
Deploy a Performance Monitoring Solution
Use the latest Commercial version of Couchbase
Size your infrastructure accordingly
Use Prepared Statements
Optimize Indexes
There are many steps on the road to better database performance. But first it is necessary to ask what is the ideal database performance? In this post, I will walk you through some of the areas I have found helpful in my career as a database specialist. Each of the steps below is a jumping-off point for you to investigate further into the world of database optimization. Some of these will provide more explosive gains than others, but they are all worth investigating. Remember, each environment is different and may require a different approach by you and your teams to meet the needs of your internal and external customers. Lastly, when it comes to how to improve your database performance, we’re here to help you in any way that we can.
Deploy a Database Performance Monitoring Solution
Using the world’s fastest NoSQL database without monitoring is about as unwise as using paper as a fireguard. Unbelievably, paper was once used as a fireguard between the engine and racing drivers in motorsport! Equally unbelievable, some companies don’t invest the time and money required to monitor correctly. Not you, of course, dear reader, as you are one of the enlightened ones who have already implemented a monitoring solution and are checking to make sure all the BASE’s are covered (see what I did there? Don’t worry if not, you can read about our IPO here) or it’s top of your to-do list.
The first thing you need to decide is what you should monitor. What are you trying to achieve? If your assessment concludes you don’t already have all you need, should you buy or build to meet the business criteria?
Having spent over ten years working for ISVs (Independent Software Vendors) in the tooling industry (specializing in monitoring and optimization), I have already written thousands of words on the buy vs. build debate and what you should look for in a monitoring solution. In summary, it usually boils down to the capital versus operational expenditure battle and what is valued most in your political environment:
- What is your time worth from a fiscal spend and revenue-generating perspective?
- What is the ROI of buying in?
When it comes to how to measure database performance these are the fundamental questions that will need answering to shape this area of improving performance.
There are, of course, several companies that provide monitoring solutions ready for you to deploy. They won’t be named here as this will date the content, and it’s a simple task to enter some keywords into your favorite search engine. For the rest of this section, I will introduce you to some of the native monitoring capabilities and open-source options for monitoring.
The first and most accessible way to view metrics is via the Couchbase web console. Anybody with the relevant permissions may view the myriad of metrics available or create their customized dashboard.
An example of the default dashboard can be seen below. Note the ability to change time frames, buckets, and dive into individual nodes.
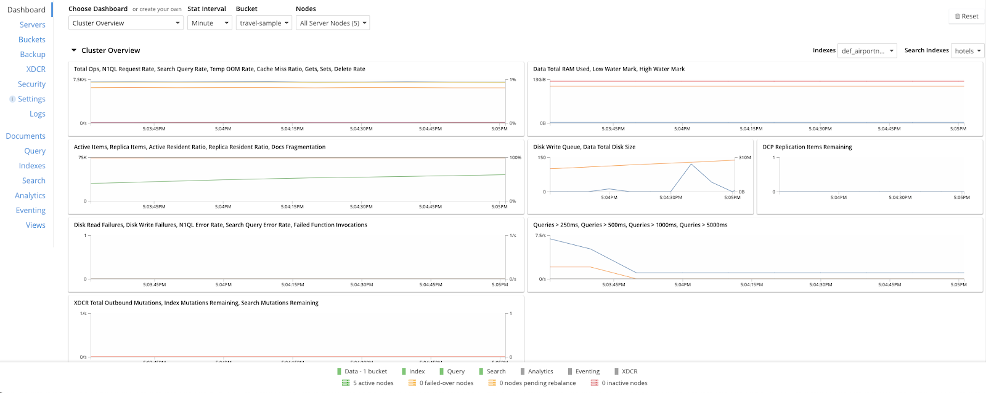
To create your dashboard, ensure you are on the Dashboard tab, then click on the drop-down list labeled Choose Dashboard or create your own. In this example, we start with a blank canvas rather than using the current charts.

Once you have clicked on Save, you will be prompted to create a new Group for charts. When you have added in a group, click on Add a Chart.

You can choose a size and a data metric to show when adding a chart. In this particular example, we show separate nodes rather than a combined view. Please note that tooltips are available when you hover over a metric if you are not sure what the metric is.

