애플리케이션을 개발하다 보면 데이터 덩어리 내에서 특정 텍스트 집합을 검색해야 하는 시나리오에 항상 부딪히게 됩니다. 다른 많은 사람들과 마찬가지로 저도 쉬운 방법을 택하여 와일드카드 쿼리를 사용하는 경우가 많습니다. 하지만 쿼리에서 와일드카드를 사용하면 애플리케이션이나 데이터베이스 내에서 상당한 성능 저하와 비효율을 초래할 수 있습니다. 바로 이 지점에서 전체 텍스트 검색(FTS)이 등장합니다.
전체 텍스트 검색은 전체 텍스트 인덱스에서 작동하며 데이터베이스에서 단어와 구문을 검색할 때 와일드카드로 작업하는 것보다 훨씬 효율적입니다. 지금까지는 이를 가능하게 하려면 Solr 또는 ElasticSearch와 같은 다른 검색 소프트웨어를 사용해야 했습니다. Couchbase 4.5부터는 개발자 미리 보기를 통해 FTS를 단일 플랫폼으로 가져올 수 있습니다.
Couchbase Server용 Node.js SDK를 사용하여 Node.js 애플리케이션에서 전체 텍스트 검색을 사용하는 방법을 살펴보겠습니다. 다음 내용은 이미 Node.js가 설치되어 있고 개발 준비가 되어 있다고 가정합니다. 또한 Couchbase Server 4.5 이상을 사용하고 있다고 가정합니다.
간단하게 설명하기 위해 간단한 스토리가 있는 새 Node.js 프로젝트를 만들어 보겠습니다. 컴퓨터 어딘가에 새 프로젝트를 생성하는 것으로 시작하겠습니다. 이 프로젝트를 이력서. 프로젝트 이름에서 짐작할 수 있듯이, 우리는 입사 지원자의 이력서를 파싱하는 애플리케이션을 만들려고 합니다. FTS를 사용하여 특정 직무와 관련된 키워드나 문구를 검색할 수 있습니다. FTS는 검색 점수를 제공하기 때문에 어떤 후보자가 해당 직무에 더 적합한지 확인할 수 있습니다.
새 Node.js 프로젝트 만들기
터미널(Mac 및 Linux) 또는 명령 프롬프트(Windows)를 사용하여 프로젝트를 현재 활성 디렉터리로 설정하고 다음을 실행합니다:
|
1 2 3 |
npm init -y |
위의 명령은 새 Node.js 프로젝트를 초기화합니다. 앞으로 모든 터미널 및 명령 프롬프트 활동은 프로젝트를 현재 작업 디렉터리로 사용하여 수행됩니다.
RESTful 애플리케이션보다는 Node.js 스크립트를 더 많이 만들려고 합니다. 즉, 종속성 요구 사항은 단 한 가지이며, 그것은 바로 Couchbase Node.js SDK입니다. 설치하려면 명령 프롬프트 또는 터미널에서 다음을 실행합니다:
|
1 2 3 |
npm install couchbase --save |
아직 코딩을 시작하지는 않겠지만 기본 Node.js 파일을 만들려고 합니다. Create app.js 를 프로젝트의 루트에 추가하세요.
전체 텍스트 검색 색인 만들기
전체 텍스트 검색을 사용하려면 먼저 특수 색인을 만들어야 합니다. 이 작업은 색인 -> 전체 텍스트 탭을 클릭합니다.
