Los microservicios requieren un conjunto de componentes escalable y sostenible. Este post presenta cómo construir microservicios usando Python y Couchbase para proporcionar una solución totalmente escalable.
Las aplicaciones monolíticas presentan muchos retos. Nacieron en una época en la que todo se ejecutaba en un único sistema, normalmente un mainframe o un miniordenador. Arquitectura orientada a servicios liberó las aplicaciones, permitiéndoles utilizar colecciones de servidores básicos no compartidos y escalables. Permitía escalar discretamente partes de un entorno de aplicaciones según fuera necesario. Hoy en día, tenemos patrones similares, excepto que los servidores han sido sustituidos por máquinas virtuales o instancias en la nube.
Algunas arquitecturas orientadas a servicios son colecciones de aplicaciones pequeñas o grandes que necesitan interoperar. Esto permite cierta desagregación y escalado horizontal, pero no resuelve todos los problemas para lograr una escalabilidad global de la nube, porque cada servicio suele ser una aplicación monolítica. Las grandes aplicaciones no sólo son difíciles de escalar, sino también de desarrollar. Requieren mucha codificación y mantenimiento. Las simples actualizaciones de código pueden requerir pruebas de regresión completas, lo que exige un esfuerzo considerable.
Introduzca el Arquitectura de microservicios. Este patrón arquitectónico divide cada componente de la aplicación en pequeñas piezas que pueden escalarse independientemente. Suelen ser apátridas, de modo que pueden activarse y desactivarse cuando sea necesario. El principal reto es la latencia de la red, pero no suele ser un problema porque las redes de alta velocidad son omnipresentes hoy en día.
Diseño de microservicios
Un buen microservicio debe ser ligero y sin estado. El objetivo de un Arquitectura de microservicios es dividir la funcionalidad de la aplicación en componentes discretos que funcionen de forma independiente. Cada microservicio debe servir a un área funcional de la aplicación global. Lo más importante es que cada microservicio pueda evolucionar independientemente del resto de la aplicación. Esto funciona bien con un Metodología de desarrollo ágilque permite a los equipos ofrecer rápidamente nuevas funciones sin afectar a la aplicación en su conjunto.
Se ha dicho que los microservicios deben diseñarse para el fracaso. Esto puede sonar extraño al principio, pero tiene mucho sentido si se tiene en cuenta la naturaleza y el ciclo de vida de un microservicio. Un buen microservicio debe ser efímero. Dado que no tienen estado, debería ser posible añadir y eliminar instancias de microservicio sin afectar a la aplicación.
Dado que los microservicios estarán en perpetuo cambio, toda interacción con ellos debe realizarse a través de un estilo de API que funcione bien en este entorno. Como tal, Interfaces RESTful son una buena opción para el diseño de la API. Las llamadas REST son efímeras y funcionan bien detrás de un equilibrador de carga de red (que es un método para hacer que los microservicios basados en REST sean altamente disponibles y escalables).
Por último, deben ser fáciles de desplegar y automatizar con herramientas DevOps populares. Cada servicio debe poder ejecutarse en un sistema con otros servicios o en un contenedor. Kubernetes, una tecnología de orquestación de contenedores, se creó esencialmente para microservicios.
Creación de un microservicio de perfil de usuario
Es difícil crear una aplicación completa a partir de microservicios. La lógica empresarial principal a menudo debe ser proporcionada por alguna aplicación que no puede reescribirse con microservicios. Por ejemplo, es posible que necesite interactuar con una pila de aplicaciones ERP o CRM estándar. Pero para aplicaciones Web y Móviles, es un patrón común para front-end tales grandes sistemas con microservicios para controlar la experiencia del usuario final.
Los consumidores de tecnología quieren una experiencia rápida y personalizada cuando interactúan con una aplicación web o móvil. Con los microservicios, puede distribuir globalmente los elementos más utilizados de la capa de presentación para que estén geográficamente cerca del usuario final. También puede escalar de forma independiente estos componentes en función de los patrones de uso.
Un componente frecuente de una aplicación web o móvil es el concepto de perfil de usuario. Suele ser el icono de la "silueta de una persona" en la parte superior derecha de la interfaz de usuario. Los perfiles de usuario pueden ser simplistas, con información demográfica básica, o muy detallados, con abundante información sobre preferencias e historial para impulsar cambios personalizados en la experiencia del usuario.
