에서 NoSQL 애플리케이션을 위한 데이터 구조 게시물, 네이티브 컬렉션, 맵 등을 통해 간소화된 JSON 데이터 액세스를 사용했습니다. 이 게시물에서는 JSON용 SQL 기반 언어인 상위 수준 N1QL 쿼리를 사용하여 해당 데이터를 쿼리하는 방법을 보여줍니다.
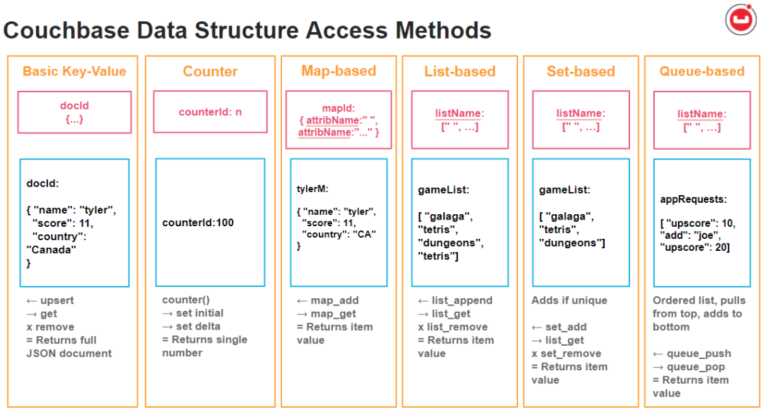
카우치베이스 데이터 구조 유형 및 JSON 샘플 요약.
개발자는 프로그래밍 언어를 사용하여 기본 데이터 구조와 데이터 유형을 관리하는 데 집중할 수 있습니다. 한편, DBA와 분석가는 쿼리 언어를 사용하여 동일한 데이터에 액세스할 수 있습니다. Couchbase는 NoSQL 데이터 인덱싱 방법과 N1QL 쿼리 서비스를 사용하여 이를 수행합니다.
Couchbase 전체 텍스트 검색 엔진을 사용한 검색 쿼리도 가능하며 향후 게시물에서 다룰 예정입니다.
NoSQL 데이터베이스 인덱싱이란 무엇인가요?
인덱싱은 데이터를 검사하고 해당 요소를 다시 찾는 방법을 결정합니다. 인덱싱은 JSON 문서, 키/필드 또는 필드의 값에 적용할 수 있습니다. JSON 문서의 키는 표 형식 데이터베이스 인덱싱 시스템에서 열 이름처럼 작동합니다.
데이터베이스는 이러한 요소 및 값 모음을 소스를 가리키는 인덱스로 관리합니다. 데이터베이스 백엔드는 데이터를 저장하는 동안 문서가 변경되면 인덱싱을 업데이트합니다. 한편, DBA는 대용량 쓰기나 쿼리와 같은 특정 사용 사례에 맞게 인덱싱을 최적화할 수 있습니다.
인덱스를 사용하면 N1QL 쿼리는 원본 데이터를 스캔하지 않고도 일치하는 필드 값을 빠르게 찾을 수 있습니다. 이 방법은 일반적인 데이터 구조에도 적용됩니다, 에 소개된 컬렉션 및 범위 Couchbase 7.0.
N1QL로 카우치베이스 데이터 구조 쿼리하기
Couchbase 웹 콘솔은 데이터베이스의 데이터 구조 문서를 쉽게 볼 수 있는 방법입니다. 데이터 구조 문서가 복잡한 JSON 문서보다 훨씬 간단한 경우가 많다는 점에 주목하세요.
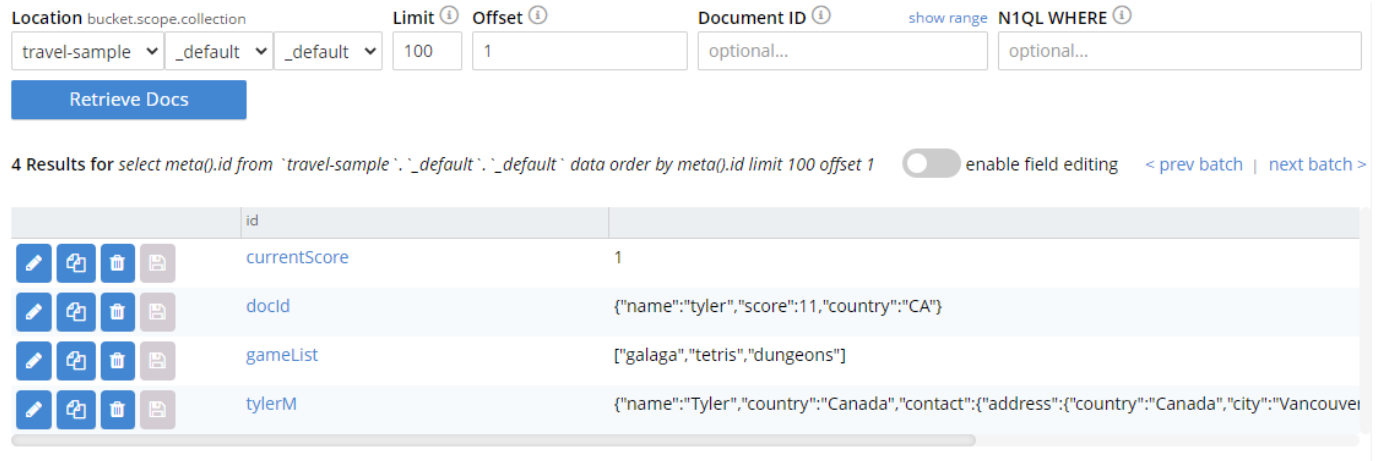
버킷에 있는 데이터 구조 문서 목록
N1QL 쿼리 작성을 시작하려면 데이터 구조 데이터를 인덱싱해야 합니다. 기본 작업을 위해서는 최소한 버킷 전체에 대한 기본 인덱스가 필요합니다.
