Implantar una solución de supervisión del rendimiento
Utilice la última versión comercial de Couchbase
Dimensione su infraestructura en consecuencia
Utilizar declaraciones preparadas
Optimizar índices
Hay muchos pasos en el camino hacia un mejor rendimiento de la base de datos. Pero primero es necesario preguntarse ¿cuál es el rendimiento ideal de una base de datos? En este post, te guiaré a través de algunas de las áreas que he encontrado útiles en mi carrera como especialista en bases de datos. Cada uno de los pasos siguientes es un punto de partida para que investigues más a fondo en el mundo de la optimización de bases de datos. Algunos de ellos proporcionarán ganancias más explosivas que otros, pero vale la pena investigarlos todos. Recuerde que cada entorno es diferente y puede requerir un enfoque distinto por su parte y la de sus equipos para satisfacer las necesidades de sus clientes internos y externos. Por último, cuando se trata de cómo mejorar el rendimiento de su base de datos, estamos aquí para ayudarle en todo lo que podamos.
Implantar una solución de supervisión del rendimiento de la base de datos
Utilizar la base de datos NoSQL más rápida del mundo sin supervisión es tan imprudente como utilizar papel como cortafuegos. Increíblemente, el papel se utilizaba antiguamente como cortafuegos entre el motor y los pilotos en los deportes de motor. Igualmente increíble es que algunas empresas no inviertan el tiempo y el dinero necesarios para monitorizar correctamente. Por supuesto, tú no, querido lector, ya que eres uno de los iluminados que ya han implementado una solución de monitorización y están comprobando que todas las BASE están cubiertas (¿ves lo que he hecho?). No se preocupe si no es así, puede informarse sobre nuestra OPV aquí) o encabeza su lista de tareas pendientes.
Lo primero que tiene que decidir es qué debe controlar. ¿Qué quiere conseguir? Si la evaluación concluye que aún no tiene todo lo que necesita, ¿debe comprar o construir para cumplir los criterios de la empresa?
Habiendo pasado más de diez años trabajando para ISVs (Independent Software Vendors) en la industria de las herramientas (especializadas en monitorización y optimización), ya he escrito miles de palabras sobre el debate comprar vs. construir y lo que deberías buscar en una solución de monitorización. En resumen, suele reducirse a la batalla entre gastos de capital y gastos operativos, y a lo que más se valora en su entorno político:
- ¿Cuánto vale su tiempo desde el punto de vista del gasto fiscal y la generación de ingresos?
- ¿Cuál es el retorno de la inversión?
Cuando se trata de cómo medir el rendimiento de las bases de datos, éstas son las preguntas fundamentales que habrá que responder para dar forma a este ámbito de mejora del rendimiento.
Hay, por supuesto, varias empresas que ofrecen soluciones de monitorización listas para que usted las despliegue. No las nombraré aquí ya que esto fecharía el contenido, y es una tarea sencilla introducir algunas palabras clave en su motor de búsqueda favorito. En el resto de esta sección, le presentaré algunas de las capacidades de monitorización nativas y opciones de código abierto para la monitorización.
La primera y más accesible forma de ver las métricas es a través de la consola web de Couchbase. Cualquiera con los permisos pertinentes puede ver la miríada de métricas disponibles o crear su panel personalizado.
A continuación se muestra un ejemplo del panel de control predeterminado. Obsérvese la posibilidad de cambiar los marcos temporales, los buckets y de bucear en nodos individuales.
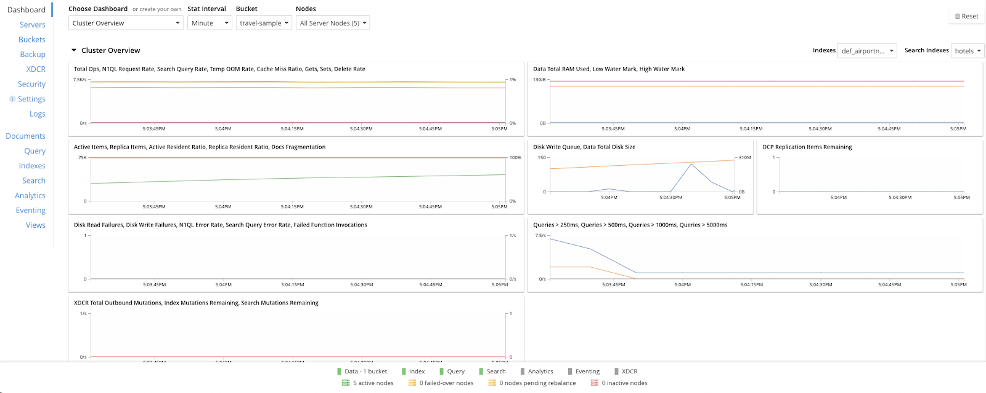
Para crear su cuadro de mandos, asegúrese de que se encuentra en la página Cuadro de mandos y, a continuación, haga clic en la lista desplegable Seleccionar cuadro de mando o cree uno propio. En este ejemplo, empezamos con un lienzo en blanco en lugar de utilizar los gráficos actuales.
