Amplie a pesquisa de texto completo no Couchbase Server 4.5 Beta
O Couchbase Server 4.5 inclui um novo serviço, pesquisa de texto completo (FTS) . Neste blog, falarei sobre como o FTS é dimensionado entre nós, como replicar índices e como ele se comporta em um rebalanceamento.
Desde o lançamento do Couchbase Server 4.5 Developer Preview, a equipe do FTS tem estado ocupada. A versão beta do Couchbase Server 4.5 não apenas elimina vários bugs do FTS, mas também inclui muitos aprimoramentos importantes no FTS:
- Desempenho de indexação 12x mais rápido
- melhores estatísticas
- suporte para autenticação e controle de acesso baseado em função
- Registro de auditoria de eventos do administrador
- suporte para resultados parciais
O novo recurso de pesquisa mais notável na versão beta do 4.5 é a capacidade de executar o serviço FTS em vários nós. Você pode testá-lo hoje com a versão beta, e o que você leu aqui ainda se aplicará quando o Couchbase Server 4.5 for lançado no GA.
Deixe-me esclarecer a isenção de responsabilidade agora mesmo: O FTS continuará sendo uma prévia para desenvolvedores na versão GA do Couchbase Server 4.5, portanto, não o execute em um servidor de produção. Há muitas funcionalidades realmente excelentes no FTS, mas ainda não marcamos todas as caixas de seleção de testes de desempenho e sistema em nossa lista de tarefas. O lado positivo é que isso nos dá a oportunidade de abordar alguns dos comentários que estamos recebendo dos usuários dos primeiros testes. (Tem comentários? Sinta-se à vontade para me enviar um e-mail diretamente para will dot gardella at couchbase dot com)
Ok, vamos ao que interessa. Você pode usar o serviço de pesquisa para indexar e pesquisar texto em seus documentos do Couchbase sem depender de um pacote de pesquisa de terceiros. O novo serviço de pesquisa une os serviços de dados, índice e consulta e pode ser gerenciado como outros serviços para fins de dimensionamento multidimensional (MDS). Observe que, diferentemente do N1QL, o serviço de pesquisa faz consultas de texto completo e indexação em um único serviço.
Serviço de pesquisa distribuída - sob o capô
Na maioria das vezes, os índices de pesquisa distribuída "simplesmente funcionam": o serviço Couchbase Full Text Search aproveita o novo hardware à medida que você adiciona nós, e os índices de texto completo sofrem falhas e são rebalanceados junto com o serviço de dados. Esta seção fala sobre os mecanismos que permitem isso, que você normalmente não precisa conhecer como usuário, mas que às vezes encontrará, como nos resultados parciais de pesquisa (abordados mais adiante).
Desde o início, a pesquisa de texto completo foi projetada para distribuir índices de texto entre os nós, da mesma forma que o serviço de dados distribui dados em buckets. Se você entender a função buckets e vBucketsSe você tem um bom modelo mental para entender isso. O bucket é uma unidade lógica de contenção de dados que é fácil de trabalhar, e o vBucket é uma parte física dos dados que estão em um bucket, que vive em um nó específico em um cluster. Quando você ativa a replicação em um bucket, o Couchbase Server cria cópias de todos os vBuckets necessários que compõem esse bucket. O Couchbase Server também garante que o layout desses vBuckets seja ideal, o que, por si só, é um tópico complexo, mas, por enquanto, você pode pensar nisso como o equilíbrio dos locais dos vBuckets para que eles sejam distribuídos uniformemente entre os nós.
O FTS funciona de forma semelhante. Os índices de texto completo são automaticamente divididos em fragmentos chamados pindexesque é a abreviação de "índices particionados" ou "índices físicos", dependendo de quem você perguntar. Assim como um bucket, um índice de texto completo é um conceito lógico. O pindex é a implementação física do índice, assim como o vBucket é a implementação física do bucket.
Os pindexes são distribuídos fisicamente pelos nós do Couchbase que executam o serviço de pesquisa, por mais numerosos que sejam. Na visualização para desenvolvedores, era um único nó, mas essa restrição foi suspensa na versão Beta. Nos exemplos abaixo, usaremos apenas dois nós para manter a simplicidade.
Adição de um nó de pesquisa
É hora de colocar a mão na massa. Se você tiver o Couchbase Server 4.5 Beta ou mais recente, estará pronto para começar. Você precisará configurar mais de um nó, portanto, prepare uma VM. Para este exemplo, vou usar duas VMs do Windows Server 2012.
