Todos los casos de uso del aprendizaje automático tienen diferentes necesidades de rendimiento, y cuando se trata de sistemas empresariales de predicción basados en ML, no es diferente.
Un modelo de aprendizaje automático toma una entrada (por ejemplo, una imagen) y realiza una predicción sobre ella (por ejemplo, qué objeto aparece en la imagen). Una vez que el modelo de ML se ha entrenado con datos históricos (por ejemplo, un conjunto de imágenes antiguas), se despliega en un sistema de predicción para realizar predicciones con datos nuevos.
Una empresa puede construir su propio sistema de predicción o utilizar un sistema de un proveedor en la nube. En cualquier caso, el sistema de predicción necesita almacenamiento para las predicciones, los metadatos del modelo y las entradas o características que se pasan a los modelos.
Este artículo describe diferentes arquitecturas para servir aprendizaje automático de predicción en tiempo real en producción y cómo el Plataforma de datos Couchbase satisface diversas necesidades de almacenamiento de un sistema de servicio de predicción empresarial.
Terminología
Antes de entrar en detalles, veamos algunos términos utilizados en este artículo.
-
- Sistema Servidor de Predicciones: Sistema que toma un modelo de aprendizaje automático entrenado y nuevos datos como entrada y devuelve una predicción como salida.
- Modelo entrenado: Una estructura de datos estadísticos que contiene los pesos y sesgos obtenidos del proceso de entrenamiento.
- Características: Atributos de los datos que son relevantes para el proceso de predicción.
Al hacer una predicción en tiempo real, por ejemplo, considere un problema de regresión lineal simple como: y = b1 x1 + b2 x2 ... + bn xn ...
-
- Las características son x1, x2, ...
- El modelo entrenado es una estructura de datos que contiene valores para b1, b2, .... Estos valores se aprendieron mediante el proceso de formación.
- El sistema de predicción toma las características y el modelo como entrada y devuelve la predicción. y como salida.
Requisitos de rendimiento de un sistema de predicción en tiempo real
Los distintos casos de uso del aprendizaje automático de predicción en tiempo real tienen necesidades de rendimiento diferentes.
Con las predicciones en tiempo real, por ejemplo, una aplicación web interactiva puede requerir que las predicciones se entreguen en decenas de milisegundos, mientras que una aplicación de juegos puede necesitar una latencia de predicción inferior al milisegundo. El sistema de predicción puede tener que atender un gran volumen de peticiones y escalar para gestionar cargas de trabajo dinámicas.
Diferentes tipos de bases de datos gestionan estas diferentes necesidades de rendimiento. Un importante proveedor de servicios en la nube recomienda tres bases de datos NoSQL diferentes para su sistema de predicción. Múltiples productos de bases de datos de este tipo se combinan para gestionar un único caso de uso. El resultado es una arquitectura compleja para el sistema de predicción.
En este artículo, verá cómo Couchbase sustituye a varios de datos utilizados en un sistema de predicción. Esto reduce la complejidad, la sobrecarga operativa y el coste total de propiedad (TCO). Con Couchbase, la carga de trabajo operativa, analítica y de IA/ML coexiste en la misma plataforma de datos.
Servidor Couchbasecon caché de documentos integrada, ofrece un alto rendimiento sostenido y una latencia constante por debajo del milisegundo, superando a otros productos NoSQL como MongoDB y DataStax Cassandra. (Consulte Puntos de referencia de Couchbase y Caché de alto rendimiento de Couchbase para más información).
El rendimiento de un sistema de servicio de predicción depende de su arquitectura y del rendimiento de sus componentes. A su vez, la arquitectura de un sistema determinado depende del caso de uso. Veamos con más detalle algunos de los casos de uso más comunes del servicio de predicciones.
Caso de uso #1: Predicciones en tiempo real con datos brutos almacenados en Couchbase
Utilicemos como ejemplo la predicción en tiempo real de la tasa de rotación de clientes.
Una empresa ficticia llamada ACME quiere identificar a los clientes que probablemente dejarán de utilizar sus productos. La empresa entrena un modelo de predicción de bajas a partir de datos históricos de clientes y lo despliega en producción para obtener puntuaciones de bajas de nuevos clientes en tiempo real mediante aprendizaje automático de predicción.
