최근 엔터프라이즈급 스토리지에 대한 관심이 뜨겁습니다. 이 분야의 리더로 인정받고 있는 퓨어스토리지는 최근 연구실 환경 중 하나에 카우치베이스를 구축할 기회를 제공했습니다. 8노드 클러스터는 초당 100만 건의 쓰기 작업을 수행하는 100% 워크로드를 쉽게 견뎌낼 수 있었습니다. 다음 매개변수를 사용하여 클러스터 노드 중 하나에서 실행되는 Pillowfight 도구를 사용하여 초당 1,000,000건의 쓰기 워크로드를 생성했습니다:
클러스터에서 초당 1백만 건의 지속적인 쓰기 로드는 다음과 같습니다:

이 워크로드는 인상적이긴 했지만 스토리지 어레이를 조금도 사용하지 않았습니다. 사실, 퓨어 대시보드에서 많은 부하를 찾기도 어려웠습니다. 그 이유는 필로우파이트에서는 64바이트 문서만을 사용했기 때문입니다. 작은 키/값을 빠른 속도로 많이 작성하는 사물 인터넷 사용 사례를 고려할 때 이는 매우 합리적인 워크로드입니다. 사용자 프로필 저장소 사용 사례는 어떨까요? 실제 애플리케이션과 사실적으로 스타일이 지정된 사용자 프로필 데이터를 사용하는 이 환경에서 고속 100% 쓰기 워크로드의 성능은 어떨까요?
테스트 하네스
이 애플리케이션에는 신속하게 배포되는 테스트 하네스와 로드 생성기가 필요하며, node.js가 완벽한 플랫폼입니다. 소스 코드는 다음에서 사용할 수 있습니다. github . 먼저 생성 메서드가 있는 데이터 레이어 개체가 필요합니다:
var 엔드포인트=“10.21.16.121:8091”;
var 클러스터 = new 카우치베이스.클러스터(엔드포인트);
var db = 클러스터.오픈버킷("user",함수 (err) {
만약 (err) {
콘솔.로그('=>DB 연결 오류:', err);
}
});
함수 create(키, 항목){
db.업서트(키, 항목, 함수(err, 결과){
만약(err){
}else {
}
});
}
다음으로 사용자를 생성하는 방법이 필요합니다. 멋진 "faker.js" 라이브러리를 활용하여 사용자를 생성하면 이 작업이 간단해집니다. faker를 사용하여 사용자를 생성하는 것은 매우 간단하며, 이 기능을 더욱 추상화하는 도우미 함수가 있습니다. 간단한 for 루프를 생성하면 faker로 사용자가 생성되고 위에서 설명한 데이터 계층으로 전달됩니다:
에 대한(i=0;i<limit;i++){
var u=faker.도우미.사용자 카드();
연결.db.create(u.이메일,u);
}
}
카우치베이스에 수집을 수행하려면 제어 루프가 필요합니다:
체크옵스(함수(완료){
콘솔.로그(완료);
만약 (parseInt(완료, 10) < 임계값) {
로드 텍스트 사용자 프로필(testBatch);
콘솔.로그("INGEST:추가됨:",testBatch);
}
else {
콘솔.로그("INGEST:바쁨:", 완료);
}
});
}, testInterval
);
제어 루프는 모든 유형의 성능 테스트 및 스트레스 분석에 유용한 기능인 스로틀링 로직을 사용합니다. 이 함수는 클러스터의 노드에서 나머지 엔드포인트를 호출하고 클러스터가 현재 처리 중인 초당 작업 수를 확인합니다:
http.get("https://" + 엔드포인트 + "/pools/default/버킷/사용자", 함수 (res) {
var 데이터=“”;
res.setEncoding('utf8');
res.on('데이터', 함수 (청크) {
데이터 += 청크;
});
res.on('end',함수(){
var 파싱된=JSON.parse(데이터);
opsV(파싱됩니다.기본 통계.opsPerSec);
});
});
}
결과
사물 인터넷 사용 사례와 마찬가지로 사용자 프로필 저장소의 성능 결과도 인상적이었습니다. 단기간에 초당 40만 건의 지속적인 워크로드에서 5억 명에 가까운 사용자를 생성할 수 있었습니다.
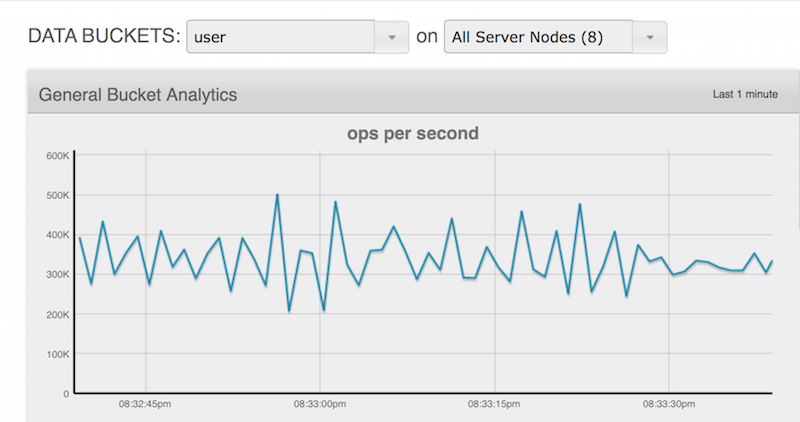
흥미를 유지하기 위해 전체 퇴거를 사용하고 메모리를 최종 데이터 세트 크기의 약 10%로 조정했습니다.

퓨어시스템은 완벽하게 작동했습니다. 스토리지 시스템의 헤드룸이 부족해지기 훨씬 전에 CPU 처리 한계에 도달했습니다:
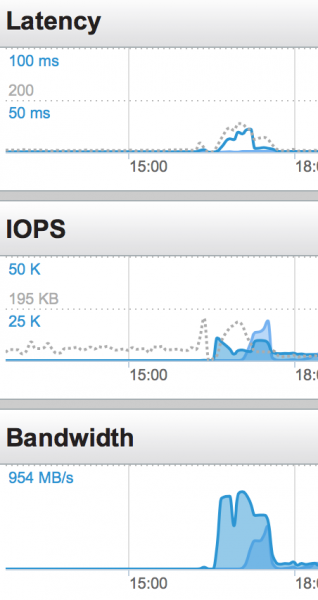
워크로드 성능 자체보다 더 인상적인 것은 스토리지 공간입니다. 이는 분산 시스템에서 스토리지의 가장 어려운 측면 중 하나입니다. 퓨어의 중복제거 기술은 탁월합니다.

퓨어는 경쟁사 시스템보다 4배 더 정밀한 512바이트 단위로 매우 까다로운 워크로드도 효율적으로 중복 제거할 수 있습니다. 가짜 사용자를 생성하는 테스트 환경에서 데이터는 무작위로 균등하게 분산됩니다. 실제 워크로드에서는 중복 제거 성능이 더욱 향상될 것으로 기대할 수 있습니다. 무작위 사용자 데이터 세트에서는 1.6대 1의 일관된 중복 제거율을 보였으며, 1개의 카우치베이스 복제본이 활성화되었습니다. 향후 퓨어의 기술을 활용한 추가 벤치마킹을 기대하며, 퓨어의 시스템을 사용한 카우치베이스의 성능에 대해 기대가 큽니다.