Transações ACID são essenciais quando você tem requisitos rigorosos de consistência de dados em seu aplicativo. Os custos de execução de transações em sistemas distribuídos podem criar rapidamente gargalos em escala. Neste artigo, apresentaremos uma visão geral de alguns dos desafios enfrentados pelos bancos de dados NoSQL e NewSQL. Em seguida, vamos nos aprofundar em como o Couchbase implementou um modelo de transação distribuída escalável sem coordenação central e sem ponto único de falha. Além disso, também darei uma breve visão geral de como é o suporte para transações no N1QL no Couchbase 7.0.
Alguns detalhes menores foram omitidos por uma questão de simplicidade.
Transações relacionais vs. NewSQL vs. NoSQL
Antes de começar a explicar como o Couchbase implementou o suporte a transações, preciso primeiro explicar as características inerentes à atomicidade em bancos de dados relacionais e NoSQL (usando modelos de dados semiestruturados como JSON):
Atomicidade em RDBMS
Digamos que você precise salvar um novo usuário no banco de dados. Naturalmente, como o banco de dados tem muitas outras tabelas associadas a ele, a inserção de um usuário também exigirá inserções em muitas outras tabelas:
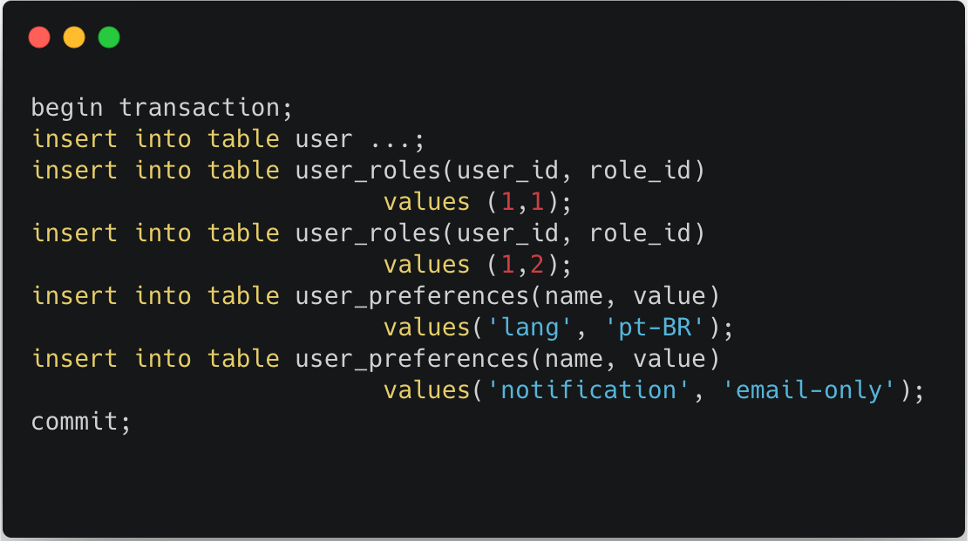
Como o modelo relacional o obriga a armazenar tudo em "caixas" e a dividir os dados em partes pequenas, a adição de um novo usuário deve sempre ser executada dentro de um contexto transacional. Caso contrário, se uma de suas inserções falhar, o usuário acabará sendo salvo pela metade. Observe como um RDBMS depende muito de transações, pois os aplicativos são muito mais complexos do que quando o modelo relacional foi originalmente projetado nos anos setenta.
Felizmente, como esses bancos de dados são projetados para serem executados em um único nó, é possível usar um coordenador de transações central para confirmar os dados de uma só vez sem nenhum impacto no desempenho.
Atomicidade no NewSQL
No lado do NewSQL (relacional distribuído), as coisas são um pouco mais complicadas. Como a maioria desses bancos de dados reutiliza o modelo relacional, os dados de sua entidade (ou raiz agregada) tende a se espalhar por vários nós.
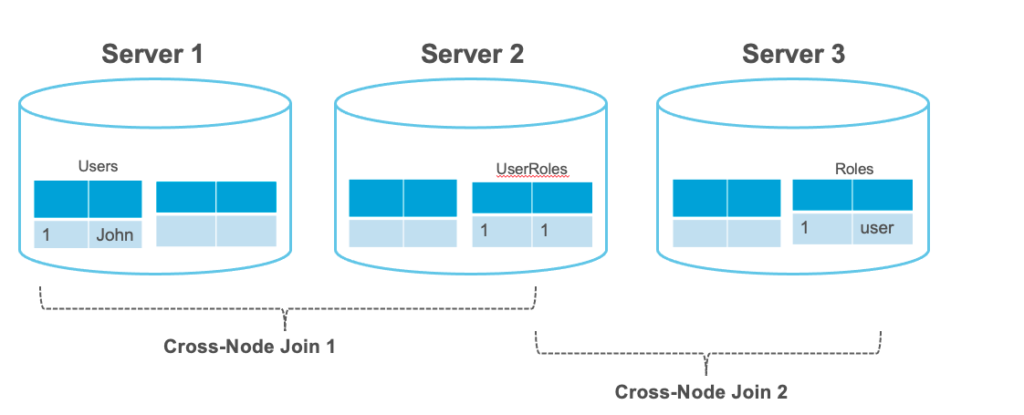
Na imagem acima, se precisarmos carregar o usuário na memória, precisaremos primeiro obter o usuário do Servidor 1, depois carregar a associação entre usuários e funções no Servidor 2 e, por fim, carregar a função de destino do Servidor 3. Essa operação simples exige que os dados viajem pelo menos duas vezes pela rede, o que acabará limitando o desempenho da leitura. Em um cenário do mundo real, um usuário tem muito mais tabelas associadas a ele. É por isso que o relacional distribuído ainda não é prático quando você precisa ler/gravar o mais rápido possível.
Você pode tentar minimizar os problemas acima limitando o tamanho do cluster, confiando muito nos índices para rastrear todos os relacionamentos ou usando algumas técnicas de sharding para manter todos os dados relacionados no mesmo nó (o que é difícil de implementar na prática). As duas últimas abordagens, mesmo quando bem implementadas, consumirão recursos significativos do banco de dados para serem gerenciadas adequadamente.
As transações ACID em bancos de dados NewSQL exigem mais coordenação do que em NoSQL, pois os dados relacionados a uma entidade são divididos em várias tabelas que podem estar em nós diferentes. O modelo relacional, como usamos atualmente, exige transações para a maioria das gravações, atualizações e exclusões em cascata. A coordenação extra que a arquitetura NewSQL exige tem o custo de reduzir a taxa de transferência para aplicativos que exigem operações de baixa latência.
Atomicidade em bancos de dados de documentos
O uso de dados semiestruturados, como o JSON, pode reduzir drasticamente o número de "junções entre nós", proporcionando, portanto, melhor desempenho de leitura/gravação sem a necessidade de depender muito da indexação. Esse foi um dos principais insights do Papel Dynamo (publicado pela primeira vez há cerca de 13 anos), que foi o para criar os bancos de dados NoSQL como os conhecemos hoje.
Outra característica interessante de um modelo de dados semiestruturado é que ele é menos transacional, pois é possível encaixar todos os dados do usuário em um único documento:
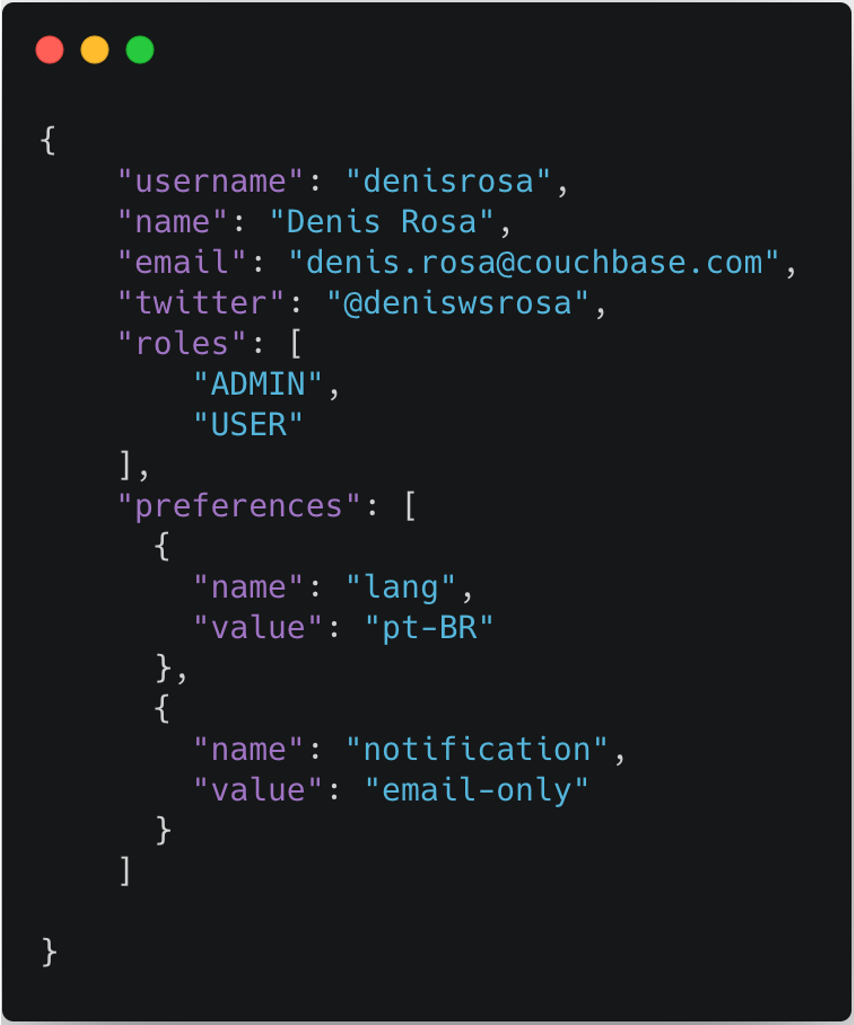
Como você pode ver na imagem acima, as preferências e funções do usuário podem caber facilmente em um "Documento do usuário", portanto, não há necessidade de uma transação para inserir ou atualizar um usuário, pois a operação é atômica. Inserimos o documento ou a operação inteira falha. O mesmo é válido para muitos outros casos de uso comuns: carrinhos de compras, produtos, estruturas de árvore e raízes agregadas em geral.
Na maioria dos aplicativos que usam bancos de dados de documentos, 90% das operações transacionais se enquadram nessa categoria de documento único. Mas... e os outros 10%? Bem, para essas, precisaremos de suporte a transações com vários documentos, que foi adicionado ao Couchbase desde a versão 6.5 e é o foco principal deste artigo.
Aqui está uma apresentação sobre transações que foi feita no Couchbase Connect 2020. Matt Ingenthron explica quando e por que você pode precisar de transações ACID com vários documentos:
Assista a versão completa em https://www.youtube.com/watch?v=2fsZVe2cT3M&ab_channel=Couchbase
Transcrição do vídeo
Clique para ler a transcrição completa.
Vamos falar sobre como isso é aplicado a um exemplo fictício, mas talvez um pouco realista, de um modelo de documento para um sistema Couchbase. Então, levantamos algum dinheiro e vamos construir um jogo de RPG on-line para múltiplos jogadores (um MMORPG), com jogadores e monstros. Portanto, precisamos de um modelo de dados.
Teremos jogadores que lutarão contra monstros e, com base nessa luta, eles ganharão ou perderão. Se vencerem, receberão uma arma, se perderem, perderão alguns pontos de vida para que ninguém possa morrer. Você sempre pode voltar à vida, você sempre pode encontrar outro dia. Mas seus jogadores lutam contra monstros, e nós construímos nossa versão 1.0. Ótimo! Certo, conseguimos nosso financiamento, construímos nossa versão 1.0.
O problema é que esquecemos de fazer a parte do multijogador em massa. Não há jogo colaborativo. Não posso ter vários jogadores lutando contra o mesmo monstro. Portanto, preciso consertar isso, certo? Então, vamos lançar uma nova versão. Assim, os jogadores continuarão lutando contra monstros e ganhando armas.
Então, lançamos nossa versão 2.0 e, na versão 2.0, os jogadores podem lutar contra monstros juntos. Posso me coordenar com meus amigos, encontrar um monstro e matar esse monstro.
Mas deixamos um bug lá. É possível que vários jogadores deem o golpe mortal e o motivo pelo qual isso é um problema é que os jogadores do jogo descobriram isso. Em vez de lutar contra um monstro juntos até a morte, o que eles fazem é, nesse mundo multijogador em massa, lutar até quase a morte e, em seguida, um grupo de jogadores se reúne e todos dão o golpe mortal ou muitos dão o golpe mortal ao mesmo tempo.
O problema é que eles ganham itens, ganham vários itens e, como os itens têm raridade, e se você não tiver uma certa quantidade de raridade para um item, a jogabilidade não é muito interessante. Esse bug permitiu a existência de muitos itens no mundo, e os jogadores estão apenas gastando tempo hackeando o jogo, e então ficam entediados e vão embora. Precisamos manter a jogabilidade interessante.
Então, vamos pensar sobre isso. Como podemos consertar isso? Acho que o que precisaremos fazer é provavelmente introduzir uma correção. Ainda permitiremos que jogadores e monstros, vários jogadores lutem contra um monstro. Mas o que vamos fazer é usar um dos truques que temos, vamos usar Couchbase CAS Operações.
Com o Operação CAS O que acontece é que agora vários jogadores estão lutando contra esse monstro, diminuindo seus pontos de vida até que ele chegue a zero. Mas somente um desses jogadores conseguirá dar o golpe mortal no monstro e ganhar um item.
Portanto, se dois jogadores estiverem tentando dar o golpe fatal, o aplicativo O servidor que está lidando com a solicitação tentará modificar o documento. Ele precisa pegar um pequeno pedaço de informação opaca que chamamos de CAS (sigla em inglês para Check And Set)Isso significa que, se o opaco não corresponder, os documentos já foram modificados e, portanto, será necessário repetir a operação. No cenário em que dois atores do sistema estão tentando obter esse documento ao mesmo tempo, o que queremos é que um seja bem-sucedido e o outro falhe, e o CAS nos dará isso de forma muito eficiente.
Retiramos esse truque, introduzimos as operações CAS, o bug foi corrigido, a jogabilidade ficou muito mais interessante e a versão 2.1 se saiu muito bem, o que é ótimo.
Então, agora vamos tentar um , uh, queremos seguir em frente, queremos tornar as coisas mais interessantes. Imagine agora que eu introduzo outro recurso: "Os jogadores ainda podem lutar contra monstros juntos, mas precisam fazer isso fora da cidade. Portanto, você precisa estar fora da muralha da cidade, onde os jogadores estão, e se você entrar na cidade, fará trocas em um ambiente bizarro"
Isso funciona muito bem no início, mas depois os jogadores descobrem algo.
Então, imagine o jogador1, preciso recuperar o documento do jogador1. Em seguida, preciso recuperar o documento do jogador2. Em seguida, preciso mover a espada do jogador1 para o jogador2, o que é muito fácil de fazer na lógica do aplicativo, e depois armazeno essa alteração de volta no sistema com a operação CAS e, em seguida, armazeno a outra alteração de volta, certo? Parece que vai ser ótimo. Só que há um erro.
O problema aqui é que meus jogadores podem iniciar uma negociação e depois se desconectar, e os itens que poderíamos querer que fossem raros não serão raros. Eles podem ser duplicados dentro do sistema.
Em jogos de RPG on-line para múltiplos jogadores, isso é chamado de Dup Bug. Se você for ao Google e procurar por um "Dup Bug", encontrará muitos cenários.
Aqui está um de apenas algumas semanas atrás, em que Final Fantasy Crystal Chronicles no Switch teve de ser corrigido por causa de um bug Dup. E houve um que ocorreu alguns dias antes, este é de um blog em que um blogueiro de jogos mostrava às pessoas como usar esse bug Dup para recuperar... para obter itens adicionais no jogo.
Portanto, precisamos corrigir esse bug. Como vamos fazer isso? Bem, então vamos acessar nosso conjunto de truques do Couchbase.
Vamos apresentar as transações do Couchbase. A jogabilidade é quase exatamente a mesma. Mas o que vamos fazer com as transações do Couchbase? Portanto, este é o único slide em que falarei um pouco sobre o código.
Transações ACID distribuídas de vários documentos no Couchbase
Agora que você já sabe como as transações se comportam em diferentes modelos de dados, é hora de se aprofundar em como as implementamos no Couchbase e o que levou às nossas escolhas de design. Primeiro, vamos examinar a sintaxe:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
transactions.run((ctx) -> { // get the account documents for userA and UserB TransactionJsonDocument userA = ctx.getOrError(collection, "userA"); JsonObject userAContent = userA.contentAsObject(); int userABalance = userAContent.getInt("account_balance"); TransactionJsonDocument userB = ctx.getOrError(collection, "Beth"); JsonObject userBContent = userB.contentAsObject(); int userBBalance = userBContent.getInt("account_balance"); // if userB has sufficient funds, make the transfer if (userBBalance > transferAmount) { userAContent.put("account_balance", userABalance + transferAmount); ctx.replace(userA, userAContent); userBContent.put("account_balance", userBBalance - transferAmount); ctx.replace(userB, userBContent); } else throw new InsufficientFunds(); }); |
O exemplo em Java acima é o exemplo clássico de como transferir dinheiro entre dois clientes. Observe que decidimos usar um função lambda para expressar a transação. O tratamento adequado de erros pode ser um desafio nesse cenário, e envolver sua transação com uma função anônima permite que o Couchbase Java SDK faça esse trabalho para você (ou seja, tente novamente se algo falhar).
Quando lançamos o suporte a transações pela primeira vez, estávamos tentando evitar a verbosidade. Esta era a aparência da sintaxe de transação de um concorrente:
![]()
Ultimamente, parece que a manipulação de transações dentro de funções lambda está se tornando a norma para os bancos de dados NoSQL.
Para aqueles que esperavam que fosse semelhante à sintaxe relacional para transações (por exemplo, comandos SQL BEGIN/COMMIT/ROLLBACK), continue lendo: você também pode executar transações por meio do N1QL! Agora, vamos tentar entender o que está acontecendo nos bastidores.
Revisão da arquitetura do Couchbase
Para aqueles que não estão familiarizados com a arquitetura do Couchbase, preciso explicar rapidamente quatro conceitos importantes antes de prosseguir:
- O Couchbase é altamente dimensionável, você pode facilmente ir de 1 a 100 nós em um único cluster com o mínimo de esforço
- Os documentos JSON têm um espaço "Meta" chamado xAttr onde você pode armazenar metadados sobre seu documento.
- Dentro de cada Bucket (semelhante a um esquema em RDBMS), o Couchbase distribuiu automaticamente os dados em 1024 fragmentos chamados vBuckets. A fragmentação é totalmente transparente para o desenvolvedor, e nós também cuidamos da estratégia de fragmentação. Nosso algoritmo de fragmentação (CRC32) garante essencialmente que os documentos serão distribuídos de forma homogênea entre esses vBuckets e que não será necessária nenhuma fragmentação. Os vBuckets são distribuídos igualmente entre os nós de seu cluster (por exemplo, se você tiver um cluster de 4 nós, cada nó conterá 256 vBuckets).
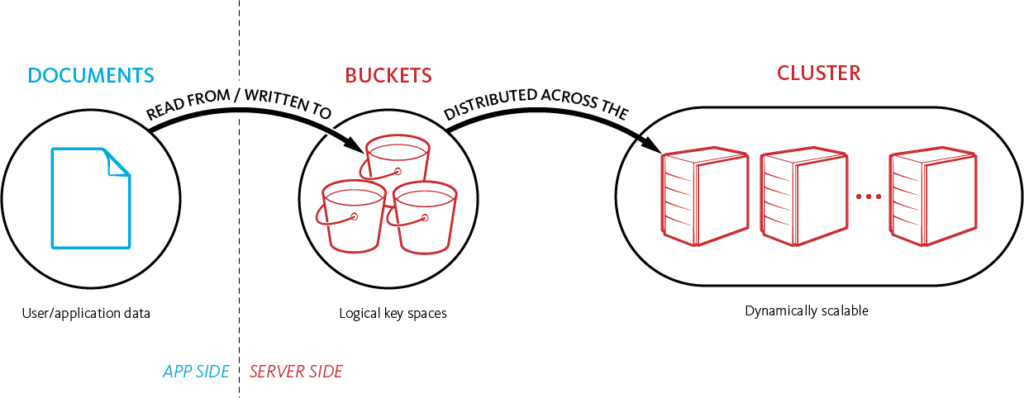
- O SDK do cliente armazena uma cópia do mapa do cluster, que é um hashmap dos vBuckets e do nó responsável por eles. Ao fazer o hash da chave do documento, o SDK pode descobrir em qual vBucket o documento deve estar localizado. E, graças ao mapa do cluster, ele pode se comunicar diretamente com o nó responsável pelo documento durante as operações de salvar/excluir/atualizar.
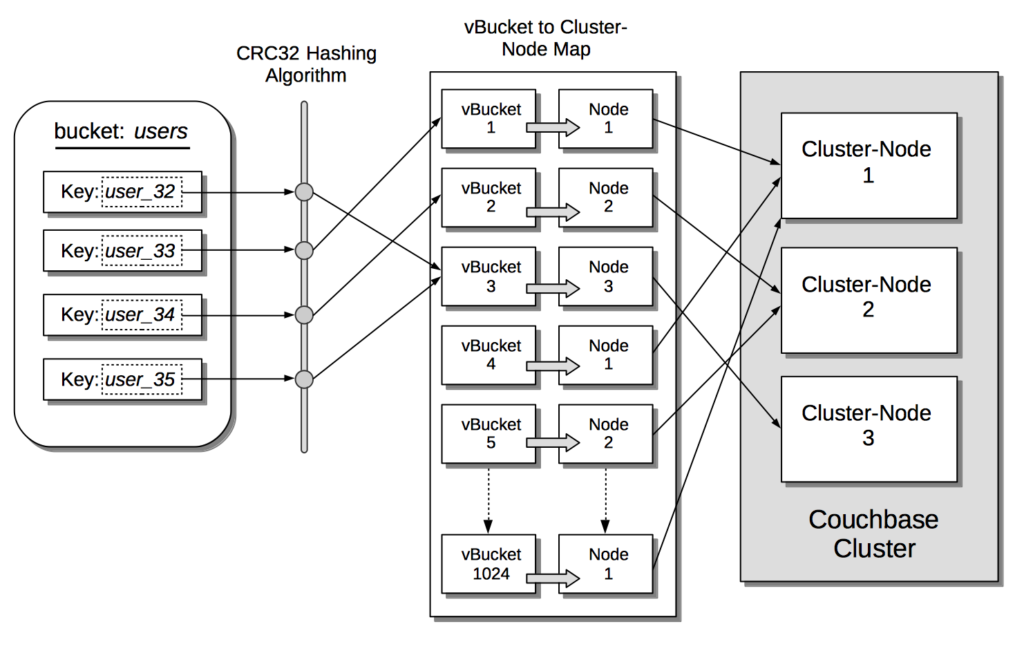
As escolhas de design acima permitem que o Couchbase tenha uma arquitetura sem mestre (também chamada de mestre/mestre) em vez da tradicional mestre/escravo usada em outros bancos de dados NoSQL. Há várias vantagens nesse tipo de arquitetura, mas as mais relevantes para nós agora são as seguintes:
- O SDK economiza "um salto de rede" durante as operações de inserção/atualização/exclusão, pois sabe onde um determinado documento está localizado (na arquitetura mestre/escravo, você precisa perguntar ao mestre onde está o documento).
- O banco de dados em si não tem um coordenador central e, portanto, não tem um ponto único de falha. Na prática, o cliente atua indiretamente como um coordenador leve, pois sabe exatamente com qual nó do cluster deve se comunicar.
Transações distribuídas sem um coordenador central
Na arquitetura do Couchbase, cada cliente é responsável pela coordenação de suas próprias transações. Naturalmente, tudo é feito por baixo do pano no nível do SDK. Para simplificar, se você tiver 100 instâncias do seu aplicativo executando transações, terá potencialmente cerca de 100 coordenadores. Esses coordenadores não adicionam quase nenhuma sobrecarga ao seu aplicativo, e você logo entenderá o porquê.
Se reutilizarmos o exemplo de transferência de dinheiro mostrado em nosso exemplo de código e presumirmos que os dois documentos envolvidos nessa transação residem em dois nós diferentes, a partir de uma visão de 1.000 pés, a transação seguirá estas etapas:
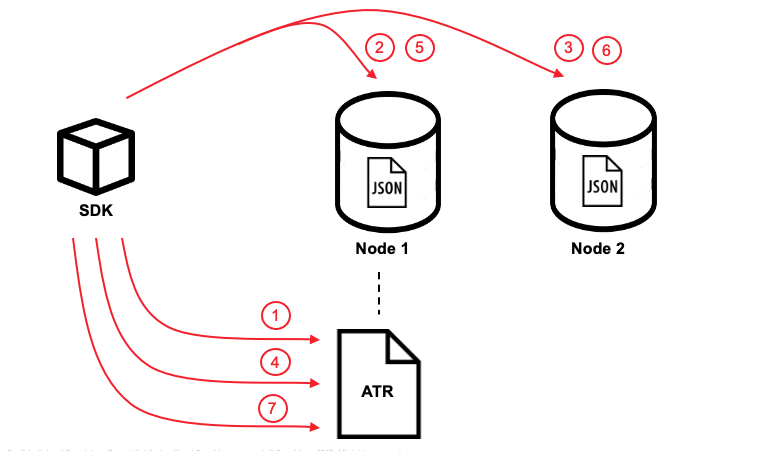
- Cada vBucket tem um único documento responsável pelo registro de transações chamado Registro de transação ativa (ATR). O ATR pode ser facilmente identificado pelo _txn:atr- prefixo id. Antes da primeira mutação de documento ( ctx.replace(userA, userAContent) nesse caso), uma nova entrada é adicionada no ATR no mesmo vBucket com o ID da transação e o status "Pending". Apenas um ATR é usado por transação.
- O ID da transação e o conteúdo da primeira mutação, ctx.replace(userA, userAContent)é encenado no xAttrs do primeiro documento ("userA").
- O ID da transação e o conteúdo da segunda mutação, ctx.replace(userB, userBContent)é encenado no xAttrs do segundo documento "userB".
- A transação é marcada como "Comprometida" no ATR. Também aproveitamos essa chamada para atualizar a lista de IDs de documentos envolvidos na transação.
- O documento "userA" não foi preparado (removido de xAttrs e substitui o corpo do documento)
- O documento "userB" não foi preparado (removido de xAttrs e substitui o corpo do documento)
- A transação é marcada como "Concluída" e removida do ATR
Observe que essa implementação não é limitada por escopos, coleções, ou shards (vBuckets). Na verdade, você pode até mesmo executar transações em vários buckets. Desde que você tenha permissões suficientes, qualquer documento dentro do seu cluster pode fazer parte de uma transação.
A esta altura, presumo que você tenha muitas perguntas sobre todos os possíveis cenários de falha. Vamos tentar abordar os tópicos mais importantes aqui. Sinta-se à vontade para deixar comentários e tentarei atualizar o artigo de acordo.
Manuseio do isolamento - visão atômica monotônica
Jepsen tem um gráfico brilhante que explica os modelos de consistência mais importantes para bancos de dados:
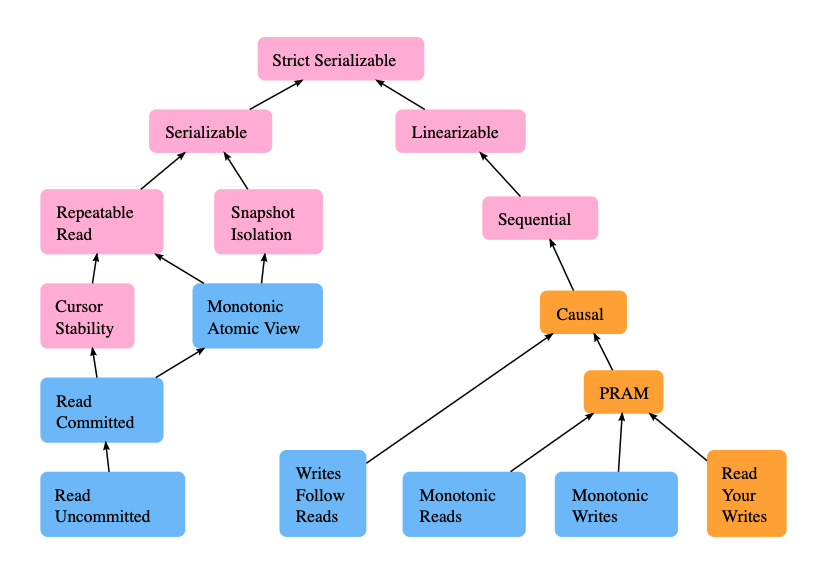
O Couchbase tem suporte para o Ler comprometido/Visão atômica monotônica" modelos de consistência. Mas até que ponto isso é bom? Bom, Ler comprometido é a opção padrão no Postgres, MySQL, MariaDB e em muitos outros bancos de dados existentes; se você nunca alterou essa opção, é isso que está usando no momento.
Ler comprometido garante que seu aplicativo não possa ler dados não confirmados, que é o que você provavelmente espera do seu banco de dados, mas a parte interessante aqui é como o processo de confirmação realmente acontece. Em bancos de dados relacionais, muitas vezes, há uma coordenação entre as novas versões das linhas alteradas em uma transação para assumir as versões anteriores, todas ao mesmo tempo. Isso é comumente chamado de Compromisso de ponto de gravação. Para que isso aconteça, Controle de simultaneidade multiversão (MVCC) é necessário. Isso é problemático por causa de toda a bagagem que vem com ele, sem mencionar o quão caro fica (em termos de desempenho) para ser implementado em um banco de dados distribuído ACID em que leituras/escritas rápidas são fundamentais.
Outra desvantagem dos commits de ponto de gravação é que você pode gastar um tempo valioso sincronizando seu commit, mas ... nenhum outro thread o lê logo em seguida, desperdiçando todo o esforço gasto com a sincronização. Isso acontece quando Visão atômica monotônica (MAV) entra em ação. Ele foi descrito pela primeira vez no Transações altamente disponíveis: Virtudes e limitações e teve uma grande influência em nosso design.
Com o MAV, podemos fornecer um commit atômico no ponto de leitura, o que leva a uma melhoria significativa no desempenho. Vamos ver como isso funciona na prática:
Leituras repetíveis e visualizações atômicas monotônicas
Em nosso exemplo de transação, há uma fração de tempo após Etapa 4 em que definimos a transação no ATR como "Confirmada", mas ainda não removemos os dados dos documentos envolvidos na transação. Então, o que acontecerá se outro cliente tentar ler os dados durante esse intervalo?
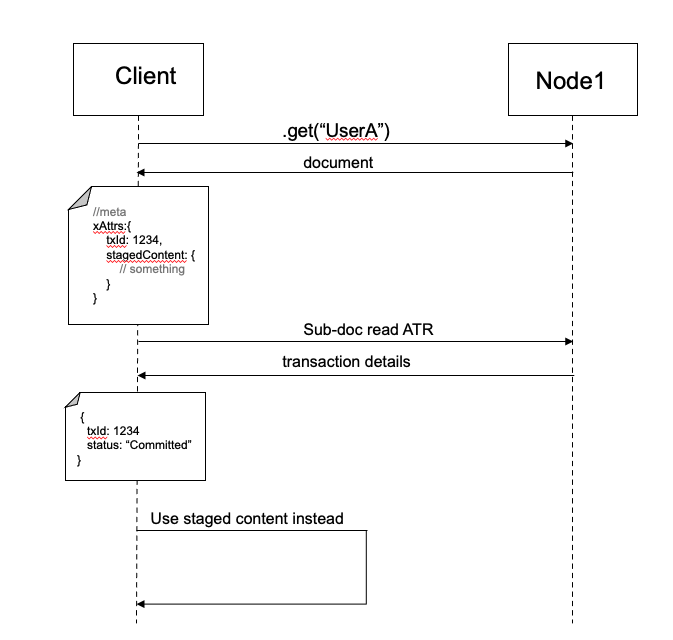
Internamente, se por acaso o SDK encontrar um documento que contenha conteúdo preparado, ele também lerá o ATR para obter o estado da transação. Se o estado for "Confirmado", ele retornará a versão preparada. Bum! Não há necessidade de sincronizar gravações se você puder simplesmente resolver o problema QUANDO ele ocorrer no momento da leitura.
Durabilidade em um banco de dados distribuído
Uma das tarefas mais importantes de um banco de dados é garantir que o que foi escrito permaneça escrito. Mesmo no caso de falha de um nó, nenhum dado deve ser perdido. Isso é obtido no Couchbase por meio de dois recursos: Replicas de Bucket e Durabilidade no SDK.
Durante a criação do seu bucket, você pode configurar quantas réplicas (backups) de cada documento você deseja (dois é a opção mais comum). Essa opção permite que você perca um número N de nós sem que isso implique uma possível perda de dados.
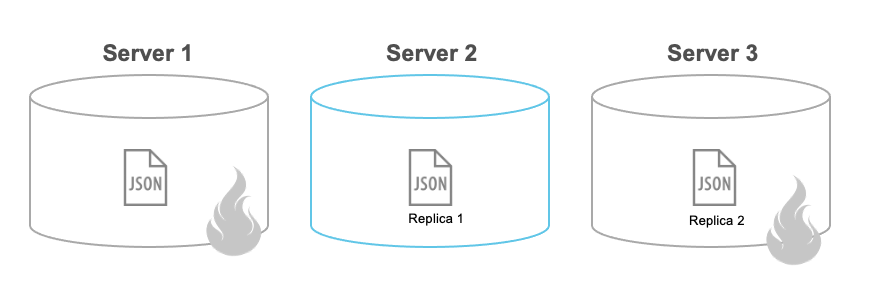
O Couchbase é configurado por padrão para sempre adotar a abordagem mais rápida, portanto, assim que os dados chegarem ao servidor, uma confirmação será enviada de volta ao cliente informando que a gravação foi bem-sucedida e que toda a replicação de dados será tratada de forma oculta. No entanto, se o servidor falhar antes de ter a chance de replicar os dados (estamos falando de microssegundos a alguns milissegundos, pois a replicação é feita de memória para memória), você poderá perder naturalmente a alteração. Isso pode ser bom para alguns dados de baixo valor, mas... ei! Isso viola totalmente a "durabilidade" do ACID. É por isso que permitimos que você especifique seu Requisitos de durabilidade:

O MAIORIA (opção padrão na biblioteca da transação) no código acima significa que a mutação deve ser replicada para (ou seja, mantida na memória alocada para o bucket) a maioria dos nós do Data Service. As outras opções são: majorityAndPersistActive, e persistToMajority. Favor consultar para a documentação oficial sobre requisitos de durabilidade para entender melhor como ele funciona. Esse recurso também pode ser usado fora de uma transação, caso você precise garantir de forma pessimista que um documento foi salvo.
O que acontece se algo falhar durante uma transação?
Você pode configurar o tempo que a transação deve durar antes de ser revertida. O valor padrão é 15 segundos. Dentro desse período, se houver problemas de concorrência ou de nó, usaremos uma combinação de espera e nova tentativa até que a transação atinja esse tempo.
Se o cliente que estiver gerenciando a transação se desconectar repentinamente, ele poderá deixar algum conteúdo preparado nos metadados do documento. No entanto, outros clientes que tentam modificar o mesmo documento podem reconhecer que o conteúdo preparado pode ser substituído, pois faz parte de uma transação que já expirou.
Além disso, a biblioteca de transações executará periodicamente limpezas para remover transações não ativas dos ATRs, a fim de mantê-los o menor possível.
Transações SQL distribuídas com N1QL
N1QL é uma linguagem de consulta que implementa a especificação SQL++, compatível com o SQL92, mas projetada para documentos JSON estruturados e flexíveis. Saiba mais sobre o assunto neste tutorial interativo sobre N1QL.
A solução de transação distribuída que discutimos até agora é excelente para transações no nível do aplicativo. Mas, às vezes, precisamos executar alterações de dados ad hoc. Ou, devido ao número de documentos envolvidos na operação, manipulá-los na memória do aplicativo torna-se uma operação cara (por exemplo, adicionar 10 créditos às contas de todos os usuários). No Couchbase Server 7.0, você pode executar transações por meio do N1QL com praticamente a mesma sintaxe SQL da maioria dos bancos de dados relacionais:
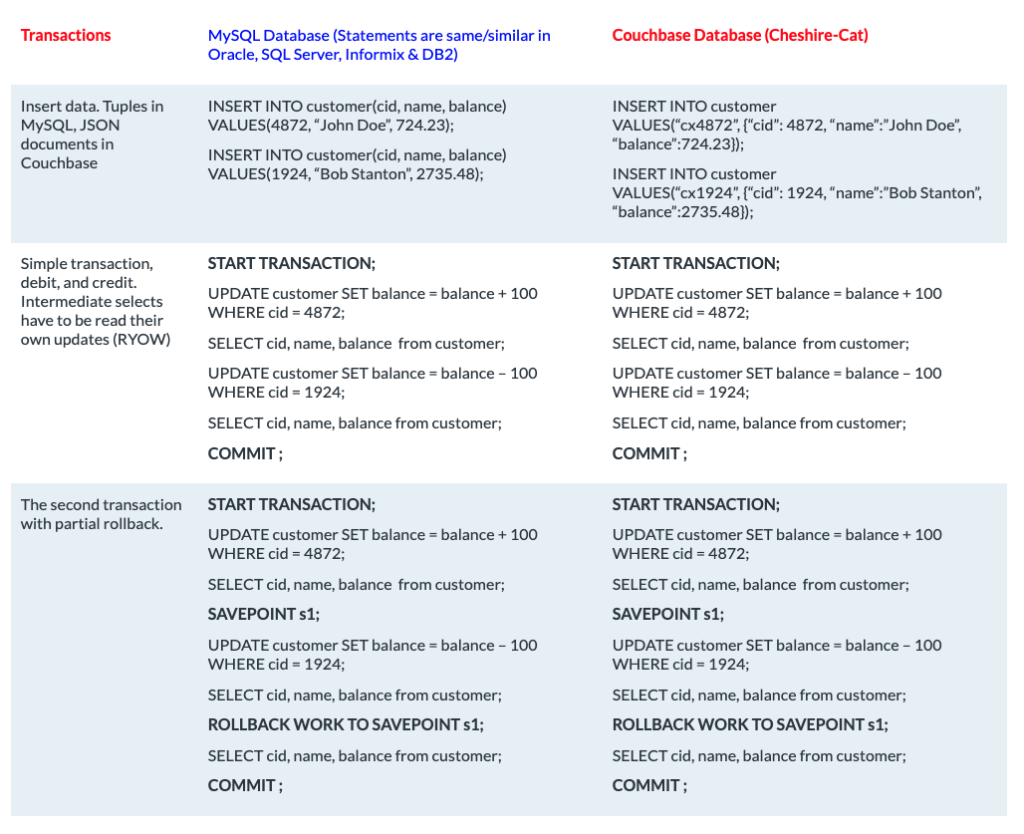
As transações N1QL já foram devidamente introduzidas em Transações do Couchbase com N1QL e "Casos de uso e práticas recomendadas para transações distribuídas por meio do N1QL"Por isso, não vou me aprofundar nesse tópico. Em uma visão de mil pés, a transação é gerenciada pelo serviço de consulta. Como o Couchbase é modular, você pode aumentar a taxa de transferência de transações aumentando ou diminuindo a escala dos nós que executam o serviço de consulta.
Você pode usar as transações N1QL e lambda juntas, mas é preferível usar apenas a biblioteca de transações sempre que possível
Conclusão: O melhor NoSQL para transações
O Couchbase já tinha suporte para operações atômicas de documento único e Bloqueio otimista e pessimista há muito tempo. No ano passado, introduzimos o suporte transacional rápido, independentemente de buckets, coleções, escopos ou shards. Com o Couchbase 7.0, você pode até usar a mesma sintaxe de transação relacional tradicional. A combinação de todos esses recursos torna o Couchbase, o melhor NoSQL para transações em escala.
Baixo custo - Pague pelo que usar
A sobrecarga total da transação é simplesmente o número de mutações de documentos + 3 (ATR marcado como Pendente, Confirmado e Concluído). Por exemplo, a execução do exemplo de transferência de dinheiro em um contexto transacional custará até 5 chamadas adicionais ao banco de dados.
A biblioteca de transações é uma camada sobre o SDK. Adicionamos suporte a transações com impacto zero sobre o desempenho (algo que outros jogadores não podem afirmar facilmente). Isso só foi possível graças à nossa sólida arquitetura.
Não há gerente central de transações ou coordenador central
Dada a arquitetura sem mestre do Couchbase e o fato de que os clientes são responsáveis por gerenciar suas próprias transações, nossa implementação não tem coordenação central nem ponto único de falha. Mesmo durante uma falha de nó, as transações que não estão tocando em documentos no servidor com falha ainda podem ser concluídas com êxito. Na verdade, com um tempo máximo de transação adequado, mesmo que você toque em documentos em um nó que está falhando, Failover de nó do Couchbase pode ser rápido o suficiente para isolar o servidor defeituoso e promover um novo nó antes que sua transação expire
Sem relógio global interno e sem MVCC
Algumas implementações de transações exigem o conceito de um relógio global, cuja manutenção pode ser cara sem hardware dedicado em um ambiente distribuído. Em alguns casos, ele pode até mesmo derrubar o banco de dados se a inclinação do relógio for superior a aproximadamente 250 milissegundos.
Com o MVCC (Multiversion Concurrency Control, controle de simultaneidade de multiversão) e relógios globais, é possível atingir níveis tecnicamente mais altos de consistência. Por outro lado, isso provavelmente afetará o desempenho geral do banco de dados. O Couchbase oferece suporte ao modelo de consistência Read Committed, que é o mesmo que os bancos de dados relacionais oferecem por padrão.
Flexibilidade
Você pode usar o opções de durabilidade dentro e fora de um contexto transacional, use bloqueio otimista e pessimista para evitar possíveis problemas de concorrência e usar transações no SDK e/ou via N1QL. Há muita flexibilidade para você criar qualquer tipo de aplicativo com base no Couchbase e ajustar o desempenho de acordo com suas necessidades comerciais.
Qual é o próximo passo?
Aqui estão alguns links para você saber mais sobre o que acabamos de discutir e para começar a usar o Couchbase:
| Saiba mais sobre transações | https://www.couchbase.com/transactions |
| Transações do Java SDK | https://docs.couchbase.com/java-sdk/current/howtos/distributed-acid-transactions-from-the-sdk.html |
| Transações do SDK do .NET | https://docs.couchbase.com/dotnet-sdk/current/howtos/distributed-acid-transactions-from-the-sdk.html |
| Transações do SDK do C++ | https://docs.couchbase.com/cxx-txns/current/distributed-acid-transactions-from-the-sdk.html |
| Transações N1QL | https://www.couchbase.com/blog/couchbase-transactions-with-n1ql/ |
| Baixar o Couchbase | https://www.couchbase.com/downloads |
| O que há de novo no Couchbase 7.0? | https://docs.couchbase.com/server/7.0/introduction/whats-new.html |
Ótima postagem!