Una forma sencilla de que ACME configure un sistema de servicio de predicciones es la que se muestra en el diagrama de casos de uso de la Figura 1.
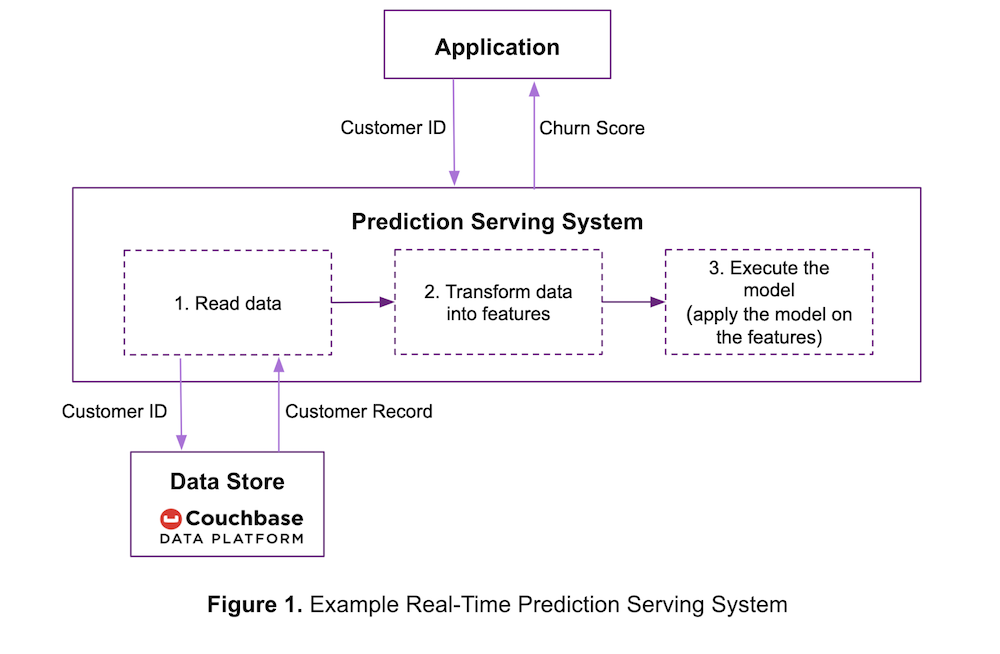
Para conocer la puntuación de rotación de un cliente, una aplicación ACME envía el ID del cliente al sistema de predicción. A continuación, el sistema de predicción:
- Lee los datos brutos del cliente del almacén de datos.
- Transforma los datos en características esperadas por el modelo, por ejemplo, un valor verdadero o falso se convierte en 0 o 1.
- Aplica el modelo entrenado sobre las características para calcular la predicción y la devuelve a la aplicación.
Si el modelo entrenado es también un pipeline, que transforma los datos en características, entonces se combinan los pasos 2 y 3. Para que las predicciones sean lo más oportunas posible, el sistema debe completar todos los pasos anteriores en el menor tiempo posible.
Si ACME almacenara sus datos de entrada en la plataforma de datos Couchbase de baja latencia de lectura, como se muestra en la Figura 1, se reduciría el tiempo necesario para completar el paso 1. Por supuesto, Couchbase también podría ser una base de datos operativa que sirviera al mismo tiempo a otras aplicaciones de ACME.
Si el sistema servidor de predicciones no requiere un todo entonces la API de sub-documento de Couchbase le ayuda a acceder sólo a las partes de los documentos JSON que necesita. El uso de la API de subdocumentos mejora el rendimiento y la eficiencia de E/S de la red, especialmente cuando se trabaja con documentos de gran tamaño.
Caso práctico #2: predicciones en tiempo real con funciones almacenadas en Couchbase
Para mejorar el rendimiento, ACME puede decidir preprocesar los datos de entrada y almacenarlos en un almacén de características, como se muestra en la figura 2.
Las ventajas de este planteamiento son las siguientes:
-
- Las características están disponibles para una búsqueda rápida mientras se hacen predicciones.