Vamos começar com um único nó executando o serviço de pesquisa. Criaremos um índice simples nos documentos de hotel do bucket de amostra de viagem. Se você não tiver a amostra de viagem instalada, poderá obtê-la clicando em Configurações > Baldes de amostra e, em seguida, marcar a caixa.
Para fins desta demonstração, qualquer índice de texto completo serve. Criei um índice em type="hotel" (não se esqueça de desativar o mapeamento de tipo padrão) com dois campos, "name" e "description", store = true e "index only specified fields" (indexar somente os campos especificados), apenas para que o índice seja construído rapidamente.
Aqui está o comando curl, caso você tenha alergia à interface do usuário:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
curl -XPUT -H "Content-Type: application/json" https://localhost:8094/api/index/hotel -d '{ "type": "fulltext-index", "name": "hotel", "sourceType": "couchbase", "sourceName": "travel-sample", "planParams": { "maxPartitionsPerPIndex": 32, "numReplicas": 0, "hierarchyRules": null, "nodePlanParams": null, "pindexWeights": null, "planFrozen": false }, "params": { "mapping": { "byte_array_converter": "json", "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "display_order": "1", "dynamic": true, "enabled": false }, "default_type": "_default", "index_dynamic": true, "store_dynamic": false, "type_field": "type", "types": { "hotel": { "display_order": "0", "dynamic": false, "enabled": true, "properties": { "description": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "", "display_order": "0", "include_in_all": true, "include_term_vectors": true, "index": true, "name": "description", "store": true, "type": "text" } ] }, "name": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "", "display_order": "1", "include_in_all": true, "include_term_vectors": true, "index": true, "name": "name", "store": true, "type": "text" } ] } } } } }, "store": { "kvStoreName": "forestdb" } }, "sourceParams": { "clusterManagerBackoffFactor": 