Couchbase Capella é uma oferta de DBaaS (Database-as-a-Service) de documento JSON totalmente gerenciado que elimina as tarefas de gerenciamento de banco de dados e reduz os custos gerais. A Capella oferece desempenho robusto, flexibilidade e escalabilidade em um banco de dados distribuído e nativo da nuvem moderna que combina os pontos fortes dos recursos de bancos de dados relacionais, como transações SQL e ACID, com a flexibilidade e a escala JSON que definem o NoSQL.
Pydantic é uma biblioteca que permite que os desenvolvedores definam e validem objetos JSON personalizados usando anotações de tipo Python. O Pydantic acelera o tempo de codificação, aplicando dicas de tipo em tempo de execução e gerando erros de validação fáceis de usar. Os documentos JSON gerados com o pydantic podem ser usados na plataforma Capella sem a preocupação com documentos mal formados que podem ocorrer quando os documentos JSON são criados por meio da concatenação padrão de strings.
Configuração do pydantic
Para executar o projeto de início rápido, você precisa dos seguintes pré-requisitos:
-
- URL do repositório Git: https://github.com/brickj/capella_pydantic
- Python 3 instalado
- O tubulação ferramenta de gerenciamento de pacotes
- Instalado o Couchbase Capella™ SDK:
- A documentação completa está localizada aqui
- Exemplo de comando Python: pip install couchbase
- Instalada a biblioteca Python pydantic:
- A documentação completa está localizada aqui
- Exemplo de comando Python: pip install pydantic
- Conta do Couchbase Capella:
- Inscreva-se em um teste gratuito de 30 dias
- Nome do cluster e do bucket do Couchbase Capella pydantic
Neste blog, examinarei rapidamente um exemplo de uso do pydantic para criar documentos JSON válidos e armazená-los no Couchbase Capella.
O Couchbase Python SDK permite que os desenvolvedores executem operações CRUD em um bucket especificado em um cluster do Couchbase. Por exemplo, o trecho de código a seguir executa um upsert (inserir se a chave do documento não estiver no bucket ou atualizar se o documento já existir):
|
1 2 |
# Armazenar um documento cb_coll.upsert('u:king_arthur', {"nome: "Arthur, 'email': 'kingarthur@couchbase.com', "interesses: ["Santo Graal, Andorinhas africanas]}) |
Os desenvolvedores Python geralmente criam documentos JSON usando strings ou inteiros para preencher um objeto de dicionário que armazena pares de valores-chave. Esse objeto de dicionário é então enviado para o compartimento especificado no banco de dados do Capella para inserção. O código de amostra para criar e preencher o objeto de dicionário é semelhante ao trecho abaixo:
|
1 2 |
# Objeto de dicionário com chaves e valores ditado_amostra = {1: "documento 1, 2: "documento 2} |
Com o pydantic, os desenvolvedores têm a flexibilidade de especificar um esquema para objetos JSON que pode ser aplicado à medida que os documentos são criados. Por exemplo, as etapas a seguir mostram a criação de um documento JSON para publicações de usuários. O modelo do documento tem a seguinte aparência:
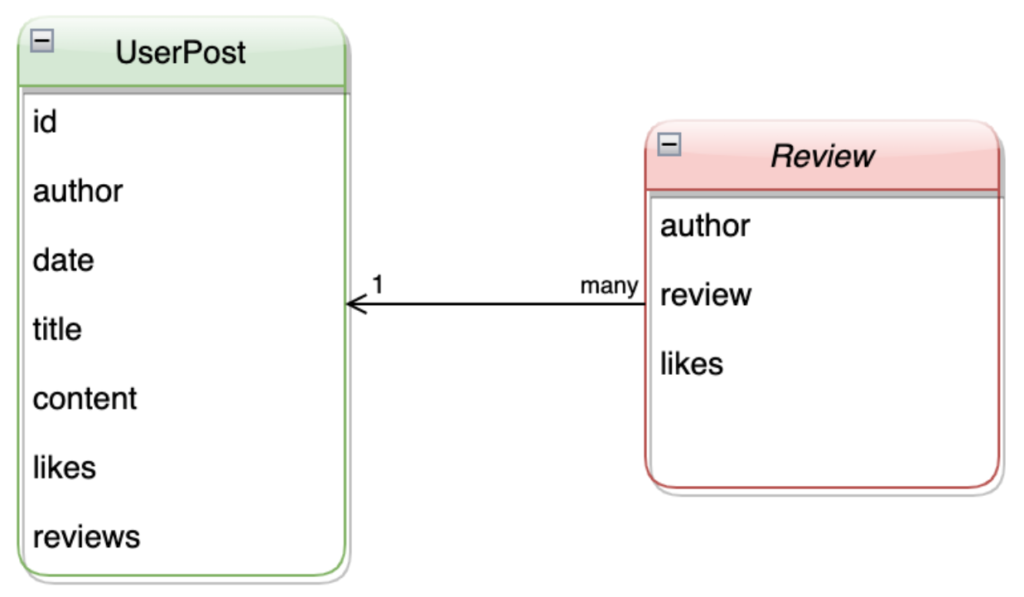
Cada UserPost tem os campos usados na postagem, mas cada postagem pode ter várias revisões que precisam ser aninhadas dentro da postagem. Para habilitar essa funcionalidade, os desenvolvedores podem criar duas classes separadas para o objeto UserPost e o Revisão. Por exemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
classe Revisão(BaseModel): autor: str revisão: str gostos: int classe UserPost(BaseModel): autor: str data: str título: Opcional[str] = Nenhum conteúdo: str id: int gostos: Lista[str] revisões: Lista[Revisão] |
Criação de documentos JSON em Python
Depois que os objetos são criados, é fácil preencher os documentos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
revisão = [ Revisão(autor="johndoe", revisão="Isso é um comentário!", gostos=3), Revisão(autor="rickJ", revisão="Esse é um comentário do Rick J!", gostos=1), Revisão(autor="janedoe", revisão="Este é um comentário da Jane Doe!", gostos=2) ] user_post1 = UserPost(autor="johndoe", data="1/1/1970", título="Postagem legal", conteúdo="Conteúdo legal", id=10101, gostos=["johndoe", "janedoe"], revisões=revisão) |
Agora você pode usar o UserPost como um dicionário e inseri-lo no Couchbase Capella usando um código semelhante ao código upsert mostrado anteriormente, mas usando o objeto dict() método:
|
1 2 |
# Upsert JSON dict com a chave 'u:pydantic_document' cb_coll.upsert('u:pydantic_document', user_post1.ditado()) |
O projeto completo ilustrado neste blog inclui o seguinte:
-
- Leiame com instruções
- Código que cria os objetos UserPost e Review
- Código que gera e imprime um documento na saída
- Código que se conecta ao Couchbase Capella usando o Couchbase Python SDK
- Código que insere o documento JSON gerado
O projeto público pode ser clonado para o Git em: https://github.com/brickj/capella_pydantic
Próximas etapas
Para saber mais sobre Couchbase Capellanossa oferta de banco de dados como serviço:
-
- Inscreva-se em um teste gratuito de 30 dias se você ainda não o fez
- Conecte seu cluster de teste ao Playground ou conecte um projeto para testá-lo por si mesmo
- Se você já estiver usando o Couchbase Capella, poderá interagir com seu cluster usando o shell interativo do Couchbase ou por meio do plano de controle do Capella para:
- Confira o visualizador de documentos
- Conectar-se a um projeto
- Dê uma olhada no Caminho de aprendizado Capella
- Confira nossos tutoriais
- O Portal do desenvolvedor do Couchbase tem toneladas de tutoriais/guias de início rápido e caminhos de aprendizagem para ajudar você a começar
- Consulte a documentação para saber mais sobre os SDKs do Couchbase
- Ler Validação de documentos JSON em Python usando Pydantic
Neste ponto, você deve ser capaz de usar rapidamente a biblioteca pydantic para criar documentos JSON válidos para uso com Couchbase Capella.
Se tiver alguma dúvida ou comentário, entre em contato conosco pelo Fóruns do Couchbase!