재귀적 공통 테이블 표현식(CTE)과 Oracle의 CONNECT BY는 RDBMS 사용자들 사이에서 잘 알려진 SQL 구조로, 복잡하고 상호 의존적인 데이터 구조 탐색을 데이터베이스 계층에 위임하여 처리 효율성을 향상시킵니다.
이러한 구조는 금융, 공급망 관리, 고객 관계 관리(CRM), 여행 예약, 최근에는 소셜 네트워크 등 다양한 산업에서 공통적으로 요구되는 상호 의존적인 데이터 구조를 쿼리하는 데 매우 중요합니다. 그 중요성을 인식한 모든 주요 관계형 데이터베이스 관리 시스템(RDBMS)인 PostgreSQL, MySQL(버전 8.0부터), SQL Server, Oracle, SQLite는 재귀적 CTE를 지원합니다.
이와는 대조적으로 문서, 키-값, 넓은 열, 그래프 데이터 등 다양한 데이터 모델을 관리하도록 설계된 NoSQL 데이터베이스는 분산 시스템에서 확장성, 고가용성, 유연성 및 성능을 우선시합니다. 이러한 환경에서는 재귀적이든 아니든 CTE 개념이 직접적으로 다루어지지 않습니다. 사용자는 복잡한 데이터 구조를 처리하기 위해 그래프 데이터베이스(예: Neo4J용 Cypher 및 ArangoDB용 AQL)와 같은 전문 솔루션을 사용하는 경우가 많습니다.
Couchbase는 JSON용 SQL로 차별화되며, 다중 모델 지원을 확장하는 재귀적 CTE에 대한 고유한 접근 방식을 제공합니다. 이 블로그에서는 세 가지 주요 주제를 다룹니다:
-
- 여러 사용 사례의 복잡한 데이터 구조에 대해 RDBMS와 동일한 방식으로, 전용 데이터베이스 없이도 단일 DBMS를 Couchbase로 활용하는 방법을 알아보세요.
- 이러한 복잡한 관계를 쿼리, 변환 및 투영하기 위해 RDBMS 사용자에게 익숙한 SQL 구문을 사용하여 Couchase SQL++ 구문을 사용합니다.
- 재귀적 CTE로 리소스 소비를 관리하는 모범 사례.
자재 명세서 사용 사례
BOM은 제품을 제조하는 데 필요한 원자재, 부품 및 구성 요소를 자세히 설명하는 제조 및 엔지니어링의 중요한 구성 요소입니다. 부품이 다른 부품이나 재료로 구성되는 계층적 구조로 되어 있는 경우가 많습니다.
이 예제에는 데스크톱 컴퓨터의 기본 구성 요소와 하위 구성 요소가 포함됩니다.
| 컴포넌트 ID | 컴포넌트 이름 | 부모 컴포넌트 ID | 수량 |
| 1 | 데스크톱 컴퓨터 | null | 1 |
| 2 | 마더보드 | 1 | 1 |
| 3 | CPU | 2 | 1 |
| 3 | CPU 팬 | 3 | 1 |
| 4 | GPU | 2 | 1 |
| 5 | RAM | 2 | 4 |
| 6 | M.2 드라이브 | 2 | 1 |
| 7 | SSD | 2 | 1 |
| 8 | 전원 공급 장치 | 1 | 1 |
| 9 | 케이스 | 1 | 1 |
| 10 | 케이스 냉각 팬 | 1 | 4 |
데스크톱 컴퓨터를 만드는 데 필요한 모든 부품과 하위 부품을 각각에 필요한 수량과 함께 나열하고 싶다고 가정해 보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
WITH RECURSIVE ComponentHierarchy AS ( SELECT ComponentID, ComponentName, ParentComponentID, Quantity, 1 AS Lvl -- Depth level in the hierarchy FROM components WHERE ParentComponentID IS NULL -- Starting point: the Desktop Computer itself UNION ALL SELECT c.ComponentID, c.ComponentName, c.ParentComponentID, ch.Quantity * c.Quantity AS Quantity, -- Calculate total quantity required at each level ch.lvl + 1 -- Increment level for each recursion step FROM components c JOIN ComponentHierarchy ch ON c.ParentComponentID = ch.ComponentID ) SELECT * FROM ComponentHierarchy; |
이 쿼리는 최상위 항목(데스크톱 컴퓨터)으로 재귀를 초기화하고 구성 요소 테이블을 자신과 재귀적으로 조인하여 계층을 따라 내려가면서 각 구성 요소 및 하위 구성 요소에 대해 필요에 따라 수량을 조정합니다.
결과에는 데스크톱 컴퓨터에 필요한 모든 부품이 나열되며, 각 부품의 수량과 계층적 수준이 표시되므로 조립 구조를 이해하거나 재고 및 주문 목적으로 유용하게 사용할 수 있습니다.
설명
CTE는 자전거(여기서 부모 파트ID가 NULL인 경우)로 시작한 다음 모든 컴포넌트와 하위 컴포넌트를 재귀적으로 찾습니다.
수량은 자전거 한 대에 필요한 총 개수를 반영하여 각 레벨에서 조정됩니다.
레벨 열은 모든 BOM 분석에 반드시 필요한 것은 아니지만 계층 구조 내에서 각 부품의 깊이를 이해하는 데 도움이 됩니다.
이 접근 방식을 사용하면 제품 제조에 필요한 모든 재료와 구성 요소를 자세히 분석할 수 있으며, 이는 제조 운영의 재고 관리, 비용 추정 및 생산 계획에 필수적입니다.
소셜 네트워킹 사용 사례
소셜 네트워킹 사용 사례의 일반적인 애플리케이션은 두 사용자 간의 연결 정도, 즉 사용자가 상호 친구 사슬을 통해 어떻게 연결되어 있는지를 찾는 것입니다. 소셜 네트워크에서 두 사용자 간의 최단 경로(연결 정도 측면에서)를 찾아야 한다고 가정해 보겠습니다. 이는 친구 관계를 제안하거나 네트워크 역학을 이해하는 등의 기능에 도움이 될 수 있습니다.
다음과 같은 사용자가 있고 이들이 서로 어떻게 친구인지 생각해 봅시다. 예를 들어 앨리스는 밥과 친구이고 찰리와도 친구입니다. 하지만 앨리스는 다나와 친구가 아닙니다.
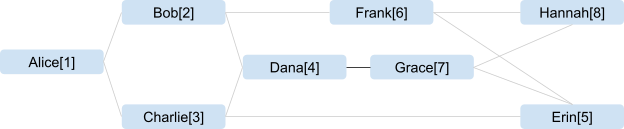
이 확장된 네트워크에서 사용자는 다양한 방식으로 연결되며, 사용자가 연결될 수 있는 여러 경로가 만들어집니다.
경로를 따라 사용자 이름을 포함하여 Alice[1]와 Frank[6] 사이의 연결 정도를 구해 보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
WITH RECURSIVE ConnectionPath AS ( SELECT u1.UserID, u1.UserName AS StartUser, u2.UserID AS FriendID, u2.UserName AS FriendName, 1 AS Degree FROM user_connections uc JOIN users u1 ON uc.UserID = u1.UserID JOIN users u2 ON uc.FriendID = u2.UserID WHERE u1.UserID = 1 -- Starting user (Alice) UNION ALL SELECT cp.UserID, cp.StartUser, u.UserID AS FriendID, u.UserName AS FriendName, cp.Degree + 1 FROM ConnectionPath cp JOIN user_connections uc ON cp.FriendID = uc.UserID JOIN users u ON uc.FriendID = u.UserID WHERE uc.FriendID NOT IN (cp.UserID) -- Avoid loops by not revisiting the start user ) SELECT * FROM ConnectionPath WHERE FriendID = 6 -- Target user (Frank) ORDER BY Degree ASC; |
설명
-
- 기본 사례: CTE는 가독성을 위해 사용자 이름을 포함하여 앨리스(사용자 ID 1)의 직접 연결을 식별하는 것으로 시작합니다.
- 재귀적 단계: 그런 다음 해당 연결의 친구를 재귀적으로 찾아서 검색을 확장하고 연결 정도를 추적합니다. 조인은 각 단계에서 시작 사용자와 친구 모두에 대해 사용자 이름이 포함되도록 합니다.
- 종료 및 필터링: Frank(사용자 ID 6)에 대한 연결을 찾을 때까지 재귀가 계속됩니다. 쿼리는 Frank로 연결되는 경로를 필터링하고 연결 정도에 따라 결과를 정렬하여 최단 경로를 식별합니다.
이 쿼리는 명확성을 위해 사용자 이름을 포함하여 소셜 네트워크를 통해 경로를 추적하고 열거하는 방법을 보여줍니다. 모든 상호 연결을 식별하거나 네트워크 구조를 탐색하는 등 보다 복잡한 분석을 위한 토대를 제공합니다.
그래프 네트워크 탐색 사용 사례
이 사용 사례에서는 아메리카 항공의 노선 데이터를 요약한 버전을 사용하겠습니다. 이것은 Couchbase 여행 샘플이 아닙니다. 이 예에서는 이 샘플 데이터 세트에서 2정거장 미만인 LAX에서 MAD까지의 모든 항공편을 찾기 위해 Couchbase SQL++ 재귀적 CTE 쿼리를 사용합니다. 이 샘플 데이터는 다음을 기반으로 하지 않습니다. 여행 샘플로 표시되지만 2008년의 AA 경로를 단순화한 버전입니다.
| 소스_공항_코드 | 목적지_공항_코드 | 항공사 |
| LAX | MAD | AA |
| LAX | LHR | AA |
| LHR | MAD | AA |
| LAX | OPO | AA |
| OPO | MAD | AA |
| MAD | OPO | AA |
| SQL++ 쿼리 | 결과 |
| /* 경유지가 2개 미만인 LAX에서 MAD까지의 모든 노선 나열 */. WITH RECURRIVE RouteCTE AS ( 선택 [r.source_airport_code, r.destination_airport_code] AS 경로, 옵션 {"levels":3} |
[ { "경로": [ "LAX", "MAD" ] }, { "경로": [ "LAX", "LHR", "MAD" ] }, { "경로": [ "LAX", "OPO", "MAD" ] } ] |
설명
-
- LAX에서 출발하는 모든 항공편에서 CTE 노선이 시작됩니다.
- 경로의 재귀적 부분은 현재 경로의 마지막 경유지에서 다른 공항으로 다시 연결되는 항공편을 찾아 LAX로 되돌아가는 경로를 피합니다.
- 경로 배열은 공항 코드의 순서를 누적하여 이동 경로를 표시합니다.
- 쿼리는 MAD로 끝나는 모든 경로를 출력하여 발견된 경로를 자세히 설명합니다.
모범 사례 재귀적 CTE
SQL++에서 재귀적 일반 테이블 표현식(CTE)을 사용할 때 개발자는 재귀적 특성의 의미와 쿼리 처리 비용을 알고 있어야 합니다. 다음은 모범 사례입니다:
재귀 깊이에 대한 제한 설정 - 무한 루프와 과도한 리소스 소모를 방지하기 위해 항상 재귀 깊이에 제한을 설정하세요. 재귀 CTE 내에서 카운터 또는 조건을 사용하여 재귀의 깊이를 제어하고 옵션 제한을 포함하세요.
성능 모니터링 - 재귀적 CTE는 리소스 집약적일 수 있습니다. 특히 길거나 복잡한 쿼리의 경우 성능을 면밀히 모니터링하고 필요에 따라 최적화하세요. 여기에는 인덱싱 또는 지나치게 복잡한 CTE를 세분화하는 작업이 포함될 수 있습니다.
불필요한 복잡성 피하기 - CTE의 재귀 부분 내의 로직은 가능한 한 단순하게 유지하세요. 지나치게 복잡한 조건이나 계산은 성능을 크게 저하시킬 수 있습니다. JOIN 조건이 올바른지 확인하세요.
올바른 데이터 구조 확인 - 데이터가 재귀를 위해 올바르게 구조화되었는지 확인합니다. 부정확하거나 잘못된 데이터는 잘못된 결과나 비효율적인 쿼리로 이어질 수 있습니다.
광범위한 테스트 - 엣지 케이스를 포함한 다양한 데이터 세트로 재귀적 CTE를 철저히 테스트하세요. 이를 통해 무한 루프, 잘못된 결과 또는 성능 병목 현상과 관련된 모든 문제를 파악할 수 있습니다.
메모리 할당량 설정 - 재귀 쿼리에서 과도한 메모리 사용을 방지하기 위해 요청 또는 노드 수준에서 메모리 할당량을 설정합니다.
제한 사항
재귀적 CTE는 다른 RDBMS에서 흔히 볼 수 있는 Couchbase SQL++의 강력한 기능입니다. 이를 통해 계층 및 그래프 네트워크 데이터를 탐색하거나 표준 SQL로는 표현하기 어려운 반복 계산을 수행하는 등 복잡한 쿼리를 실행할 수 있습니다. 그러나 재귀적 CTE를 사용할 때 주의해야 할 제한 사항과 고려 사항이 있습니다. 이러한 제한은 주로 성능, 구문 제한 및 쿼리의 복잡성과 관련이 있습니다. 다음은 몇 가지 구체적인 사항입니다:
집계: 재귀적 CTE는 일반적으로 CTE의 재귀적 부분 내에서 집계 함수(MIN(), MAX(), SUM(), AVG() 등) 또는 DISTINCT를 허용하지 않습니다. 이러한 연산은 모든 재귀가 해결된 후 최종 결과 집합을 의미하므로 재귀적으로 행을 추가하는 컨텍스트에서는 의미가 없습니다.
창 기능: 집계 함수와 마찬가지로 윈도우 함수(ROW_NUMBER(), RANK() 등)는 일반적으로 CTE의 재귀 부분에서는 사용되지 않습니다. 쿼리에서 반환된 행 집합에 사용하기 위한 것으로, 비재귀 용어 또는 재귀적 CTE에서 선택하는 쿼리에 적합합니다.
한도/주문 기준: 이러한 절은 CTE의 재귀 멤버 내에서 허용되지 않습니다. 그 이유는 최종 결과 집합 순서와 관련이 있으며 각 반복을 통해 중간 결과가 누적적으로 구성되는 재귀 집합을 구축하는 컨텍스트에서는 의미가 없기 때문입니다.
다음 단계
-
- 자세히 알아보기 카우치베이스 SQL++
- 블로그에서 더 많은 CTE 예시를 확인하세요: SQL++의 재귀 쿼리 처리 (N1QL)
- 시작하기 카우치베이스 카펠라 무료 체험판