다음에서 전체 텍스트 검색 쿼리를 실행할 수 있습니다. 카우치베이스 Elastic과 같은 추가 도구가 필요 없는 것은 NoSQL에 큰 도움이 됩니다.
약 1년 전에 저는 Node.js SDK를 사용한 Couchbase Server의 전체 텍스트 검색(FTS). 이것은 FTS가 개발자 프리뷰 버전이었을 때의 이야기입니다. 여전히 유효하지만, 전체 텍스트 검색으로 할 수 있는 작업의 진정한 힘을 요약하지는 못합니다. Take 패싯 를 예로 들 수 있습니다. 패싯은 결과 집합에서 수집된 집계 정보로, 결과 데이터를 분류할 때 유용합니다.
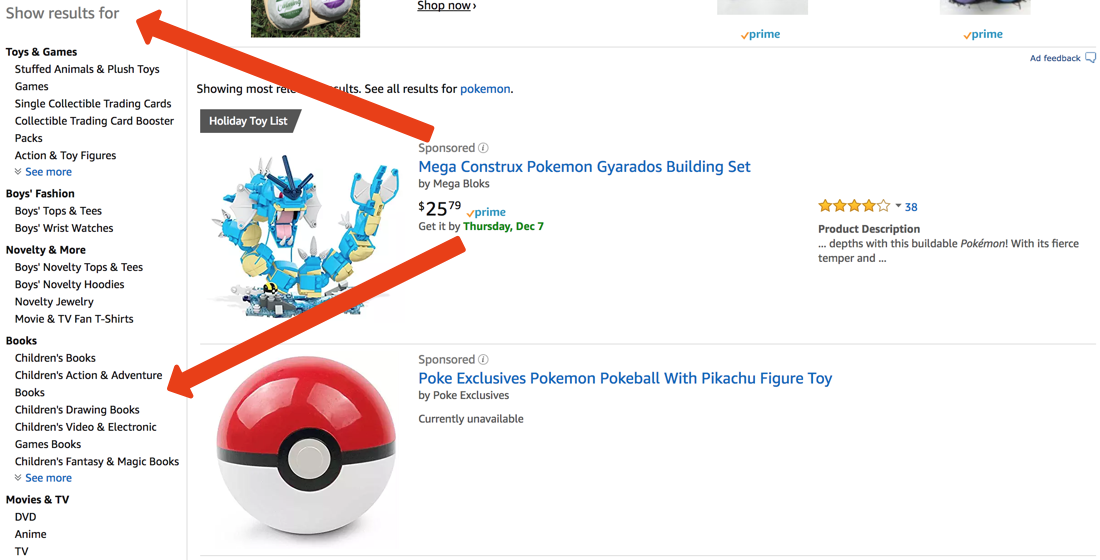
위 이미지는 아마존 검색을 보여줍니다. 다음과 같이 검색했다고 가정해 보겠습니다. 포켓몬. 왼쪽의 카테고리는 다음과 같습니다, 도서 또는 영화 및 TV를 검색 패싯으로 간주할 수 있습니다.
Node.js 애플리케이션에서 이 패싯 검색 기능을 활용하는 방법을 살펴보겠습니다.
앞으로는 Node.js와 Couchbase Server 5.0+가 이미 설치 및 구성되어 있어야 합니다. 여기서는 코드와 인덱스 생성 를 사용하여 애플리케이션에서 패싯 FTS를 작동시킬 수 있습니다.
샘플 데이터로 샘플 버킷 준비하기
작업할 데이터를 직접 만드는 대신 Couchbase를 사용하는 모든 사람이 사용할 수 있는 선택적 샘플 데이터를 활용할 것입니다. 우리는 맥주 샘플 버킷.
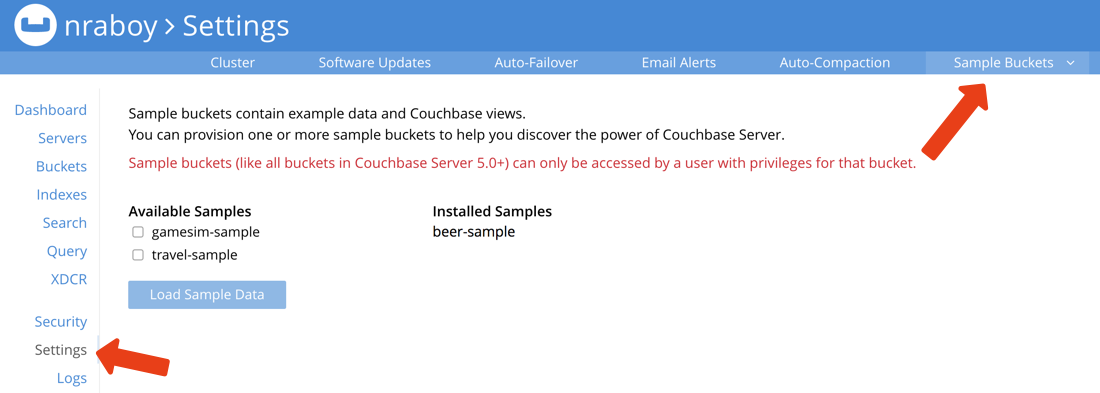
이 버킷을 설치하는 방법을 잘 모르겠다면 Couchbase 관리 대시보드에서 설정 을 클릭한 다음 샘플 버킷. 샘플 버킷을 통해 약 8,000개의 문서를 작업할 수 있습니다.
Couchbase NoSQL로 전체 텍스트 검색을 위한 인덱스 만들기
데이터베이스에 대한 검색을 수행하려면 먼저 특수 FTS 인덱스를 만들어야 합니다. 이 인덱스의 목적은 특정 문서에서 검색할 두 가지 속성을 선택하는 것입니다. 한 속성은 검색하고자 하는 대상을 나타내고, 다른 속성은 검색하고자 하는 대상과 함께 패싯을 나타냅니다.
관리 대시보드에서 다음을 선택합니다. 검색 을 클릭한 다음 색인 추가.
Couchbase에서 전체 텍스트 검색을 처음 사용하는 경우 이 부분에서 조금 이상하게 느껴질 수 있습니다.
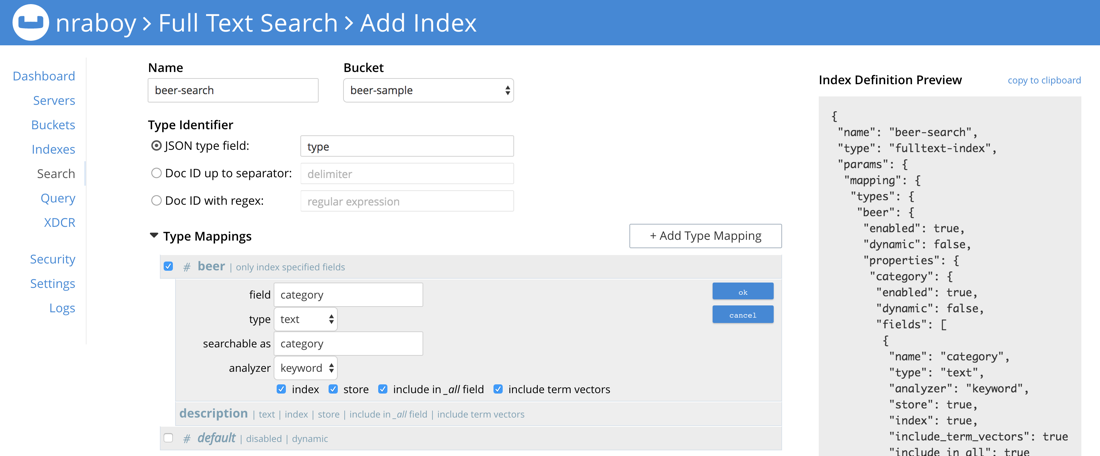
색인을 디자인할 때 이름을 지정하고 싶을 것입니다. 저는 이름을 사용하고 있습니다, 맥주 검색를 사용해야 하지만 원하는 것은 무엇이든 사용할 수 있습니다. 다만 올바른 맥주 샘플 버킷. 버킷에 유형 식별자 를 기본값으로 설정하고 유형 매핑 섹션으로 이동합니다.
다음과 같은 문서에 대해 검색할 계획입니다. 유형 일치하는 속성 맥주 따라서 위 이미지에서 만든 매핑입니다. 전체 문서가 아니라 뒤에 오는 지정된 필드만 인덱싱하는 것이 중요합니다. 새 매핑 아래에서 하위 필드를 만들어야 합니다. 이러한 하위 필드는 우리가 패싯할 수 있는 항목과 검색할 수 있는 항목을 나타냅니다.
그리고 설명 필드는 기본값을 사용하지만, 우리는 store 옵션을 선택합니다. 이렇게 하면 결과에서 액세스할 수 있습니다. 결과의 카테고리 필드는 키워드 분석기와 store 옵션을 사용하세요. 카테고리당 여러 단어가 포함되어 있으므로 분석기는 공백으로 구분된 텍스트를 처리하는 방법을 알고 있어야 합니다. 분석기의 키워드 분석기를 사용하면 이러한 약관에 따라 작업할 수 있습니다.
마지막으로 색인을 저장하면 잠시 후 모든 문서가 색인화됩니다.
Node.js에서 패싯을 사용하여 전체 텍스트 검색 쿼리 실행하기
새로 생성된 이 쿼리를 쿼리하겠습니다. 맥주 검색 인덱스를 두 부분으로 나누어 Amazon과 같은 사이트에서 수행되는 방식을 모방해 보겠습니다. 먼저 용어를 기준으로 쿼리를 실행하고 결과와 패싯을 표시하겠습니다. 이 패싯은 두 번째 부분을 준비할 것입니다.
올바르게 구성된 Node.js 프로젝트를 사용할 수 있다고 가정하고 다음 JavaScript 코드를 추가합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const Couchbase = require("couchbase"); const SearchQuery = Couchbase.SearchQuery; const SearchFacet = Couchbase.SearchFacet; const cluster = new Couchbase.Cluster("couchbase://localhost"); cluster.authenticate("demo", "123456") const bucket = cluster.openBucket("beer-sample"); var tq1 = SearchQuery.term("coffee").field("description"); var query1 = SearchQuery.new("beer-search", tq1); query1.addFacet("categories", SearchFacet.term("category", 5)); query1.limit(3); bucket.query(query1, (error, result, meta) => { for(var i = 0; i < result.length; i++) { console.log("HIT: ", result[i].id); console.log("FACETS: ", meta.facets["categories"].terms); } }); |
위의 코드 대부분은 클러스터에 대한 연결을 설정하고 다음에 이어질 검색을 준비하는 것과 관련이 있습니다. 저희가 가장 관심을 두고 있는 부분은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
var tq1 = SearchQuery.term("coffee").field("description"); var query1 = SearchQuery.new("beer-search", tq1); query1.addFacet("categories", SearchFacet.term("category", 5)); query1.limit(3); bucket.query(query1, (error, result, meta) => { for(var i = 0; i < result.length; i++) { console.log("HIT: ", result[i].id); console.log("FACETS: ", meta.facets["categories"].terms); } }); |
위 코드에서는 다음과 같은 검색어를 정의하고 있습니다. tq1 에 대해 검색하는 설명 속성 커피. 검색 쿼리를 생성할 때 이전에 생성한 인덱스를 정의하고 검색어를 추가합니다.
라는 패싯을 추가합니다. 카테고리는 저희가 방금 지어낸 이름입니다. 이 용어는 카테고리 맵이 카테고리 속성을 추가할 수 있습니다. 또한 결과에 5개 이상의 패싯이 표시되지 않기를 원합니다.
코드를 실행하면 다음과 같은 결과가 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
HIT: lagunitas_brewing_company-cappuccino_stout FACETS: [ { term: 'North American Ale', count: 50 }, { term: 'Irish Ale', count: 19 }, { term: 'British Ale', count: 11 }, { term: 'German Lager', count: 4 }, { term: 'Belgian and French Ale', count: 3 } ] HIT: terrapin_beer_company-terrapin_coffee_oatmeal_imperial_stout FACETS: [ { term: 'North American Ale', count: 50 }, { term: 'Irish Ale', count: 19 }, { term: 'British Ale', count: 11 }, { term: 'German Lager', count: 4 }, { term: 'Belgian and French Ale', count: 3 } ] HIT: humboldt_brewing-black_xantus FACETS: [ { term: 'North American Ale', count: 50 }, { term: 'Irish Ale', count: 19 }, { term: 'British Ale', count: 11 }, { term: 'German Lager', count: 4 }, { term: 'Belgian and French Ale', count: 3 } ] |
문서 키와 검색에 표시되는 모든 패싯이 인쇄되는 것을 확인할 수 있습니다. 패싯 용어에는 발생 횟수도 포함됩니다. 원한다면 결과에 다른 필드를 포함할 수도 있었지만 이 예제에서는 문서 키와 패싯으로 충분합니다.
이제 결과를 알았으니 쿼리 범위를 좁혀 보겠습니다.
Node.js에서 여러 검색어로 접속 쿼리 수행하기
사용자가 다음을 검색했다고 가정해 보겠습니다. 커피를 선택했지만, 맥주 선택 범위를 다음과 같이 좁히기로 결정했습니다. 독일 라거. 이는 일부 프런트엔드에서 사용자가 검색 후 패싯 중 하나를 선택했음을 의미합니다.
다음 자바스크립트 코드를 살펴보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
const Couchbase = require("couchbase"); const SearchQuery = Couchbase.SearchQuery; const SearchFacet = Couchbase.SearchFacet; const cluster = new Couchbase.Cluster("couchbase://localhost"); cluster.authenticate("demo", "123456") const bucket = cluster.openBucket("beer-sample"); var tq1 = SearchQuery.term("coffee").field("description"); var tq2 = SearchQuery.term("German Lager").field("category"); var conjunction = SearchQuery.conjuncts(tq1, tq2); query2 = SearchQuery.new("beer-search", conjunction); query2.addFacet("categories", SearchFacet.term("category", 5)); query2.limit(3); bucket.query(query2, (error, result, meta) => { for(var i = 0; i < result.length; i++) { console.log("HIT: ", result[i].id); console.log("FACETS: ", meta.facets["categories"].terms); } }); |
몇 가지 변경 사항이 있습니다.
이제 하나의 검색어 대신 두 개의 검색어가 있습니다. 하나는 설명를 검색하지만 새 용어는 이전과 마찬가지로 카테고리 속성. 두 용어를 사용하여 검색하려면 접속사 쿼리라고 하는 것을 수행해야 합니다.
위의 코드를 실행하면 다음과 같은 결과가 나타납니다:
|
1 2 3 4 5 6 |
HIT: sprecher_brewing-black_bavarian_lager FACETS: [ { term: 'German Lager', count: 4 } ] HIT: red_oak_brewery-battlefield_bock FACETS: [ { term: 'German Lager', count: 4 } ] HIT: four_peaks_brewing-black_betty_schwartzbier FACETS: [ { term: 'German Lager', count: 4 } ] |
이전에 보았던 다양한 맥주에 비해 결과에는 독일 라거만 포함되어 있음을 알 수 있습니다. 이는 패싯 정보를 사용하여 보조 쿼리로 결과의 범위를 좁힐 수 있었기 때문입니다.
예제의 전체 자바스크립트 코드
모든 것을 종합하면 다음과 같이 보일 것입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
const Couchbase = require("couchbase"); const SearchQuery = Couchbase.SearchQuery; const SearchFacet = Couchbase.SearchFacet; const cluster = new Couchbase.Cluster("couchbase://localhost"); cluster.authenticate("demo", "123456") const bucket = cluster.openBucket("beer-sample"); var tq1 = SearchQuery.term("coffee").field("description"); var query1 = SearchQuery.new("beer-search", tq1); query1.addFacet("categories", SearchFacet.term("category", 5)); query1.limit(3); bucket.query(query1, (error, result, meta) => { for(var i = 0; i < result.length; i++) { console.log("HIT: ", result[i].id); console.log("FACETS: ", meta.facets["categories"].terms); } }); var tq2 = SearchQuery.term("German Lager").field("category"); var conjunction = SearchQuery.conjuncts(tq1, tq2); query2 = SearchQuery.new("beer-search", conjunction); query2.addFacet("categories", SearchFacet.term("category", 5)); query2.limit(3); bucket.query(query2, (error, result, meta) => { for(var i = 0; i < result.length; i++) { console.log("HIT: ", result[i].id); console.log("FACETS: ", meta.facets["categories"].terms); } }); |
위의 코드는 현실적이지 않다는 점에 유의하세요. 우선 비동기식입니다. 실제 상황은 사용자 상호작용에 의해 제어됩니다. 사용자가 한 번의 검색을 수행하고 무언가를 변경한 다음 앞서 설명한 대로 두 번째 검색을 수행합니다.
결론
에서 패싯으로 검색하는 방법을 보셨습니다. 카우치베이스 전체 텍스트 검색(FTS)과 Node.js SDK를 사용합니다. FTS는 자연어를 쿼리하는 방법이며 N1QL과는 매우 다릅니다. FTS는 매우 강력하며 많은 훌륭한 작업을 수행할 수 있습니다.
카우치베이스에서 전체 텍스트 검색을 사용하는 방법에 대한 자세한 내용은 다음을 참조하세요. 카우치베이스 개발자 포털.