
A data mesh architecture can help an organization enable AI at scale by democratizing data access for domain-specific analysis and assigning domain experts responsibility for each subject area. This improves data quality for better, more accurate AI.
In a data mesh architecture, business domains own and curate their data as a data product, ensuring its quality for analysis and AI exercises like model training. This enables analysts and data scientists to access high-quality, thoroughly cleansed, well-documented data for AI and machine learning algorithms, ensuring accuracy and reducing phenomena such as large language mode (LLM) hallucinations.
Let’s examine this concept more deeply by exploring the data mesh architecture.
- What is a data mesh?
- Why data mesh?
- Data mesh principles
- Data mesh use cases
- Data mesh benefits
- The difference between dash mesh, data lake, and data fabric
- Implementing a data mesh architecture
- Future of data mesh architecture
What is a data mesh?
Enterprises, large and small, have various systems that run the day-to-day business. For example, in most organizations, you might find a CRM for sales operations, an ERP for finance management, a helpdesk system for customer support, a project management application for product development, etc. It’s crucial to get accurate insight into performance across all operations to determine that your enterprise’s data is accurate, to improve processes, and to streamline workflows.
The problem is that only specific business areas know their data in-depth, which causes issues with analysis and quality control. This can undermine traditional data warehouse efforts that combine data from multiple domains into a centralized data repository because the cleanliness and integrity of the data cannot be guaranteed. And as is becoming increasingly evident, the less trustworthy the data, the less effective and less accurate the AI.
A data mesh architecture overcomes these challenges by distributing domain-specific data to individual analytic repositories and decentralizing ownership of each domain. This ensures that each domain’s data is thoroughly vetted and fit for immediate use by its respective experts. It also unifies disparate sources via centrally managed data-sharing guidelines and governance standards.
With a data mesh architecture, business functions maintain control over the data used for analysis and govern how their data is accessed. While a data mesh can add complexity to an enterprise’s data ecosystem, it also brings efficiency by improving data access and quality, which fuels better analysis and AI.
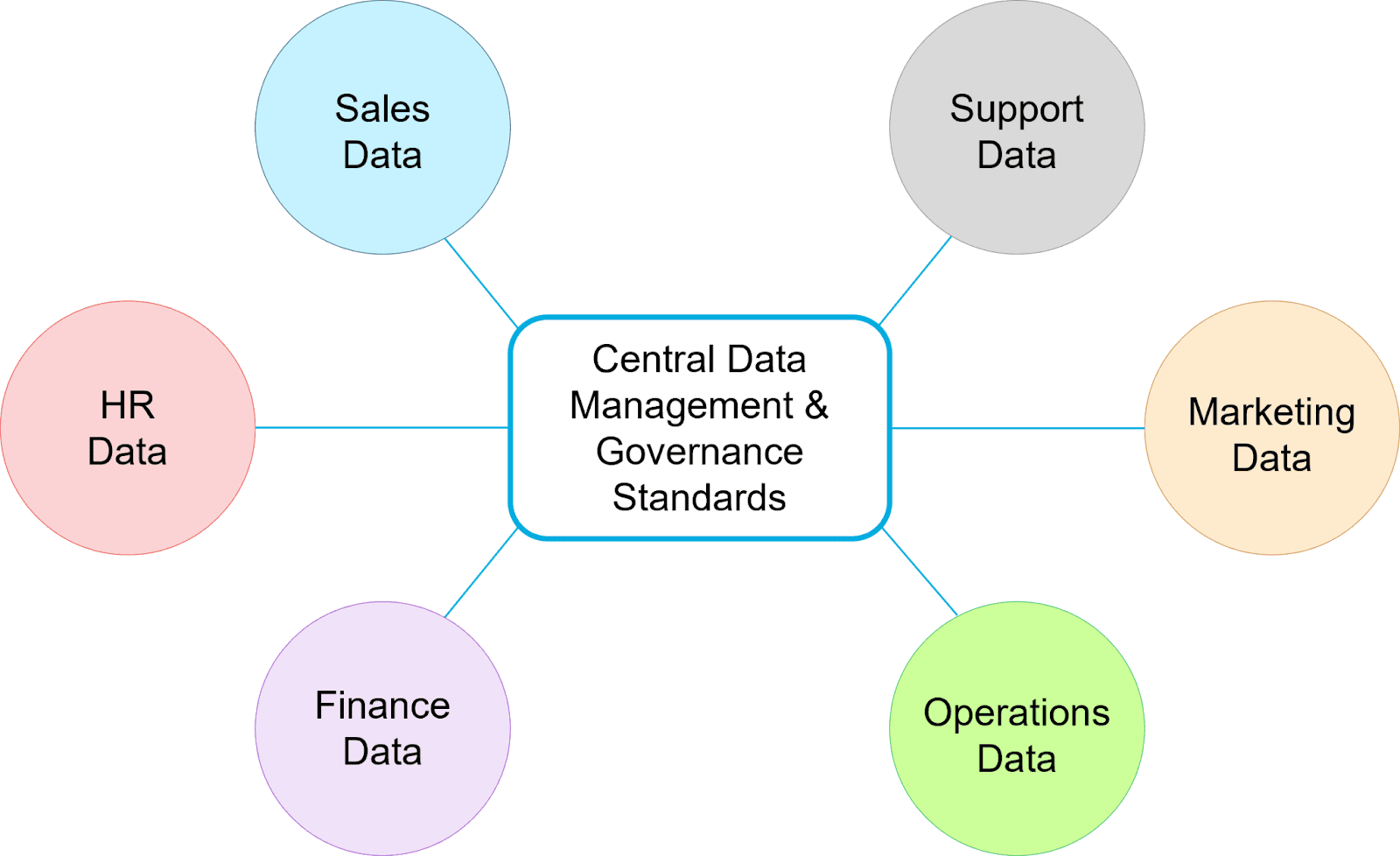
A data mesh architecture distributes domain-specific data under the ownership of each business area.
Why data mesh?
The data mesh architecture was formed out of a need to go beyond traditional centralized data warehouse or data lake implementations, which tend to suffer from some fundamental challenges:
- Establishing a single source of truth can be nearly impossible with traditional approaches because most enterprises’ data footprint is fragmented across many disparate systems in various formats.