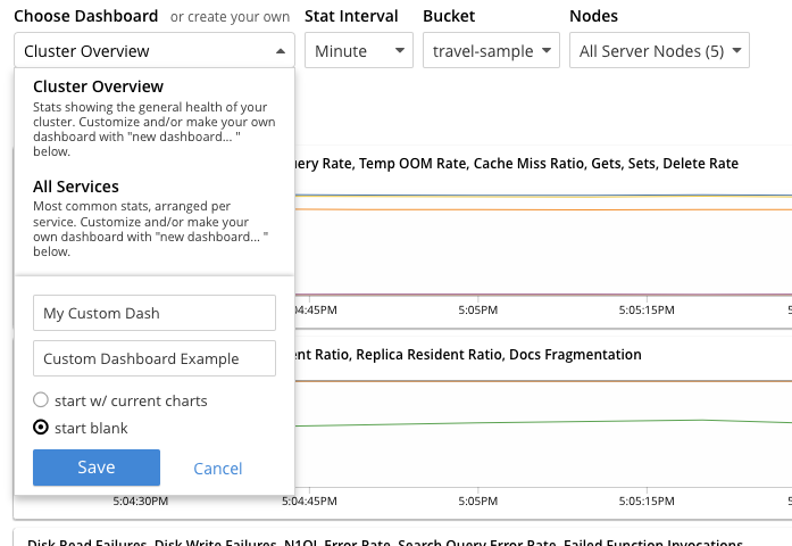
Una vez que haya hecho clic en Guardar, se le pedirá que cree un nuevo Grupo para los gráficos. Cuando haya añadido un grupo, haga clic en Añadir un gráfico.

Puede elegir un tamaño y una métrica de datos para mostrar al añadir un gráfico. En este ejemplo concreto, mostramos nodos separados en lugar de una vista combinada. Tenga en cuenta que si no está seguro de qué métrica se trata, puede utilizar la información sobre herramientas al pasar el ratón por encima de una métrica.
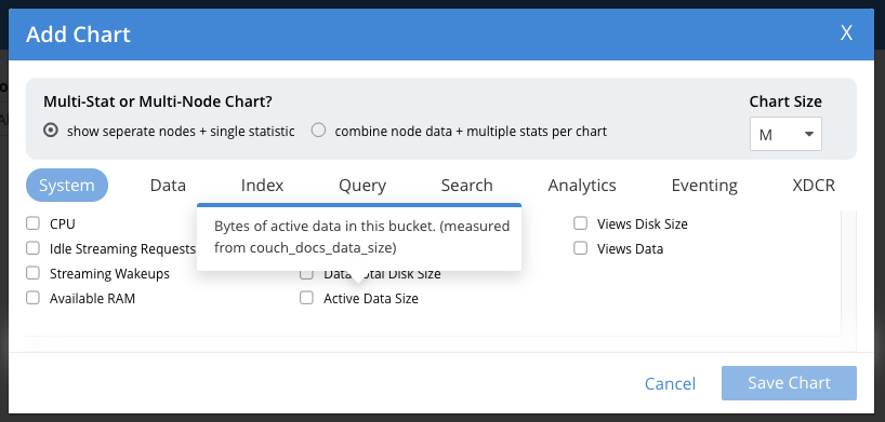
Como hablaremos de índices más adelante en este post, elegí cuatro contadores de índices en este sistema en reposo para mostrar el tipo de datos que el sistema podía mostrar:

Como puede ver, no le costará ningún esfuerzo crear sus cuadros de mando y le permitirá centrarse en las métricas más importantes para su entorno de la forma que más le convenga.
Si prefiere arremangarse e investigar datos, quizá le interese más ver cbstats o Obtención de estadísticas de clúster a través de la API REST. Como hay tantas métricas que puede ver, no entraremos en detalles aquí. En su lugar, para una inmersión mucho más profunda en lo que es posible recoger, por favor refiérase a lo siguiente Guía de monitorización de Couchbase.