- Los datos no tienen que transformarse en características cada vez que se actualiza el modelo. Esto supone una ventaja frente a las canalizaciones de modelos.
- Las funciones pueden reutilizarse en varios modelos.
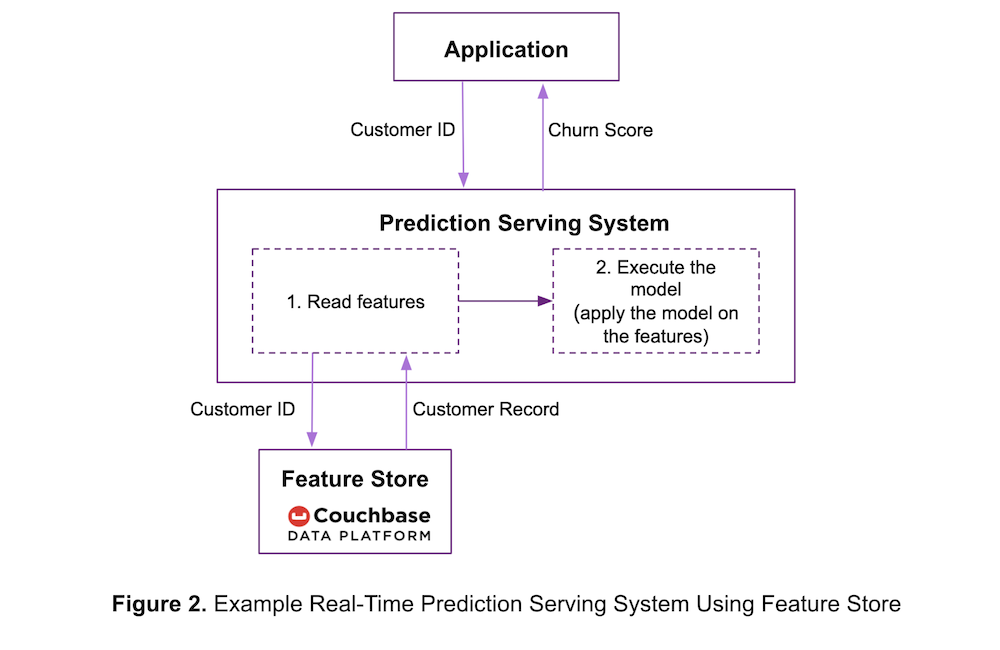
En esta arquitectura, el sistema servidor de predicciones:
- Lee funciones del almacén de funciones.
- Aplica el modelo entrenado a las características para generar una predicción y devuelve la predicción a la aplicación.
Si ACME almacena las características en la plataforma de datos Couchbase de rápida ingesta de datos, las características se escriben rápidamente. Como antes, la baja latencia de lectura que proporciona Couchbase reduce el tiempo necesario para ejecutar el paso 1, reduciendo a su vez la latencia de predicción.
El tiempo necesario para ejecutar el paso 2 depende del rendimiento del modelo. Los modelos lineales más sencillos son rápidos, pero los modelos sofisticados, como las redes neuronales profundas, son intensivos desde el punto de vista computacional y pueden tardar más en generar predicciones. Los usuarios pueden tener que simplificar los modelos complejos o utilizar aceleradores de hardware para reducir el tiempo que tarda el paso 2.
Caso de uso #3: Predicciones precalculadas almacenadas en caché en Couchbase
El servicio de atención al cliente de ACME tiene un problema: cuando un cliente llama para quejarse, necesitan saber su nivel de rotación y su puntuación. rápidamente.
Esperar a que el servicio de predicción calcule la puntuación de cancelación en tiempo real no es una opción. Para solucionarlo, ACME puede decidir precalcular las predicciones mediante un trabajo por lotes, como se muestra en la figura 3.
