카우치베이스 N1QL 은 유연한 데이터 모델을 통해 분산 데이터의 인덱스별로 JSON에 대한 집계 SQL을 제공하도록 설계된 최신 쿼리 처리 엔진입니다. 최신 데이터베이스는 대규모 클러스터에 배포됩니다. JSON을 사용하면 유연한 데이터 모드를 제공합니다. N1QL은 쿼리 처리를 더 쉽게 하기 위해 향상된 JSON용 인덱스별 그룹 SQL을 지원합니다.
애플리케이션과 데이터베이스 드라이버는 클러스터에서 사용 가능한 쿼리 노드 중 하나에 N1QL 쿼리를 제출합니다. 쿼리 노드는 쿼리를 분석하고 기본 개체에 대한 메타데이터를 사용하여 최적의 실행 계획을 파악한 다음 실행합니다. 실행 중에 쿼리에 따라 해당 인덱스를 사용하여 쿼리 노드는 인덱스 및 데이터 노드와 함께 작동하여 데이터를 검색하고 계획된 작업을 수행합니다. Couchbase는 모듈식 클러스터형 데이터베이스이므로 성능 및 가용성 목표에 맞게 데이터, 인덱스, 쿼리 서비스를 확장할 수 있습니다.
Couchbase 5.5 이전에는 GROUP BY 및/또는 집계가 포함된 쿼리가 인덱스에 포함되는 경우에도 쿼리가 인덱서에서 모든 관련 데이터를 가져와 쿼리 엔진 내에서 데이터의 그룹화/집계를 수행했습니다.
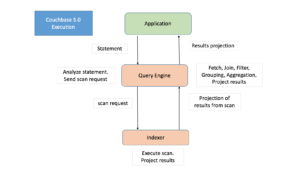
범위 스캔 외에도 그룹화 및 집계를 수행하도록 인덱서에게 지능적으로 요청하도록 개선된 Couchbase 5.5 쿼리 플래너 인덱스 커버링용. 인덱서가 그룹화, 카운트(), 합계(), 최소(), 최대(), 평균() 및 관련 연산을 즉시 수행할 수 있도록 개선되었습니다.
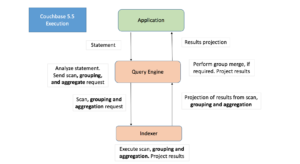
이를 위해서는 사용자 쿼리를 변경할 필요는 없지만 쿼리를 커버하고 인덱스 키를 정렬할 수 있는 좋은 인덱스 설계가 필요합니다. 모든 쿼리가 이 최적화의 혜택을 받는 것은 아니며, 모든 인덱스가 모든 그룹화 및 집계 작업을 가속화할 수 있는 것도 아닙니다. 올바른 패턴을 이해하면 인덱스와 쿼리를 설계하는 데 도움이 됩니다. 글로벌 보조 인덱스에 대한 인덱스 그룹화 및 집계는 두 스토리지 엔진 모두에서 지원됩니다: 표준 GSI와 메모리 최적화 GSI(MOI). 인덱스 그룹화 및 집계는 Enterprise Edition에서만 지원됩니다.
인덱서에 의해 GROUP BY 및 집계가 수행되는 이 감소 단계는 데이터 전송 및 디스크 I/O의 양을 줄여줍니다:
- 쿼리 응답 시간 개선
- 리소스 활용도 향상
- 짧은 지연 시간
- 높은 확장성
- 낮은 총 소유 비용
성능
인덱스 그룹화 및 집계는 쿼리 성능을 크게 개선하고 지연 시간을 크게 줄일 수 있습니다. 다음 표에는 몇 가지 쿼리 지연 시간 측정 샘플이 나와 있습니다.
색인 :
|
1 |
CREATE INDEX idx_ts_type_country_city ON `travel-sample` (type, country, city); |
| 쿼리 | 설명 | 5.0 지연 시간 | 5.5 지연 시간 |
SELECT t.type, COUNT(type) AS cnt FROM 여행 샘플 AS t 여기서 t.type이 NULL이 아닌 경우 GROUP BY t.type; |
|
230ms | 13ms |
SELECT t.type, COUNT(1) AS cnt, COUNT(DISTINCT city) AS cntdcity FROM 여행 샘플 AS t WHERE t.type IN ["hotel","airport"] GROUP BY t.type, t.country; |
|
40ms | 7ms |
SELECT t.country, COUNT(city) AS cnt FROM 여행 샘플 AS t 어디 t.type = "airport" 국가별로 그룹화; |
|
25ms | 3ms |
SELECT t.city, cnt FROM 여행 샘플 AS t 여기서 t.type이 NULL이 아닌 경우 t.city 기준 그룹화 cnt = COUNT(city) cnt > 0 인 경우 ; |
|
300ms | 160ms |
인덱스 그룹화 및 집계 개요
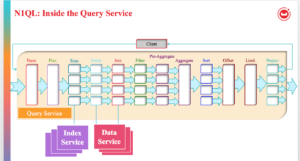
위 그림은 SELECT 쿼리가 결과를 반환하기 위해 거치는 모든 가능한 단계를 보여줍니다. 필터링 프로세스는 초기 키스페이스를 가져와 쿼리가 관심 있는 문서의 최적 하위 집합을 생성합니다. 가능한 한 가장 작은 하위 집합을 생성하기 위해 인덱스를 사용하여 가능한 한 많은 술어를 적용합니다. 쿼리 술어는 관심 있는 데이터의 하위 집합을 나타냅니다. 쿼리 계획 단계에서 사용할 인덱스를 선택합니다. 그런 다음 각 인덱스에 대해 각 인덱스가 적용할 술어를 결정합니다. 쿼리 술어는 쿼리 계획에서 범위 스캔으로 변환되어 인덱서에게 전달됩니다.
쿼리에 JOIN이 없고 인덱스에 포함되는 경우 가져오기 및 조인 단계를 모두 제거할 수 있습니다.
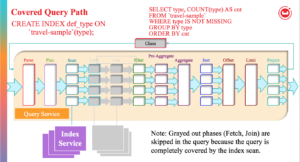
모든 술어가 범위 스캔으로 정확히 변환되면 필터 단계도 제거할 수 있습니다. 이 상황에서는 스캔과 집계가 나란히 있으며, 인덱서에는 집계 기능이 있으므로 해당 단계는 인덱서 노드에서 수행할 수 있습니다. 경우에 따라 정렬, 오프셋, 제한 단계도 인덱서 노드에서 수행할 수 있습니다.
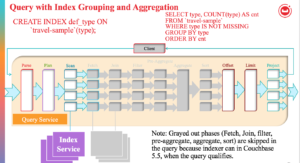
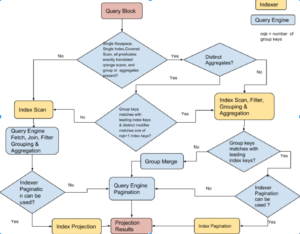
다음 흐름도는 쿼리 플래너가 쿼리의 각 쿼리 블록에 대해 인덱스 집계를 수행하기로 결정하는 방법을 설명합니다. 인덱스 집계가 불가능한 경우 쿼리 엔진에서 집계가 수행됩니다.
예를 들어, GROUP BY를 사용할 때의 이전 성능과 현재 성능을 비교하고 Couchbase에 정의된 인덱스를 사용하는 다음 쿼리의 EXPLAIN 계획을 살펴봅시다. 여행 샘플 버킷:
|
1 |
CREATE INDEX `def_type` ON `travel-sample`(`type`); |
쿼리를 생각해 보세요:
|
1 2 3 4 |
SELECT type, COUNT(type) FROM `travel-sample` WHERE type IS NOT MISSING GROUP BY type; |
Couchbase 버전 5.5 이전에는 이 쿼리 엔진이 인덱서에서 관련 데이터를 가져오고 데이터의 그룹화 및 집계는 쿼리 엔진 내에서 수행되었습니다. 이 간단한 쿼리는 약 250ms가 소요됩니다.

이제 Couchbase 버전 5.5에서 이 쿼리는 동일한 def_type 인덱스를 사용하지만 20ms 이내에 실행됩니다. 아래 설명에서 인덱스 스캔 단계에서 그룹화 및 집계도 수행하기 때문에 단계 수가 줄어들고 인덱스 스캔 후 그룹화 단계가 생략된 것을 볼 수 있습니다.

데이터 및 쿼리 복잡성이 증가함에 따라 성능 이점(지연 시간 및 처리량 모두)도 증가합니다.
인덱스 그룹화 및 집계에 대한 설명 이해
쿼리에 대한 설명을 살펴봅니다:
|
1 |
EXPLAIN SELECT type, COUNT(type) FROM `travel-sample` WHERE type IS NOT MISSING GROUP BY type;{ |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((meta(`travel-sample`).`id`))", "cover (count(cover ((`travel-sample`.`type`))))" ], "index": "def_type", "index_group_aggs": { "aggregates": [ { "aggregate": "COUNT", "depends": [ 0 ], "expr": "cover ((`travel-sample`.`type`))", "id": 2, "keypos": 0 } ], "depends": [ 0 ], "group": [ { "depends": [ 0 ], "expr": "cover ((`travel-sample`.`type`))", "id": 0, "keypos": 0 } ] }, "index_id": "b948c92b44c2739f", "index_projection": { "entry_keys": [ 0, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 1, "low": "null" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`type`))" }, { "expr": "cover (count(cover ((`travel-sample`.`type`))))" } ] }, { "#operator": "FinalProject" } ] } } ] }, "text": "SELECT type, COUNT(type) FROM `travel-sample` WHERE type IS NOT MISSING GROUP BY type;" } |
인덱스 스캔 섹션에 "index_group_aggs"가 표시됩니다(예: "#operator": "IndexScan3"). "index_group_aggs"가 누락된 경우 쿼리 서비스가 그룹화 및 집계를 수행 중입니다. 현재 쿼리가 인덱스 그룹화 및 집계를 사용하고 있고 그룹화 및 집계에 필요한 모든 관련 정보 인덱서를 가지고 있는 경우. 다음 표는 index_group_aggs 객체의 다양한 정보를 해석하는 방법을 설명합니다.
| 필드 이름 | 설명 | 예제의 회선 번호 | 예제에서 텍스트 설명하기 |
| 집계 | 집계 개체의 배열이며 각 개체는 하나의 집계를 나타냅니다. 이 항목이 없으면 쿼리에 그룹 기준만 존재한다는 의미입니다. | 14-24 | 집계 |
| 집계 | 집계 작업(최대/최소/합계/카운트/카운트). | 16 | COUNT |
| distinct | 집계 수정자는 DISTINCT입니다. | - | 거짓(참일 때만 표시) |
| 의존 | 집계 표현식이 의존하는 인덱스 키 위치(0으로 시작) 목록입니다. | 17-19 | 0 (유형이 def_type 인덱스의 0번째 인덱스 키이므로) |
| expr | 집계 표현식 | 20 | 커버 ((여행 샘플.유형)) |
| id | 내부적으로 부여된 고유 ID로 다음에서 사용됩니다. index_projection | 21 | 2 |
| 키포스 | 인덱스 키 위치 또는 expr 필드에서 표현식을 사용하도록 지시하는 표시기입니다.
|
22 | 0 (유형이 def_type 인덱스의 0번째 인덱스 키이므로) |
| 의존 | 그룹/집계 표현식이 종속되는 인덱스 키 위치 목록(통합 목록) | 25-27 | 0 |
| 그룹 | GROUP BY 객체의 배열이며 각 객체는 하나의 그룹 키를 나타냅니다. 이 항목이 없으면 쿼리에 GROUP BY 절이 없다는 의미입니다. | 28-37 | 그룹 |
| 의존 | 그룹 표현식이 의존하는 인덱스 키 위치 목록(0으로 시작). | 30-32 | 0
(유형이 def_type 인덱스의 인덱스 키의 0번째 키이므로) |
| expr | 그룹 표현식입니다. | 33 | 커버 ((여행 샘플.유형)) |
| id | 내부적으로 부여된 고유 ID로 다음에서 사용됩니다. index_projection. | 34 | 0 |
| 키포스 | 인덱스 키 위치 또는 expr 필드에서 표현식을 사용하도록 지시하는 표시기입니다.
|
35 | 0 (유형이 def_type 인덱스의 0번째 인덱스 키이므로) |
커버 필드는 배열이며 모든 인덱스 키, 문서 키(META().id), 인덱스 키와 정확히 일치하지 않는 그룹 키 표현식(id별로 정렬), id별로 정렬된 집계가 있습니다. 또한 "Index_projection"은 모든 그룹/집계 ID를 갖습니다.
|
1 2 3 4 5 |
"covers": [ "cover ((`travel-sample`.`type`))", ← Index key (0) "cover ((meta(`travel-sample`).`id`))", ← document key (1) "cover (count(cover ((`travel-sample`.`type`))))" ← aggregate (2) ] |
위의 대소문자 그룹 표현식 유형 는 인덱스의 인덱스 키와 동일합니다. def_type. 두 번 포함되지 않습니다.
세부 정보 인덱스 그룹화 및 집계
예제를 통해 인덱스 그룹화 및 집계가 어떻게 작동하는지 보여드리겠습니다. 예제를 따르려면 다음과 같이 하세요. "기본" 버킷을 생성하고 다음 문서를 삽입하세요:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO default (KEY,VALUE) VALUES ("ga0001", {"c0":1, "c1":10, "c2":100, "c3":1000, "c4":10000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0002", {"c0":1, "c1":20, "c2":200, "c3":2000, "c4":20000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0003", {"c0":1, "c1":10, "c2":300, "c3":3000, "c4":30000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0004", {"c0":1, "c1":20, "c2":400, "c3":4000, "c4":40000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0005", {"c0":2, "c1":10, "c2":100, "c3":5000, "c4":50000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0006", {"c0":2, "c1":20, "c2":200, "c3":6000, "c4":60000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0007", {"c0":2, "c1":10, "c2":300, "c3":7000, "c4":70000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0008", {"c0":2, "c1":20, "c2":400, "c3":8000, "c4":80000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}); |
예 1: 선행 인덱스 키를 기준으로 그룹화
다음 쿼리와 인덱스를 고려해 보겠습니다:
|
1 2 3 4 5 6 7 8 |
SELECT d.c0 AS c0, d.c1 AS c1, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c0, d.c1 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2; |
필수 색인:
|
1 |
CREATE INDEX idx1 ON default(c0, c1, c2, c3, c4); |
쿼리에는 GROUP BY와 여러 집계가 있고 일부 집계에는 DISTINCT 수정자가 있습니다. 쿼리는 인덱스 idx1로 커버될 수 있으며 술어(d.c0 > 0)는 정확한 범위 스캔으로 변환되어 인덱스 스캔으로 전달될 수 있습니다. 따라서 인덱스와 쿼리 조합은 인덱스 그룹화 및 집계를 한정합니다.
인덱스는 인덱스 키 정의 순서에 따라 자연스럽게 정렬되고 그룹화됩니다. 위의 쿼리에서 GROUP BY 키(d.c0, d.c1)는 인덱스의 선행 키(c0, c1)와 정확히 일치합니다. 따라서 인덱스는 각 그룹 데이터를 함께 가지고 있으며, 인덱서는 그룹당 하나의 행, 즉 전체 집계를 생성합니다. 또한 쿼리에는 DISTINCT 수정자가 있는 집계가 있고, 그룹 키 수에 1을 더한 수보다 작거나 같은 위치의 인덱스 키 중 하나와 정확히 일치합니다(즉, 그룹 키가 2개이고, 인덱스 키 뒤에 오는 그룹 키와 DISTINCT 수정자가 정렬 없이 적용 가능하므로 0,1,2 위치의 인덱스 키 중 어느 하나가 될 수 있음). 따라서 위의 쿼리는 그룹화 및 집계를 처리하는 인덱서에 적합합니다.
선행 인덱스 키 중 하나가 누락되어 그룹화되고 동일성 술어가 있는 경우, 그룹 키에 암시적으로 존재하는 인덱스 키를 처리하여 특수 최적화가 수행되고 전체 집계가 가능한지 여부를 결정합니다. 파티션 인덱스의 경우 전체 집계를 생성하려면 모든 파티션 키가 그룹 키에 존재해야 합니다.
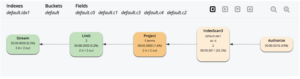
위의 그래픽 실행 트리는 인덱스 스캔(IndexScan3)이 스캔 및 인덱스 그룹화 집계를 수행하는 것을 보여줍니다. 인덱스 스캔의 결과가 투영됩니다.
텍스트 기반 설명 을 살펴 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 |
{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "as": "d", "covers": [ "cover ((`d`.`c0`))", "cover ((`d`.`c1`))", "cover ((`d`.`c2`))", "cover ((`d`.`c3`))", "cover ((`d`.`c4`))", "cover ((meta(`d`).`id`))", "cover (count(distinct cover ((`d`.`c2`))))", "cover (countn(cover ((`d`.`c4`))))", "cover (sum(cover ((`d`.`c3`))))", "cover (sum(cover ((`d`.`c4`))))" ], "index": "idx1", "index_group_aggs": { "aggregates": [ { "aggregate": "COUNT", "depends": [ 2 ], "distinct": true, "expr": "cover ((`d`.`c2`))", "id": 6, "keypos": 2 }, { "aggregate": "COUNTN", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 7, "keypos": 4 }, { "aggregate": "SUM", "depends": [ 3 ], "expr": "cover ((`d`.`c3`))", "id": 8, "keypos": 3 }, { "aggregate": "SUM", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 9, "keypos": 4 } ], "depends": [ 0, 1, 2, 3, 4 ], "group": [ { "depends": [ 0 ], "expr": "cover ((`d`.`c0`))", "id": 0, "keypos": 0 }, { "depends": [ 1 ], "expr": "cover ((`d`.`c1`))", "id": 1, "keypos": 1 } ] }, "index_id": "d06df7c5d379cd5", "index_order": [ { "keypos": 0 }, { "keypos": 1 } ], "index_projection": { "entry_keys": [ 0, 1, 6, 7, 8, 9 ] }, "keyspace": "default", "limit": "2", "namespace": "default", "offset": "1", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "0" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "maxParallelism": 1, "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialProject", "result_terms": [ { "as": "c0", "expr": "cover ((`d`.`c0`))" }, { "as": "c1", "expr": "cover ((`d`.`c1`))" }, { "as": "sumc3", "expr": "cover (sum(cover ((`d`.`c3`))))" }, { "as": "avgc4", "expr": "(cover (sum(cover ((`d`.`c4`)))) / cover (countn(cover ((`d`.`c4`)))))" }, { "as": "dcountc2", "expr": "cover (count(distinct cover ((`d`.`c2`))))" } ] }, { "#operator": "FinalProject" } ] } } ] }, { "#operator": "Limit", "expr": "2" } ] }, "text": "SELECT d.c0 AS c0, d.c1 AS c1, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d\nWHERE d.c0 > 0 GROUP BY d.c0, d.c1 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2;" } |
- 인덱스 그룹화 및 집계를 사용하는 쿼리를 보여주는 IndexScan 섹션의 "index_group_aggs"(24-89줄)(예: "#operator": "IndexScan3")는 인덱스 그룹화 및 집계를 보여줍니다.
- 쿼리가 인덱스 그룹화 및 집계를 사용하는 경우 술어는 정확히 범위 스캔으로 변환되어 스팬의 일부로 인덱스 스캔으로 전달되므로 설명에 필터 연산자가 없습니다.
- 키별 그룹은 선행 인덱스 키와 정확히 일치하므로 인덱서는 전체 집계를 생성합니다. 따라서 쿼리 서비스에서도 그룹화를 제거합니다(설명에 InitialGroup, IntermediateGroup, FinalGroup 연산자가 없습니다).
- 인덱서는 모든 그룹 키와 집계를 포함하여 "index_projection"(99-107줄)을 투사합니다.
- 쿼리 ORDER BY가 선행 인덱스 키와 일치하고 GROUP BY가 선행 인덱스 키에 있으면 인덱스 순서를 사용할 수 있습니다. 이는 설명(91-98줄)에서 찾을 수 있으며 "#operator"를 사용하지 않습니다: 164-165줄 사이에 "Order".
- 쿼리는 인덱스 순서를 사용할 수 있고 쿼리에 HAVING 절이 없으므로 "오프셋" 및 "제한" 값을 인덱서에게 전달할 수 있습니다.
- 이는 112, 110번 라인에서 찾을 수 있습니다. "오프셋"은 "#operator"가 표시되지 않는 경우에만 적용할 수 있습니다: 164-165줄 사이에 "오프셋"을 적용하지만 "제한"을 다시 적용하는 것은 불가능합니다. 이는 165-168줄에서 확인할 수 있습니다.
- 쿼리에 AVG(x)가 포함된 경우 SUM(x)/COUNTN(x)로 재작성되었습니다. COUNTN(x)는 x가 숫자 값일 때만 계산됩니다.
예 2: 선행 인덱스 키, LETTING, HAVING을 기준으로 그룹화하기
다음 쿼리와 인덱스를 고려해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT d.c0 AS c0, d.c1 AS c1, sumc3 AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c0, d.c1 LETTING sumc3 = SUM(d.c3) HAVING sumc3 > 0 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2; |
필수 색인:
|
1 |
CREATE INDEX idx1 ON default(c0, c1, c2, c3, c4); |
위의 쿼리는 예제 1과 유사하지만 LETTING, HAVING 절이 있습니다. 인덱서에서는 이를 처리할 수 없으므로 그룹화 및 집계 후 쿼리 서비스에서 LETTING, HAVING 절을 적용합니다. 따라서 실행 트리에서 IndexScan3 뒤에 Let, Filter 연산자가 표시됩니다. Having 절은 필터이므로 "오프셋", "제한" 항목은 인덱서에 푸시할 수 없고 쿼리 서비스에서 적용해야 하지만 인덱스 순서는 계속 사용할 수 있습니다.

예 3: 선행이 아닌 인덱스 키를 기준으로 그룹화하기
다음 쿼리와 인덱스를 고려해 보겠습니다:
|
1 2 3 4 5 6 7 8 |
SELECT d.c1 AS c1, d.c2 AS c2, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(d.c2) AS countc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c1, d.c2 ORDER BY d.c1, d.c2 OFFSET 1 LIMIT 2; |
필수 색인:
|
1 |
CREATE INDEX idx1 ON default(c0, c1, c2, c3, c4); |
쿼리에는 GROUP BY와 여러 집계가 있습니다. 쿼리는 인덱스 idx1에 포함될 수 있으며 술어(d.c0 > 0)는 정확한 범위 스캔으로 변환되어 인덱스 스캔으로 전달될 수 있습니다. 따라서 인덱스와 쿼리 조합은 인덱스 그룹화 및 집계를 한정합니다.
위의 쿼리에서 GROUP BY 키(d.c1, d.c2)는 인덱스의 선행 키(c0, c1)와 일치하지 않습니다. 그룹이 인덱스 전체에 흩어져 있습니다. 따라서 인덱서는 각 그룹당 여러 행을 생성합니다(즉, 부분 집계). 부분 집계 쿼리 서비스가 그룹 병합을 수행하는 경우, 쿼리는 인덱스 순서를 사용하거나 인덱서에 "오프셋", "제한"을 푸시할 수 없습니다. 부분 집계의 경우 집계에 DISTINCT 수정자 인덱스 그룹화가 있는 경우 집계가 불가능합니다. 위의 쿼리는 인덱서가 그룹화 및 집계를 처리하는 데 적합합니다.
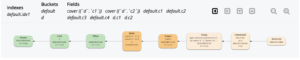
위의 그래픽 실행 트리는 인덱스 스캔(IndexScan3)이 스캔 및 인덱스 그룹화 집계를 수행하는 것을 보여줍니다. 인덱스 스캔 결과는 다시 그룹화되어 투영됩니다.
텍스트 기반 설명 을 살펴 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 |
{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "as": "d", "covers": [ "cover ((`d`.`c0`))", "cover ((`d`.`c1`))", "cover ((`d`.`c2`))", "cover ((`d`.`c3`))", "cover ((`d`.`c4`))", "cover ((meta(`d`).`id`))", "cover (count(cover ((`d`.`c2`))))", "cover (countn(cover ((`d`.`c4`))))", "cover (sum(cover ((`d`.`c3`))))", "cover (sum(cover ((`d`.`c4`))))" ], "index": "idx1", "index_group_aggs": { "aggregates": [ { "aggregate": "COUNT", "depends": [ 2 ], "expr": "cover ((`d`.`c2`))", "id": 6, "keypos": 2 }, { "aggregate": "COUNTN", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 7, "keypos": 4 }, { "aggregate": "SUM", "depends": [ 3 ], "expr": "cover ((`d`.`c3`))", "id": 8, "keypos": 3 }, { "aggregate": "SUM", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 9, "keypos": 4 } ], "depends": [ 1, 2, 3, 4 ], "group": [ { "depends": [ 1 ], "expr": "cover ((`d`.`c1`))", "id": 1, "keypos": 1 }, { "depends": [ 2 ], "expr": "cover ((`d`.`c2`))", "id": 2, "keypos": 2 } ], "partial": true }, "index_id": "d06df7c5d379cd5", "index_projection": { "entry_keys": [ 1, 2, 6, 7, 8, 9 ] }, "keyspace": "default", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "0" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialGroup", "aggregates": [ "sum(cover (count(cover ((`d`.`c2`)))))", "sum(cover (countn(cover ((`d`.`c4`)))))", "sum(cover (sum(cover ((`d`.`c3`)))))", "sum(cover (sum(cover ((`d`.`c4`)))))" ], "group_keys": [ "cover ((`d`.`c1`))", "cover ((`d`.`c2`))" ] } ] } }, { "#operator": "IntermediateGroup", "aggregates": [ "sum(cover (count(cover ((`d`.`c2`)))))", "sum(cover (countn(cover ((`d`.`c4`)))))", "sum(cover (sum(cover ((`d`.`c3`)))))", "sum(cover (sum(cover ((`d`.`c4`)))))" ], "group_keys": [ "cover ((`d`.`c1`))", "cover ((`d`.`c2`))" ] }, { "#operator": "FinalGroup", "aggregates": [ "sum(cover (count(cover ((`d`.`c2`)))))", "sum(cover (countn(cover ((`d`.`c4`)))))", "sum(cover (sum(cover ((`d`.`c3`)))))", "sum(cover (sum(cover ((`d`.`c4`)))))" ], "group_keys": [ "cover ((`d`.`c1`))", "cover ((`d`.`c2`))" ] }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialProject", "result_terms": [ { "as": "c1", "expr": "cover ((`d`.`c1`))" }, { "as": "c2", "expr": "cover ((`d`.`c2`))" }, { "as": "sumc3", "expr": "sum(cover (sum(cover ((`d`.`c3`)))))" }, { "as": "avgc4", "expr": "(sum(cover (sum(cover ((`d`.`c4`))))) / sum(cover (countn(cover ((`d`.`c4`))))))" }, { "as": "countc2", "expr": "sum(cover (count(cover ((`d`.`c2`)))))" } ] } ] } } ] }, { "#operator": "Order", "limit": "2", "offset": "1", "sort_terms": [ { "expr": "cover ((`d`.`c1`))" }, { "expr": "cover ((`d`.`c2`))" } ] }, { "#operator": "Offset", "expr": "1" }, { "#operator": "Limit", "expr": "2" }, { "#operator": "FinalProject" } ] }, "text": "SELECT d.c1 AS c1, d.c2 AS c2, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(d.c2) AS countc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c1, d.c2 ORDER BY d.c1, d.c2 OFFSET 1 LIMIT 2;" } |
- 인덱스 그룹화 및 집계를 사용하는 쿼리를 보여주는 IndexScan 섹션(즉, "#operator": "IndexScan3")의 "index_group_aggs"(24~88행)는 인덱스 그룹화 및 집계를 보여줍니다.
- 쿼리가 인덱스 그룹화 및 집계를 사용하는 경우 술어는 정확히 범위 스캔으로 변환되어 스팬의 일부로 인덱스 스캔으로 전달되므로 설명에 필터 연산자가 없습니다.
- 키별 그룹화가 선행 인덱스 키와 일치하지 않기 때문에 인덱서는 부분 집계를 생성합니다. 이것은 87줄의 "index_group_aggs" 내에서 "partial":true로 볼 수 있습니다. 쿼리 서비스가 그룹 병합을 수행합니다(119~161줄 참조).
- 인덱서는 그룹 키와 집계가 포함된 "index_projection"(91-99줄)을 투사합니다.
- 인덱서가 부분 집계를 생성하는 쿼리는 인덱스 순서를 사용할 수 없고 명시적인 정렬이 필요하며 "offset", "limit"을 인덱서에 푸시할 수 없습니다. 이 계획에는 명시적인 "Order", "Offset", "Limit" 연산자가 있습니다(197~217줄).
- 쿼리에는 AVG(x)가 포함되며, 이 쿼리는 SUM(x)/COUNTN(x)로 재작성되었습니다. COUNTN(x)는 x가 숫자 값일 때만 계산됩니다.
- 그룹 병합 중
- MIN이 MIN의 MIN이 됩니다.
- MAX는 MAX의 MAX가 됩니다.
- SUM이 SUM의 합계가 됩니다.
- 카운트는 카운트의 합계가 됩니다.
- CONTN이 COUNTN의 합계가 됩니다.
- AVG는 SUM을 SUM의 합계로 나눈 값이 됩니다.
예 4: 배열 인덱스를 사용한 그룹화 및 집계
다음 쿼리와 인덱스를 고려해 보겠습니다:
|
1 2 3 4 5 6 7 8 |
SELECT d.c0 AS c0, d.c1 AS c1, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d WHERE d.c0 > 0 AND d.c1 >= 10 AND ANY v IN d.a1 SATISFIES v.id = 3 END GROUP BY d.c0, d.c1 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2; |
필수 색인:
|
1 |
CREATE INDEX idxad1 ON default(c0, c1, DISTINCT ARRAY v.id FOR v IN a1 END, c2, c3, c4); |
쿼리에 GROUP BY 및 여러 집계가 있고 일부 집계에는 DISTINCT 수정자가 있습니다. 쿼리 술어에 ANY 절이 있고 쿼리는 배열 인덱스 idxad1로 커버될 수 있습니다. 조건 (d.c0 > 0 AND d,c11 >= 10 AND ANY v IN d.a1 SATISFIES v.id = 3 END)를 정확한 범위 스캔으로 변환하여 인덱스 스캔으로 전달할 수 있습니다. 배열 인덱스 인덱서는 각 배열 인덱스 키에 대해 별도의 요소를 유지하므로 인덱스 그룹 및 집계를 사용하려면 SATISFIES 술어에 단일 같음 술어가 있어야 하고 배열 인덱스 키에 DISTINCT 수정자가 있어야 합니다. 따라서 인덱스와 쿼리 조합은 인덱스 그룹화 및 집계를 처리하는 데 적합합니다.

이 예제는 배열 인덱스를 사용한다는 점을 제외하면 예제 1과 유사합니다. 위의 그래픽 실행 트리는 스캔, 인덱스 그룹화 집계, 순서, 오프셋 및 제한을 수행하는 인덱스 스캔(IndexScan3)을 보여줍니다. 인덱스 스캔의 결과가 투영됩니다.
예제 5: UNNEST 작업의 그룹화 및 집계
다음 쿼리와 인덱스를 고려해 보겠습니다:
|
1 2 3 4 5 |
SELECT v.id AS id, d.c0 AS c0, SUM(v.id) AS sumid, AVG(d.c1) AS avgc1 FROM default AS d UNNEST d.a1 AS v WHERE v.id > 0 GROUP BY v.id, d.c0; |
필수 색인:
|
1 |
CREATE INDEX idxaa1 ON default(ALL ARRAY v.id FOR v IN a1 END, c0, c1); |
쿼리에 GROUP BY 및 여러 집계가 있습니다. 쿼리에 배열 d.a1에 UNNEST가 있고 배열 키에 술어가 있습니다(v.id > 0). 인덱스 idxaa1은 쿼리를 한정합니다(인덱스 스캔에 배열 인덱스를 사용하려면 배열 인덱스가 선행 키여야 하고 인덱스 정의의 배열 변수가 UNNEST 별칭과 일치해야 합니다). 술어(v.id > 0)는 정확한 범위 스캔으로 변환되어 인덱스 스캔으로 전달될 수 있습니다. 따라서 인덱스와 쿼리 조합은 인덱스 그룹화 및 집계를 처리하는 데 적합합니다.
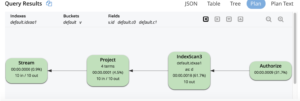
위의 그래픽 실행 트리는 인덱스 스캔(IndexScan3)이 스캔, 인덱스 그룹화 집계를 수행하는 것을 보여줍니다. 인덱스 스캔의 결과가 투영됩니다. UNNEST는 부모와 각 배열 요소 사이의 특수한 유형의 JOIN입니다. 따라서 UNNEST는 상위 문서 필드(d.c0, d.c1)와 하위 문서 필드(d.c0, d.c1)를 반복합니다. D.C0, DC.1 참조는 원본과 비교하여 중복이 있을 수 있습니다. d 문서(SUM(), AVG()에서 사용할 때는 이 점을 유의해야 합니다).
인덱스 그룹화 및 집계 규칙
인덱스 그룹화 및 집계는 쿼리 블록 단위로 이루어지며, 인덱스 그룹화/집계 사용 여부는 인덱스 선택 프로세스 후에만 결정됩니다.
- 쿼리 블록에는 조인, NEST, SUB쿼리가 포함되어서는 안 됩니다.
- 쿼리 블록은 단일 라인 인덱스로 덮여 있어야 합니다.
- 쿼리 블록에 ARRAY_AGG()가 포함되어서는 안 됩니다.
- 쿼리 블록을 상호 연관시킬 수 없음
- 모든 술어는 범위 스캔으로 정확하게 번역되어야 합니다.
- GROUP BY, 집계 표현식은 하위 쿼리, 명명된 매개 변수, 위치 매개 변수를 참조할 수 없습니다.
- GROUP BY 키에서 집계 표현식은 인덱스 키, 문서 키, 인덱스 키의 표현식 또는 문서 키의 표현식이 될 수 있습니다.
- 인덱스는 쿼리 블록의 모든 집계에 대해 그룹화 및 집계를 수행할 수 있어야 하며, 그렇지 않으면 인덱스 집계를 수행할 수 없습니다. (즉, ALL 또는 None)
- 집계에 DISTINCT 수정자 포함
- 그룹 키는 선행 인덱스 키와 정확히 일치해야 합니다(쿼리에 인덱스 키에 동일성 술어가 포함된 경우, 이 인덱스 키가 아직 없는 경우 GROUP 키에 암시적으로 포함되어 있다고 가정합니다).
- 집계 표현식은 n+1 선행 인덱스 키 중 하나에 있어야 합니다(n은 그룹 키의 수를 나타냄).
- 파티션 인덱스의 경우 파티션 키는 그룹 키와 정확히 일치해야 합니다.
요약
설명 계획을 분석할 때 설명의 술어를 스팬과 연관시키고 모든 술어가 범위 스캔과 쿼리에 정확히 변환되어 있는지 확인합니다. 인덱스 그룹화 및 집계를 사용하여 쿼리하고, 가능하면 인덱스 키를 조정하여 인덱서에서 전체 집계를 사용하여 쿼리하는 것이 더 나은 성능을 보장합니다.