0, "clusterManagerSleepInitMS": 0, "clusterManagerSleepMaxMS": 2000, "dataManagerBackoffFactor": 0, "dataManagerSleepInitMS": 0, "dataManagerSleepMaxMS": 2000, "feedBufferAckThreshold": 0, "feedBufferSizeBytes": 0 } }' |
Quando terminar, você pode pesquisar uma palavra comum, como "Inn", para ter certeza de que as coisas estão funcionando.
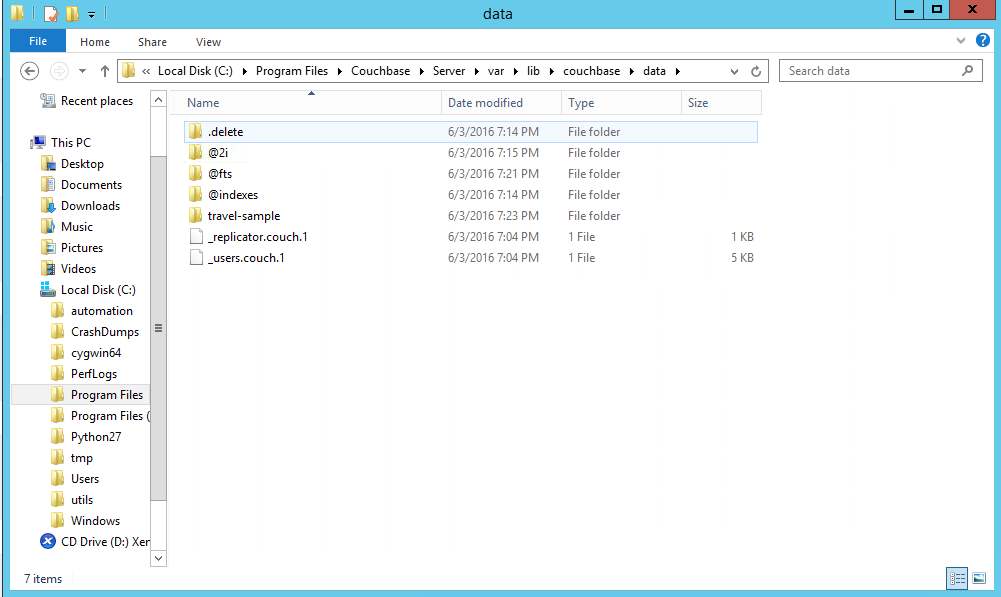
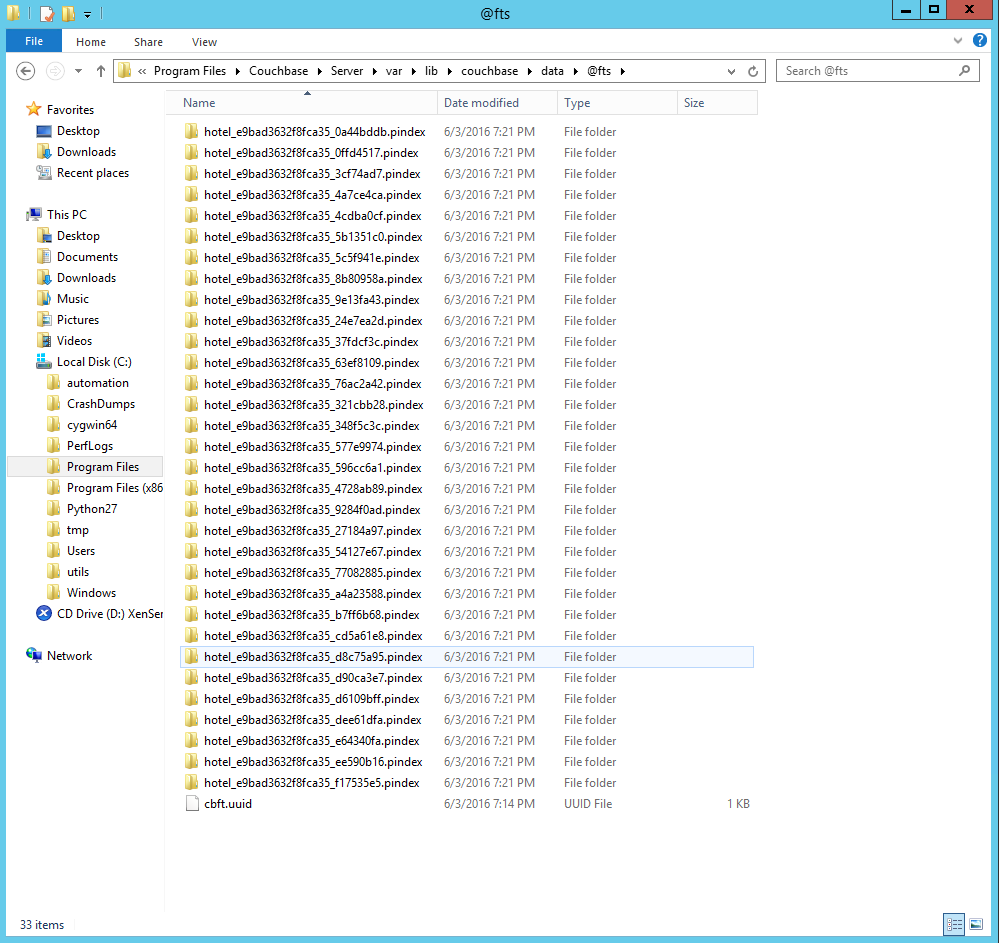
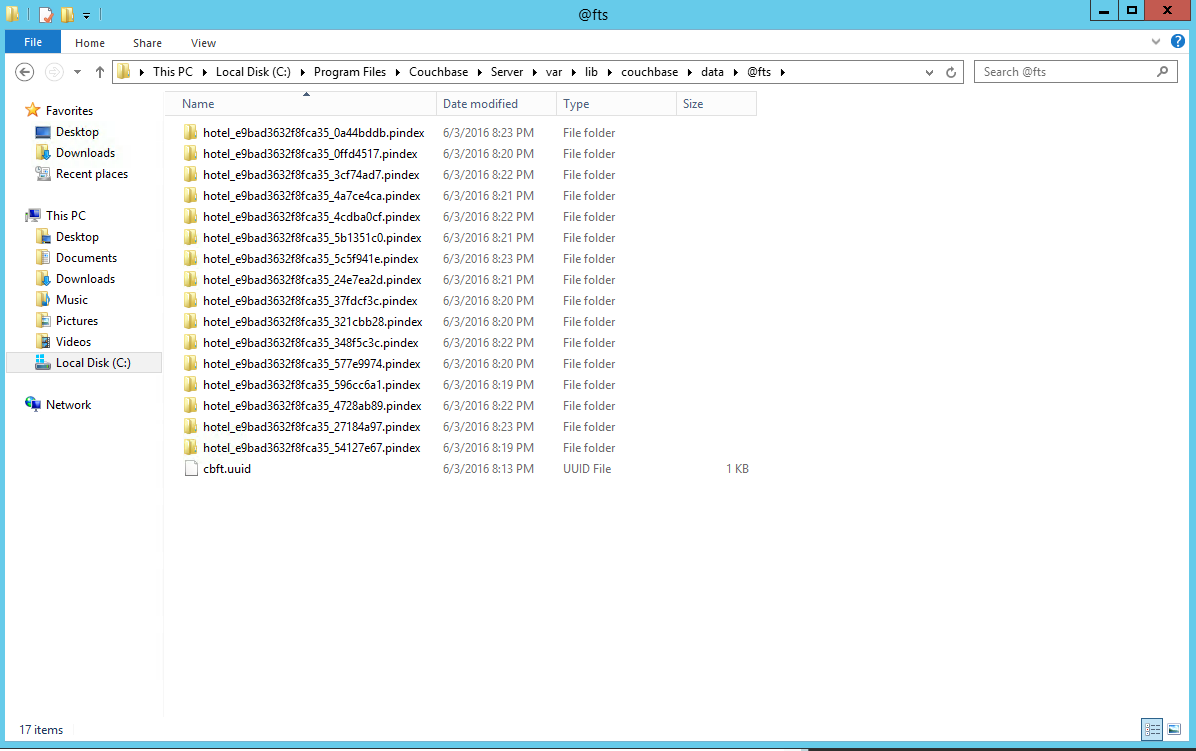
Ao dar uma olhada no diretório de dados do Couchbase, você verá um @fts diretório. Abra-o e você verá vários diretórios contendo os pindexes.
Segundo nó de pesquisa e rebalanceamento
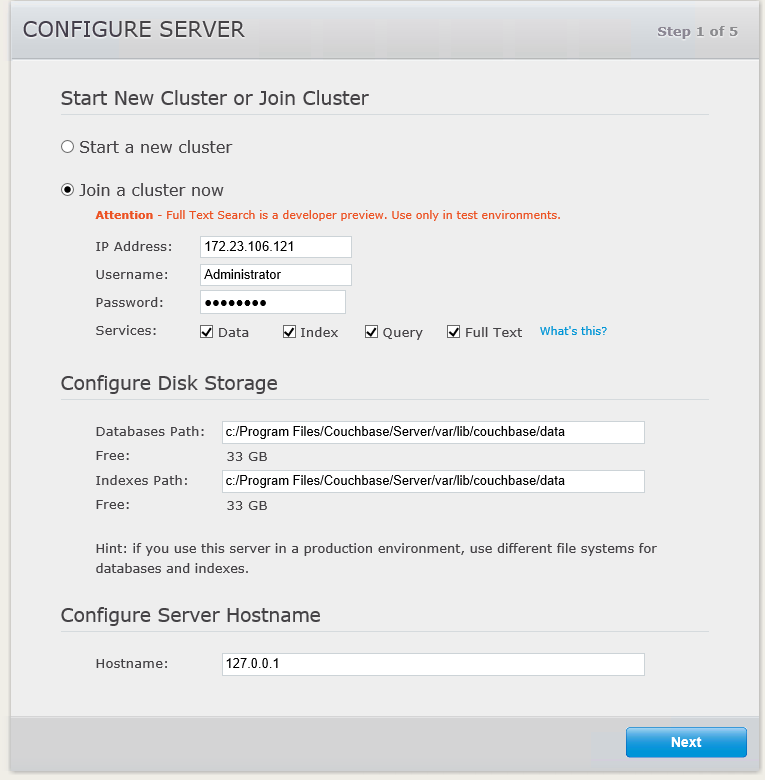
Vá em frente e adicione um segundo nó ao cluster, como faria normalmente. Não se esqueça de marcar a caixa para ativar o serviço de pesquisa.
Quando terminar, você verá uma tela parecida com esta, mostrando um servidor com rebalanceamento pendente.