- In the current age of AI, demand for easier access to domain data is increasing, as is the volume of data in most enterprises. This creates challenges in handling storage and access.
- Data scientists and analysts need access to data in the formats they require. The data must be trustworthy and not require deep technical knowledge or IT intervention.
Trying to solve these issues by loading all of the data into a centralized analytics system creates its own issues: How do you ensure the quality and timeliness of the data? How do you handle rapidly changing data? How do you handle new data sources and formats?
The data mesh architecture strives to overcome these challenges by distributing ownership of data and analytics systems to domain experts. This spreads the analytic data footprint to smaller, more manageable domain-specific systems that are easier to manage individually. Because each domain expert knows their data best and has direct access to it with the data mesh, data quality and integrity are improved, allowing it to be used more reliably and easily across the organization.
Data mesh principles
The data mesh architecture follows these general principles:
1. Data must be owned by their domains.
Business domains curate and manage their data for analysis and AI rather than delegating ownership to centralized teams.
2. Data must be self-service for authorized users.
To democratize data access, organizations need to simplify access through abstraction and make it as easy as possible without sacrificing stringent security.
3. Data governance must be distributed.
Data management, storage, and security policies are centrally managed, but each domain owns its data products, ensuring flexibility and repeatable structure.
4. Data must be treated as a product (DaaP).
Adhering to the above principles ensures vetted, high-quality, and fully cleansed data products that authorized consumers can easily access and use. In a data mesh architecture, domains own their data products, sourced from analytical and operational systems, and by following standardized management guidelines, they make that data more accurate and accessible across the organization.
Data mesh use cases
A data mesh architecture can support many different use cases across a wide variety of industries and verticals. Some examples are:
Customer lifecycle
Through access to data from systems that span customer engagement, organizations get a 360-degree view of customer journeys, individually and in the aggregate, in real time. This allows the business to create AI that engages customers more quickly with relevant offers and suggestions and examines reasons for successes or failures in overall engagement.
AI and machine learning
Data scientists and advanced analysts can easily access several sources to feed AI and machine learning models, confident that the data is clean, current, and accurate.
IoT environment monitoring
The distributed architecture in a data mesh allows IoT device deployments to be managed and monitored more effectively by the individual business units responsible for IoT applications.
