Ser capaz de executar consultas de pesquisa de texto completo em Couchbase sem a necessidade de ferramentas adicionais, como a Elastic, é enorme para o NoSQL.
Há cerca de um ano, escrevi sobre o uso de Pesquisa de texto completo (FTS) no Couchbase Server com o SDK do Node.js. Isso foi na época em que o FTS estava na versão prévia para desenvolvedores. Embora ainda seja muito válido, ele não resume o verdadeiro poder do que você pode fazer com o Full Text Search. Pegue facetas por exemplo. As facetas são informações agregadas coletadas em um conjunto de resultados e são úteis quando se trata de categorização de dados de resultados.
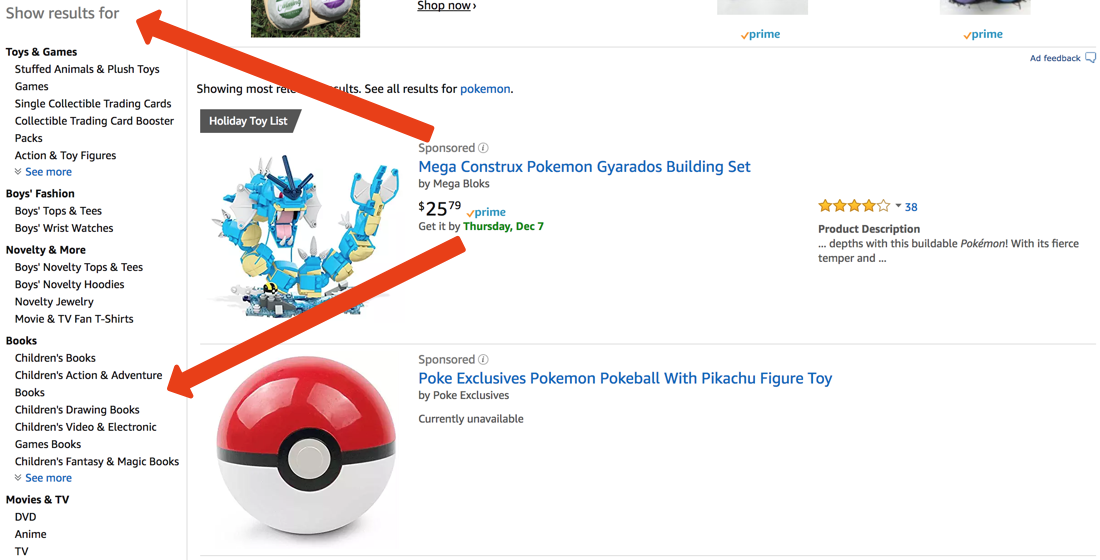
A imagem acima mostra uma pesquisa na Amazon. Digamos que tenhamos pesquisado por Pokémon. As categorias à esquerda, como, Livros ou Filmes e TVpodem ser consideradas facetas de pesquisa.
Veremos como aproveitar essa funcionalidade de pesquisa facetada em um aplicativo Node.js.
A partir de agora, você já deve ter o Node.js e o Couchbase Server 5.0+ instalados e configurados. Vamos nos concentrar no código e na criação de índices para que o FTS facetado funcione em nosso aplicativo.
Preparação de um compartimento de amostra com dados de amostra
Em vez de criar nossos próprios dados para trabalhar, vamos aproveitar os dados de amostra opcionais disponibilizados para qualquer pessoa que use o Couchbase. Vamos aproveitar o amostra de cerveja balde.
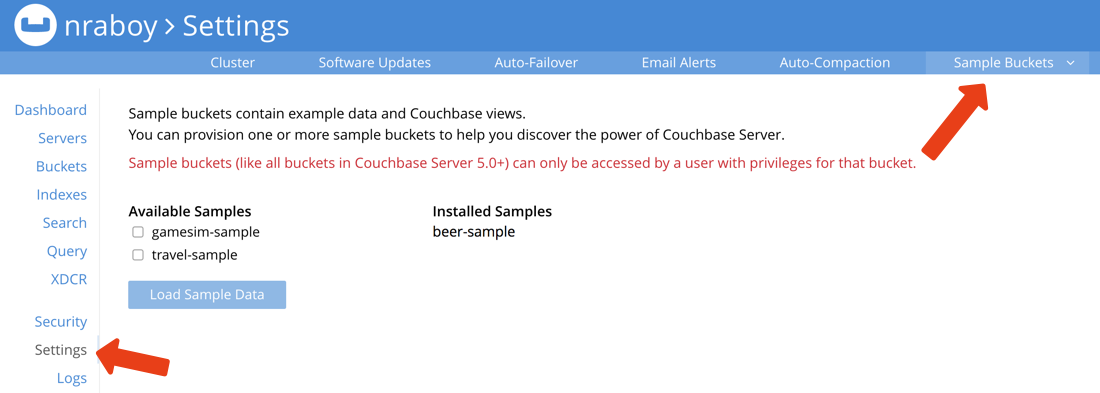
Se você não tiver certeza de como instalar esse bucket, no painel administrativo do Couchbase, escolha Configurações e, em seguida, selecione Baldes de amostra. O conjunto de amostras nos dará cerca de 8.000 documentos para trabalhar.