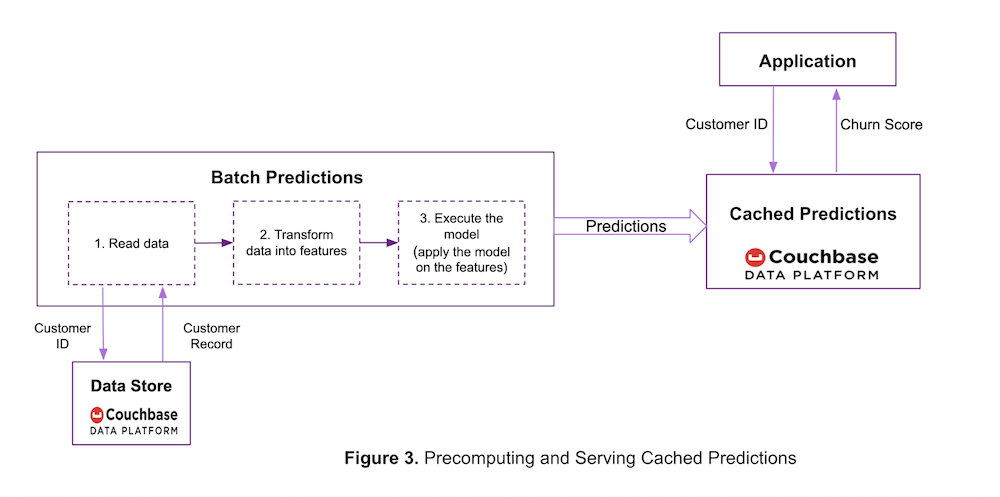
En esta arquitectura, el paso de ejecución del modelo no se encuentra en la ruta crítica de servir predicciones y, como resultado, la complejidad del modelo (redes neuronales simples frente a profundas) puede no ser relevante.
En este caso, la plataforma de datos Couchbase se utiliza con dos fines:
- Almacenamiento de los datos brutos (o características) necesarios para realizar predicciones en el trabajo por lotes.
- Almacenamiento en caché de las predicciones precalculadas para servirlas con un alto rendimiento y una latencia de lectura inferior al milisegundo. El ID de cliente se utiliza como clave para las predicciones precalculadas.
Por defecto, Couchbase persiste las predicciones almacenadas en caché en el disco. Pero si las predicciones se regeneran periódicamente y su persistencia no es necesaria, ACME puede almacenarlas en caché en buckets efímeros de Couchbase. Esto mejora aún más el rendimiento al reducir la sobrecarga de disco en segundo plano y disminuye los costes de almacenamiento en disco. (Más información sobre el uso de cubos efímeros con cubos Couchbase.)
Además de la ganancia de rendimiento al almacenar en caché las predicciones en Couchbase, hay otras ventajas de usar la Plataforma de Datos de Couchbase. Las predicciones almacenadas en caché pueden ser indexadas usando el servicio Index de Couchbase y usadas para ejecutar consultas usando el servicio Query de Couchbase. Por ejemplo, los usuarios pueden ejecutar una Consulta N1QL de Couchbase para identificar a los clientes de alto riesgo cuya tasa de rotación se prevé que supere un determinado umbral. El departamento de marketing de ACME puede utilizar esta información para dirigir ofertas promocionales a estos clientes.
Couchbase soporta escalado multidimensional donde cada servicio-datos, índices, consultas, eventos, análisis-puede ser escalado independientemente. Esto también proporciona aislamiento de la carga de trabajo, de modo que la carga de trabajo de, por ejemplo, el servicio de consulta no interfiere con la del servicio de datos.
Caso de uso #4: Predicciones basadas en eventos con datos almacenados en Couchbase
El servicio de atención al cliente de ACME tiene un nuevo requisito: Quieren que la puntuación de rotación de un cliente se vuelva a calcular cada vez que cambie el registro del cliente.
Para gestionar este caso de uso, ACME puede decidir generar predicciones casi en tiempo real en respuesta a un suceso y almacenarlas en caché para más tarde, como se muestra en la figura 4.

Este caso de uso también muestra el papel que desempeñan los metadatos del modelo en el proceso de predicción.
Los metadatos del modelo son información sobre el modelo, como su nombre, número de versión, cuándo se entrenó, etcétera. También pueden incluir las métricas de rendimiento del modelo, como la latencia media de predicción y la precisión.
En este ejemplo, los metadatos del modelo se utilizan para identificar las características esperadas por el modelo entrenado. Dado que este paso se realiza durante el proceso de predicción, los metadatos del modelo también deben almacenarse en un almacén de búsqueda rápida.
