Couchbase es la base de datos documental NoSQL líder en el mundo. Ofrece un rendimiento, una flexibilidad y una escalabilidad inigualables en el perímetro, en las instalaciones y en la nube. Spark es uno de los entornos de computación en memoria más populares. Las dos plataformas pueden combinarse para ejecutar funciones de consulta, ingeniería de datos, ciencia de datos y aprendizaje automático increíblemente rápidas.
En este QuickStart, te guiaré a través de los sencillos pasos para configurar Couchbase con Databricks* y ejecutar consultas de datos de Couchbase y consultas SQL de Spark.
*Nota: Los pasos de este QuickStart se han validado con Databricks runtime 10.4 LTS.
Configurar
Requisitos previos
Para completar este QuickStart, necesitará lo siguiente:
-
- Un clúster Couchbase y viaje-muestra accesible al clúster Databricks. He utilizado un clúster Couchbase en una máquina AWS EC2.
- A Cuenta Databricks - hay disponibles pruebas gratuitas que requieren una cuenta de AWS, Azure o GCP.
- Couchbase conector de chispa versión 3.2.2, disponible en Maven:
- En la pantalla de creación del clúster, en la sección Bibliotecas pestaña. Seleccione Instale nuevo y busque el paquete en Maven Central. Vea el siguiente ejemplo:
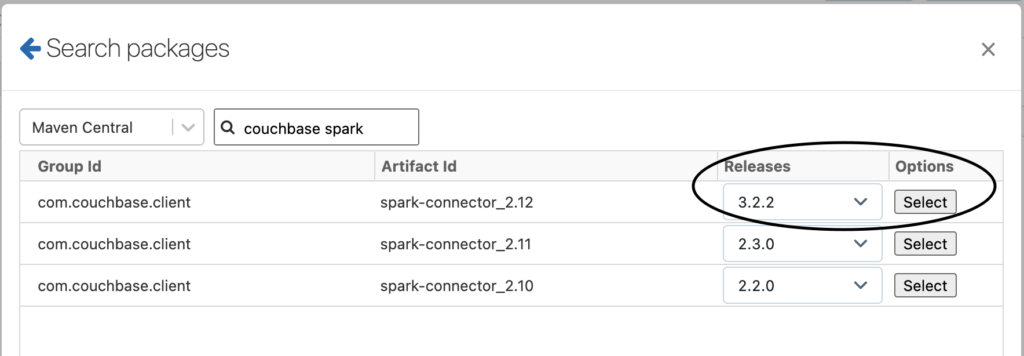
-
- En Instale se configurará como en el ejemplo siguiente:
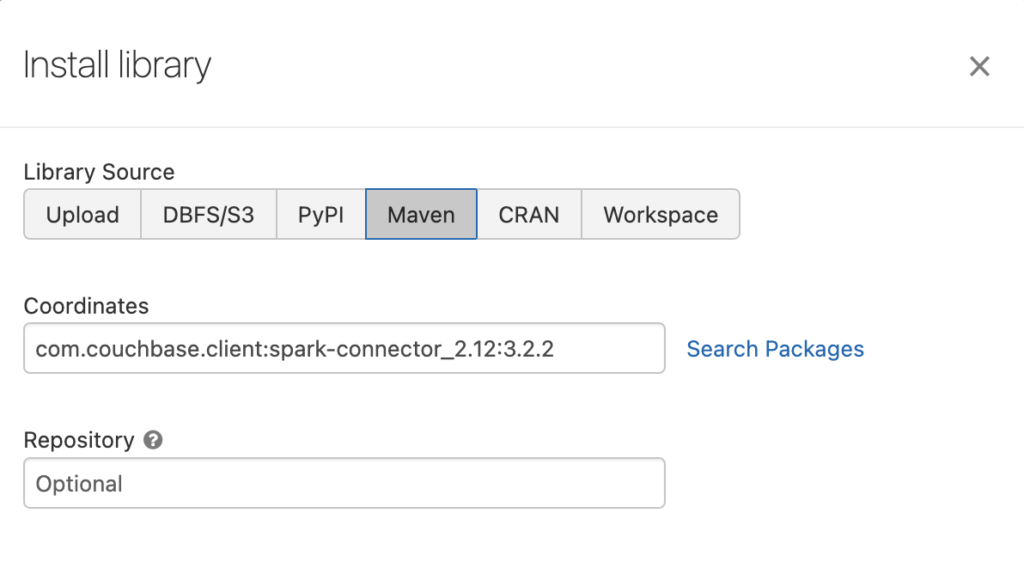
Configuración
Antes de empezar, necesitamos configurar los siguientes parámetros en el cluster Databricks opciones avanzadas Configuración de Spark. Esto se puede hacer al crear un clúster (véase la impresión de pantalla a continuación):
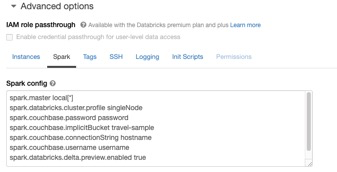
Puede copiar y pegar la configuración de abajo y sustituir los parámetros en <> con los valores de su clúster Couchbase en el campo opciones avanzadas Configuración de Spark:
|
1 2 3 4 5 |
spark.couchbase.password <password> spark.couchbase.implicitBucket <travel-sample> spark.couchbase.connectionString <hostname> spark.couchbase.username <username> spark.databricks.delta.preview.enabled true |
En primer lugar, vamos a ejecutar las importaciones necesarias. Copie el código de ejemplo a continuación en un cuaderno en blanco conectado a un clúster con la configuración anterior
|
1 2 3 4 5 6 7 8 9 10 11 |
import com.couchbase.spark._ import org.apache.spark.sql._ import com.couchbase.client.scala.json.JsonObject import com.couchbase.spark.kv.Get import com.couchbase.client.scala.kv.MutateInSpec import com.couchbase.spark.kv.MutateIn import com.couchbase.client.scala.kv.LookupInSpec import com.couchbase.spark.kv.LookupIn import com.couchbase.client.scala.query.QueryOptions import com.couchbase.spark.query.QueryOptions import com.couchbase.client.scala.analytics.AnalyticsOptions |
Ahora, vamos a obtener algunos documentos por claves desde Couchbase viaje-muestra utilizando el siguiente código:
|
1 2 3 4 |
sc .couchbaseGet(Seq(Get("airline_10"), Get("airline_10642"))) .collect() .foreach(result => println(result.contentAs[JsonObject])) |
Genial, nos hemos conectado al clúster y hemos devuelto nuestro primer RDD (Resilient Distributed Dataset).
