O Couchbase Server 6.5 traz uma série de novos recursos [1...] para o principal banco de dados NoSQL. Uma das principais adições à linguagem de consulta N1QL é o suporte a funções de janela. Essas funções foram originalmente introduzidas no padrão SQL:2003 e oferecem uma maneira eficiente de responder a muitas consultas comerciais complexas. As funções Window foram discutidas anteriormente na série de postagens [2], [3], [4] e, nesta parte, vamos nos aprofundar em sua implementação no Couchbase Analytics.
O Serviço do Couchbase Analytics [5O Couchbase® foi projetado para lidar com consultas ad-hoc complexas na plataforma de dados do Couchbase. Seu principal componente é o mecanismo de consulta MPP, que é executado em um conjunto separado de nós no cluster para garantir o isolamento da carga de trabalho dos nós de dados operacionais. Os dados são ingeridos no Analytics usando o Protocolo de alteração de DCP [6] e é particionado por hash entre todos os nós do Analytics disponíveis. O processador de consultas MPP divide uma única consulta em subtarefas e as programa para serem executadas em paralelo em todos os nós, reparticionando os dados, se necessário. Mais informações sobre a arquitetura geral do serviço estão disponíveis em nosso recente Papel do VLDB 2019 [7] e em nosso canal de vídeo [8].
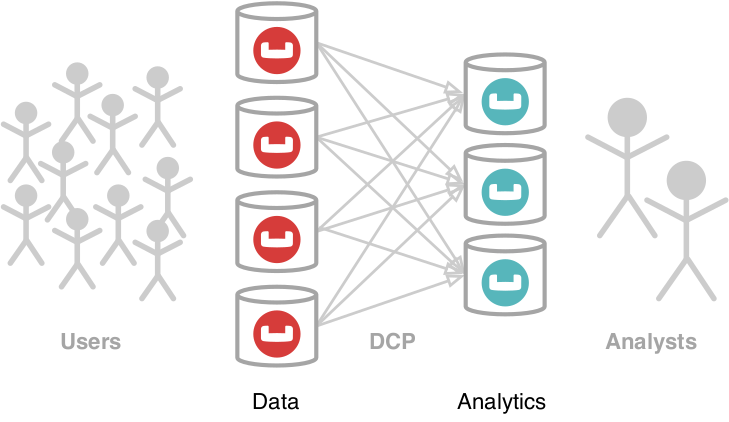
Figura 1: Serviço de análise do Couchbase
As funções de janela também são avaliadas de forma distribuída e paralela à partição pelo mecanismo de consulta do Analytics. O compilador de consultas cria um plano de execução que contém vários operadores trabalhando juntos para computar o resultado da chamada da função de janela. Esse plano de execução é então enviado a todos os nós do Analytics no cluster, onde cada operador trabalha em uma partição dos dados de entrada. O mecanismo de execução coordena a execução do operador e fornece o resultado da consulta ao cliente. Por exemplo, considere a seguinte consulta que classifica os funcionários de cada departamento de acordo com seus salários.
|
1 2 3 4 5 |
SELECT RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank, employee_id, department_id, salary FROM employee |
O processador de consultas avalia essa função em três etapas, conforme ilustrado na Figura 2.
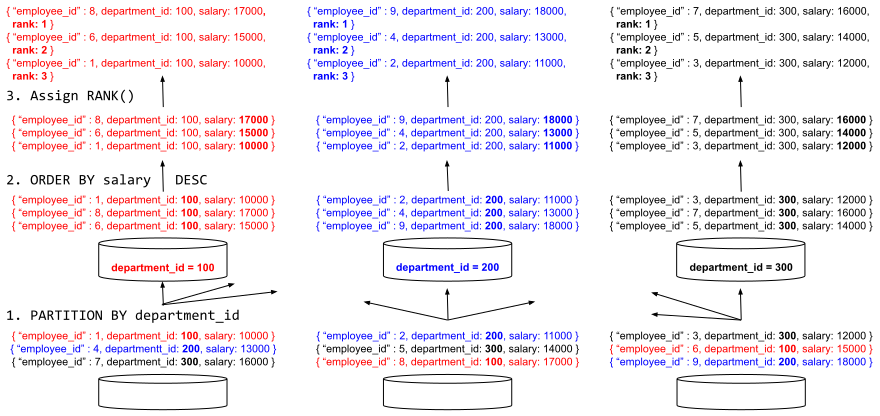
Figura 2: Execução de consulta paralela e distribuída de funções de janela
- Depois que os dados são selecionados do conjunto de dados de funcionários, eles são reparticionados de acordo com a subcláusula PARTITION BY da cláusula OVER. O layout de dados inicial pode ter cada um dos registros de departamento espalhados por diferentes partições de armazenamento em vários nós do Analytics. Após a etapa de reparticionamento, todos os registros de funcionários de um único departamento chegam à mesma partição de computação. A etapa de reparticionamento é executada em paralelo em todos os nós/partições do cluster. Na configuração mais comum do Analytics, há uma relação de um para um entre o número de partições de dados e o número de núcleos de CPU disponíveis no cluster.
- Os registros de cada departamento são classificados de acordo com a subcláusula ORDER BY da cláusula OVER. Quando os registros de cada departamento chegam às partições de computação correspondentes, o processador de consultas começa a classificar os dados. Essa etapa de classificação também é executada em paralelo em todos os nós do Analytics.
- A função RANK() é então computada em registros classificados dentro de cada departamento. Essa função específica só precisa examinar o registro atual e compará-lo com o anterior, portanto, pode ser avaliada de forma contínua sem exigir materialização de dados adicional.
A execução dessas etapas em paralelo em todos os nós disponíveis permite que o Analytics utilize todos os recursos computacionais do cluster. Isso permite que o Analytics obtenha escalabilidade linear à medida que mais nós são adicionados para atender às metas de desempenho necessárias.
Vamos ver como os estágios acima podem ser identificados em um plano de execução de consulta. O recurso Analytics explain plan foi descrito em um post anterior [9], portanto, aqui nos concentramos apenas no fragmento do plano relacionado à avaliação da função de janela. (Lembre-se de que os planos de consulta do Analytics devem ser lidos de baixo para cima).
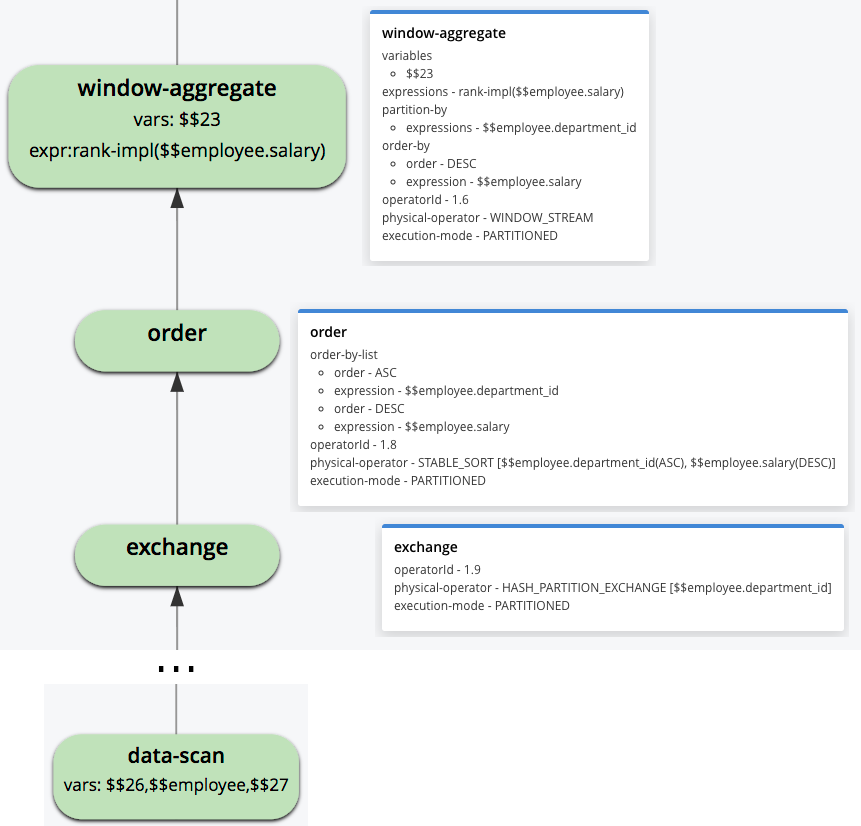
Figura 3: Fragmento do plano de execução da consulta
Os dados são lidos do conjunto de dados do funcionário pelo operador "data-scan" e são passados para o operador "exchange", que é responsável pelo reparticionamento dos dados. O campo de repartição é "department_id", conforme solicitado pela subcláusula PARTITION BY. Em seguida, o operador "order" classifica os dados de acordo com a subcláusula ORDER BY. Por fim, o operador "window-aggregate" calcula a função RANK(). Observe como o valor de "physical-operator" para esse operador está definido como "WINDOW_STREAM", o que significa que o operador funciona em um modo de fluxo contínuo e não exige nenhuma materialização de dados adicional. O campo "execution-mode" está definido como "PARTITIONED" para todos os operadores, de modo que todos eles serão executados em todas as partições de computação disponíveis no cluster.
A avaliação de algumas funções de janela pode exigir informações relativas a uma partição lógica inteira (seu número total de tuplas para as funções NTILE() e PERCENTILE_RANK(), por exemplo) ou várias iterações em toda a partição (ao calcular quadros de janela para funções agregadas). Essas funções são processadas por operadores de janela sem fluxo contínuo. Um operador de janela sem fluxo é identificado pelo valor "physical-operator" de "WINDOW" no plano de execução da consulta. O operador materializa uma partição lógica de cada vez e, em seguida, inicia o cálculo da função de janela para cada tupla nessa partição. Para lidar com quantidades arbitrárias de dados de entrada, o operador segue o modelo de gerenciamento de memória do mecanismo de execução do Analytics. O planejador de consultas atribui um orçamento de memória a cada operador. Esse orçamento não pode ser excedido durante a execução da consulta. Os dados operacionais que ultrapassam o orçamento são transferidos para o disco por cada operador e lidos de volta mais tarde, quando a memória estiver disponível. Uma consulta geralmente consiste em vários operadores e, portanto, tem um orçamento de memória global que não pode ser excedido no tempo de execução. O processador de consultas do Analytics implementa o controle de carga baseado em recursos para consultas de entrada, admitindo apenas aquelas que podem ser executadas dentro da memória disponível em todos os nós.
O N1QL for Analytics também impõe menos restrições ao contexto sintático das chamadas de função de janela. Diferentemente do SQL, as consultas no N1QL for Analytics permitem funções de janela nas cláusulas WHERE e HAVING, bem como nas cláusulas LET específicas do N1QL.
Nossa consulta original, por exemplo, pode ser facilmente modificada para retornar apenas o funcionário mais bem classificado em cada departamento:
|
1 2 3 4 5 |
SELECT employee_id, department_id, salary FROM employee WHERE RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) = 1 |
Para concluir, as funções de janela no Analytics fornecem um mecanismo poderoso para análise e geração de relatórios de dados paralelos. A linguagem de consulta N1QL do Couchbase permite que os usuários avaliem facilmente essas funções diretamente nos dados JSON de seus aplicativos, evitando assim o processamento complexo de ETL.
Faça o download do Couchbase Server 6.5 hoje mesmo e entre em contato conosco pelo Fóruns para quaisquer perguntas ou comentários.
Referências
[1] Anunciando o Couchbase Server 6.5 GA - O que há de novo e aprimorado
https://www.couchbase.com/blog/announcing-couchbase-server-6-5-0-whats-new-and-improved/
[2] Em pé de igualdade com as funções de janela
https://www.couchbase.com/blog/on-par-with-window-functions-in-n1ql/
[3] Obtenha uma visão mais ampla com as funções de janela e CTE do N1QL
https://www.couchbase.com/blog/get-a-bigger-picture-with-n1ql-window-functions-and-cte/
[4] Funções de janela no Couchbase Analytics
https://www.couchbase.com/blog/window-functions-in-couchbase-analytics/
[5] Anunciando o Couchbase Server 6.0 com Analytics
https://www.couchbase.com/blog/announcing-couchbase-6-0/
[6] A história de tudo do Couchbase: DCP
https://www.couchbase.com/blog/couchbases-history-everything-dcp/
[7] Murtadha Al Hubail, Ali Alsuliman, Michael Blow, Michael Carey, Dmitry Lychagin, Ian Maxon e Till Westmann. Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis. PVLDB, 12(12): 2275-2286, 2019
https://www.vldb.org/pvldb/vol12/p2275-hubail.pdf
[8] Couchbase Analytics: Sob o capô - Connect Silicon Valley 2018
https://www.youtube.com/watch?v=1dN11TUj58c
[9] Plano de explicação do Analytics - Parte 1
https://www.couchbase.com/blog/analytics-explain-plan-part-1/
Boa postagem!