Criação de um índice para pesquisa de texto completo com o Couchbase NoSQL
Antes que qualquer pesquisa possa ser feita no banco de dados, um índice FTS especial deve ser criado. O objetivo desse índice é escolher duas propriedades em um determinado documento para pesquisar. Uma propriedade representará o que desejamos pesquisar e a outra representará nossas facetas, bem como o que desejamos pesquisar.
No painel de controle administrativo, selecione Pesquisa e, em seguida, selecione Adicionar índice.
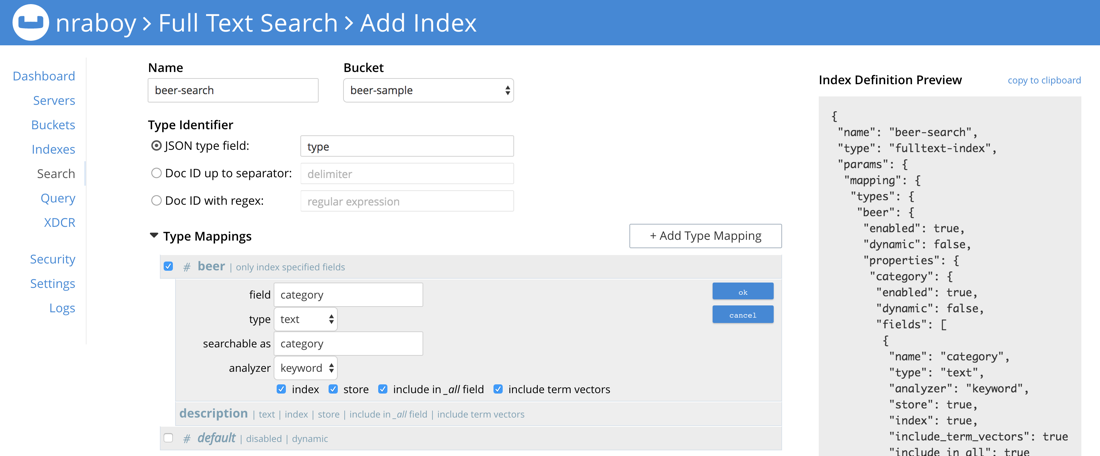
É aqui que as coisas podem ficar um pouco estranhas se esta for a primeira vez que você está brincando com o Full Text Search no Couchbase.
Ao projetar o índice, você deve dar um nome a ele. Estou usando o nome, Busca de cervejamas você pode usar o que quiser. Apenas certifique-se de que seja para o amostra de cerveja balde. Deixe o Identificador de tipo como padrão e entrar no Mapeamentos de tipos seção.
Planejamos pesquisar documentos que tenham um tipo que corresponde à propriedade cerveja daí o mapeamento que criamos na imagem acima. É importante que estejamos indexando apenas os campos especificados a seguir, e não o documento inteiro. No novo mapeamento, precisamos criar campos secundários. Esses campos filhos representam o que podemos facetar e o que podemos pesquisar.
O descrição usará os padrões, mas estamos selecionando o campo loja opção. Isso nos permitirá acessá-la no resultado. A opção categoria usará o campo palavra-chave analisador e o loja opção. Como nossas categorias contêm várias palavras por categoria, o analisador precisa saber como lidar com o texto delimitado por espaço. A opção palavra-chave permitirá que trabalhemos com esses termos.
Por fim, salve o índice e todos os documentos deverão ser indexados após um pequeno período de tempo.
Execução de uma consulta de pesquisa de texto completo com facetas no Node.js
Vamos consultar o recém-criado Busca de cerveja em duas partes para imitar como isso seria feito em um site como o da Amazon. Primeiro, executaremos uma consulta com base no termo e mostraremos os resultados, bem como as facetas. Essas facetas nos prepararão para a segunda parte.