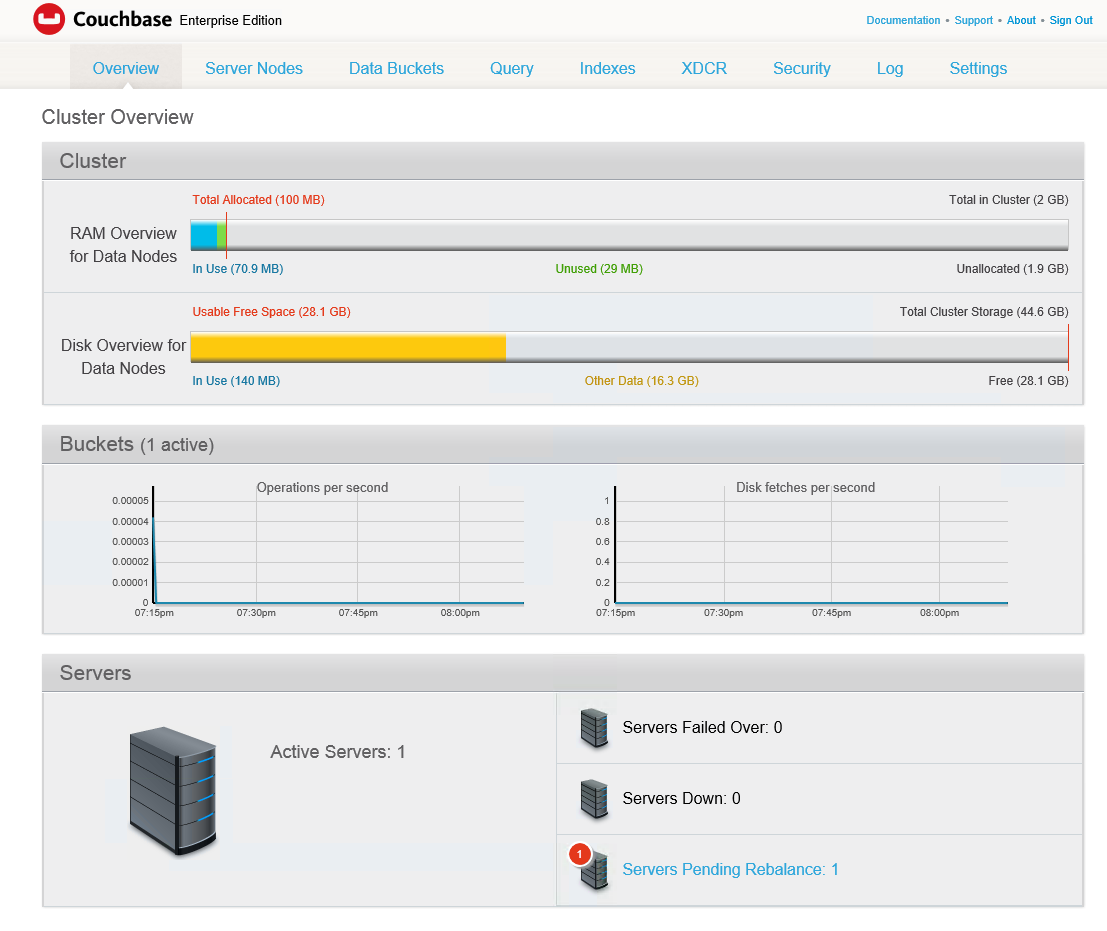
Nesse caso, vejo um aviso de fail over porque os dados de amostra de viagem não têm réplicas. Entro e pressiono o botão de rebalanceamento. Os documentos começam a ser copiados para o novo nó, as réplicas são criadas e as exibições da amostra de viagem são mostradas como "em construção" porque são uma forma de índice local, portanto, o rebalanceamento de dados significa que as exibições também precisam ser reconstruídas à medida que os dados ativos são movidos. (Se você quiser economizar algum tempo para os fins desta demonstração, poderá excluir as exibições). Seus pindexes também são rebalanceados entre os nós disponíveis.
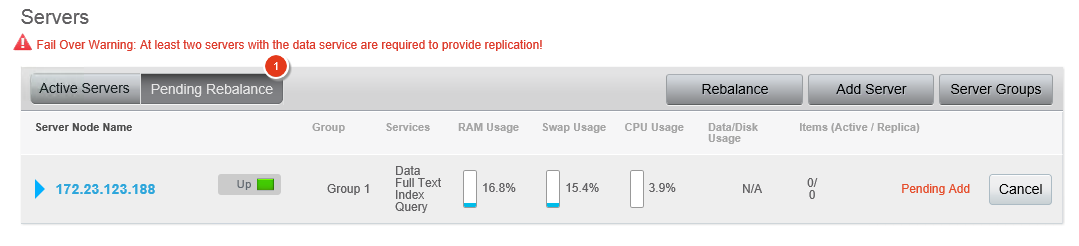
Quando o processo for concluído, você terá agora metade dos pindexes em cada servidor.