Distributed data security policy
Data security is paramount in a distributed model like the data mesh. By dividing responsibility for data product security policies between individual domains, access to the data is more appropriately restricted based on domain expertise. While more detailed overall, it’s also more stringent than a centralized, one-size-fits-all security policy in its granularity.
Data mesh benefits
There are many benefits of a data mesh architecture, among them some of the most important are:
Data agility
The data mesh architecture reduces dependencies on IT resources to provide access to data from various systems, enabling business teams to concentrate on quality and deliver data products more quickly.
Higher-quality data for AI
Because individual domain experts manage data, their deeper understanding of its context and meaning results in better curated, more trustworthy data, which is critical for reducing inaccurate results and LLM hallucinations.
Faster data availability
A main bottleneck of the centralized data lake approach is the time it takes to add and update sources, let alone manage them and make them easily available. With a data mesh architecture, the delivery of data products happens in parallel rather than in sequence and, thus, happens faster.
Standard central data governance policies
Because of its core principle of following a centralized set of strict governance guidelines, the data mesh architecture sets a standard for data custodianship across the organization while simultaneously providing each domain autonomy.
These are just some of the reasons many organizations adopt a data mesh architecture.
The difference between dash mesh, data lake, and data fabric
When evaluating your organization’s data and AI needs, you’ll inevitably hear about alternative approaches and architectures, such as a data lake or a data fabric. Here are the differences in a nutshell:
Data lake
A data lake is a term that refers to a centralized repository for data from various sources and systems, where all data is collected and stored for aggregated analysis that spans the sources across various domains. A data lake sometimes precedes and feeds a data warehouse, a more refined centralized data repository.
A fundamental difference between a data lake and a data mesh is that the former is centralized, which makes it massive and complex to manage – typically requiring dedicated teams – and difficult to keep current.
Data fabric
A data fabric is similar in concept to a data mesh, except that it employs a technical framework instead of an organizational framework. A data fabric utilizes a centralized data repository but isolates access to each domain and subject area through strict access restriction protocols. This alleviates the need for domains to establish their own domain-specific repositories and removes their direct involvement with the day-to-day data management.
The main difference between a data mesh and a data fabric is that the former is not a distributed model but a technical framework. In contrast, the latter focuses on organizational domains as data owners.
Implementing a data mesh architecture
Because of its decentralized model, a real-time operational data processing and analytics platform is the optimal implementation for data mesh architecture.
This blog explains how Couchbase Capella™ provides a cloud database ideal for data mesh implementations. In a nutshell, Couchbase provides:
A multi-purpose, cloud NoSQL database
Couchbase Capella is a multipurpose, developer-friendly database with built-in caching, JSON document storage, SQL support, search, eventing, and mobile sync. With these combined capabilities, an organization can replace other operational database technologies with one solution, simplifying the data mesh by reducing operational inputs.
Instant operational insights
Capella also provides a built-in columnar analytics service for real-time analysis of any operational data. The results can provide on-the-wire insight without looping through the data mesh. This speeds up the overall mesh, as Capella can be used for instant analysis of specific operational data and then feed those results to the mesh for deeper analysis and AI.
Faster insight-to-action
Capella provides eventing and user-defined function features, allowing the ability to script routines that capture analytic insights from the mesh and back into the operational layers. This effectively enables action on insights – if machine learning algorithms on a data lake mesh develop a new customer classification based on historical data, you can pull that classification back into the sales app for targeted marketing.
Accelerated development
Capella allows an organization to consolidate their operational data sprawl into a database that is easy for developers to work with. SQL++ (SQL for JSON) support, rich SDKs, backend-managed services, and a fully hosted DBaaS reduce development friction – there are no server installation or maintenance headaches and no new languages for developers to learn.
Future of data mesh architecture
As propelled by digitization across industries and accelerated by AI investments and development, data products will become increasingly important for most enterprises, and adhering to its principles of domain ownership and curation can lay the foundation for future innovations fueled by data.
Try Couchbase Capella for yourself and see how easily it can fit into your data mesh architecture initiative.
You can also view our hub and these additional resources to learn more about general concepts related to data architecture:
What Is a Data Platform?
Example Architectures for Data-Intensive Applications
4 Patterns for Microservices Architecture in Couchbase