|
1 |
CREATE PRIMARY INDEX ON `travel-sample`; |
다음에서 새로운 컬렉션 기능을 사용하는 문서의 경우 Couchbase 7.0를 사용하여 인덱싱해야 합니다.
|
1 |
CREATE PRIMARY INDEX ON `travel-sample`.`scope1`.`col1` |
P기본 인덱스 대규모 데이터 집합으로 인한 어려움 하지만 소량의 데이터를 빠르게 탐색하는 데는 탁월합니다. 빅 데이터 프로젝트에서 프로덕션 단계로 넘어갈 때는 글로벌 보조 인덱스(GSI)를 사용하세요.
모든 데이터 문서 및 ID 목록
그러나 데이터 구조에 명명된 키가 없을 수 있으므로 보다 타겟팅된 인덱싱이 항상 가능한 것은 아닙니다. 예를 들어 카운터는 필드 이름이 없는 ID와 정수 값일 뿐입니다. 하지만 맵이 있는 경우 내부 키를 대상으로 하는 인덱스를 만들 수 있습니다.
문서 ID에 대한 기본 쿼리는 모든 문서를 반환하고 사용 중인 필드 이름을 표시할 수 있습니다.
|
1 |
SELECT META().id, * FROM `travel-sample` |
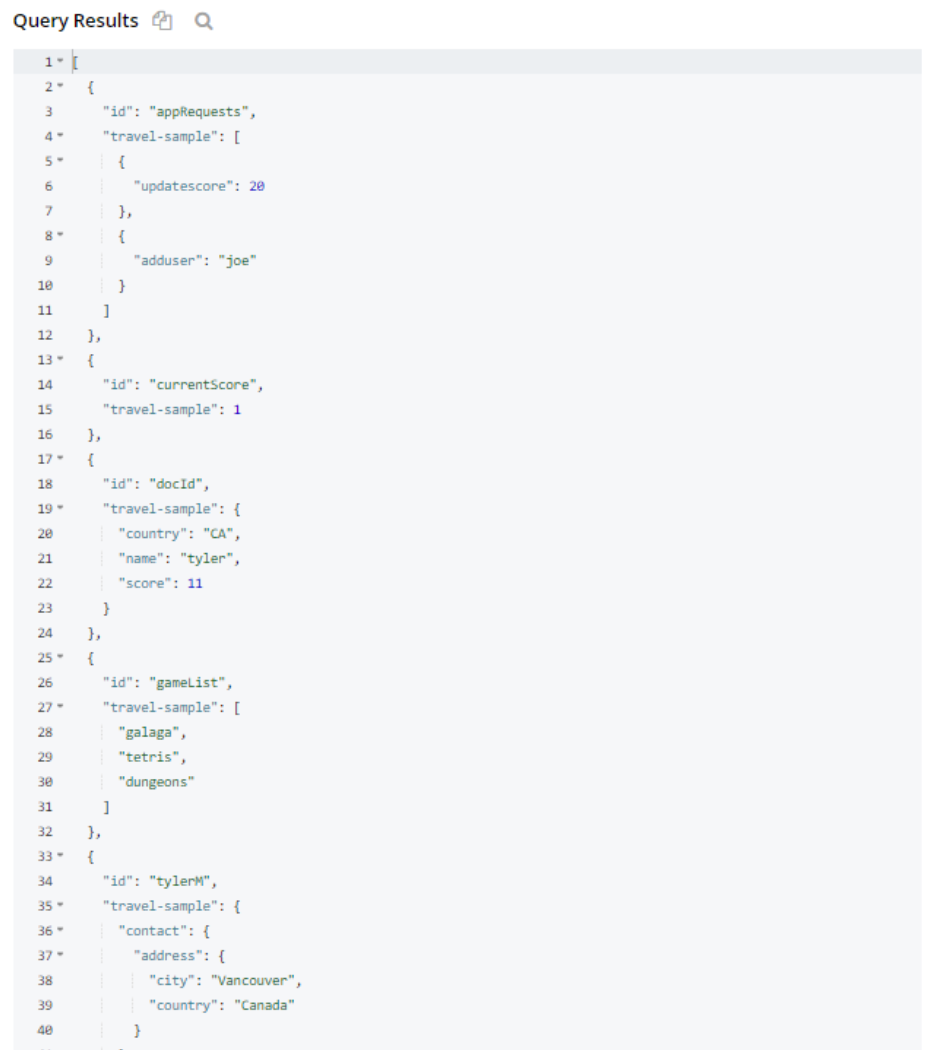
현재 점수 는 기본 카운터인 반면 게임 목록 는 목록/컬렉션 등입니다.
데이터 구조에 대한 범위/컬렉션 쿼리하기
범위 및 컬렉션을 사용하는 경우 from 절에 추가합니다.
|
1 |
SELECT * FROM `travel-sample`.`scope1`.`col1` |
명명된 데이터 구조 객체에서 특정 값을 where 절에 추가하여 검색합니다.
|
1 |
SELECT META().id, * FROM `travel-sample` WHERE META().id = 'currentScore' |
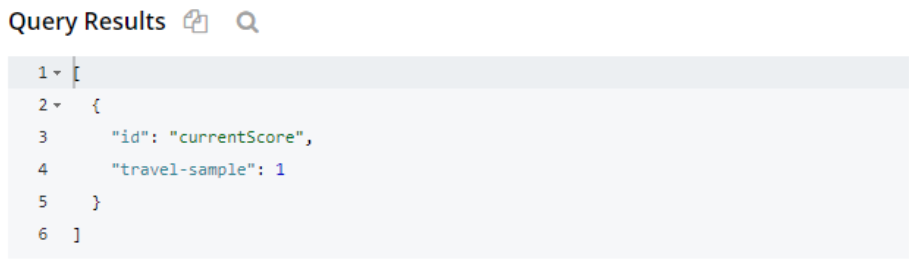
필드 이름만 지정하고 ID는 지정하지 않으면 쿼리는 모든 문서에서 일치하는 값을 반환합니다.
|
1 |
SELECT name, contact FROM `travel-sample` |
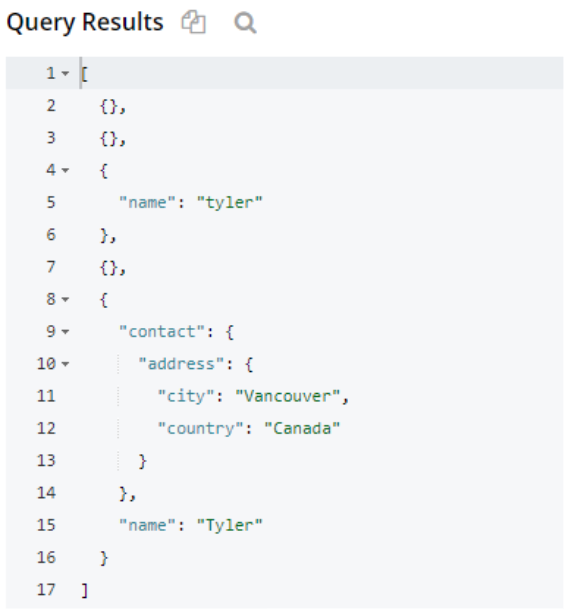
쿼리는 특정 필드와 해당 값을 가진 객체를 반환합니다. 위의 결과에서 데이터 구조 중 하나만 연락처 필드. 다른 두 개는 이름 필드로 이동했지만 일치하는 필드가 없는 빈 개체가 여러 개 표시됩니다.
확장성을 위해 모든 쿼리 애플리케이션은 특정 필드에 대해 글로벌 보조 인덱스(GSI)도 사용해야 합니다.
이 데이터베이스 인덱싱 모범 사례 기사에서는 빅데이터 소프트웨어 엔지니어링에 사용되는 더 많은 컴퓨터 과학 시나리오를 다룹니다.
모든 것을 하나로 모으기
보시다시피, Couchbase를 사용하면 문서 및 관련 하위 컴포넌트를 쿼리하는 것이 매우 간단합니다. 정교한 인덱싱 방법을 전략적으로 사용하면 애플리케이션이 생성하는 데이터에 액세스할 수 있는 방법이 훨씬 더 다양해집니다.
카우치베이스는 시스템 아키텍처를 획기적으로 간소화하여 개발자가 큰 어려움 없이 시작할 수 있도록 지원합니다. 이 레퍼런스는 빠르게 시작하는 데 도움이 될 것입니다.
- Couchbase 7.0의 NoSQL 애플리케이션을 위한 데이터 구조
- 멀티테넌트 애플리케이션을 위한 범위 및 컬렉션
- 카우치베이스 데이터 구조 API (파이썬 SDK)
- 하위 문서 운영 문서 (파이썬 SDK)
- NoSQL 데이터베이스 시스템 인덱스 모범 사례
- NoSQL 전체 텍스트 검색 인덱싱 모범 사례
- 전체 텍스트 검색 문서