As we shall be talking about indexes later in this post, I chose four index counters on this idling system to show the kind of data that the system could show:

As you can see, it is effortless to create your dashboards and allows you to have laser focus on those metrics that matter the most to your environment in a way that suits you best.
If you prefer to roll up your sleeves and investigate data, you may be more interested in looking at cbstats or Getting Cluster Statistics via the REST API. As there are so many metrics that you can view, we won’t go into detail here. Instead, for a much deeper dive into what is possible to collect, please refer to the following Couchbase Monitoring Guide.
Once you have chosen the metrics you are interested in, you can visualize them in Grafana; this excellent blog post will walk you through the process. How to Build Observability Dashboards with Prometheus, Grafana & Couchbase.
Use the latest Couchbase Enterprise version
It should come as no surprise that the commercial edition of Couchbase offers far superior functionality than the free version. This section will cover some of the core pieces of functionality that you will benefit from out of the box with Couchbase Enterprise Edition.
For a complete list of the differences between the various editions of Couchbase, please refer to https://www.couchbase.com/products/editions.
Quantity of nodes
As one might expect, the number of nodes allowed in the Community Edition is much less than that of the commercial version. This is currently limited to 5 nodes; however, one should always check the latest documentation as this is subject to change.
Why is this a database performance issue and what are the solutions? There are a few reasons, the main one is scalability, which then affects performance. It should be no surprise that the inability to scale out further than five nodes will cause an issue with larger datasets. The failure to make use of more hardware will be an issue in a memory-first architecture. As one would expect, Enterprise mitigates this in several ways, e.g., via compression.
Compression
This is a core element in improving performance and keeping the total cost of ownership low. If one could fit more documents into RAM, this means less hardware and lower cost. This also simplifies deployment and management (not that it’s too difficult), reducing costs even further.
Compression is arguably more important when it comes to scenarios where there is High Data Density, or in layman’s terms, “way more data than can fit in memory.” Hence, it needs to be persisted and recalled from the disk to be served back to the end-user. As disks are generally factors of magnitude slower than memory, if the data is smaller, it will be read from the disk faster.
Indexing
If you want to migrate a legacy relational application straight over to NoSQL, you will likely use SQL++, our SQL for JSON language. What’s more, you will want to port your schemas and tables over and have the same indexes on them. With Couchbase 7.0, you can certainly do this however, there will be a few differences in how indexes will behave between the Community and Enterprise editions.
Firstly, they use two different engines. Secondly, one can use partitioning in the Enterprise version. The benefit of partitioning is that the user can split the index across multiple nodes allowing it to benefit from using more cores rather than being restricted to the cores on one node. On more extensive indexes, this can make a significant difference in performance.
Scopes and collections
While scopes and collections are available in the Community Edition, it is not available in all of the services that Couchbase offers. If you are new to Couchbase and have not heard of Scopes and Collections before but are used to relational databases, then a Scope would be akin to a schema, and a Collection would be akin to a table.
This sounds like Couchbase might be becoming a relational database, but in truth, we are the modern database choice for enterprise applications providing a fusion between the relational and distributed NoSQL worlds. We are making it easier than ever to migrate from legacy monolithic systems to new distributed memory-first architecture that will support microservices.
Adding Scopes and Collections has enabled us to re-architect several internal processes resulting in much faster performance than in previous versions, while also increasing capabilities such as the number of indexes supported by a cluster.
When it comes to how to increase database performance, this new feature increases our ability to support multi-tenant environments, reducing your total cost of ownership. To read more about implementing Scopes and Collections in Couchbase 7.0, check out this blog How Scopes & Collections Simplify Multi-Tenant App Deployments on Couchbase.
Size your infrastructure accordingly
Coming from a relational background, I often found numerous constraints with all the data and all the various components offered by the platform being on a single server. This isn’t a conversation about relational platforms. However, you are probably already well versed in having to scale up, know how expensive it can become, and understand how difficult it can be to re-architect and try to scale out with those platforms.
This is where Multi-Dimensional Scaling (MDS) comes in and immediately captured my attention due to the reasons above. No longer were my systems constrained. I could scale up or scale out just those services that needed extra power. If you have not heard of MDS before, do have a quick read of the documentation I linked to above. The TLDR is that it allows you to install multiple services on multiple machines. You can stripe them across all machines or have them striped across dedicated machines for each service. I recommend that dedicated machines be used in production as this isolates the workload and ensures that no part of the system will negatively affect another. Of course, to reduce costs, non-production environments such as Development, QA, Pre-production, etc., could have shared resources.
