As consultas analíticas ad-hoc típicas precisam processar muito mais dados do que cabem na memória. Consequentemente, essas consultas tendem a ser limitadas por E/S. Quando o serviço Analytics foi introduzido no Couchbase 6.0, ele permitiu que os usuários especificassem vários "Analytics Disk Paths" durante a inicialização do nó. Neste artigo, realizamos alguns experimentos em diferentes instâncias na nuvem para mostrar como configurar corretamente vários "Analytics Disk Paths" e como esse recurso pode ser utilizado para acelerar as consultas do Analytics.
Figura 1: Especificação de caminhos de disco do Analytics durante a inicialização do nó
Durante a inicialização do nó, qualquer caminho exclusivo do sistema de arquivos pode ser usado como um "Caminho de disco analítico", independentemente do dispositivo de armazenamento físico real no qual esse caminho reside. Vários caminhos que residem no mesmo dispositivo podem ser usados. Os dados no serviço Analytics são particionados em todos os "Analytics Disk Paths" especificados em todos os nós que têm o serviço Analytics. Por exemplo, se um cluster tiver dois nós com o serviço Analytics e um dos nós tiver 4 "Analytics Disk Paths" especificados e o outro nó tiver 8 "Analytics Disk Paths", cada conjunto de dados criado no Analytics terá um total de 12 partições (partições de dados).
Durante a execução da consulta, o mecanismo de consulta MPP do Analytics tenta ler e processar simultaneamente os dados de todas as partições de dados. Por esse motivo, as operações de entrada/saída por segundo (IOPS) do disco físico real em que cada partição de dados reside desempenham um papel importante na determinação do tempo de execução da consulta.
Os dispositivos de armazenamento modernos, como os SSDs, têm IOPS muito mais alto e podem lidar melhor com leituras simultâneas do que os HDDs. Portanto, ter uma única partição de dados em dispositivos com alto IOPS não utilizará totalmente seus recursos. Para simplificar a configuração do caso típico de um nó com um único dispositivo de armazenamento moderno, o serviço Analytics cria automaticamente várias partições de dados no mesmo dispositivo de armazenamento se, e somente se, um único "Analytics Disk Path" for especificado durante a inicialização do nó. O número de partições de dados criadas automaticamente é baseado nesta fórmula:
|
1 2 |
Maximum partitions to create = Min((Analytics Memory in MB / 1024), 16) Actual created partitions = Min(node virtual cores, Maximum partitions to create) |
Por exemplo, se um nó tiver 8 núcleos virtuais e o serviço Analytics tiver sido configurado com memória >= 8 GB, serão criadas 8 partições de dados nesse nó. Da mesma forma, se um nó tiver 32 núcleos virtuais e tiver sido configurado com memória >= 16 GB, apenas 16 partições serão criadas, pois as partições máximas a serem criadas automaticamente têm um limite superior de 16 partições.
Para mostrar o impacto do desempenho no número de partições de dados por disco, realizamos alguns experimentos em diferentes tipos de instâncias no Amazon Web Services EC2 usando Servidor Couchbase 6.5 Beta 2. Os dados usados nos experimentos são uma versão JSONificada do famoso TPC-DS em que cada linha foi convertida em um documento JSON com um campo adicional que identifica o nome da tabela à qual o documento pertence. Os dados de amostra do TPC-DS foram gerados e carregados em um bucket chamado tpcds. Em ambos os experimentos, o serviço do Analytics recebeu 32 GB de memória.