Podemos consultar los datos usando SQL++ (lenguaje de consulta de Couchbase basado en SQL). Ejecuta el siguiente código como ejemplo:
|
1 2 3 4 |
sc .couchbaseQuery[JsonObject]("select country, count(*) as count from `travel-sample` where type = 'airport' group by country order by count desc") .collect() .foreach(println) |
Consulta del servicio de análisis
Couchbase también ofrece un servicio de análisis para el análisis operativo y análisis en tiempo real a continuación es un ejemplo de una consulta de análisis:
|
1 2 |
val query = "SELECT ht.city,ht.state,COUNT(*) AS num_hotels FROM `travel-sample`.inventory.hotel ht GROUP BY ht.city,ht.state HAVING COUNT(*) > 30" sc.couchbaseAnalyticsQuery[JsonObject](query).collect().foreach(println) |
Pasemos ahora a Spark SQL
Utilice el código siguiente para crear vistas temporales para líneas aéreas y aeropuertos Marcos de datos:
|
1 2 3 4 5 6 7 8 9 |
val airlines = spark.read.format("couchbase.query") .option(QueryOptions.Filter, "type = 'airline'") .load() airlines.createOrReplaceTempView("airlines") val airports = spark.read.format("couchbase.query") .option(QueryOptions.Filter, "type = 'airport'") .load() airports.createOrReplaceTempView("airports") |
Ahora podemos ejecutar consultas Spark SQL en las vistas, por ejemplo:
Obtener las compañías aéreas en orden ascendente:
|
1 |
%sql select * from airlines order by name asc limit 10 |
Obtenga las compañías aéreas agrupadas por países:
|
1 |
%sql select country, count(*) from airlines group by country; |
Y por último, visualicemos los aeropuertos por país utilizando un UDF (User Defined Function) junto con la función de mapeo de Databricks. Crear el UDF utilizando el SQL ++ a continuación:
|
1 2 3 4 5 6 7 8 |
val countrymap = (s: String) => { s match { case "France" => "FRA" case "United States" => "USA" case "United Kingdom" => "GBR" } } spark.udf.register("countrymap", countrymap) |
Seleccione los recuentos de aeropuertos por país y visualice los resultados:
|
1 |
%sql select countrymap(country), count(*) from airports group by country; |
Después de completar este Quickstart, su resultado debe ser similar a la visualización de abajo:
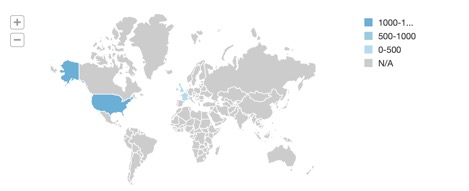
Lo que hemos conseguido
En este QuickStart, he descrito cómo utilizar el spark-connector de Couchbase con Databricks para crear RDDs, ejecutar consultas SQL de Couchbase y Spark, crear un UDF, y utilizar la función de mapeo de Databricks para visualizar los resultados. Estos pasos demuestran el proceso utilizado para acceder, analizar y visualizar datos en un clúster Couchbase desde una interfaz de cuaderno Databricks.
Próximos pasos
Más información Couchbase Capella:
-
- Prueba Capella suscribiéndote a un prueba gratuita de 30 días.
- Conecte su grupo de prueba al Playground o conecta un proyecto para probarlo por ti mismo.
- Visite el Portal para desarrolladores de Couchbase que toneladas de tutoriales/guías de inicio rápido y vías de aprendizaje que le ayudarán a empezar.
- Consulte la documentación para obtener más información sobre los SDK de Couchbase.
Gracias por leer este post. Si tiene alguna pregunta o comentario, por favor conecte con nosotros en el Couchbase Foros