Como se ve en la Figura 4, un único cluster de Couchbase puede almacenar los metadatos del modelo, así como las características y predicciones. Cada uno de estos tipos de datos puede almacenarse en un bucket separado de Couchbase. Couchbase soporta multi-tenancy, es decir, la posibilidad de que más de una aplicación almacene y recupere información dentro de Couchbase. Los buckets son los elementos lógicos utilizados para soportar multi-tenancy.
Caso práctico #5: predicciones entre centros de datos con Couchbase
ACME se está expandiendo como empresa. Para protegerse de los fallos de los centros de datos y servir predicciones de baja latencia en distintas geografías, despliega el sistema de servicio de predicciones en varios centros de datos, como se muestra en la Figura 5.
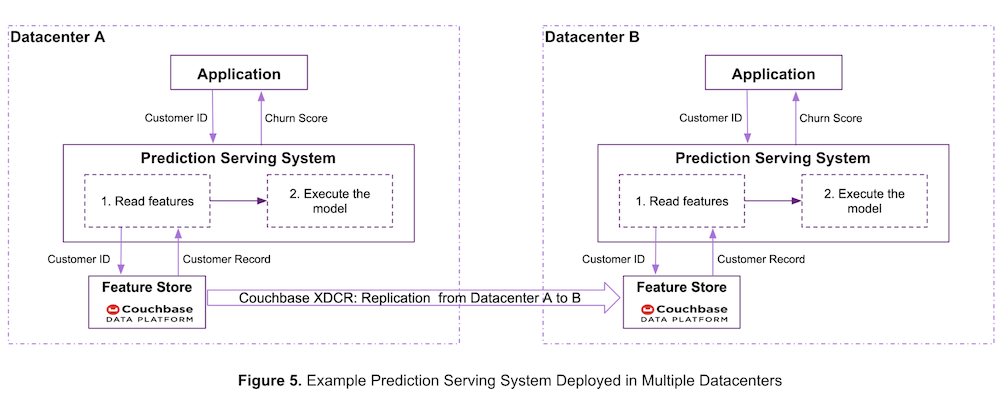
ACME utiliza la tecnología de replicación entre centros de datos (XDCR) de Couchbase, que permite a los clientes desplegar aplicaciones geodistribuidas con alta disponibilidad en cualquier entorno (on-prem, nube pública y privada, o nube híbrida). Consulte la documentación de Couchbase XDCR para más información sobre esta tecnología.
Como se ve en la Figura 5, ACME almacena las funciones en el servidor Couchbase y utiliza la función XDCR de Couchbase para replicar las funciones desde el centro de datos A al centro de datos B.
La figura 6 muestra otra forma de que ACME sirva predicciones entre centros de datos.
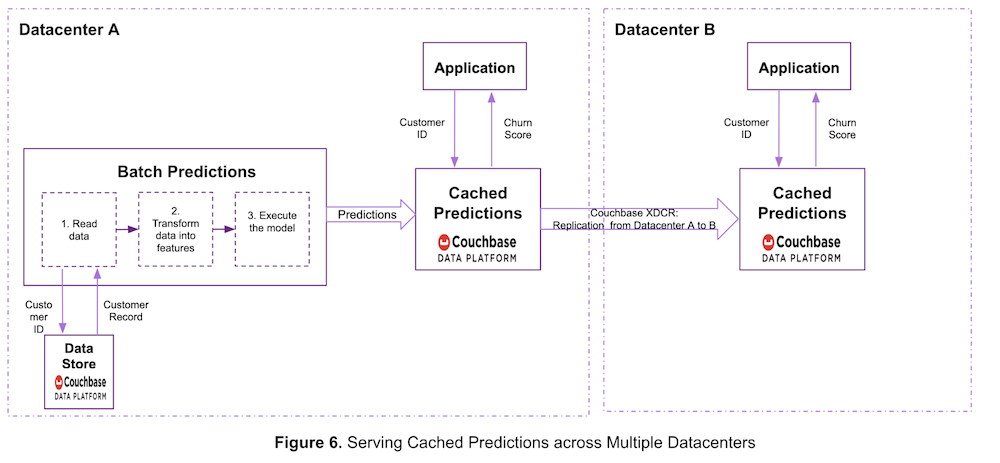
En este caso, el sistema de servicio de predicciones se despliega en un único centro de datos. Las predicciones se generan en el centro de datos A, se almacenan en caché en Couchbase y se replican en otros centros de datos mediante Couchbase XDCR.