Una vez que hayas elegido las métricas que te interesan, puedes visualizarlas en Grafana; esta excelente entrada de blog te guiará a través del proceso. Cómo crear cuadros de mando de observabilidad con Prometheus, Grafana y Couchbase.
Utilice la última versión de Couchbase Enterprise
No debería sorprendernos que la edición comercial de Couchbase ofrezca una funcionalidad muy superior a la de la versión gratuita. Esta sección cubrirá algunas de las funcionalidades principales de las que te beneficiarás con Couchbase Enterprise Edition.
Para obtener una lista completa de las diferencias entre las distintas ediciones de Couchbase, consulte https://www.couchbase.com/products/editions.
Cantidad de nodos
Como era de esperar, el número de nodos permitidos en la Edición Comunidad es mucho menor que el de la versión comercial. Actualmente está limitado a 5 nodos; sin embargo, siempre se debe consultar la documentación más reciente, ya que está sujeto a cambios.
¿Por qué es un problema de rendimiento de la base de datos y cuáles son las soluciones? Hay varias razones, la principal es la escalabilidad, que afecta al rendimiento. No es de extrañar que la incapacidad de escalar más allá de cinco nodos cause problemas con conjuntos de datos más grandes. La imposibilidad de utilizar más hardware será un problema en una arquitectura que priorice la memoria. Como era de esperar, Enterprise mitiga esto de varias maneras, por ejemplo, a través de la compresión.
Compresión
Se trata de un elemento fundamental para mejorar el rendimiento y mantener bajo el coste total de propiedad. Si caben más documentos en la RAM, esto significa menos hardware y menor coste. Esto también simplifica el despliegue y la gestión (no es que sea demasiado difícil), reduciendo aún más los costes.
Podría decirse que la compresión es más importante cuando se trata de escenarios en los que hay una alta densidad de datos o, en términos sencillos, "muchos más datos de los que caben en la memoria". Por lo tanto, es necesario que persistan y se recuperen del disco para servirlos de nuevo al usuario final. Como los discos suelen ser factores de magnitud más lentos que la memoria, si los datos son más pequeños, se leerán del disco más rápidamente.
Indexación
Si quieres migrar una aplicación relacional heredada directamente a NoSQL, es probable que utilices SQL++, nuestro lenguaje SQL para JSON. Es más, querrás portar tus esquemas y tablas y tener los mismos índices en ellos. Con Couchbase 7.0, ciertamente puedes hacer esto, sin embargo, habrá algunas diferencias en cómo se comportarán los índices entre las ediciones Community y Enterprise.
En primer lugar, utilizan dos motores diferentes. En segundo lugar, se puede utilizar la partición en la versión Enterprise. La ventaja de la partición es que el usuario puede dividir el índice en varios nodos, lo que le permite beneficiarse del uso de más núcleos en lugar de limitarse a los núcleos de un solo nodo. En los índices más extensos, esto puede suponer una diferencia significativa en el rendimiento.
Ámbitos y colecciones
Aunque los ámbitos y las colecciones están disponibles en la Community Edition, no lo están en todos los servicios que ofrece Couchbase. Si eres nuevo en Couchbase y no has oído hablar de Scopes y Collections antes, pero estás acostumbrado a bases de datos relacionales, entonces un Scope sería similar a un esquema, y una Collection sería similar a una tabla.
Esto suena como si Couchbase pudiera estar convirtiéndose en una base de datos relacional, pero en realidad, somos la elección de base de datos moderna para aplicaciones empresariales proporcionando una fusión entre los mundos relacionales y distribuidos NoSQL. Estamos haciendo que sea más fácil que nunca migrar de sistemas monolíticos heredados a una nueva arquitectura de memoria distribuida que soportará microservicios.
La incorporación de ámbitos y colecciones nos ha permitido rediseñar varios procesos internos, lo que ha dado lugar a un rendimiento mucho más rápido que en versiones anteriores, a la vez que se han incrementado capacidades como el número de índices admitidos por un clúster.
Cuando se trata de cómo aumentar el rendimiento de la base de datos, esta nueva característica aumenta nuestra capacidad para soportar entornos multi-tenant, reduciendo el coste total de propiedad. Para leer más sobre la implementación de Scopes y Collections en Couchbase 7.0, echa un vistazo a este blog Cómo los ámbitos y las colecciones simplifican los despliegues de aplicaciones multiusuario en Couchbase.
