라트노팜 차크라바티 는 현재 에릭슨에서 근무하는 소프트웨어 개발자입니다. 그는 오랫동안 IoT, 기계 간 기술, 커넥티드 카, 스마트 시티 분야에 집중해 왔습니다. 그는 새로운 기술을 배우고 이를 실무에 적용하는 것을 좋아합니다. 일하지 않을 때는 3살 난 아들과 함께 시간을 보내는 것을 즐깁니다.
전체 텍스트 기반 검색은 사용자가 텍스트와 키워드를 기반으로 검색할 수 있는 기능으로, 사용자와 개발자 커뮤니티에서 매우 인기 있는 기능입니다. 따라서 전체 텍스트 검색을 제공하는 API와 프레임워크가 Apache Solr, Lucene, Elasticsearch 등 수없이 많다는 것은 당연한 일입니다. 카우치베이스선도적인 NoSQL 업체 중 하나인 카우치베이스는 Couchbase Server 4.5 릴리스에서 이 기능을 출시하기 시작했습니다.
이 게시물에서는 전체 텍스트 검색 서비스를 애플리케이션에 통합하는 방법을 설명합니다. 카우치베이스 자바 SDK.
설정
start.spring.io로 이동하여 Spring 부팅 애플리케이션의 종속성으로 Couchbase를 선택합니다.
프로젝트가 설정되면 프로젝트 개체 모델(pom.xml) 파일에 다음과 같은 종속성이 표시됩니다. 이는 앱에 대한 모든 Couchbase 라이브러리가 제자리에 있는지 확인합니다.
<dependency>
org.springframework.boot
스프링-부팅-스타터-데이터-카우치베이스
</dependency>
검색할 샘플 데이터 집합을 저장할 Couchbase 버킷을 설정해야 합니다.
Couchbase 관리 콘솔에서 "conference"라는 이름의 버킷을 만들었습니다.
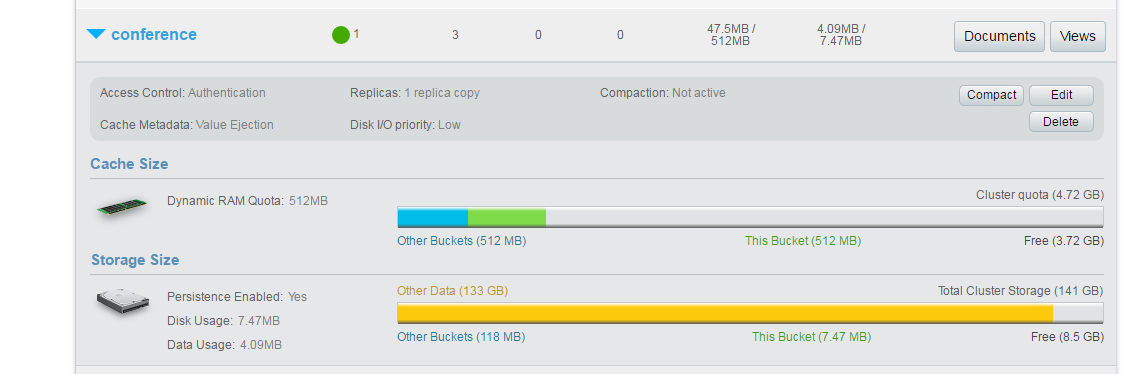
'컨퍼런스' 버킷에는 현재 3개의 문서가 있으며, 여기에는 전 세계에서 개최되는 다양한 컨퍼런스에 대한 데이터가 담겨 있습니다. 이 데이터 모델을 확장하거나 실험을 원한다면 직접 데이터 모델을 만들 수도 있습니다. 예를 들어 이력서, 제품 카탈로그, 심지어 트윗도 전체 텍스트 검색에 좋은 활용 사례가 될 수 있습니다. 하지만 여기서는 아래 그림과 같이 컨퍼런스 데이터를 예로 들어 보겠습니다:
{
"title": "도커콘",
"유형": "회의",
"위치": "오스틴",
"시작": "04/17/2017",
"end": "04/20/2017",
"주제": [
"컨테이너",
"devops",
"마이크로 서비스",
"제품 개발",
"가상화"
],
"참석자": 20000,
"요약": "도커콘은 도커와 그 생태계의 모든 측면을 다루는 주제와 콘텐츠를 제공할 것이며 개발자, DevOps, 시스템 관리자, 최고 경영진에게 적합할 것입니다.": "도커콘은 개발자, 개발자, 시스템 관리자, 최고 경영진을 위한 행사입니다.",
"social": {
"facebook": "https://www.facebook.com/dockercon",
"twitter": "https://www.twitter.com/dockercon"
},
"스피커": [
{
"name": "아룬 굽타",
"토크": "카우치베이스가 있는 도커",
"date": "04/18/2017",
"기간": "2"
},
{
"이름": "로라 프랭크",
"토크": "오픈소스",
"date": "04/19/2017",
"기간": "2"
}
]
}
위의 데이터 세트에서 전체 텍스트 검색을 사용하려면 먼저 전체 텍스트 검색 인덱스를 만들어야 합니다. 다음 단계를 수행합니다:
Couchbase 관리 콘솔에서 인덱스 탭을 클릭합니다.
전체 텍스트 링크를 클릭하면 현재 전체 텍스트 색인이 나열됩니다.
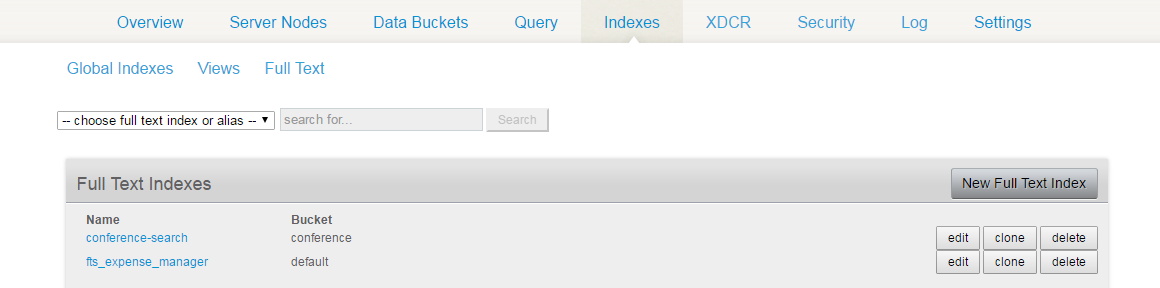
짐작할 수 있듯이, 저는 회의 관련 데이터를 검색하기 위해 Java 코드에서 "conference-search"라는 인덱스를 만들었습니다.
새 전체 텍스트 색인 버튼을 클릭하여 새 색인을 만듭니다.
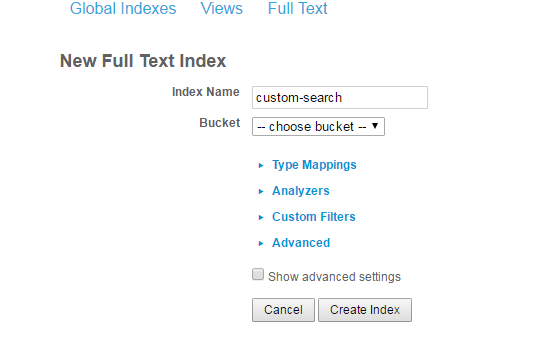
네, 그렇게 간단합니다. 인덱스를 만들었으면 구축 중인 앱에서 인덱스를 사용할 준비가 된 것입니다.
코드를 살펴보기 전에 이미 버킷에 있는 다른 두 개의 문서를 살펴봅시다.