Esta serie de entradas de blog analiza el uso de Python para proporcionar una interfaz RESTful a los datos de perfil de usuario alojados en una base de datos Couchbase. Utilizaremos un ejemplo sencillo con un esquema básico con fines ilustrativos. Sin embargo, puedes mejorar este ejemplo tanto como necesites para una aplicación del "mundo real".
¿Por qué usar Couchbase para microservicios?
Couchbase combina múltiples elementos de procesamiento de datos en una plataforma de datos unificada. Couchbase incluye un motor clave-valor, soporte para esquemas relacionales, un completo motor de consulta SQL, un completo motor de búsqueda de texto, un motor de eventos y un motor de análisis. Proporciona tiempos de respuesta de microsegundos y elimina la necesidad de que las organizaciones elijan sistemas distintos para cargas de trabajo diferentes.
Un servicio de perfil de usuario suele ser un servicio al que se accede con frecuencia. Como mínimo, junto con la autorización y la autenticación, se accede a él cada vez que un usuario inicia sesión en una aplicación. Sin embargo, lo más probable es que haya que acceder a él muchas veces mientras alguien interactúa con una aplicación. Por ello, el rendimiento y la latencia serán características esenciales del diseño.
La arquitectura de memoria de Couchbase le permite ofrecer un rendimiento increíblemente rápido. El rendimiento de Couchbase es casi lineal gracias a su arquitectura scale-out, shared-nothing, que le permite mantener el rendimiento y las latencias a medida que se escala el clúster. Couchbase puede escalar junto con los elementos de microservicio porque la arquitectura de microservicio también es escalable y no se comparte.
Couchbase está diseñado para eliminar muchas tareas administrativas tradicionales. Couchbase aprovecha un modelo dinámico de contención de datos con auto-sharding y reequilibrio de datos, y separando la gestión de índices de la gestión de datos. Con la Oferta de Capella Couchbase Cloudo on-prem con herramientas como Terraform o Kubernetes y el Operador autónomo de CouchbaseLos cambios en las bases de datos y los microservicios pueden automatizarse y orquestarse a través de nubes privadas y públicas.
¿Por qué Python?
Esta puede ser la pregunta que más te ronda por la cabeza mientras lees este post. Algo como Node.js puede ser el primer lenguaje que te venga a la mente. De hecho, por Berkeley JavaScript es el lenguaje más demandado, sin embargo, Python es el segundo. Python es muy accesible, ya que forma parte de la distribución de software para Linux y macOS y se puede instalar fácilmente en Windows. Se pueden tener varias versiones del lenguaje instaladas, y la función de entorno virtual facilita tener varios entornos personalizados utilizando diferentes versiones del lenguaje. Aunque Python admite multihilo, sus hilos no son tan eficaces como los de un lenguaje como Java. Aún así, Python es ligero, por lo que se adapta bien al multiprocesamiento y tiene paquetes que facilitan el envío de hilos o procesos. Lo mejor de Python es que es fácil de aprender y de programar.
Ejemplo de recorrido por la aplicación
Para demostrar el concepto, he creado un microservicio Python de ejemplo (el código está en GitHub) que proporciona una interfaz RESTful muy sencilla para acceder a la información del perfil de usuario. Couchbase soporta tipos de documento JSON, UTF-8 (string), o binario (raw). El formato JSON se considera el formato nativo y permite muchas características ricas en la plataforma, por lo que ese es el formato de documento que vamos a utilizar.
Nuestro perfil de usuario, muy sencillo, contiene el nombre del usuario y otros detalles básicos sobre su cuenta. El perfil incluye una imagen que hace referencia a un registro independiente que contiene el archivo de imagen codificado en Base64. Podríamos haber utilizado el tipo de documento RAW, pero pusimos la imagen en un valor JSON para este ejemplo.