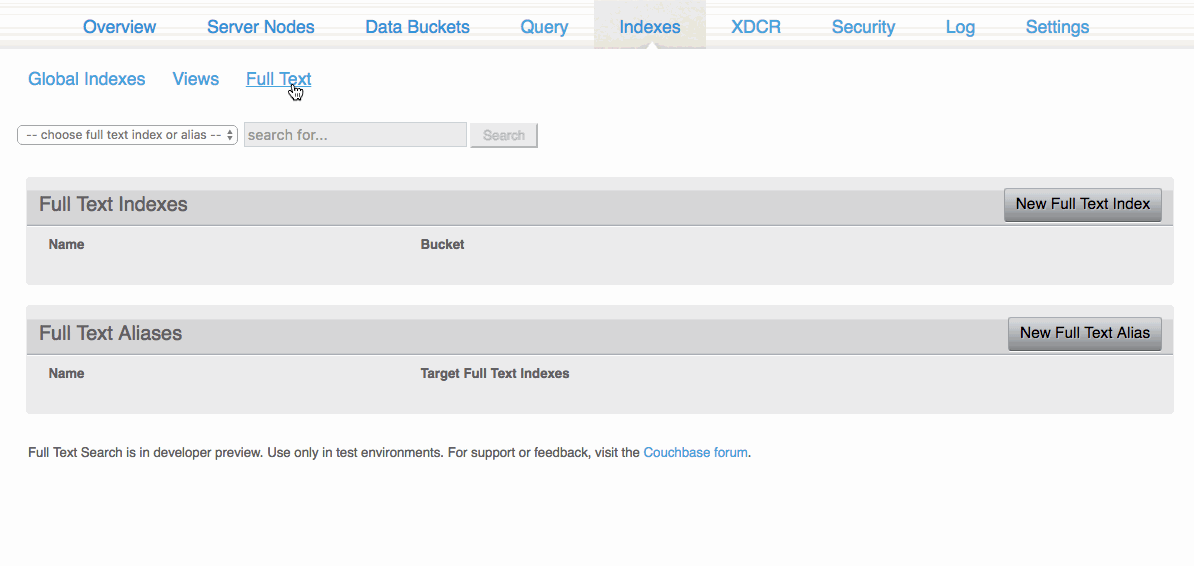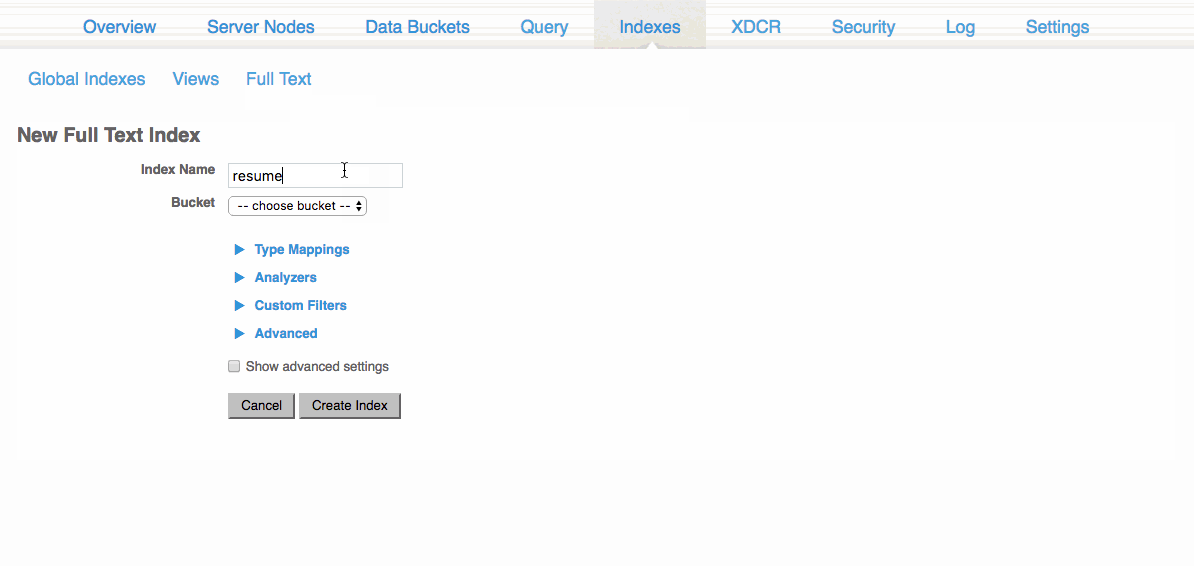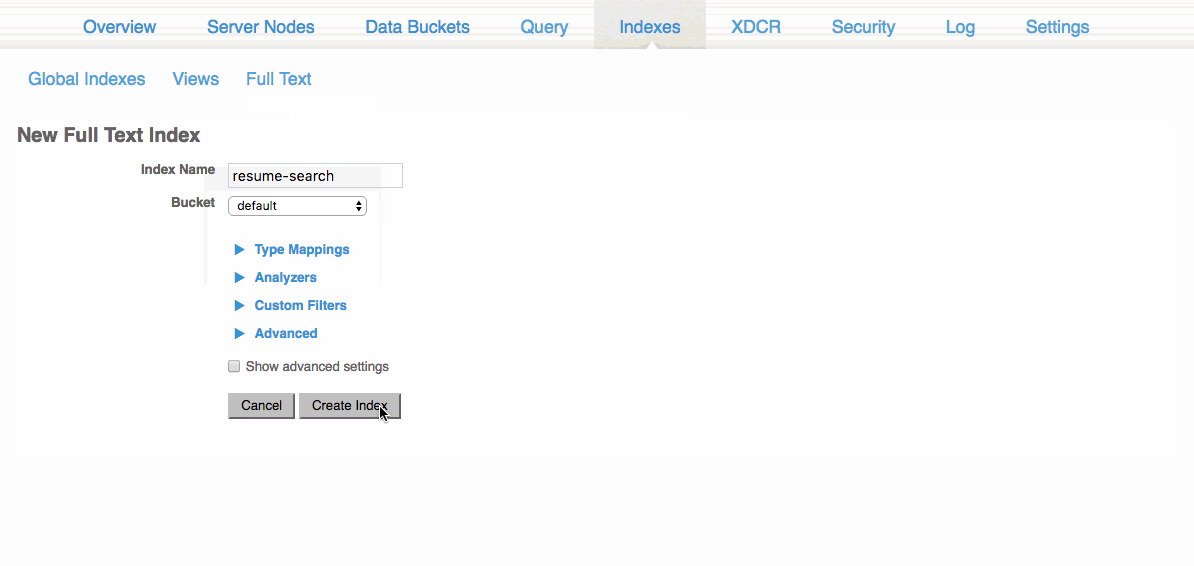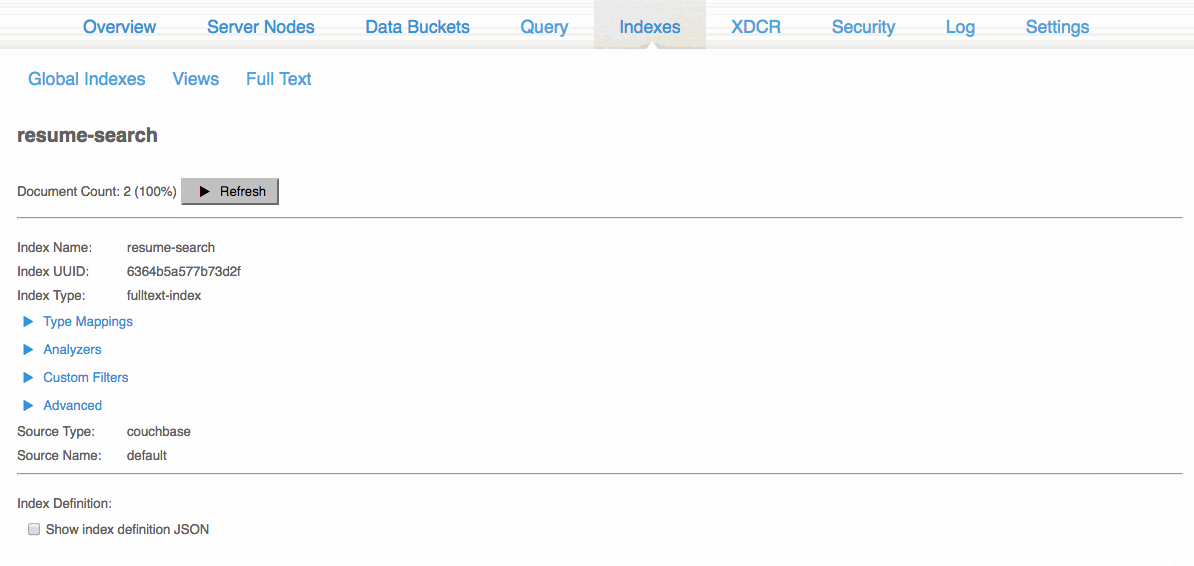
이 섹션에서 다음을 선택할 수 있습니다. 새로운 전체 텍스트 색인 을 클릭하고 적용할 이름과 버킷을 선택합니다. 이 예제에서는 기본값 버킷과 이력서 검색. 인덱스는 매우 기본적이므로 이 인덱스를 통해 문서 필요에 가장 잘 맞출 수 있습니다.
인덱스가 생성된 후 새로 고침 버튼을 클릭합니다. 이 시점에서 대시보드 또는 자체 코드를 통해 테스트해 볼 수 있습니다.
Node.js 애플리케이션 개발
다시 한 번 말씀드리자면, 이 프로젝트는 다소 단순하게 진행될 것입니다. 이 아이디어를 확장하여 완전한 이력서 평가 애플리케이션을 만들 수도 있습니다. 저희는 가능성의 표면을 긁어모은 것에 불과합니다.
프로젝트의 app.js 파일을 열고 다음 자바스크립트 코드를 포함합니다:
|
1 2 3 4 5 6 |
var Couchbase = require("couchbase"); var cluster = new Couchbase.Cluster("couchbase://localhost") var bucket = cluster.openBucket("default"); |
위에서는 다운로드한 종속성을 가져와서 선택한 Couchbase 클러스터에 연결을 설정하고 있습니다. 이 경우에는 내 로컬 머신의 단일 노드 클러스터입니다.
전체 텍스트 검색 작업을 시작하기 전에 데이터 모델에 대해 생각해 보겠습니다. 각 이력서가 데이터베이스에 있는 문서라고 가정해 보겠습니다. 예를 들어 여기 제 이력서가 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
{ "firstname": "Nic", "lastname": "Raboy", "skills": [ "java", "node.js", "golang", "nosql" ], "summary": "", "social": { "github": "https://www.github.com/nraboy", "twitter": "https://www.twitter.com/nraboy" }, "employment": [ { "employer": "Couchbase", "title": "Developer Advocate", "location": "San Francisco" } ] } |
예, 물론 위의 내용은 실제 이력서가 아닙니다. 우리가 작업할 내용을 확인하기 위한 예시일 뿐입니다. 이제 그 사람이 이전에 개발자 옹호자 경력이 있는 모든 이력서를 찾고 싶다고 가정해 보겠습니다. Node.js에서 다음을 생성할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var SearchQuery = Couchbase.SearchQuery; var query = SearchQuery.new("resume-search", SearchQuery.match("developer advocate")); bucket.query(query, function(error, result, meta) { if(error) { return console.log("ERROR: ", error); } for (var i = 0; i < result.length; i++) { console.log({"id": result[i].id, "score": result[i].score}); } return; }); |
내 경력에 개발자 지원 담당자였다고 기재했으므로 제 기록이 표시됩니다. 하지만 위의 FTS 쿼리는 다소 모호합니다. 문서의 어떤 속성에서든 "개발자 옹호자"라는 단어만 있으면 알 수 있습니다. 구체적으로 고용 기록으로 범위를 좁히고 싶을 수도 있습니다. 이 경우 검색 쿼리 를 다음과 같이 설정합니다:
|
1 2 3 |
var query = SearchQuery.new("resume-search", SearchQuery.match("developer advocate").field("employment.title")); |
사용법에 유의하세요. 필드 함수를 사용하시나요? 다음 기능을 사용할 수도 있습니다. 필드 를 클릭하고 검색할 필드 배열을 전달합니다.
FTS와 Node.js SDK를 사용하여 데이터를 검색하는 다른 방법도 많이 있습니다. FTS 사용에 대한 몇 가지 정보를 확인하려면 개발자 문서 또는 Node.js API 문서.
결론
와일드카드 데이터를 효율적인 방식으로 쿼리해야 하는 경우, Couchbase와 Node.js SDK는 전체 텍스트 검색(FTS)을 지원합니다. 전체 텍스트 검색에는 제가 설명한 것보다 훨씬 더 복잡한 시나리오가 있습니다. 예를 들어 검색에 조건을 추가하거나 패싯 정보를 보고 싶을 수도 있습니다. 이 모든 내용은 카우치베이스 개발자 포털.