Why is isolation so important? Good question. It all comes back to the monolithic way of doing things with everything on one machine and struggling to utilize the shared resources evenly. Even if you have not experienced this with a relational database, you have probably experienced it with virtual machines where resources have been overallocated and the CPU you thought you had was assigned elsewhere.
Still not convinced? If so, I’ll share three common issues that I have seen in hundreds of environments over the last few years that having a distributed isolated workload will avoid.
Scheduling
The relational database with which I have the most experience uses a cooperative scheduler. It will yield CPU requests to other processes to ensure that the operating system can do what it needs to do. That sounds like a great thing – my database won’t hold my OS hostage – happy days! Well, yes, and no. The thing is, co-operative typically does not distinguish what is from the operating system and other third-party applications, primarily because the OS will change over time and add in new processes.
The problem arises where other applications are installed from either different vendors or, in some cases, from the same database vendor. The database engine will yield when these other applications call for CPU time. I have seen numerous systems waiting for significant periods of time for CPU purely because other applications have requested it. Of course, the database is blamed even though it just obeys its rules. The flip side is if it were a truly isolated distributed architecture, this issue would never happen.
Cache bloat
In summary, many database vendors create an area of memory called a plan cache or a procedure cache. The idea is that it is too CPU intensive to continually create what is generally referred to as an execution or explain plan. Once one is made, it is put into this area of memory. The problem arises when this memory area is shared on the same machine that stores data in memory to reduce the access time to data on disk.
What can happen (and this will be database-specific as some have more controls than others) is that the plan/procedure cache will significantly eat into the amount of memory available. This means that little memory is available for data and more trips to the physical disk are required, resulting in increased latency and dropping throughput significantly.
Again, a system can be designed to separate the query and data nodes with isolation. Not only does this mean that the memory is separate, and this would not happen, but the CPU is also isolated – remember, I said that creating a plan was CPU intensive.
Index rebuilds
This issue shares some commonalities with the scenario above but uses different parts of the various database engines. Some database engines store the data and index pages in the same memory space. You can probably predict where this is going. Not every environment will have routines to defragment indexes; as a general rule, you should, and you should do it during periods that cause the least amount of disruption as your indexes may be large and may cause a lot of disk access and logging.
Because of this, I have seen several companies perform their index rebuild on a Sunday when their system is most quiet. The problem is that Monday morning is one of the busiest, with lots of people logging on at the same time and wanting to run reports for the previous week, maybe even the previous month, quarter, or yearly reports.
Why is this a problem? Well, it comes back to that shared memory space again. For argument’s sake, let’s say I currently have 50% index and 50% data in my memory cache. What happens when I rebuild all of my indexes? The simplistic answer is that it will read in the data from each table/document and rebuild each index in turn.
In truth, it’s a little more complex. The outcome is that the data you had in cache before the weekend is no longer in cache on Monday when all those urgent reports are run. This means slow disk access pulling in all the indexes and data required to satisfy those requests. Again, with a distributed isolated architecture, one could benefit from separate services on different nodes meaning the necessary data in memory was still in memory.
These are just some of the benefits that come with the Enterprise Edition. If you would like to consider trialing our software, reach out to our sales team. If you are already a customer and want to ensure that you have the correct number of nodes and have architected things correctly, reach out to your Sales rep and Sales Engineer, who will be happy to help.
Use Prepared Statements
We can break down queries into two categories: badly written and highly optimized. (Sorry, not sorry). Some of you may be thinking, “Hang on, this query is good enough.” Why yes, it might be on your test harness, but when it comes to how to improve a database do you have 1,000+ users ready to test how it scales on that system? Probably not. Do you see why monitoring was the first item on the list now?
Where high throughput and low latency response times are needed, a good data model and query etiquette are required. We have already touched on why Couchbase Enterprise Edition would be a great fit and will be covering Optimizing Indexes next. In this section, we will talk about prepared queries. It might be something new to you, but it is well worth learning.
As with everything, there are potential drawbacks to every decision you make. I am certainly not suggesting that you utilize prepared statements for all your SQL++ queries. You should do your due diligence to see where it makes sense.