회의::2
{
"title": "Devoxx UK",
"유형": "회의",
"위치": "벨기에",
"시작": "05/11/2017",
"end": "05/12/2017",
"주제": [
"클라우드",
"IOT",
"빅 데이터",
"머신 러닝",
"가상 현실"
],
"참석자": 10000,
"요약": "Devoxx UK가 2017년에 런던으로 돌아옵니다. 다시 한 번 최고의 개발자 콘텐츠와 멋진 경험을 위해 훌륭한 연사와 참석자를 맞이할 것입니다."
"social": {
"facebook": "https://www.facebook.com/devoxxUK",
"twitter": "https://www.twitter.com/devoxxUK"
},
"스피커": [
{
"이름": "빅토르 파르치치",
"talk": "클라우드비",
"date": "05/11/2017",
"기간": "2"
},
{
"이름": "패트릭 쿠아",
"이야기": "씽크웍스",
"date": "05/12/2017",
"기간": "2"
}
]
}
회의::3
{
"title": "리인벤트",
"유형": "회의",
"위치": "라스베가스",
"시작": "11/28/2017",
"end": "11/30/2017",
"주제": [
"aws",
"서버리스",
"마이크로 서비스",
"클라우드 컴퓨팅",
"증강 현실"
],
"참석자": 30000,
"요약": "아마존 웹 서비스 리인벤트 2017은 더 큰 장소, 더 많은 세션, 마이크로서비스 및 람다와 같은 기술에 초점을 맞출 것을 약속합니다.",
"social": {
"facebook": "https://www.facebook.com/reinvent",
"twitter": "https://www.twitter.com/reinvent"
},
"스피커": [
{
"이름": "라이언 K",
"talk": "아마존 알렉사",
"date": "11/28/2017",
"기간": "2.5"
},
{
"이름": "앤서니 제이",
"talk": "람다",
"date": "11/29/2017",
"기간": "1.5"
}
]
}
Java 코드에서 전체 텍스트 검색 호출하기
코드에서 Couchbase 버킷에 연결하기
Spring 부팅은 특정 Couchbase 환경 세부 사항을 Spring 구성으로 지정할 수 있도록 하여 Couchbase 환경에 편리하게 연결할 수 있는 방법을 제공합니다. 일반적으로 application.properties 파일에 다음 매개 변수를 지정합니다:
spring.couchbase.bootstrap-hosts=127.0.0.1
spring.couchbase.bucket.name=conference
spring.couchbase.bucket.password=
여기서는 노트북에서 Couchbase Server를 실행하고 있으므로 로컬 호스트 IP를 지정했습니다. 참고: 컨테이너의 IP 주소를 제공하면 Couchbase를 Docker 컨테이너로 실행할 수 있습니다.
버킷 이름은 Couchbase 콘솔을 사용하여 만든 버킷의 이름과 일치해야 합니다.
IP 주소 클러스터를 부트스트랩 호스트로 지정할 수도 있습니다. Spring은 Couchbase를 실행하는 모든 노드가 있는 Couchbase 환경 클러스터를 제공합니다. 버킷을 생성할 때 비밀번호를 설정했다면 비밀번호도 지정할 수 있지만, 그렇지 않은 경우 해당 필드를 비워둡니다. 저희의 경우에는 비워 두었습니다.
원하는 버킷에 대해 쿼리를 실행하려면 먼저 버킷 객체에 대한 참조가 있어야 합니다. 그리고 스프링 카우치베이스 구성은 뒤에서 모든 무거운 작업을 처리합니다. Spring 서비스 빈 클래스 내의 생성자에서 버킷을 주입하기만 하면 됩니다.
코드는 다음과 같습니다:
서비스
공용 클래스 FullTextSearchService {
비공개 버킷 버킷;
public FullTextSearchService(버킷 버킷) {
this.bucket = 버킷;
log.info("******** 버킷 :: = " + bucket.name());
}
public void findByTextMatch(String searchText) throws Exception {
검색 쿼리 결과 결과 = getBucket().query(
새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, 검색 쿼리.일치문구(검색 텍스트)).필드("요약"));
for (SearchQueryRow hit : result.hits()) {
log.info("****** score := " + hit.score() + " and content := "
+ bucket.get(hit.id()).content().get("title"));
}
}
또한 일부 CouchbaseEnvironment 설정 매개변수를 사용자 정의할 수도 있습니다. 사용자 지정할 수 있는 매개변수의 자세한 목록은 다음을 참조하세요. 참조 지침:
이 시점에서 다음에서 서비스를 호출할 수 있습니다. CommandLineRunner 콩.
@Configuration
public 클래스 FtsRunner는 CommandLineRunner를 구현합니다.
오토와이어드
풀텍스트검색서비스 fts;
오버라이드
public void run(String... arg0) throw Exception {
fts.findByTextMatch("개발자");
}
}
전체 텍스트 검색 서비스 사용
Java SDK의 핵심인 Couchbase는 다음과 같은 기능을 제공합니다. 쿼리() 메서드를 지정된 버킷에 쿼리하는 방법으로 사용할 수 있습니다. N1QL 쿼리 또는 쿼리 보기에 익숙한 경우에는 쿼리() 메서드는 비슷한 패턴을 제공하지만, 검색의 유일한 차이점은 검색 쿼리 매개 변수를 인수로 전달합니다.
다음은 '회의' 버킷에서 주어진 텍스트를 검색하는 코드입니다. getBucket() 메서드는 버킷의 핸들을 반환합니다.
검색 쿼리를 만들 때 위의 설정 섹션에서 만든 인덱스의 이름을 제공해야 합니다. 여기서는 "conference-search"를 인덱스로 사용하고 있으며, 이는 FtsConstants.FTS_IDX_CONF에 지정되어 있습니다. 참고로 앱의 전체 소스 코드는 GitHub에 업로드되어 있으며 다운로드할 수 있습니다. 링크는 게시물 끝에 있습니다.
public static void findByTextMatch(String searchText) throws Exception {
검색 쿼리 결과 결과 = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, 검색 쿼리.matchPhrase(searchText)).fields("summary"));
log.info("****** 총 조회수 :="+ result.hits().size());
for (SearchQueryRow hit : result.hits()) {
log.info("****** score := " + hit.score() + " and content := "+ bucket.get(hit.id()).content().get("title"));
}
}
위의 코드는 버킷에 있는 문서의 '요약' 필드를 사용하여 matchPhrase(searchText) 메서드를 사용합니다.
이 코드는 간단한 호출로 호출됩니다:
findByTextMatch("developer");
따라서 전체 텍스트 검색은 회의 버킷의 요약 필드에 '개발자'라는 텍스트가 있는 모든 문서를 반환해야 합니다. 다음은 출력 결과입니다:
버킷 회의 열기
****** 총 조회수 := 1
****** 점수 := 0.036940739161339185 및 콘텐츠 := Devoxx UK
총 적중 수는 발견된 총 경기 수를 나타냅니다. 여기서는 1이며 해당 일치 항목의 해당 점수도 찾을 수 있습니다. 이 코드는 전체 문서를 인쇄하지 않고 회의 제목만 출력합니다. 원하는 경우 문서의 다른 속성도 인쇄할 수 있습니다.
다음에 설명하는 다른 검색 쿼리 사용 방법도 있습니다.
퍼지 텍스트 검색
최대 퍼지 쿼리를 지정하여 퍼지 쿼리를 수행할 수 있습니다. 레벤슈타인 거리 를 용어에 허용할 최대 퍼지()로 설정합니다. 기본 퍼지니스는 2입니다.
예를 들어, 'sysops'가 '주제' 중 하나인 컨퍼런스를 찾고 싶다고 가정해 보겠습니다. 위의 데이터 집합을 보면 어떤 컨퍼런스에도 "sysops"라는 주제가 없다는 것을 알 수 있습니다. 가장 가까운 일치 항목은 "devops"이지만, 이는 3레벤슈타인 거리 떨어져 있습니다. 따라서 퍼지 1 또는 2를 사용하여 다음 코드를 실행하면 아무런 결과도 반환되지 않아야 하지만 그렇지 않습니다.
검색 쿼리 결과 결과 퍼지 = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, 검색 쿼리.일치(searchText).퍼지)(2)).fields("topics"));
log.info("****** 총 조회수 :="+ resultFuzzy.hits().size());
for (SearchQueryRow hit : resultFuzzy.hits()) {
log.info("****** score := " + hit.score() + " and content := "+ bucket.get(hit.id()).content().get("topics"));
}
findByTextFuzzy("sysops"); 은 다음과 같은 출력을 제공합니다:
총 조회수 := 0
이제 퍼지를 "3"으로 변경하고 동일한 코드를 다시 호출하면 문서가 반환됩니다. 여기 있습니다:
****** 총 조회수 := 1
****** score := 0.016616112953992054 and content := ["containers","devops","마이크로서비스","제품 개발","가상화"]
"devops"는 퍼지 3의 "sysops"와 일치하므로 검색에서 문서를 찾을 수 있습니다.
정규식 쿼리
SearchQuery를 사용하여 정규식 기반 쿼리를 수행할 수 있습니다. 다음 코드는 RegExpQuery 를 클릭해 제공된 패턴에 따라 '주제'를 검색합니다.
RegexpQuery rq = 새 RegexpQuery(regexp).field("topics");
검색 쿼리 결과 결과RegExp = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, rq));
log.info("****** 총 조회수 :="+ resultRegExp.hits().size());
for (SearchQueryRow hit : resultRegExp.hits()) {
log.info("****** score := " + hit.score() + " and content := "+ bucket.get(hit.id()).content().get("topics"));
}
로 호출하면
findByRegExp("[a-z]*\\s*reality");
다음 2개의 문서를 반환합니다:
****** 총 조회수 := 2
****** score := 0.11597946228887497 and content := ["aws","서버리스","마이크로서비스","클라우드 컴퓨팅","증강 현실“]
****** score := 0.1084888528694293 and content := ["클라우드","사물인터넷","빅데이터","머신러닝","가상 현실“]
접두사로 쿼리하기
Couchbase를 사용하면 텍스트 요소의 '접두사'를 기반으로 쿼리할 수 있습니다. 이 API는 지정된 접두사로 시작하는 텍스트를 검색합니다. 이 코드는 문서의 '요약' 필드에서 제공된 접두사가 있는 텍스트를 검색하는 것으로 사용이 간단합니다.
PrefixQuery pq = new PrefixQuery(prefix).field("summary");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, pq).fields("summary"));
log.info("****** 총 조회수 :="+ resultPrefix.hits().size());
for (SearchQueryRow hit : resultPrefix.hits()) {
log.info("****** score := " + hit.score() + " and content := "+ bucket.get(hit.id()).content().get("summary"));
}
코드를 findByPrefix("micro")로 호출하는 경우;
다음과 같은 출력이 표시됩니다:
****** 총 조회수 := 1
****** 점수 := 0.08200986407165835 및 내용 := 아마존 웹 서비스 재인벤트 2017은 더 큰 장소, 더 많은 세션 및 다음과 같은 기술에 초점을 맞출 것을 약속합니다. 마이크로서비스 및 람다.
구문으로 쿼리하기
다음 코드를 사용하면 텍스트의 구문을 쿼리할 수 있습니다.
매치프레이즈 쿼리 mpq = 새 매치프레이즈 쿼리(matchPhrase).field("speakers.talk");
검색 쿼리 결과 결과 프리픽스 = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, mpq).fields("speakers.talk"));
log.info("****** 총 조회수 :="+ resultPrefix.hits().size());
for (SearchQueryRow hit : resultPrefix.hits()) {
log.info("****** score := " + hit.score() + " and content := "+ bucket.get(hit.id()).content().get("title") + " speakers = "+bucket.get(hit.id()).content().get("speakers")");
}
여기서 쿼리는 'speakers.talk' 필드에서 구문을 찾고 일치하는 구문을 찾으면 반환합니다.
위 코드의 샘플 호출은
findByMatchPhrase("카우치베이스가 있는 도커")는 다음과 같은 예상 출력을 제공합니다:
****** 총 조회수 := 1
****** score := 0.25054427342401087 and content := DockerCon speakers = [{"duration":"2″,"date":"04/18/2017″,"talk":"카우치베이스가 있는 도커","이름":"Arun Gupta"},{"지속 시간":"2″,"날짜":"04/19/2017″,"토크":"오픈소스","이름":"Laura Frank"}]
범위 쿼리
전체 텍스트 검색은 숫자 범위나 날짜 범위 등 범위 기반 검색 시에도 매우 유용합니다. 예를 들어, 참석자 수가 특정 범위에 속하는 컨퍼런스를 찾고자 하는 경우 다음과 같이 쉽게 검색할 수 있습니다,
findByNumberRange(5000, 30000);
여기서 첫 번째 인수는 범위의 최소값이고 두 번째 인수는 범위의 최대값입니다.
트리거되는 코드는 다음과 같습니다:
NumericRangeQuery nrq = new NumericRangeQuery().min(min).max(max).field("attendees");
검색 쿼리 결과 결과Prefix = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, nrq).fields("title", "attendees", "location"));
log.info("****** 총 조회수 :="+ resultPrefix.hits().size());
for (SearchQueryRow hit : resultPrefix.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** score := " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " location := " + row.content().get("location"));
}
그리고 다음과 같은 출력을 제공합니다. 제공된 범위 사이에 해당하는 참석자가 있는 회의가 반환됩니다.
****** 총 조회수 := 2
****** 점수 := 5.513997563179222E-5 및 제목 := 도커콘 참석자 := 20000명 위치 := 오스틴
****** 점수 := 5.513997563179222E-5 및 제목 := Devoxx UK 참석자 := 10000 위치 := 벨기에
조합 쿼리
카우치베이스 전체 텍스트 검색 서비스를 사용하면 필요에 따라 쿼리를 조합하여 사용할 수 있습니다. 이를 시연하기 위해 먼저 두 개의 인수를 제공하여 API를 호출해 보겠습니다.
findByMatchCombination("aws", "containers");
여기서 클라이언트 코드는 "aws"와 "컨테이너"를 기반으로 조합 검색을 사용하려고 합니다. 이제 쿼리 API를 살펴보겠습니다.
매치 쿼리 mq1 = 새 매치 쿼리(text1).field("topics");
매치 쿼리 mq2 = 새 매치 쿼리(text2).field("topics");
검색 쿼리 결과 match1Result = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, mq1).fields("title", "참석자", "위치", "주제"));
log.info("****** match1의 총 조회수 :="+ match1Result.hits().size());
for (SearchQueryRow hit : match1Result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** 경기 1의 점수 := " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
검색 쿼리 결과 match2Result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mq2).fields("title", "attendees", "location", "topics"));
log.info("****** match2의 총 조회수 :="+ match2Result.hits().size());
for (SearchQueryRow hit : match2Result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** 경기 2의 점수:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
ConjunctionQuery conjunction = 새로운 ConjunctionQuery(mq1, mq2);
검색 쿼리 결과 결과 = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, 결합).fields("title", "참석자", "위치", "주제"));
log.info("****** 접속 쿼리의 총 조회 수 :="+ result.hits().size());
for (SearchQueryRow hit : result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** 접속어 쿼리 점수:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
분리 쿼리 dis = 새로운 분리 쿼리(mq1, mq2);
검색 쿼리 결과 결과Dis = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, dis).fields("title", "참석자", "위치", "주제"));
log.info("****** 분리 쿼리의 총 조회 수 :="+ resultDis.hits().size());
for (SearchQueryRow hit : resultDis.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** 분리 쿼리 점수:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
부울 쿼리 bool = 새 부울 쿼리().must(mq1).mustNot(mq2);
검색 쿼리 결과 결과Bool = getBucket().query(새로운 검색 쿼리(FtsConstants.FTS_IDX_CONF, bool).fields("title", "참석자", "위치", "주제"));
log.info("****** booelan 쿼리에 대한 총 조회수 :="+ resultBool.hits().size());
for (SearchQueryRow hit : resultBool.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** scores for resultBool query:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
먼저, 텍스트를 기반으로 개별 일치 항목을 찾습니다. 회의 주제 중 하나로 "aws"와 일치하는 결과 집합 문서를 찾습니다. 같은 방식으로 "컨테이너"를 주제로 하는 문서도 찾습니다.