Dimensione su infraestructura en consecuencia
Viniendo de un entorno relacional, a menudo encontraba numerosas limitaciones en el hecho de que todos los datos y todos los diversos componentes ofrecidos por la plataforma estuvieran en un único servidor. Esta no es una conversación sobre plataformas relacionales. Sin embargo, es probable que usted ya esté familiarizado con la necesidad de escalar, sepa lo caro que puede llegar a ser y comprenda lo difícil que puede resultar rediseñar e intentar escalar con esas plataformas.
Aquí es donde Escalado multidimensional (MDS) llega y capta inmediatamente mi atención por las razones anteriores. Mis sistemas ya no estaban limitados. Podía ampliar o reducir sólo aquellos servicios que necesitaran más potencia. Si no has oído hablar de MDS antes, echa un vistazo a la documentación que he enlazado más arriba. El resumen es que te permite instalar múltiples servicios en múltiples máquinas. Puedes distribuirlos en todas las máquinas o distribuirlos en máquinas dedicadas para cada servicio. Recomiendo que se utilicen máquinas dedicadas en producción, ya que esto aísla la carga de trabajo y garantiza que ninguna parte del sistema afecte negativamente a otra. Por supuesto, para reducir costes, los entornos que no son de producción, como Desarrollo, QA, Preproducción, etc., podrían tener recursos compartidos.
¿Por qué es tan importante el aislamiento? Buena pregunta. Todo se remonta a la forma monolítica de hacer las cosas con todo en una sola máquina y luchando por utilizar los recursos compartidos de manera uniforme. Incluso si no has experimentado esto con una base de datos relacional, probablemente lo hayas experimentado con máquinas virtuales donde los recursos han sido sobreasignados y la CPU que pensabas que tenías fue asignada a otro lugar.
¿Aún no está convencido? Si es así, compartiré tres problemas comunes que he visto en cientos de entornos en los últimos años y que tener una carga de trabajo aislada distribuida evitará.
Programación
La base de datos relacional con la que tengo más experiencia utiliza un planificador cooperativo. Cederá peticiones de CPU a otros procesos para garantizar que el sistema operativo pueda hacer lo que tiene que hacer. Eso suena muy bien: mi base de datos no tendrá secuestrado a mi sistema operativo, ¡qué alegría! Bueno, sí y no. La cuestión es que, normalmente, el cooperativo no distingue lo que es del sistema operativo y otras aplicaciones de terceros, principalmente porque el SO cambiará con el tiempo y añadirá nuevos procesos.
El problema surge cuando se instalan otras aplicaciones de distintos proveedores o, en algunos casos, del mismo proveedor de bases de datos. El motor de la base de datos cederá cuando estas otras aplicaciones soliciten tiempo de CPU. He visto numerosos sistemas esperando durante periodos significativos de tiempo por CPU puramente porque otras aplicaciones lo han solicitado. Por supuesto, se culpa a la base de datos a pesar de que sólo obedece sus reglas. La otra cara de la moneda es que si se tratara de una arquitectura distribuida realmente aislada, este problema nunca ocurriría.
Inflamación de la caché
En resumen, muchos proveedores de bases de datos crean un área de memoria denominada caché de planes o caché de procedimientos. La idea es que es demasiado intensivo para la CPU crear continuamente lo que generalmente se conoce como un plan de ejecución o de explicación. Una vez creado uno, se coloca en esta área de memoria. El problema surge cuando esta zona de memoria se comparte en la misma máquina que almacena los datos en memoria para reducir el tiempo de acceso a los datos en disco.
Lo que puede ocurrir (y esto dependerá de la base de datos, ya que algunas tienen más controles que otras) es que la caché del plan/procedimiento consuma una cantidad significativa de la memoria disponible. Esto significa que hay poca memoria disponible para los datos y se requieren más viajes al disco físico, lo que resulta en un aumento de la latencia y una caída significativa del rendimiento.
De nuevo, se puede diseñar un sistema que separe los nodos de consulta y datos con aislamiento. Esto no sólo significa que la memoria está separada, y esto no sucedería, sino que la CPU también está aislada - recuerda, dije que crear un plan era intensivo para la CPU.
Reconstrucción de índices
Este problema comparte algunos puntos en común con el escenario anterior, pero utiliza partes diferentes de los distintos motores de bases de datos. Algunos motores de bases de datos almacenan los datos y las páginas de índice en el mismo espacio de memoria. Probablemente puedas predecir a dónde va esto. No todos los entornos tendrán rutinas para desfragmentar los índices; como regla general, deberías hacerlo, y deberías hacerlo durante periodos que causen la menor cantidad de interrupciones ya que tus índices pueden ser grandes y pueden causar muchos accesos al disco y registros.
Por este motivo, he visto a varias empresas realizar su reconstrucción de índices un domingo, cuando su sistema está más tranquilo. El problema es que la mañana del lunes es una de las más ajetreadas, con mucha gente conectándose al mismo tiempo y queriendo ejecutar los informes de la semana anterior, o incluso los del mes, trimestre o año anteriores.
¿Por qué es esto un problema? Bueno, volvemos al espacio de memoria compartida. Por ejemplo, supongamos que tengo 50% de índices y 50% de datos en la memoria caché. ¿Qué pasará cuando reconstruya todos mis índices? La respuesta simplista es que leerá los datos de cada tabla/documento y reconstruirá cada índice a su vez.
En realidad, es un poco más complejo. El resultado es que los datos que tenías en caché antes del fin de semana ya no están en caché el lunes, cuando se ejecutan todos esos informes urgentes. Esto significa un acceso lento al disco que arrastra todos los índices y datos necesarios para satisfacer esas peticiones. De nuevo, con una arquitectura aislada distribuida, uno podría beneficiarse de servicios separados en diferentes nodos, lo que significaría que los datos necesarios en memoria seguirían estando en memoria.
Estas son sólo algunas de las ventajas de la edición Enterprise. Si desea considerar probando nuestro software, póngase en contacto con equipo de ventas. Si ya eres cliente y quieres asegurarte de que tienes el número correcto de nodos y de que la arquitectura es la adecuada, ponte en contacto con tu comercial y tu ingeniero de ventas, que estarán encantados de ayudarte.
Utilizar declaraciones preparadas
Podemos dividir las consultas en dos categorías: mal escritas y muy optimizadas. (Perdón, no lo siento). Algunos de ustedes pueden estar pensando: "Espera, esta consulta es lo suficientemente buena". Pues sí, puede que esté en tu arnés de pruebas, pero cuando se trata de cómo mejorar una base de datos, ¿tienes más de 1.000 usuarios listos para probar cómo se escala en ese sistema? Probablemente no. ¿Ves ahora por qué la monitorización era el primer punto de la lista?
Cuando se necesita un alto rendimiento y tiempos de respuesta de baja latencia, se requiere un buen modelo de datos y etiqueta de consulta. Ya hemos tocado el tema de por qué Couchbase Enterprise Edition sería un gran ajuste y cubriremos la Optimización de Índices a continuación. En esta sección hablaremos de las consultas preparadas. Puede que sea algo nuevo para ti, pero merece la pena aprenderlo.
Como en todo, cada decisión tiene sus inconvenientes. Ciertamente no estoy sugiriendo que utilices sentencias preparadas para todas tus consultas SQL++. Usted debe hacer su debida diligencia para ver donde tiene sentido.
Llegados a este punto, es posible que se pregunte qué es una declaración preparada. Bueno, ya lo hemos mencionado en la última sección sobre dimensionamiento. Una de las optimizaciones que muchos proveedores de bases de datos añaden a sus productos es guardar los planes de ejecución. Esto reduce el coste de tener que calcularlo cada vez que se ejecuta.
Es posible hacerlo a través del SDK y CLI o del Query Workbench. Los ejemplos que se muestran a continuación están diseñados para funcionar en Query Workbench.
Ejemplo 1 - Una sentencia preparada, antes de Couchbase 7.0:
|
1 2 3 4 5 |
PREPARE MyCode AS SELECT * FROM `travel-sample` WHERE type = "hotel" LIMIT 5; EXECUTE MyCode |
El ejemplo 1 muestra una consulta sencilla que devuelve todos los datos de cinco documentos de hotel. Si sólo has empezado a utilizar Couchbase 7.0 o superior, no habrás visto antes el atributo "type". Se utilizaba para identificar el tipo de documento que se estaba utilizando. Esto fue eliminado con la introducción de ámbitos y colecciones.
Ejemplo 2 - Una sentencia preparada en Couchbase 7+, por favor tenga en cuenta que necesitará configurar el bucket a viaje-muestra y alcance a Inventario en el Query Workbench:
|
1 2 3 4 5 6 7 8 9 |
PREPARE FindVacantHotels AS SELECT name, url FROM hotel WHERE city = $1 AND vacancy = TRUE ORDER BY name LIMIT 10; EXECUTE FindVacantHotels USING["London"] |
El ejemplo 2 muestra una consulta que se acercará un poco más a una consulta del mundo real que usted desearía preparar. En este caso, hemos elegido cuidadosamente los atributos que deseamos devolver en lugar de todos los atributos del documento. También hemos añadido más predicados, incluyendo un parámetro y una cláusula ORDER BY. Esto facilita el soporte de la consulta con una buena estrategia de indexación.
Aunque este post sería demasiado largo para abarcar el modelado de datos, ya que es un tema enorme por derecho propio, sí quiero proporcionar algunos enlaces donde se puede obtener más información.
Para arquitectos, he aquí un breve curso gratuito, CB131que cubre algunos aspectos básicos de Couchbase, incluyendo el modelado de datos. Aquí tienes un curso más profundo que puedes comprar, CD212que profundiza en los enfoques de modelado y consulta de datos.
Optimizar índices
Crear los índices correctos se considera a menudo arte en lugar de ciencia; la verdad es que probablemente sea un poco de ambas cosas. Sin embargo, demos un paso atrás, ya que es posible que no hayas utilizado o ni siquiera hayas oído hablar de un índice antes.
Un índice se define generalmente como una copia materializada de los valores de los datos de forma ordenada, lo que permite encontrar los datos de origen mucho más rápidamente. Existen otros tipos, pero este enunciado cumple su función a modo de introducción. Si eres lo suficientemente mayor como para recordar los libros (cosas pesadas hechas de papel con palabras impresas en ellas), en particular los libros de no ficción, casi siempre había algo llamado índice. Un índice era una sección al final del libro que contenía una lista de palabras (en orden alfabético) con números de página asociados. Esto permitía al usuario buscar una sección concreta sin tener que hojear todo el libro.
Esta es la misma premisa de un índice de base de datos, proporcionar otra copia materializada de los datos con la capacidad de encontrar datos eficientemente sin incurrir en mucha sobrecarga - en este caso, sin leer en más documentos de los necesarios.
La indexación es un tema muy amplio, y no podemos hacerle justicia aquí. Para hacer las cosas más fáciles, Couchbase creó la herramienta Asesor de índices para facilitar la creación del índice perfecto. Está disponible en el Query Workbench o puede utilizar la función CONSEJO mando.
El orden en el que se añaden los atributos al índice y su cardinalidad (el grado de unicidad de los valores) pueden afectar considerablemente al rendimiento de la consulta.
Para ayudar a aquellos que deseen crear sus propios índices, este es el orden en el que se deben añadir predicados y uniones:
- IGUALDAD
- EN
- MENOS DE
- ENTRE
- MAYOR QUE
- Predicados de matriz
- Busque añadir campos adicionales para el índice para cubrir la consulta
En la sección, Usar la última versión de Couchbase Enterprise, tocamos el tema de los índices particionados. Esto es sin duda algo a probar si tienes índices más significativos y múltiples nodos de índice.
Otra técnica de mejora del rendimiento de las bases de datos para aumentar el rendimiento a través de la arquitectura de los índices es introducir réplicas adicionales. Se pueden añadir hasta 2 réplicas; cada réplica tendría que residir en un nodo de índice distinto. Esto proporcionaría tres nodos desde los que leer los datos en lugar de sólo uno.
Esta es sólo una de las ventajas de la arquitectura distribuida que utiliza Couchbase. Las bases de datos relacionales normalmente sólo tienen una copia legible de un índice, lo que puede causar un cuello de botella.
Recursos
Sea cual sea la forma en que prefiera aprender, y sea cual sea el tiempo del que disponga o no, sin duda puede beneficiarse de la idea compartida anteriormente y de los enlaces resumidos a continuación. ¡Feliz optimización!
- Guía de monitorización de Couchbase
- Cómo crear cuadros de mando de observabilidad con Prometheus, Grafana y Couchbase
- Cómo los ámbitos y las colecciones simplifican el despliegue de aplicaciones multiusuario en Couchbase
- Escala multidimensional
- CB131: Curso de certificación Couchbase Associate Architect
- CD212: Curso de modelado, consulta y búsqueda de datos NoSQL en Couchbase
- Asesor de índices de Couchbase
- Comparar diferentes ediciones de Couchbase