At this point, you may be asking yourself, what is a prepared statement? Well, we touched on this slightly in the last section on Sizing. One of the optimizations that many database vendors add to their products is saving execution plans. This reduces the cost of having to calculate it every time it runs.
It’s possible to do this via the SDK and CLI or the Query Workbench. The examples shown below are designed to work in Query Workbench.
Example 1 – A prepared statement, before Couchbase 7.0:
PREPARE MyCode AS
SELECT * FROM `travel-sample` WHERE type = "hotel"
LIMIT 5;
EXECUTE MyCodeExample 1 shows a simple query returning all data from five hotel documents. If you only started with using Couchbase 7.0 or above, you will not have seen the “type” attribute before. This was used to identify the kind of document being used. This was phased out with the introduction of scopes and collections.
Example 2 – A prepared statement in Couchbase 7+, please note you will need to set the bucket to travel-sample and scope to Inventory in Query Workbench:
PREPARE FindVacantHotels AS
SELECT name, url
FROM hotel
WHERE city = $1
AND vacancy = TRUE
ORDER BY name
LIMIT 10;
EXECUTE FindVacantHotels USING["London"]Example 2 shows a query that will be a bit closer to a real-world query that you would want to prepare. In this case, we have carefully chosen the attributes we wish to return rather than all attributes in the document. We have also added more predicates, including a parameter and ORDER BY clause. This makes it easier to support the query with a good indexing strategy.
Although this post would be too long to cover data modeling, it is a massive subject in its own right, but I do want to provide some links where you can gain further information.
For architects, here’s a free short course, CB131, that covers some Couchbase basics, including data modeling. Here’s a deeper dive course you can purchase, CD212, that goes further into data modeling and querying approaches.
Optimize Indexes
Creating the correct indexes is often considered art instead of science; the truth is it’s probably a little of both. However, let’s take one step back as you may not have used or even heard of an index before.
An index is generally defined as a materialized copy of data values in an ordered fashion, allowing you to find the source data a lot faster. There are other kinds, but this statement serves its purpose for an introduction. If you are old enough to remember books (heavy things made from paper with words printed on them), particularly non-fiction books, there was almost always something called an index. An index was a section at the end of the book that contained a list of words (in alphabetical order) with associated page numbers. This allowed the user to look up a particular section without scanning through the entire book.
This is the same premise of a database index, to provide another materialized copy of the data with the ability to efficiently find data without incurring a lot of overhead – in this case, without reading in more documents than you need to.
Indexing is a vast topic, and we can’t do it justice here. To make things easier, Couchbase created the Index Advisor feature to take the strain out of creating the perfect index. This is available either in the Query Workbench or you can use the ADVISE command.
The order in which you add the attributes into your index and their cardinality (how unique the values are) can dramatically affect how your query will perform.
To help those of you who wish to create their own indexes, this is the order in which you should add predicates and joins:
- EQUALITY
- IN
- LESS THAN
- BETWEEN
- GREATER THAN
- Array predicates
- Look to add additional fields for the index to cover the query
In the section, Use the latest Couchbase Enterprise version, we touched on the topic of partitioned indexes. This is undoubtedly something to test if you have more significant indexes and multiple index nodes.
Another database performance improvement technique for increasing performance through the architecture of indexes is to introduce extra replicas. You can add in up to 2 replicas; each replica would need to reside on a separate index node. This would provide three nodes to read the data from instead of just one.
This is just one of the benefits of the distributed architecture that Couchbase uses. Relational databases will typically only have one readable copy of an index which can cause a bottleneck.
Resources
Whatever way you prefer to learn, and however much time you may or may not have, you can certainly benefit from looking at the idea shared above and the summarized links below. Happy optimizing!
- Couchbase Monitoring Guide
- How to Build Observability Dashboards with Prometheus, Grafana & Couchbase
- How Scopes & Collections Simplify Multi-Tenant App Deployments on Couchbase
- Multi-Dimensional Scaling
- CB131: Couchbase Associate Architect Certification Course
- CD212: Couchbase NoSQL Data Modeling, Querying, Search Course
- Couchbase Index Advisor
- Compare Different Editions of Couchbase
Deixe um comentário
Você precisa fazer o login para publicar um comentário.