: type: array description: An array of keywords items: type: string data: min: 0 max: 10 build: faker.random.word() availability: type: string description: The availability status of the product data: build: | let availability = 'In-Stock'; if (chance.bool({ likelihood: 40 })) { availability = faker.random.arrayElement([ 'Preorder', 'Out of Stock', 'Discontinued' ]); } return availability; availability_date: type: integer description: An epoch time of when the product is available data: build: faker.date.recent() post_build: new Date(this.availability_date).getTime() product_slug: type: string description: The URL friendly version of the product name data: post_build: faker.helpers.slugify(this.display_name).toLowerCase() category: type: string description: Category for the Product data: build: faker.commerce.department() category_slug: type: string description: The URL friendly version of the category name data: post_build: faker.helpers.slugify(this.category).toLowerCase() image: type: string description: Image URL representing the product. data: build: faker.image.image() alternate_images: type: array description: An array of alternate images for the product items: type: string data: min: 0 max: 4 build: faker.image.image() |
Los datos de nuestras categorías existentes se han facilitado en formato CSV.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
categories.csv "category_id","category_name","category_slug" 23,"Electronics","electronics" 1032,"Office Supplies","office-supplies" 983,"Clothing & Apparel","clothing-and-apparel" 483,"Movies, Music & Books","movies-music-and-books" 3023,"Sports & Fitness","sports-and-fitness" 4935,"Automotive","automotive" 923,"Tools","tools" 5782,"Home Furniture","home-furniture" 9783,"Health & Beauty","health-and-beauty" 2537,"Toys","toys" 10,"Video Games","video-games" 736,"Pet Supplies","pet-supplies" |
Ahora tenemos que actualizar nuestro modelo products.yaml para utilizar estos datos existentes.
(En aras de la brevedad, se han omitido las demás propiedades de la definición del modelo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Products type: object key: _id data: min: 4000 max: 5000 inputs: - ./categories.csv pre_build: globals.current_category = faker.random.arrayElement(inputs.categories); properties: ... category_id: type: integer description: The Category ID for the Product data: build: globals.current_category.category_id category: type: string description: Category for the Product data: build: globals.current_category.category_name category_slug: type: string description: The URL friendly version of the category name data: post_build: globals.current_category.category_slug ... |
Hay algunas cosas que notar acerca de cómo hemos actualizado nuestro modelo products.yaml.
- inputs: se define como una matriz, no como una cadena. Aunque sólo estamos utilizando una entrada, puede proporcionar tantos archivos de entrada a su modelo como sea necesario.
- Se define una función pre_build en la raíz del modelo. Esto se debe a que no podemos tomar un elemento de matriz al azar para cada una de nuestras tres propiedades de categoría, ya que los valores no coincidirían. Cada vez que se genere un documento individual para nuestro modelo, esta función pre_build se ejecutará primero.
- Cada una de nuestras funciones de construcción de propiedades de categoría hace referencia a la variable global establecida por la función pre_build en nuestro modelo.
Podemos probar nuestros cambios utilizando el siguiente comando:
|
1 |
fakeit console --count 1 models/products.yaml |
Conclusión
La posibilidad de trabajar con datos existentes es una característica extremadamente potente de FakeIt. Se puede utilizar para mantener la integridad de los documentos generados aleatoriamente para trabajar con el sistema existente, e incluso se puede utilizar para transformar los datos existentes e importarlos a Couchbase Server.
A continuación
Anterior
- FakeIt Serie 1 de 5: Generación de datos falsos
- FakeIt Serie 2 de 5: Datos compartidos y dependencias
- FakeIt Series 3 de 5: Modelos Lean a través de definiciones

Este post forma parte del Programa de Escritura de la Comunidad Couchbase