다음으로 개별 결과를 결합하여 조합 쿼리를 생성하기 시작합니다.
접속사 쿼리
연결 쿼리는 'aws'와 '컨테이너'가 모두 주제로 나열된 일치하는 모든 컨퍼런스를 반환합니다. 현재 데이터 세트에는 아직 그러한 컨퍼런스가 없으므로 예상대로 쿼리를 실행하면 일치하는 문서가 반환되지 않습니다.
****** match1의 총 조회 수 := 1 - "aws"와 일치합니다.
****** 경기 1 점수 := 0.11597946228887497 및 제목 := ReInvent 참석자 := 30000 주제 := ["aws","서버리스","마이크로서비스","클라우드 컴퓨팅","증강 현실"]
****** match2의 총 조회 수 := 1 - "컨테이너"와 일치합니다.
****** 경기 점수 2:= 0.12527214351929328 및 제목 := DockerCon 참석자 := 20000 주제 := ["컨테이너","devops","마이크로서비스","제품 개발","가상화"]
****** 연결 쿼리의 총 조회 수 := 0
분리 쿼리
분리 쿼리는 후보 쿼리 중 하나라도 일치하는 항목이 있으면 일치하는 모든 컨퍼런스를 반환합니다. 각 개별 일치 쿼리는 각각 하나의 컨퍼런스를 반환하므로 연결 해제 쿼리를 실행하면 두 결과를 모두 반환합니다.
****** 분리 쿼리의 총 조회 수 := 2
****** 분리 쿼리 점수 := 0.018374455634478874 및 제목 := 도커콘 참석자 := 20000 주제 := ["컨테이너","devops","마이크로서비스","제품 개발","가상화"]
****** 분리 쿼리 점수 := 0.01701143945069833 및 제목 := ReInvent 참석자 := 30000 주제 := ["aws","서버리스","마이크로서비스","클라우드 컴퓨팅","증강 현실"]
부울 쿼리
부울 쿼리를 사용하면 다양한 조합의 일치 쿼리를 결합할 수 있습니다. 예를 들어, 부울 쿼리 bool = 새로운 부울 쿼리().must(mq1).mustNot(mq2)는 첫 번째 용어 쿼리 결과인 mq1과 일치해야 하는 모든 회의를 반환하는 동시에 mq2와 일치해서는 안 되는 회의도 반환합니다. 조합을 뒤집을 수 있습니다.
코드의 출력은 다음과 같습니다:
****** 부란 쿼리의 총 조회 수 := 1
****** resultBool 쿼리 점수:= 0.11597946228887497 및 title := ReInvent 참석자 := 30000 주제 := ["aws","서버리스","마이크로서비스","클라우드 컴퓨팅","증강 현실"]
"aws"라는 주제가 있고(참고로 mq1과 동일) "containers"라는 주제가 없는(즉, mq2) 컨퍼런스를 반환합니다. 이 두 가지 조건을 모두 충족하는 유일한 회의는 제목이 "ReInvent"이고 출력으로 반환됩니다.
이 게시물이 도움이 되셨기를 바랍니다. 소스 코드는 다음에서 찾을 수 있습니다. 온라인. Couchbase 전체 텍스트 검색 서비스에 대한 일반적인 아이디어는 다음을 참조하세요. 블로그 게시물 에서 유용한 인사이트를 확인하세요: