A typical AI agent application in 2025 usually involves:
- A cloud-hosted LLM
- A vector database for retrieval
- A separate operational database
- Prompt management and tool management tools
- Observability and tracing frameworks
- Guardrails
Each tool solves a problem. Collectively, however, they can potentially create architectural sprawl with unpredictable latency, rising operational costs, and governance blind spots. As a result, a lot of AI agents never move beyond demos or internal prototypes because the complexity escalates too fast.
This post walks through how we migrated an existing AI agent application to Couchbase AI Services and the Agent Catalog, moving to a single production-ready AI platform.
The Core Problem: Fragmentation Kills Production AI
It’s important to understand why agentic systems struggle in production. Most AI agents today are built from too many loosely coupled parts: prompts live in one system, vectors in another, conversations are logged inconsistently, tools are invoked without clear traceability – making agent behavior difficult to debug. At the same time, sending enterprise data to third-party LLM endpoints introduces compliance and security risks. Finally, governance is usually treated as an afterthought; many frameworks emphasize what an agent can do, but fail to explain why it made a decision, which prompt or tool influenced it, or whether that decision should have been allowed at all. This is an unacceptable gap for real business workflows.
What Are Couchbase AI Services?
Building AI applications often involves juggling multiple services: a vector database for memory, an inference provider for LLMs (like OpenAI or Anthropic), and separate infrastructure for embedding models.
Couchbase AI Services streamlines this by providing a unified platform where your operational data, vector search, and AI models live together. It offers:
- LLM inference and embeddings API: Access popular LLMs (like Llama 3) and embedding models directly within Couchbase Capella, with no external API keys, no extra infrastructure, and no data egress. Your application data stays inside Capella. Queries, vectors, and model inference all happen where the data lives. This enables secure, low-latency AI experiences while meeting privacy and compliance requirements. The key value: data and AI together, with sensitive information kept inside your system.
- Unified platform: Maintain your database, vectorization, search, and model in a central location.
- Integrated Vector Search: Perform semantic search directly on your JSON data with millisecond latency.
Why Is This Needed?
As we move from simple chatbots to agentic workflows – where AI models autonomously use tools – latency and setup complexity become major bottlenecks. Couchbase AI Services takes a platform-first approach. By co-locating your data and AI services, it reduces operational overhead and latency. In addition, tools like the Agent Catalog help manage hundreds of agent prompts and tools, while providing built-in logging and telemetry for agents.
At this point, the question shifts from why a platform-first approach matters to how it works in practice.
So let’s explore how you can migrate an existing agentic application, and improve its performance, governance, and reliability along the way.
What the Current App Looks Like
The current application is an HR Sourcing Agent designed to automate the initial screening of candidates. The main job of the agent application is to ingest raw resume files (PDFs), understand the content of the resumes using an LLM, and structure the unstructured data into a queryable format enriched with semantic embeddings in Couchbase. It allows HR professionals to upload a new job description and get results for the best-suited candidates using Couchbase vector search.
In its current state, the HR Sourcing App is a Python-based microservice that wraps an LLM with the Google ADK. It manually wires together model definitions, agent prompts, and execution pipelines. While functional, the architecture requires the developer to manage session state in memory, handle retry logic, clean raw model outputs, and maintain the integration between the LLM and the database manually. Also, there is no built-in telemetry for our agent.
The app manually instantiates a model provider. In this specific case, it connects to a hosted open source model (Qwen 2.5-72B via Nebius) using the LiteLLM wrapper. The app has to manually spin up a runtime environment for the agent. It initializes an InMemorySessionService to track the state of the conversation (even if short-lived) and a Runner to execute the user’s input (the resume text) against the agent pipeline.
Migrating the Agent Application to Couchbase AI Services
Now let’s dive into how to migrate the core logic of our agent to use Couchbase AI Services and the Agent Catalog.
The new agent uses a LangChain ReAct agent to process job descriptions, it performs intelligent candidate matching using vector search and provides ranked candidate recommendations with explanations.
Prerequisites
Before we begin, ensure you have:
- Python 3.10+ installed.
Install Dependencies
We’ll start by installing the necessary packages. This includes the agentc CLI for the catalog and the LangChain integration packages.
|
1 2 3 4 5 6 |
%pip install -q \ "pydantic>=2.0.0,<3.0.0" \ "python-dotenv>=1.0.0,<2.0.0" \ "pandas>=2.0.0,<3.0.0" \ "nest-asyncio>=1.6.0,<2.0.0" \ "langchain-couchbase>=0.2.4,<0.5.0" \ "langchain-openai>=0.3.11,<0.4.0" \ "arize-phoenix>=11.37.0,<12.0.0" \ "openinference-instrumentation-langchain>=0.1.29,<0.2.0" # Install Agent Catalog %pip install agentc==1.0.0 |
Centralized Model Service (Couchbase AI Model Services Integration)
In the original adk_resume_agent.py, we had to manually instantiate LiteLLM, manage specific provider API keys (Nebius, OpenAI, etc.), and handle the connection logic inside our application code. We will migrate the code to use Couchbase.
Couchbase AI Services provides OpenAI-compatible endpoints that are used by the agents. For the LLM and embeddings, we use the LangChain OpenAI package, which integrates directly with the LangChain Couchbase connector.
Enable AI Services
- Navigate to Capella’s AI Services section on the UI.
- Deploy the Embeddings and LLM models.
- You need to launch an embedding and an LLM for this demo in the same region as the Capella cluster where the data will be stored.
- Deploy an LLM that has tool calling capabilities such as mistralai/mistral-7b-instruct-v0.3. For embeddings, you can choose a model like the nvidia/llama-3.2-nv-embedqa-1b-v2.
- Note the endpoint URL and generate API keys.
For more details on launching AI models, you can check the official documentation.
Implementing the Code Logic for LLM and Embedding Models
We need to configure the endpoints for Capella Model Services. Capella Model Services are compatible with the OpenAI API format, so we can use the standard langchain-openai library by pointing it to our Capella endpoint. We initialize the embedding model with OpenAIEmbeddings and the LLM with ChatOpenAI, but point it to Capella.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# Model Services Config CAPELLA_API_ENDPOINT = getpass.getpass("Capella Model Services Endpoint: ") CAPELLA_API_LLM_MODEL = "mistralai/mistral-7b-instruct-v0.3" CAPELLA_API_LLM_KEY = getpass.getpass("LLM API Key: ") CAPELLA_API_EMBEDDING_MODEL = "nvidia/llama-3.2-nv-embedqa-1b-v2" CAPELLA_API_EMBEDDINGS_KEY = getpass.getpass("Embedding API Key: ") def setup_ai_services(temperature: float = 0.0): embeddings = None llm = None if not embeddings and os.getenv("CAPELLA_API_ENDPOINT") and os.getenv("CAPELLA_API_EMBEDDINGS_KEY"): try: endpoint = os.getenv("CAPELLA_API_ENDPOINT") api_key = os.getenv("CAPELLA_API_EMBEDDINGS_KEY") model = os.getenv("CAPELLA_API_EMBEDDING_MODEL", "Snowflake/snowflake-arctic-embed-l-v2.0") api_base = endpoint if endpoint.endswith('/v1') else f"{endpoint}/v1" embeddings = OpenAIEmbeddings( model=model, api_key=api_key, base_url=api_base, check_embedding_ctx_length=False, ) except Exception as e: logger.error(f"Couchbase AI embeddings failed: {e}") if not llm and os.getenv("CAPELLA_API_ENDPOINT") and os.getenv("CAPELLA_API_LLM_KEY"): try: endpoint = os.getenv("CAPELLA_API_ENDPOINT") llm_key = os.getenv("CAPELLA_API_LLM_KEY") llm_model = os.getenv("CAPELLA_API_LLM_MODEL", "deepseek-ai/DeepSeek-R1-Distill-Llama-8B") api_base = endpoint if endpoint.endswith('/v1') else f"{endpoint}/v1" llm = ChatOpenAI( model=llm_model, base_url=api_base, api_key=llm_key, temperature=temperature, ) test_response = llm.invoke("Hello") except Exception as e: logger.error(f"Couchbase AI LLM failed: {e}") llm = None |
Instead of hardcoding model providers, the agent now connects to a unified Capella endpoint, which acts as an API gateway for both the LLM and the embedding model.
Decoupling Prompts and Tools With Agent Catalog
The Agent Catalog is a powerful tool for managing the lifecycle of your agent’s capabilities. Instead of hardcoding prompts and tool definitions in your Python files, you manage them as versioned assets. You can centralize and reuse your tools across your development teams. You can also examine and monitor agent responses with the Agent Tracer. These features provide visibility, control, and traceability for agent development and deployment. Your teams can build agents with confidence, knowing they can be audited and managed effectively.
Without the ability to back-trace agent behavior, it becomes impossible to automate the ongoing trust, validation, and corroboration of the autonomous decisions made by agents. In the Agent Catalog, this is performed by evaluating both the agentic code and its conversation transcript with its LLM to assess the appropriateness of its pending decision or MCP tool lookup.
So let’s incorporate Agent Catalog in the project.
Adding the Vector Search Tool
We will start by adding our tool definition for the Agent Catalog. In this case we have the vector search tool.
To add a new Python function as a tool for your agent, you can use the Agent Catalog command-line tool’s add command:
agentc add
If you have an existing Python tool that you want to add to the Agent Catalog, add agentc to your imports and the @agentc.catalog.tool decorator to your tool definition. In our example, we define a Python function for performing vector search as our tool.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
""" Vector search tool for finding candidates based on job descriptions. This tool uses Couchbase vector search to find the most relevant candidates. Updated for Agent Catalog v1.0.0 with @tool decorator. """ import os import logging from typing import List, Dict, Any from datetime import timedelta from agentc_core.tool import tool from couchbase.cluster import Cluster from couchbase.auth import PasswordAuthenticator from couchbase.options import ClusterOptions from couchbase.vector_search import VectorQuery, VectorSearch from couchbase.search import SearchRequest, MatchNoneQuery logger = logging.getLogger(__name__) def generate_embedding(text: str, embeddings_client) -> List[float]: """Generate embeddings for text using the provided embeddings client.""" try: # Use the embeddings client to generate embeddings result = embeddings_client.embed_query(text) return result except Exception as e: logger.error(f"Error generating embedding: {e}") return [0.0] * 1024 # Return zero vector as fallback @tool( name="search_candidates_vector", description="Search for candidates using vector similarity based on a job description. Returns matching candidate profiles ranked by relevance.", annotations={"category": "hr", "type": "search"} ) def search_candidates_vector( job_description: str, num_results: int = 5, embeddings_client=None, ) -> str: """ Search for candidates using vector similarity based on job description. Args: job_description: The job description text to search against num_results: Number of top candidates to return (default: 5) embeddings_client: The embeddings client for generating query embeddings Returns: Formatted string with candidate information """ try: # Get environment variables bucket_name = os.getenv("CB_BUCKET", "travel-sample") scope_name = os.getenv("CB_SCOPE", "agentc_data") collection_name = os.getenv("CB_COLLECTION", "candidates") index_name = os.getenv("CB_INDEX", "candidates_index") # Connect to Couchbase cluster = get_cluster_connection() if not cluster: return "Error: Could not connect to database" bucket = cluster.bucket(bucket_name) scope = bucket.scope(scope_name) collection = scope.collection(collection_name) # Use scope.collection(), not bucket.collection() # Generate query embedding logger.info(f"Generating embedding for job description...") if embeddings_client is None: return "Error: Embeddings client not provided" query_embedding = generate_embedding(job_description, embeddings_client) # Perform vector search logger.info(f"Performing vector search with index: {index_name}") search_req = SearchRequest.create(MatchNoneQuery()).with_vector_search( VectorSearch.from_vector_query( VectorQuery("embedding", query_embedding, num_candidates=num_results * 2) ) ) result = scope.search(index_name, search_req, timeout=timedelta(seconds=20)) rows = list(result.rows()) if not rows: return "No candidates found matching the job description." # Fetch candidate details candidates = [] for row in rows[:num_results]: try: doc = collection.get(row.id, timeout=timedelta(seconds=5)) if doc and doc.value: data = doc.value data["_id"] = row.id data["_score"] = row.score candidates.append(data) except Exception as e: logger.warning(f"Error fetching candidate {row.id}: {e}") continue # Format results if not candidates: return "No candidate details could be retrieved." result_text = f"Found {len(candidates)} matching candidates:\n\n" for i, candidate in enumerate(candidates, 1): result_text += f"**Candidate {i}: {candidate.get('name', 'Unknown')}**\n" result_text += f"- Match Score: {candidate.get('_score', 0):.4f}\n" result_text += f"- Email: {candidate.get('email', 'N/A')}\n" result_text += f"- Location: {candidate.get('location', 'N/A')}\n" result_text += f"- Years of Experience: {candidate.get('years_experience', 0)}\n" skills = candidate.get('skills', []) if skills: result_text += f"- Skills: {', '.join(skills[:10])}\n" technical_skills = candidate.get('technical_skills', []) if technical_skills: result_text += f"- Technical Skills: {', '.join(technical_skills[:10])}\n" summary = candidate.get('summary', '') if summary: # Truncate summary if too long summary_text = summary[:200] + "..." if len(summary) > 200 else summary result_text += f"- Summary: {summary_text}\n" result_text += "\n" return result_text except Exception as e: logger.error(f"Error in vector search: {e}") import traceback traceback.print_exc() return f"Error performing candidate search: {str(e)}" |
Adding the Prompts
In the original architecture, the agent’s instructions were buried inside the Python code as large string variables, making them difficult to version or update without a full deployment. With the Agent Catalog, we now define our “HR Recruiter” persona as a standalone, managed asset using prompts. Using a structured YAML definition (record_kind: prompt), we create the hr_recruiter_assistant. This definition doesn’t just hold the text; it encapsulates the entire behavior of the agent, strictly defining the ReAct pattern (Thought → Action → Observation) that guides the LLM to use the vector search tool effectively.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
record_kind: prompt name: hr_recruiter_assistant description: AI-powered HR recruiter assistant that helps match candidates to job descriptions using vector search annotations: category: hr type: recruitment content: | You are an expert HR recruiter assistant with deep knowledge of talent acquisition and candidate matching. Your role is to help HR professionals find the best candidates for job openings by analyzing job descriptions and searching through a database of candidate profiles. You have access to the following tools: {tools} Use the following format for your responses: Question: the input question or job description you must analyze Thought: think about what information you need to find the best candidates Action: the action to take, should be one of [{tool_names}] Action Input: the input to the action (for candidate search, provide the job description text) Observation: the result of the action ... (this Thought/Action/Action Input/Observation can repeat N times) Thought: I now have enough information to provide recommendations Final Answer: Provide a comprehensive summary of the top candidates including: - Candidate names and key qualifications - Skills match percentage and relevance - Years of experience - Why each candidate is a good fit for the role - Any notable strengths or unique qualifications IMPORTANT GUIDELINES: - Always use the search_candidates_vector tool to find candidates - Analyze the job description to understand required skills and experience - Provide detailed reasoning for candidate recommendations - Highlight both technical skills and soft skills when relevant - Be specific about match percentages and scores - Format your final answer in a clear, professional manner Begin! Question: {input} Thought: {agent_scratchpad} |
Index and Publishing the Local Files
We use agentc to index our local files and publish them to Couchbase. This stores the metadata in the database, making it searchable and discoverable by the agent at runtime.
|
1 2 3 4 5 |
# Create local index of tools and prompts agentc index . # Upload to Couchbase agentc publish |
In our code, we initialize the Catalog and use catalog.find() to retrieve verified prompts and tools. We no longer hardcode prompts; instead, we fetch them.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# BEFORE: Hardcoded Prompt Strings # parse_instruction = "You are a resume parsing assistant..." import agentc from agentc import Catalog, Span # AFTER: Dynamic Asset Loading catalog = Catalog() # Load the "search" tool dynamically tool_result = catalog.find("tool", name="search_candidates_vector") # Load the "recruiter" persona dynamically prompt_result = catalog.find("prompt", name="hr_recruiter_assistant") # We act on the retrieved metadata tools = [Tool(name=tool_result.meta.name, func=...)] |
Standardized Reasoning Engine (LangChain Integration)
The previous app used a custom SequentialAgent pipeline. While flexible, it meant we had to maintain our own execution loops, error handling, and retry logic for the agent’s reasoning steps.
By leveraging the Agent Catalog’s compatibility with LangChain, we switched to a standard ReAct (Reason + Act) agent architecture. We simply feed the tools and prompts fetched from the catalog directly into create_react_agent.
What’s the benefit? We get industry-standard reasoning loops – Thought -> Action -> Observation – out of the box. The agent can now autonomously decide to search for “React Developers,” analyze the results, and then perform a second search for “Frontend Engineers” if the first yields few results. something the linear ADK pipeline struggled with.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
def create_langchain_agent(self, catalog: Catalog, embeddings, llm): try: # Load tools from catalog using v1.0.0 API tool_result = catalog.find("tool", name="search_candidates_vector") # Create tool wrapper that injects embeddings client def search_with_embeddings(job_description: str) -> str: return tool_result.func( job_description=job_description, num_results=5, embeddings_client=embeddings, ) tools = [ Tool( name=tool_result.meta.name, description=tool_result.meta.description, func=search_with_embeddings, ), ] # Load prompt from catalog using v1.0.0 API prompt_result = catalog.find("prompt", name="hr_recruiter_assistant") if prompt_result is None: raise ValueError("Could not find hr_recruiter_assistant prompt in catalog. Run 'agentc index' first.") custom_prompt = PromptTemplate( template=prompt_result.content.strip(), input_variables=["input", "agent_scratchpad"], partial_variables={ "tools": "\n".join([f"{tool.name}: {tool.description}" for tool in tools]), "tool_names": ", ".join([tool.name for tool in tools]), }, ) # Create agent agent = create_react_agent(llm, tools, custom_prompt) agent_executor = AgentExecutor( agent=agent, tools=tools, verbose=True, handle_parsing_errors=handle_parsing_error, max_iterations=5, max_execution_time=120, early_stopping_method="force", return_intermediate_steps=True, ) logger.info("LangChain ReAct agent created successfully") return agent_executor |
Built-in Observability (Agent Tracing)
In the previous agent application, observability was limited to print() statements. There was no way to “replay” an agent’s session to understand why it rejected a specific candidate.
Agent Catalog provides tracing. It allows users to use SQL++ with traces, leverage the performance of Couchbase, and get insight into details of prompts and tools in the same platform.
We can add Transactional Observability using catalog.Span(). We wrap the execution logic in a context manager that logs every thought, action, and result back to Couchbase. We can now view a full “trace” of the recruitment session in the Capella UI, showing exactly how the LLM processed a candidate’s resume.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
application_span = catalog.Span(name="HR Recruiter Agent") # AFTER: granular observability with span.new(name="job_matching_query") as query_span: # Log the input query_span.log(UserContent(value=job_description)) # Run the agent response = agent.invoke({"input": job_description}) # Log the agent's final decision query_span.log(AssistantContent(value=response["output"])) |
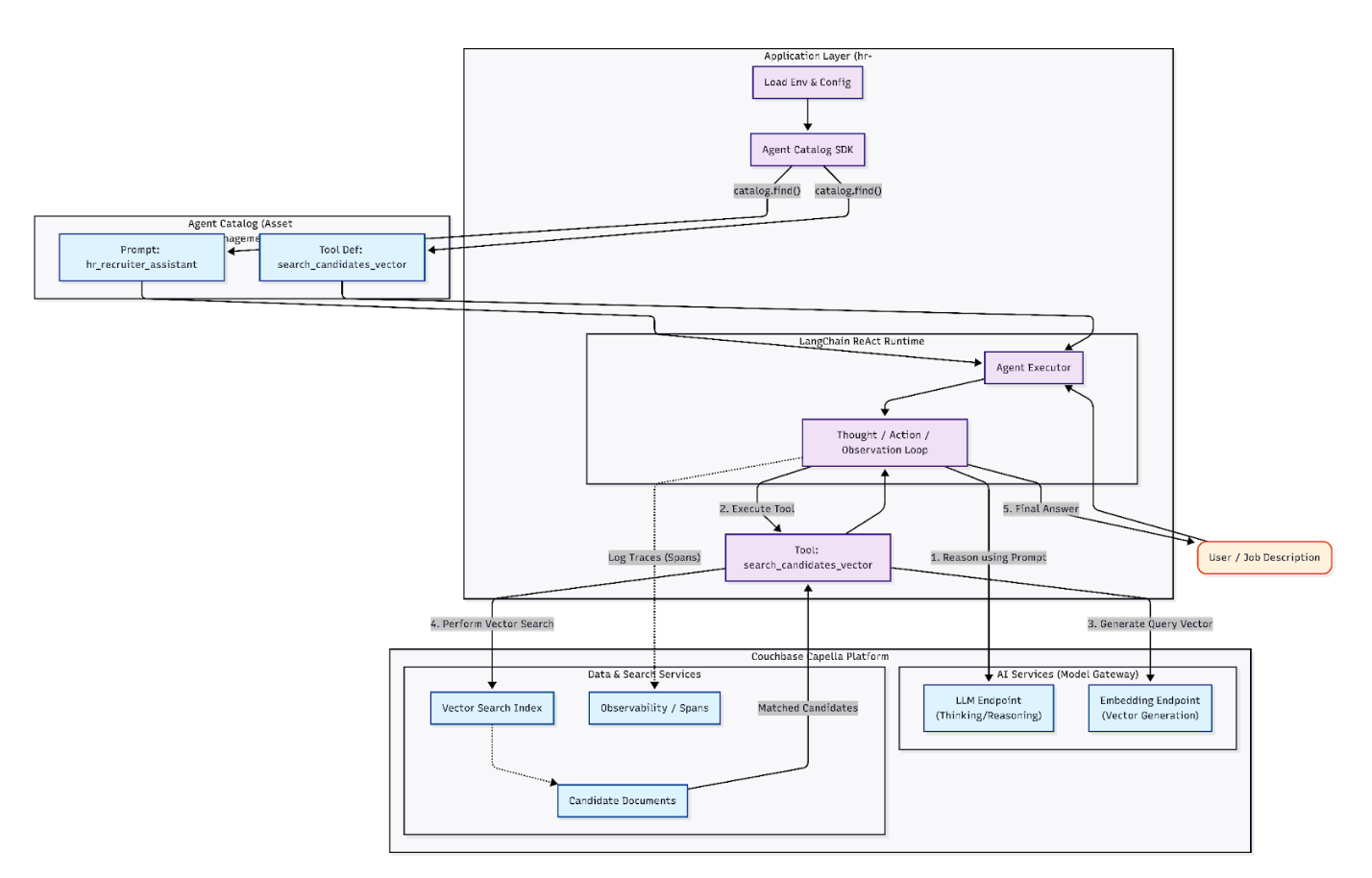
Conclusion
AI agents fail in production not because LLMs lack capability, but because agentic systems can become too complex. By adopting a platform-first approach with Couchbase AI Services and the Agent Catalog, we transformed a complex agent into a governed, scalable agentic system.
If you’re building AI agents today, the real question isn’t which LLM to use – it’s how you’ll run agents safely, observably, and at scale. Couchbase AI Services are built for exactly that.