La replicación entre centros de datos es independiente de la infraestructura. En los ejemplos anteriores, el centro de datos A y el centro de datos B pueden ejecutarse en el mismo entorno de nube o en entornos diferentes, o incluso en infraestructuras diferentes como on-prem y cloud.
Couchbase cumple otros requisitos de los sistemas servidores de predicciones
Couchbase también se puede utilizar para almacenar metadatos de características. Esta es la descripción de cada característica en un almacén de características. Los metadatos pueden incluir el nombre de la característica, cómo fue creada, su esquema y demás. Las características pueden compartirse entre varios modelos de aprendizaje automático. Los metadatos de características ayudan a los usuarios a descubrir características que son relevantes para sus modelos.
Couchbase permite acceder a los datos con una baja latencia constante y un alto rendimiento sostenido. Además de satisfacer sus necesidades de rendimiento, Couchbase también satisface los siguientes requisitos de base de datos de un sistema de servicio de predicciones de nivel de producción.
Escalabilidad
A medida que aumenta la carga de trabajo de predicción, el almacén de datos debe seguir ofreciendo el mismo rendimiento constante. Debe ser capaz de escalar lineal y fácilmente sin afectar negativamente al rendimiento del sistema de predicción.
Couchbase Server está diseñado para proporcionar escalabilidad lineal y elástica mediante el acceso inteligente y directo de datos de aplicación a nodo sin enrutamiento ni proxy adicionales. Añadir o eliminar nodos se hace en minutos con la simplicidad de pulsar un botón, sin tiempo de inactividad o cambios de código.
Disponibilidad
Para mantener la disponibilidad de su sistema de división de predicciones, la base de datos debe estar siempre disponible tanto durante las interrupciones planificadas como durante las imprevistas.
Couchbase Server está diseñado para ser tolerante a fallos y altamente resistente a cualquier escala y en cualquier plataforma -física o virtual-, ofreciendo una disponibilidad permanente en caso de fallos de hardware o ventanas de mantenimiento planificadas.
Manejabilidad
El almacén de datos no debe suponer una carga excesiva para el equipo de despliegue y operaciones del sistema de predicción. Debe ser razonablemente rápido de desplegar y fácil de supervisar y gestionar.
Couchbase soporta múltiples métodos de despliegue incluyendo nube híbrida y contenedores Docker con el Operador Autónomo Couchbase. La página Operador autónomo de Couchbase proporciona integración nativa de Couchbase Server con Kubernetes de código abierto y Red Hat OpenShift. Permite a los usuarios automatizar la gestión de tareas comunes de Couchbase, como la configuración, creación, escalado y recuperación de clústeres de Couchbase.
Seguridad
Una base de datos segura es fundamental para la seguridad y la integridad generales de su sistema de servicio de predicción empresarial.
Couchbase proporciona cifrado de datos de extremo a extremo, tanto por cable como en reposo. Las opciones de seguridad flexibles son posibles con la autenticación basada en roles y los datos incrustados, y las herramientas de auditoría administrativa permiten un control sólido de los datos de su empresa.
Conclusión
Ya has visto cinco ejemplos reales de cómo se utiliza Couchbase para almacenar datos de entrada sin procesar, características, predicciones y metadatos de modelos. Tanto si estás comprando un sistema de predicción empresarial como si estás construyendo el tuyo propio, la plataforma de datos de Couchbase ofrece el máximo rendimiento y resultados en tiempo real para que maximices el valor de tus predicciones de aprendizaje automático.
Aquí tienes algunas formas de empezar y probar Couchbase por ti mismo:
-
- Comience su prueba gratuita de Couchbase Cloud - no requiere instalación.
- Profundice en los detalles técnicos con este libro blanco: Couchbase bajo el capó: una visión general de la arquitectura.
- Explora la Consulta, Búsqueda de texto completo, Eventosy Analítica que ofrece Couchbase.