Para verificar isso, verifique o da do Couchbaseta novamente. Você verá metade do número de diretórios:
Réplicas de índices
Os índices de texto completo podem ser replicados, assim como você pode ter documentos ativos e réplicas no Couchbase. Assim como as réplicas de documentos, as réplicas de índices de texto são dispostas automaticamente no cluster em uma distribuição equilibrada, dependendo do hardware disponível. A replicação de índices de texto completo serve principalmente para acelerar o failover. Ao contrário dos documentos, os índices de texto completo não correm o risco de perda de dados porque sempre podem ser recriados por meio da reindexação usando a definição de índice.
Ao criar ou atualizar um índice de texto completo, você tem a opção de especificar uma ou duas réplicas. Para fazer isso, navegue até a definição do índice, clique em Editare, em seguida, verifique Mostrar configurações avançadas.
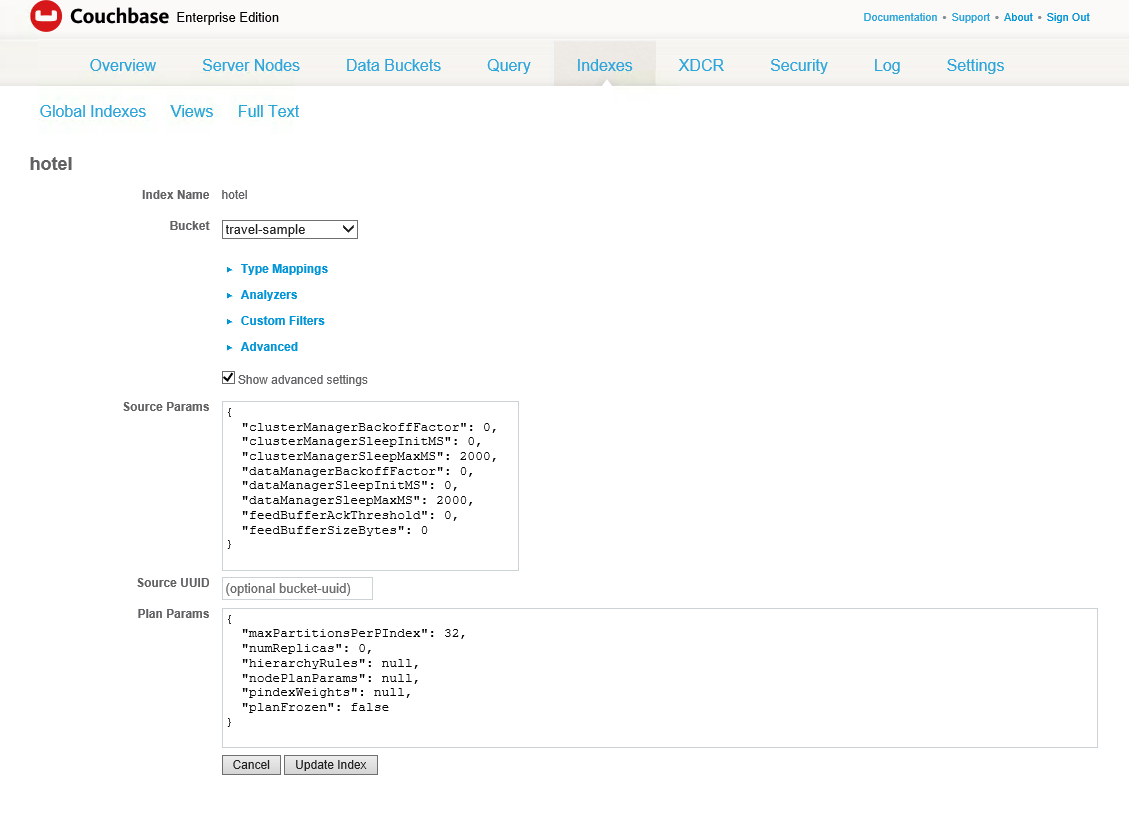
Em Parâmetros do plano, mudar numReplicas para 1 e, em seguida Índice de atualização.
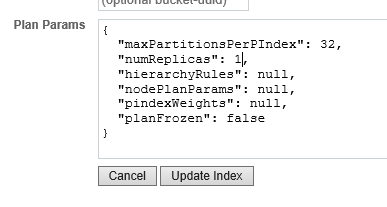
Assim que você salvar sua definição, o Couchbase Server começará a criar os índices de texto ativo e de réplica. Isso lhe dará outra cópia do índice. Novamente, você pode verificar isso examinando um dos diretórios data@fts e contando os pindexes. Cada nó deve ter agora 1/2 dos índices de pinos ativos e 1/2 dos índices de pinos de réplica.
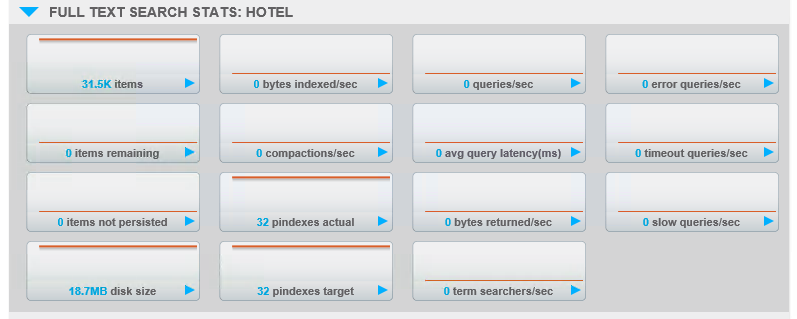
Você também pode ver isso clicando no ícone Nós do servidor clicando em um dos servidores e, em seguida, expandindo "Estatísticas de pesquisa de texto completo" para o índice que você criou. Você verá as estatísticas de pindexes reais (quantos existem) e pindexes alvo (quantas deveriam existir, dado o número de réplicas que você solicitou).

Failing Over
Agora, faça o failover de um nó. Se você pesquisar agora, obterá resultados parciais, ou seja, obterá resultados de pesquisa dos pindexes restantes. Isso foi projetado, pois alguns aplicativos podem optar por continuar com resultados parciais em vez de gerar um erro. Afinal, com um conjunto de dados grande o suficiente, os usuários podem nem perceber a falta de documentos.
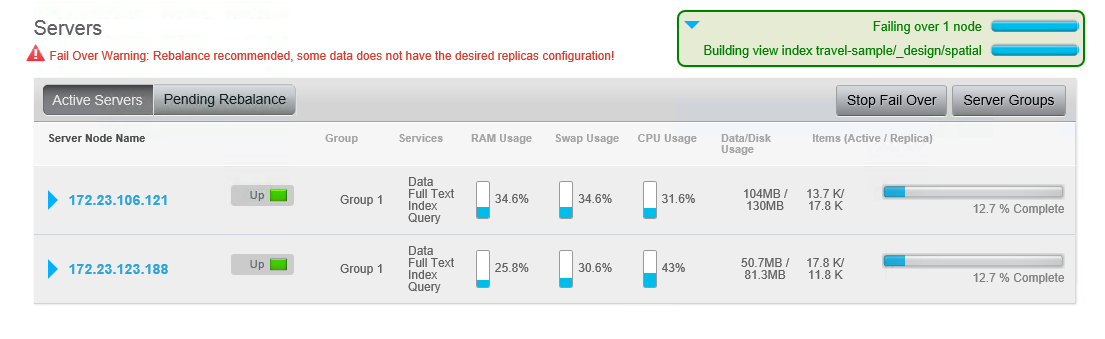
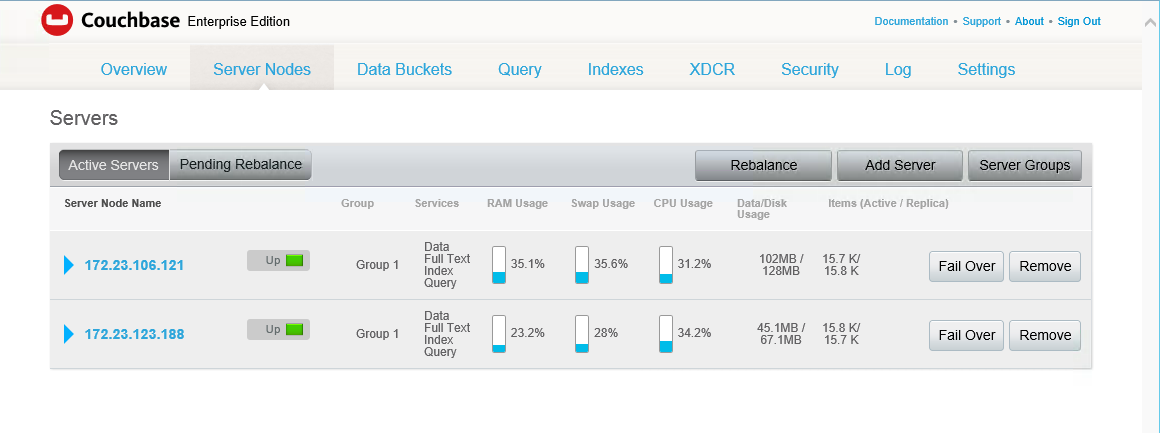
Agora, faça o rebalanceamento do nó. O reequilíbrio com réplicas é bastante rápido (se você não tiver excluído as exibições de amostra de viagem anteriormente, o failover levará muito mais tempo).
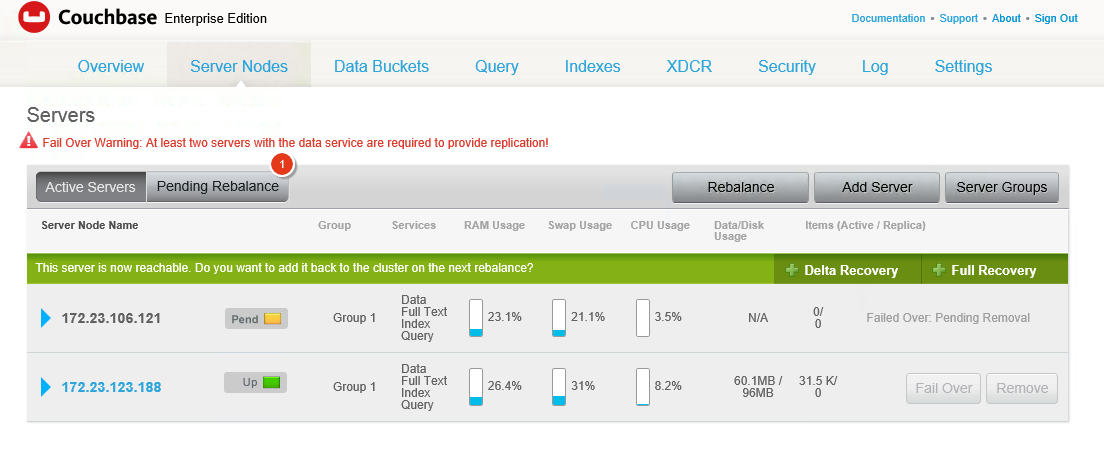
Quando você aciona o rebalanceamento, o outro nó assume o controle rapidamente, ativando as réplicas - tanto as réplicas de documentos quanto as réplicas de pindex. Essa promoção é instantânea. Se a indexação estiver em andamento, seja porque o índice não está totalmente atualizado ou porque estão ocorrendo mutações de documentos, os índices de texto completo podem levar mais tempo para serem criados. À medida que os vBuckets se movem, os nós que executam o serviço FTS reconectam seus fluxos de DCP para onde quer que os vBuckets tenham terminado no rebalanceamento.
Você deverá ver algo parecido com isto quando o rebalanceamento for concluído. Agora não temos réplicas e voltamos ao número de pindexes que tínhamos no início:
Failing over sem réplicas
Você deve estar se perguntando o que aconteceria se fizesse o experimento acima sem ter criado nenhuma réplica de índice de texto completo primeiro. Isso também funciona, e vale a pena fazer isso pelo menos uma vez para ver o que acontece. Você não terá primárias para alguns de seus pindexes - exatamente a metade nesse caso. Tudo bem - como mencionei acima, você não terá perda de dados, pois os pindexes ausentes podem ser recriados reindexando os documentos usando as definições de índice originais. Você obterá resultados parciais e também por um período de tempo mais longo. Isso ocorre porque, quando você faz um rebalanceamento, os pindexes ausentes precisam começar do zero e não estarão tão atualizados quanto estariam se houvesse réplicas de pindex disponíveis.
Experimente
Os índices de texto completo distribuídos são um dos meus recursos favoritos desta versão. Definitivamente, eles levam mais tempo para serem explicados do que para serem usados! Convidamos você a experimentá-los e nos dizer o que achou. Boa pesquisa!