Supondo que você tenha um projeto Node.js configurado corretamente disponível, adicione o seguinte código JavaScript:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const Couchbase = exigir("couchbase"); const Pesquisa = Couchbase.Pesquisa; const BuscaFaceta = Couchbase.BuscaFaceta; const agrupamento = novo Couchbase.Aglomerado("couchbase://localhost"); agrupamento.autenticar("demo", "123456") const balde = agrupamento.openBucket("amostra de cerveja"); var tq1 = Pesquisa.prazo("café").campo("description" (descrição)); var consulta1 = Pesquisa.novo("busca de cerveja", tq1); consulta1.addFacet("categories" (categorias), BuscaFaceta.prazo("category" (categoria), 5)); consulta1.limite(3); balde.consulta(consulta1, (erro, resultado, meta) => { para(var i = 0; i < resultado.comprimento; i++) { console.registro("HIT: ", resultado[i].id); console.registro("FACETS: ", meta.facetas["categories" (categorias)].termos); } }); |
A maior parte do código acima está relacionada ao estabelecimento de uma conexão com o cluster e à preparação da pesquisa que se segue. O que mais nos interessa é o seguinte:
|
1 2 3 4 5 6 7 8 9 10 11 |
var tq1 = Pesquisa.prazo("café").campo("description" (descrição)); var consulta1 = Pesquisa.novo("busca de cerveja", tq1); consulta1.addFacet("categories" (categorias), BuscaFaceta.prazo("category" (categoria), 5)); consulta1.limite(3); balde.consulta(consulta1, (erro, resultado, meta) => { para(var i = 0; i < resultado.comprimento; i++) { console.registro("HIT: ", resultado[i].id); console.registro("FACETS: ", meta.facetas["categories" (categorias)].termos); } }); |
No código acima, estamos definindo um termo de pesquisa chamado tq1 que pesquisa no descrição propriedade para café. Quando criamos nossa consulta de pesquisa, definimos o índice que criamos anteriormente e adicionamos o termo de pesquisa.
Estamos adicionando uma faceta chamada categoriasque é um nome que acabamos de inventar. O termo que categorias mapeia para é o categoria dentro do documento. Também estamos dizendo que não queremos que mais de cinco facetas apareçam em nossos resultados.
Quando executamos o código, devemos obter algo parecido com o seguinte:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
HIT: lagunitas_brewing_company-cappuccino_stout FATOS: [ { prazo: "North American Ale" (cerveja norte-americana), contagem: 50 }, { prazo: "Irish Ale" (cerveja irlandesa), contagem: 19 }, { prazo: "British Ale, contagem: 11 }, { prazo: "German Lager" (cerveja alemã), contagem: 4 }, { prazo: "Ale belga e francesa, contagem: 3 } ] HIT: terrapin_beer_company-terrapin_coffee_oatmeal_imperial_stout FATOS: [ { prazo: "North American Ale" (cerveja norte-americana), contagem: 50 }, { prazo: "Irish Ale" (cerveja irlandesa), contagem: 19 }, { prazo: "British Ale, contagem: 11 }, { prazo: "German Lager" (cerveja alemã), contagem: 4 }, { prazo: "Ale belga e francesa, contagem: 3 } ] HIT: humboldt_brewing-black_xantus FATOS: [ { prazo: "North American Ale" (cerveja norte-americana), contagem: 50 }, { prazo: "Irish Ale" (cerveja irlandesa), contagem: 19 }, { prazo: "British Ale, contagem: 11 }, { prazo: "German Lager" (cerveja alemã), contagem: 4 }, { prazo: "Ale belga e francesa, contagem: 3 } ] |
Observe que a chave do documento é impressa, bem como as facetas que aparecem na pesquisa. O termo da faceta também inclui a quantidade de vezes que ela ocorre. Se quiséssemos, poderíamos ter incluído outros campos no resultado, mas a chave do documento e as facetas são suficientes para este exemplo.
Agora que conhecemos nossos resultados, vamos restringir nossa consulta.
Execução de uma consulta conjuntiva com vários termos de pesquisa no Node.js
Vamos supor que nosso usuário tenha pesquisado por cafémas também optou por restringir a seleção de cervejas a Lager alemã. Isso significa que, em algum front-end, o usuário selecionou uma das facetas após a pesquisa.
Vamos dar uma olhada no código JavaScript a seguir:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
const Couchbase = exigir("couchbase"); const Pesquisa = Couchbase.Pesquisa; const BuscaFaceta = Couchbase.BuscaFaceta; const agrupamento = novo Couchbase.Aglomerado("couchbase://localhost"); agrupamento.autenticar("demo", "123456") const balde = agrupamento.openBucket("amostra de cerveja"); var tq1 = Pesquisa.prazo("café").campo("description" (descrição)); var tq2 = Pesquisa.prazo("German Lager").campo("category" (categoria)); var conjunção = Pesquisa.Conjuntos(tq1, tq2); consulta2 = Pesquisa.novo("busca de cerveja", conjunção); consulta2.addFacet("categories" (categorias), BuscaFaceta.prazo("category" (categoria), 5)); consulta2.limite(3); balde.consulta(consulta2, (erro, resultado, meta) => { para(var i = 0; i < resultado.comprimento; i++) { console.registro("HIT: ", resultado[i].id); console.registro("FACETS: ", meta.facetas["categories" (categorias)].termos); } }); |
Fizemos algumas alterações.
Em vez de ter um único termo de pesquisa, agora temos dois termos de pesquisa. Um deles pesquisará o descriçãocomo o anterior, mas o novo termo será pesquisado no categoria propriedade. Para pesquisar usando dois termos, temos que realizar o que chamamos de consulta conjuntiva.
A execução do código acima produziria um resultado parecido com o seguinte:
|
1 2 3 4 5 6 |
HIT: cerveja_de_purga-black_bavarian_lager FATOS: [ { prazo: "German Lager" (cerveja alemã), contagem: 4 } ] HIT: cervejaria red_oak-campo de batalha_bock FATOS: [ { prazo: "German Lager" (cerveja alemã), contagem: 4 } ] HIT: four_peaks_brewing-black_betty_schwartzbier FATOS: [ { prazo: "German Lager" (cerveja alemã), contagem: 4 } ] |
Observe que nossos resultados contêm apenas German Lagers em comparação com a variedade que vimos anteriormente. Isso ocorre porque conseguimos usar as informações da faceta para restringir nossos resultados com uma consulta secundária.
O código JavaScript completo do exemplo
Para ver tudo junto, seria parecido com o seguinte:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
const Couchbase = exigir("couchbase"); const Pesquisa = Couchbase.Pesquisa; const BuscaFaceta = Couchbase.BuscaFaceta; const agrupamento = novo Couchbase.Aglomerado("couchbase://localhost"); agrupamento.autenticar("demo", "123456") const balde = agrupamento.openBucket("amostra de cerveja"); var tq1 = Pesquisa.prazo("café").campo("description" (descrição)); var consulta1 = Pesquisa.novo("busca de cerveja", tq1); consulta1.addFacet("categories" (categorias), BuscaFaceta.prazo("category" (categoria), 5)); consulta1.limite(3); balde.consulta(consulta1, (erro, resultado, meta) => { para(var i = 0; i < resultado.comprimento; i++) { console.registro("HIT: ", resultado[i].id); console.registro("FACETS: ", meta.facetas["categories" (categorias)].termos); } }); var tq2 = Pesquisa.prazo("German Lager").campo("category" (categoria)); var conjunção = Pesquisa.Conjuntos(tq1, tq2); consulta2 = Pesquisa.novo("busca de cerveja", conjunção); consulta2.addFacet("categories" (categorias), BuscaFaceta.prazo("category" (categoria), 5)); consulta2.limite(3); balde.consulta(consulta2, (erro, resultado, meta) => { para(var i = 0; i < resultado.comprimento; i++) { console.registro("HIT: ", resultado[i].id); console.registro("FACETS: ", meta.facetas["categories" (categorias)].termos); } }); |
Observe que o código acima não é realista. Por um lado, ele é assíncrono. A realidade das coisas seria controlada pela interação do usuário. O usuário faz uma pesquisa, altera algo e, em seguida, faz uma pesquisa secundária como descrito anteriormente.
Conclusão
Você acabou de ver como pesquisar com facetas em Couchbase usando o Full Text Search (FTS) e o SDK do Node.js. O FTS é uma forma de consultar a linguagem natural e é muito diferente do N1QL. O FTS é muito avançado e é possível fazer muitas coisas excelentes.
Para obter mais informações sobre como usar a pesquisa de texto completo com o Couchbase, consulte a Portal do desenvolvedor do Couchbase.