Experimento 1: instância única com 8 núcleos virtuais e 1 SSD NVMe
Neste experimento, criamos 3 conjuntos de dados no serviço Analytics, como segue:
|
1 2 3 |
CREATE DATASET store_sales ON tpcds WHERE table_name='store_sales'; CREATE DATASET date_dim ON tpcds WHERE table_name='date_dim'; CREATE DATASET item ON tpcds WHERE table_name='item'; |
Usamos a seguinte consulta de qualificação do TPC-DS depois de convertê-la em uma consulta do N1QL for Analytics para medir o tempo de resposta em duas configurações diferentes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT dt.d_year, item.i_brand_id brand_id, item.i_brand brand, sum(ss.ss_ext_sales_price) sum_agg FROM date_dim dt, store_sales ss, item WHERE dt.d_date_sk = ss.ss_sold_date_sk AND ss.ss_item_sk = item.i_item_sk AND item.i_manufact_id = 128 AND dt.d_moy=11 GROUP BY dt.d_year, item.i_brand, item.i_brand_id ORDER BY dt.d_year, sum_agg DESC, brand_id LIMIT 100; |
Para a primeira configuração, especificamos dois "Analytics Disk Paths" no mesmo disco, o que resultou em cada conjunto de dados com duas partições de dados. Quanto à segunda configuração, apenas um "Dados analíticos Paths" foi especificado, o que acionou a opção de configuração automática. Como o nó tem 8 núcleos virtuais, 8 partições de dados foram criadas automaticamente. A Figura 2 abaixo mostra os tempos médios de resposta de consulta para essas duas configurações. Em termos de tempo médio de resposta de consulta, a configuração automática com 8 partições foi mais de duas vezes mais rápida do que a configuração com apenas 2 partições de dados. Essa melhoria foi causada pela melhor utilização do único SSD NVMe, pois esse tipo de disco pode lidar com 8 leituras simultâneas. Além disso, como essa consulta envolve agrupamento e classificação, o processamento dos dados simultaneamente em 8 partições resultou em uma melhoria significativa no desempenho da consulta.
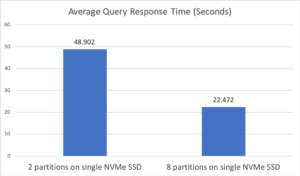
Figura 2: Tempo médio de resposta da consulta no Experimento 1
Experimento 2: instância única com 8 núcleos virtuais e 6 HDDs
Neste experimento, tentaremos examinar um volume maior de dados criando um único conjunto de dados que contenha todos os dados no bucket tpcds da seguinte forma:
|
1 |
CREATE DATASET tpcds on tpcds; |
Usamos a seguinte consulta do N1QL for Analytics que resulta na varredura de todos os dados usando duas configurações diferentes:
|
1 2 3 |
SELECT SUM(ss_ext_sales_price) FROM tpcds WHERE table_name = "store_sales"; |
Para a primeira configuração, foi especificado um único "Analytics Data Paths"; isso fez com que o sistema criasse automaticamente 8 partições em um único HDD. Na segunda configuração, foram especificados 6 "Analytics Data Paths" e cada caminho foi localizado em um HDD físico diferente, resultando em 6 partições de dados. A Figura 3 abaixo mostra o tempo médio de resposta da consulta para as duas configurações. Na primeira configuração, a execução de 8 leituras simultâneas em um único HDD resultou em desempenho ruim. Um dos principais motivos para isso é que a largura de banda de E/S dos outros 5 HDDs não foi utilizada. Além disso, a simultaneidade de 8 vias em um único HDD levou a mais movimentação do braço do disco, aumentando o custo médio de uma E/S de disco. A segunda configuração, que utilizou todos os 6 HDDs simultaneamente, teve como resultado uma melhora de mais de 7 vezes no desempenho.
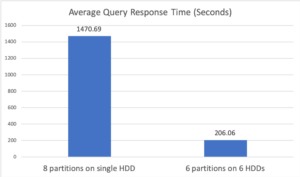
Figura 3: Tempo médio de resposta da consulta no Experimento 2
Conclusão:
O mecanismo do Analytics é um processador de consultas paralelas completo que oferece suporte a junções, agregações e classificações paralelas, com base nos "melhores algoritmos" extraídos de mais de 30 anos de pesquisa e desenvolvimento de MPP relacional, mas para dados JSON. Usando dois experimentos, mostramos o impacto significativo no desempenho que pode resultar de diferentes escolhas feitas ao configurar os "Analytics Disk Paths". Também demonstramos como o mecanismo do Analytics pode utilizar vários discos físicos, quando disponíveis, para acelerar significativamente as consultas do Analytics.