También aprovechamos la función de ámbitos y colecciones que se introdujo con Couchbase Server 7. Los documentos de perfil de usuario se almacenan en el datos_usuario y las imágenes se almacenan en el imágenes_usuario como se ilustra aquí:
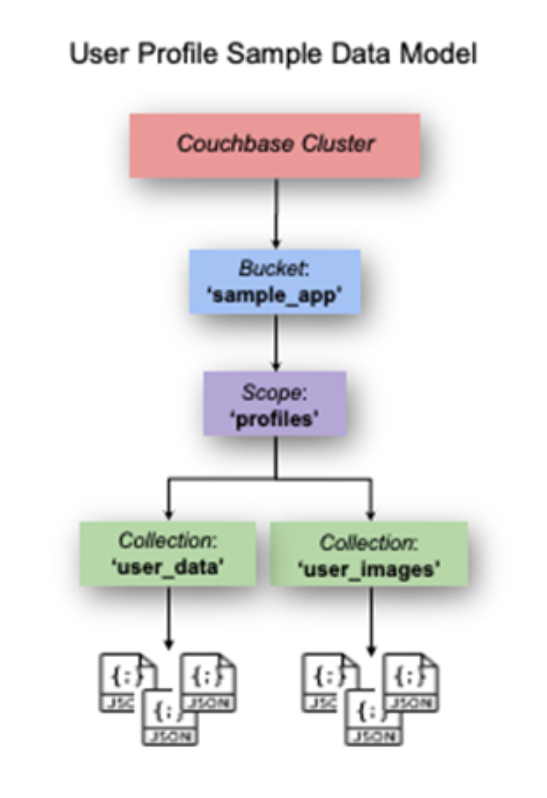
Formato del documento de perfil de usuario:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "record_id": "1", "name": "Jessica Lopez", "nickname": "jlopez", "picture": "1", "user_id": "jessicalopez9483", "email": "jessica.lopez@example.com", "email_verified": "False", "first_name": "Jessica", "last_name": "Lopez", "address": "6699 West Road", "city": "Weirton", "state": "OR", "zip_code": "21243", "phone": "306-402-6984", "date_of_birth": "03/05/1961" } |
Formato de documento de imagen de usuario:
|
1 2 3 4 5 |
{ "record_id": "1", "type": "jpeg", "image": " AAAADGpQICANC…=" } |
El microservicio de Python tiene la opción de ejecutarse en primer plano, donde la salida se envía a la pantalla (terminal), o en segundo plano como "demonio", donde la salida se envía a un archivo de registro. El código utiliza la función de clases orientadas a objetos de Python para realizar la mayor parte del trabajo.
En dbConnection está diseñada para contener punteros a objetos relacionados con la conexión a la base de datos Couchbase. Esto sólo hace que sea fácil pasar estos alrededor de otras clases y funciones.
En couchbaseDriver se encarga de la interacción con la base de datos. El sitio conecte inicia una conexión con el cluster de Couchbase. Crea objetos para acceder al bucket, scope y colecciones pasadas a la función. Almacena esos objetos en un dbConnection que se almacena en la clase. La dirección consiga realiza una recuperación clave-valor de la clave pasada a la función desde la colección referenciada aprovechando la conexión establecida. La dirección consulta realiza una SQL SELECCIONE en el campo JSON de la colección referenciada buscando una clave JSON que sea igual al valor especificado.
En restServer es una clase manejadora diseñada para ser pasada a la clase Python servidor.http módulo. Implementa la interfaz RESTful. Existen GET para encontrar datos de perfil de usuario basados en el apodo, nombre de usuario o ID. También tiene puntos finales para obtener imágenes de perfil, ya sea recuperando el documento JSON o devolviendo la propia imagen. Esto tiene una ventaja sobre otros marcos de desarrollo REST que a menudo sólo soportan responder a puntos finales REST con contenido JSON.
Por último, el microServicio inicia y detiene el servidor HTTP. Se llama desde principal que utiliza el couchbaseDriver para conectar con la base de datos e iniciar el microservicio. El microservicio completo solo tiene unos cientos de líneas de código, y puede desplegarse fácilmente en cualquier lugar, y adjuntarse a cualquier clúster de Couchbase.
Siguiente
En la siguiente parte de esta serie, hablaremos sobre la generación de datos de prueba aleatorios para el esquema de microservicios y las pruebas de rendimiento.
Consulte estos recursos cuando investigue más sobre estos temas:
