O objetivo do Couchbase é permitir que cada vez mais aplicativos corporativos aproveitem e adotem o modelo de dados NoSQL/JSON. O N1QL simplifica essa transição dos bancos de dados relacionais tradicionais e foi desenvolvido com vários recursos para obter o melhor dos dois mundos. Continuando o trem do Couchbase Server 4.5, a versão 4.5.1 traz várias melhorias de funcionalidade, usabilidade e desempenho no N1QL. Esses aprimoramentos abordam muitos dos problemas críticos de nossos clientes e, em geral, demonstram a força e a sofisticação do N1QL.
Embora alguns dos novos aprimoramentos melhorem a funcionalidade existente, outros, como a função SUFFIXES(), enriquecem a consulta N1QL com uma grande melhoria no desempenho das consultas LIKE. Outros aprimoramentos melhoram a criação e a manipulação dinâmica de objetos JSON, a precisão dos números, a sintaxe UPDATE para matrizes aninhadas etc,
Tenho certeza de que isso exigirá uma série, mas neste blog destacarei os aprimoramentos da LIKE-query e da UPDATE. Veja o Couchbase Server 4.5.1 O que há de novo e Notas de versão para obter a lista completa de aprimoramentos do N1QL. Parabéns à equipe do N1QL!
Consultas LIKE de correspondência de padrões eficientes com SUFFIXES()
A correspondência de padrões é uma funcionalidade amplamente usada em consultas SQL e, normalmente, é obtida com o uso do operador LIKE. Em especial, a correspondência curinga eficiente é muito importante. LIKE 'foo%' pode ser implementado de forma eficiente com um índice padrão, mas não LIKE '%foo%'. Essa correspondência de padrões com curinga principal é vital para todos os aplicativos que têm uma caixa de pesquisa para corresponder a palavras parciais ou para sugerir texto correspondente de forma inteligente. Por exemplo,
- Um site de reservas de viagens que deseja exibir aeroportos correspondentes quando o usuário começa a digitar algumas letras do nome do aeroporto.
- Um usuário que encontra todos os e-mails com uma palavra específica ou uma palavra parcial no assunto.
- Encontrar todos os tópicos de um fórum ou postagens de blog com palavras-chave específicas no título.
No Couchbase Server 4.5.1, o N1QL resolve esse problema adicionando uma nova função de string SUFFIXES() e combinando-a com a funcionalidade de indexação de matriz introduzida no Couchbase Server 4.5. Juntas, elas trazem uma grande diferença no desempenho das consultas LIKE com curingas principais, como LIKE "%foo%". A funcionalidade principal de SUFFIXES() é muito simples, basicamente ela produz uma matriz de todas as possíveis substrings de sufixo de uma determinada string. Por exemplo,
|
1 |
SUFIXOS("N1QL") = [ "N1QL", "1QL", "QL", "L" ] |
A imagem a seguir mostra uma técnica exclusiva para combinar SUFFIXES() com a indexação de matriz para aumentar magicamente o GOSTO desempenho da consulta.
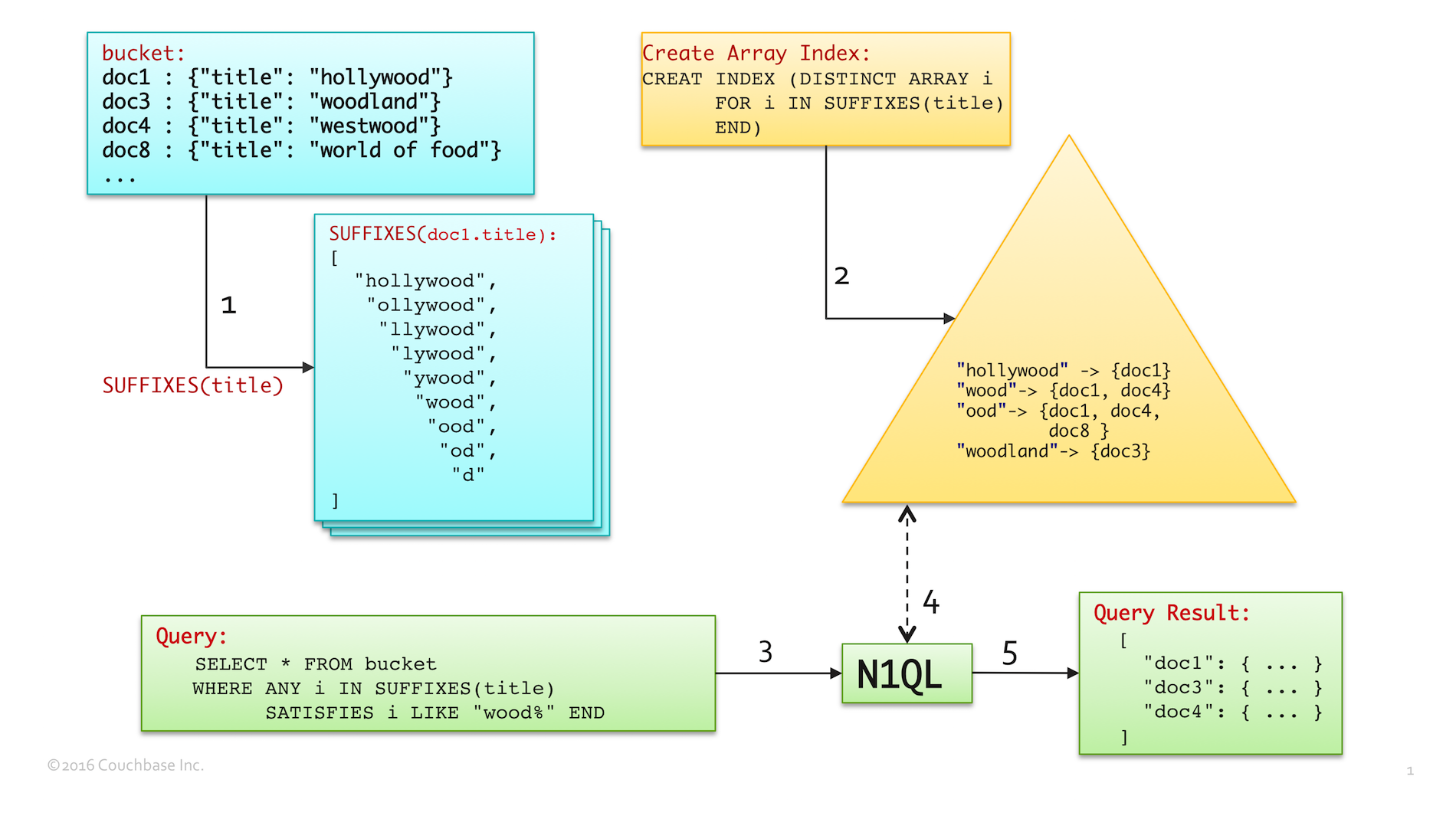
- A etapa 1 (em azul) mostra a matriz de substrings de sufixo gerada por
SUFFIXES()paradoc1.title - A etapa 2 (em amarelo) mostra o índice de matriz criado com as substrings de sufixo geradas na etapa 1. Observe que a entrada de índice para
"madeira"aponta paradoc1edoc4pois essa é uma das substrings de sufixo dos títulos de ambos os documentos. Da mesma forma,"ood"aponta paradoc1,doc4edoc8. - A etapa 3 (em verde) executa uma consulta equivalente a
SELECT title FROM bucket WHERE title LIKE "%wood%". O predicado LIKE é transformado para usar o índice de matriz usando a construção ANY. Consulte a documentação para obter mais detalhes sobre como usar a indexação de matriz.- Observe que o curinga inicial é removido no novo
LIKE "wood%"predicado. - Essa é uma transformação precisa, porque a pesquisa de índice de matriz para
"madeira"aponta para todos os documentos cujo título tenha a subcadeia final"madeira"
- Observe que o curinga inicial é removido no novo
- Na Etapa 4, o N1QL procura no Array Index para encontrar todos os documentos que correspondam a
"wood%". Isso retorna{doc1, doc3, doc4}porque- a pesquisa de índice produz uma extensão, que obtém documentos de
"madeira"para"wooe" doc1edoc4são combinados por causa da entrada de índice "wood" gerada por SUFFIXES() ao criar o índice da matriz.doc3é correspondido por causa de sua entrada de índice correspondente para"woodland" (floresta)
- a pesquisa de índice produz uma extensão, que obtém documentos de
- Por fim, na etapa 5, o N1QL retorna os resultados da consulta.
Vamos ver um exemplo de trabalho com o amostra de viagem documentos, o que mostrou um aumento de 12x no desempenho da consulta.
- Suponha um documento com um campo de string cujo valor seja algumas palavras de texto ou uma frase. Por exemplo, o título de um ponto de referência, o endereço de um local, o nome de um restaurante, o nome completo de uma pessoa/lugar etc., Para essa explicação, consideramos
títulodemarco históricodocumentos emamostra de viagem. - Criar índice secundário em
títulocampo usandoSUFFIXES()como:
123CRIAR ÍNDICE idx_title_suffixON `viagens-amostra`(DISTINTO ARRAY s PARA s IN SUFIXOS(título) FIM)ONDE tipo = "marco";
SUFFIXES(título)gera todas as possíveis substrings de sufixo detítuloe o índice terá entradas para cada uma dessas substrings, todas fazendo referência aos documentos correspondentes. - Agora, considere a seguinte consulta, que encontra todos os documentos com a substring
"terra"emtítulo. Essa consulta produz o seguinte plano e é executada em aproximadamente 120 ms no meu laptop. Você pode ver claramente que ela busca todos osmarco históricodocumentos e, em seguida, aplica oLIKE "%land%"para encontrar todos os documentos correspondentes.
12345678910111213141516171819202122232425262728293031323334353637383940414243EXPLICAR SELECT * DE `viagens-amostra` USO ÍNDICE(def_type) ONDE tipo = "marco" E título GOSTO "%land%";[{"plano": {"#operator": "Sequência","~crianças": [{"#operator": "IndexScan","índice": "def_type","index_id": "e23b6a21e21f6f2","espaço-chave": "amostra de viagem","namespace": "default","vãos": [{"Faixa": {"Alta": [""marco histórico""],"Inclusão": 3,"Baixa": [""marco histórico""]}}],"usando": "gsi"},{"#operator": "Buscar","espaço-chave": "amostra de viagem","namespace": "default"},{"#operator": "Paralelo","~child": {"#operator": "Sequência","~crianças": [{"#operator": "Filtro","condição": "(((`travel-sample`.`type`) = "marco histórico") e ((`travel-sample`.`title`) como "%terra%"))"}]} - No Couchbase 4.5.1, essa consulta pode ser reescrita para aproveitar o índice de matriz
idx_title_suffixcriado em (2) acima.
12345678910111213141516171819202122232425262728293031323334353637383940414243444546EXPLICAR SELECIONAR título DE `viagens-amostra` USO ÍNDICE(idx_title_suffix) ONDE tipo = "marco" EQUALQUER s IN SUFIXOS(título) SATISFAÇÕES s GOSTO "land%" FIM;[{"plano": {"#operator": "Sequência","~crianças": [{"#operator": "DistinctScan","scan": {"#operator": "IndexScan","índice": "idx_title_suffix","index_id": "75b20d4b253214d1","espaço-chave": "amostra de viagem","namespace": "default","vãos": [{"Faixa": {"Alta": [""pista""],"Inclusão": 1,"Baixa": [""terra""]}}],"usando": "gsi"}},{"#operator": "Buscar","espaço-chave": "amostra de viagem","namespace": "default"},{"#operator": "Paralelo","~child": {"#operator": "Sequência","~crianças": [{"#operator": "Filtro","condição": "(((`travel-sample`.`type`) = "marco histórico") e qualquer `s` em suffixes((`travel-sample`.`title`)) satisfaz (`s` like "terra%") end)"},
Observe que:
- A nova consulta em (4) usa
LIKE "land%", em vez deLIKE "%land%". O predicado anterior sem curinga inicial'%'produz uma pesquisa de índice muito mais eficiente do que a última, que não pode empurrar o predicado para o índice. - o índice da matriz
idx_title_suffixé criado com todas as possíveis substrings de sufixo detítuloe, portanto, a pesquisa de qualquer substring de sufixo do título pode encontrar uma correspondência bem-sucedida. - No plano de consulta 4.5.1 acima em (4), o N1QL transfere o predicado LIKE para a pesquisa de índice e evita o processamento adicional da string de correspondência de padrões. Essa consulta foi executada em 18 ms.
- De fato, com o índice de matriz de cobertura a seguir, a consulta foi executada em 10 ms, o que é 12 vezes mais rápido.
|
1 2 3 |
CRIAR ÍNDICE idx_title_suffix_cover ON `viagens-amostra`(DISTINTO ARRAY s PARA s IN SUFIXOS(título) FIM, título) ONDE tipo = "marco"; |
Veja isso blog para obter detalhes sobre um aplicativo do mundo real desse recurso.
Aprimoramentos no UPDATE para trabalhar com matrizes aninhadas
Os aplicativos corporativos geralmente têm dados complexos e precisam modelar documentos JSON com vários níveis de objetos e matrizes aninhados. O N1QL oferece suporte a expressões complexas e construções de linguagem para navegar e consultar esses documentos com matrizes aninhadas. O N1QL também oferece suporte a Indexação de matrizescom o qual os índices secundários podem ser criados nos elementos da matriz e, posteriormente, consultados.
No Couchbase Server 4.5.1, o ATUALIZAÇÃO A sintaxe da instrução foi aprimorada para navegar por matrizes aninhadas em documentos e atualizar campos específicos em elementos de matrizes aninhadas. A declaração PARA-cláusula do ATUALIZAÇÃO foi aprimorada para avaliar funções e expressões, e a nova sintaxe oferece suporte a vários comandos PARA para acessar e atualizar campos em matrizes aninhadas.
Considere o seguinte documento com uma matriz aninhada como:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ itens: [ { subitens: [ { nome: "N1QL" }, { nome: "GSI" } ] } ], docType: "couchbase" } |
O novo ATUALIZAÇÃO em 4.5.1 pode ser usada de diferentes maneiras para acessar e atualizar matrizes aninhadas:
-
12ATUALIZAÇÃO padrão CONJUNTO s.newField = 'newValue'PARA s IN ARRAY_FLATTEN(itens[*].subitens, 1) FIM;
-
123ATUALIZAÇÃO padrãoCONJUNTO s.newField = 'newValue'PARA s IN ARRAY_FLATTEN(ARRAY i.subitens PARA i IN itens FIM, 1) FIM;
-
123ATUALIZAÇÃO padrãoCONJUNTO i.subitens = ( ARRAY OBJECT_ADD(s, 'newField', 'newValue')PARA s IN i.subitens FIM ) PARA i IN itens FIM;
Observe que:
- O
CONJUNTOA cláusula - avalia funções comoOBJECT_ADD()eARRAY_FLATTEN() PARApodem ser usadas de forma aninhada com expressões para processar elementos de matriz em diferentes níveis de aninhamento.
Para obter um exemplo de trabalho, considere o bucket de amostra amostra de viagem fornecido com a versão 4.5.1.
- Primeiro, vamos adicionar uma matriz aninhada de voos especiais à matriz de programação em
amostra de viagembalde, para alguns documentos.
123456ATUALIZAÇÃO `viagens-amostra`CONJUNTO cronograma[0] = {"dia" : 7, "special_flights" (voos especiais) :[ {"voo" : "AI444", "utc" : "4:44:44"},{"voo" : "AI333", "utc" : "3:33:33"}] }ONDE tipo = "route" (rota) E aeroporto de destino = "CDG" E aeroporto de origem = "TLV"; - A instrução UPDATE a seguir adiciona um terceiro campo a cada voo especial:
12345678910111213141516171819202122232425262728ATUALIZAÇÃO `viagens-amostra`CONJUNTO i.voos_especiais = ( ARRAY OBJECT_ADD(s, 'newField', 'newValue' )PARA s IN i.voos_especiais FIM )PARA i IN cronograma FIMONDE tipo = "route" (rota) E aeroporto de destino = "CDG" E aeroporto de origem = "TLV";SELECIONAR cronograma[0] de `viagens-amostra`ONDE tipo = "route" (rota) E aeroporto de destino = "CDG" E aeroporto de origem = "TLV" LIMITE 1;[{"$1": {"dia": 7,"special_flights" (voos especiais): [{"voo": "AI444","newField": "newValue","utc": "4:44:44"},{"voo": "AI333","newField": "newValue","utc": "3:33:33"}]}}]
Há muitos outros aprimoramentos importantes do N1QL e recursos de desempenho na versão 4.5.1 do Couchbase Server. Escreverei sobre eles em meu próximo blog/parte2.
Download 4.5.1 e experimente. Informe-me se tiver alguma dúvida/comentário ou se estiver achando o produto fantástico ;-)
Saúde!!!