여러 지역의 사용자와 상호 작용하는 최신 웹 애플리케이션은 다양한 개인정보 보호 요구사항과 사용자 데이터 동의 가이드라인을 준수해야 합니다. 이는 팀원이 한 명이든 50명이든 상관없이 모든 엔지니어링 팀이 처리하기에는 부담스러울 수 있습니다.
프로세스를 간소화하여 번거로움을 없애고 규정 미준수 가능성을 줄이려면 어떻게 해야 할까요?
이 가이드에서는 데이터가 데이터 저장소에 도달하기 전에 데이터를 살균하기 위해 Couchbase와 함께 작동하는 AWS 서비스를 활용하는 구현을 살펴봅니다. 이 간단한 구현은 어떤 상황에서도 활용할 수 있으며 구축 중인 사용 사례에 맞게 확장할 수 있습니다.
요약 배포 지침이 포함된 README와 함께 코드만 보고 싶으신가요? 다음에서 필요한 모든 것을 찾아보세요. GitHub.
개요
시나리오 예시
독특한 수공예품을 판매하는 소규모 전자상거래 플랫폼을 상상해 보세요. 이 사이트는 일회성 구매 모델로 운영되므로 사용자는 계정을 만들거나 로그인할 필요가 없습니다. 쇼핑객은 카탈로그를 둘러보고 구매하고자 하는 품목을 선택한 다음 결제를 진행하기만 하면 됩니다. 결제 과정에서 이름, 우편 주소, 청구지 주소, 결제 정보, 전화번호, 이메일 주소 등의 필수 정보를 제공합니다. 이러한 개인 식별 정보(PII)는 구매를 완료하고 상품이 올바른 주소로 배송되는지 확인하는 데 필요합니다.
주문이 접수되면 데이터는 다양한 마이크로 서비스를 통해 이동합니다. 주문 처리 서비스는 세부 정보를 확인하고 재고를 확인하며, 결제 서비스는 청구 정보를 안전하게 처리하여 거래를 처리하고, 배송 서비스는 제공된 우편 주소를 사용하여 배송을 준비합니다.
이 사이트는 사용자에게 원활하고 쉬운 쇼핑 경험을 제공하도록 설계되었습니다. 계정이 필요하지 않습니다. 긴 등록 절차를 거칠 필요가 없습니다. 구매할 품목을 선택하고 배송 정보와 함께 결제하기만 하면 완료됩니다. 그러나 고객이 원활한 쇼핑 환경을 경험하는 동안 고객의 개인 데이터는 애플리케이션에서 동일한 원활한 경험을 할 수 없습니다. 개인정보 보호를 유지하고 규정을 준수하기 위해 이 PII는 장기 구매 내역 데이터베이스에 저장되기 전에 위생 처리되어야 합니다.
이 시나리오는 독특해 보일 수 있지만, 실제로는 애플리케이션에서 항상 발생할 수 있는 상황입니다. 사용자 정보의 모든 측면을 수집하는 모든 애플리케이션은 엄격한 동의를 확보하고 전 세계에서 운영되는 모든 지역의 법률과 규정을 준수해야 합니다. 이는 엄청난 도전이 될 수 있으며, 제대로 수행되지 않을 경우 심각한 결과를 초래할 수 있습니다.
솔루션 워크플로
실시간 데이터에 대한 개인정보 보호 요건을 효과적으로 처리하기 위해서는 데이터가 생성되는 즉시 AWS와 Couchbase의 실시간 데이터 기능을 활용하여 데이터를 변환해야 합니다. GDPR 규정에 따라 개인 데이터를 데이터베이스에 잠시라도 저장하는 것은 법적으로 매우 까다롭습니다. 따라서 데이터를 안전하게 처리한 후에만 추가하는 것이 좋은 데이터 관행일 뿐만 아니라 법적 요건일 수도 있습니다.
우리가 만들고 있는 솔루션은 AWS Simple Queue Service(SQS), Elastic Container Registry(ECR), 그리고 완전 관리형 데이터베이스 서비스(DBaaS)인 Couchbase Capella와 협력하여 작동하는 Lambda 기능을 활용할 것입니다. 이 워크플로는 큐 서비스에 메시지를 전송하는 모든 메시지 발신자를 통해 구현할 수 있으며, 데이터 위생 처리 프로세스를 시작합니다. 즉, 플러그 앤 플레이가 가능합니다.
다음 워크플로에서는 솔루션의 작동 방식을 시각적으로 보여줍니다.
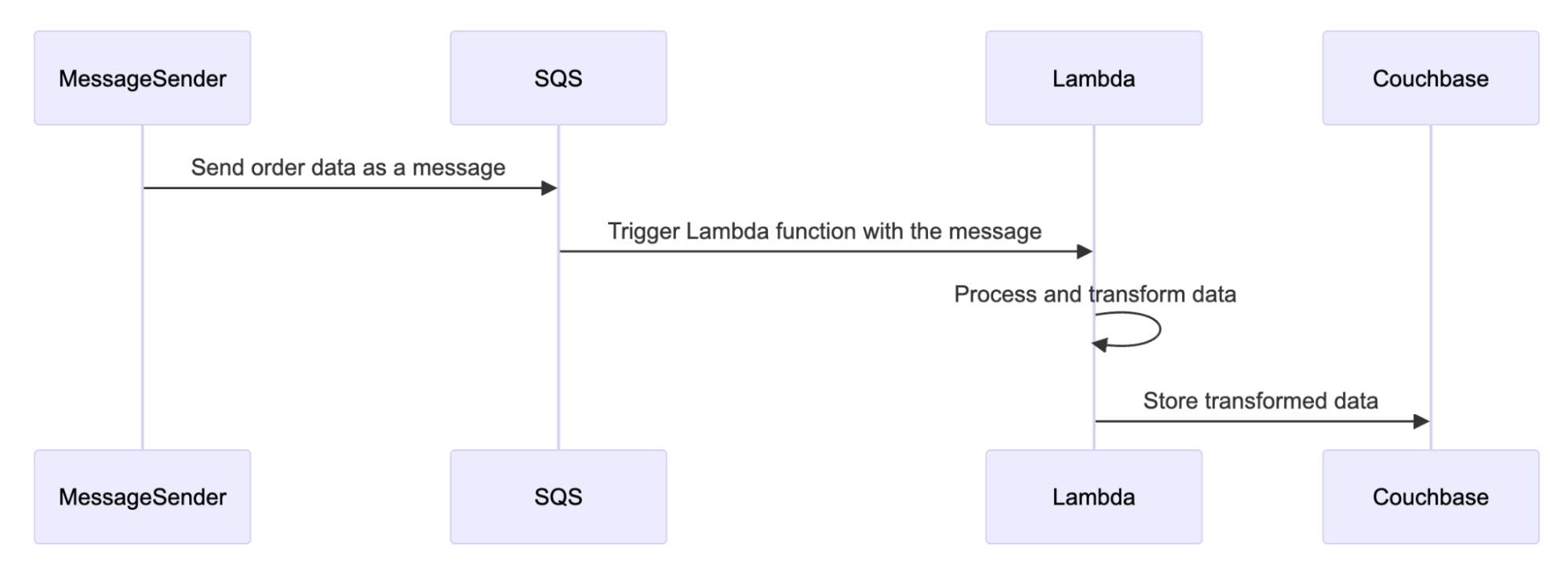
먼저 메시지 발신자가 대기열 서비스로 데이터를 전송합니다. 그러면 메시지와 함께 람다 함수가 트리거됩니다. 람다 함수는 데이터를 처리하고 변환하여 메시지에서 모든 PII를 제거합니다. 마지막으로, 위생 처리된 데이터는 데이터 저장소에 안전하게 추가될 수 있도록 Couchbase로 전송됩니다.
이제 워크플로우를 이해했으니 직접 만들어 보겠습니다!
구현
카우치베이스 아카펠라 구성
카우치베이스 카펠라에 무료로 가입하여 사용해 볼 수 있으며, 아직 가입하지 않은 경우 다음 주소로 이동하여 사용해 볼 수 있습니다. cloud.couchbase.com 을 클릭하고 GitHub 또는 Google 자격 증명을 사용하여 계정을 만들거나 이메일 주소와 비밀번호 조합으로 새 계정을 만들 수 있습니다.
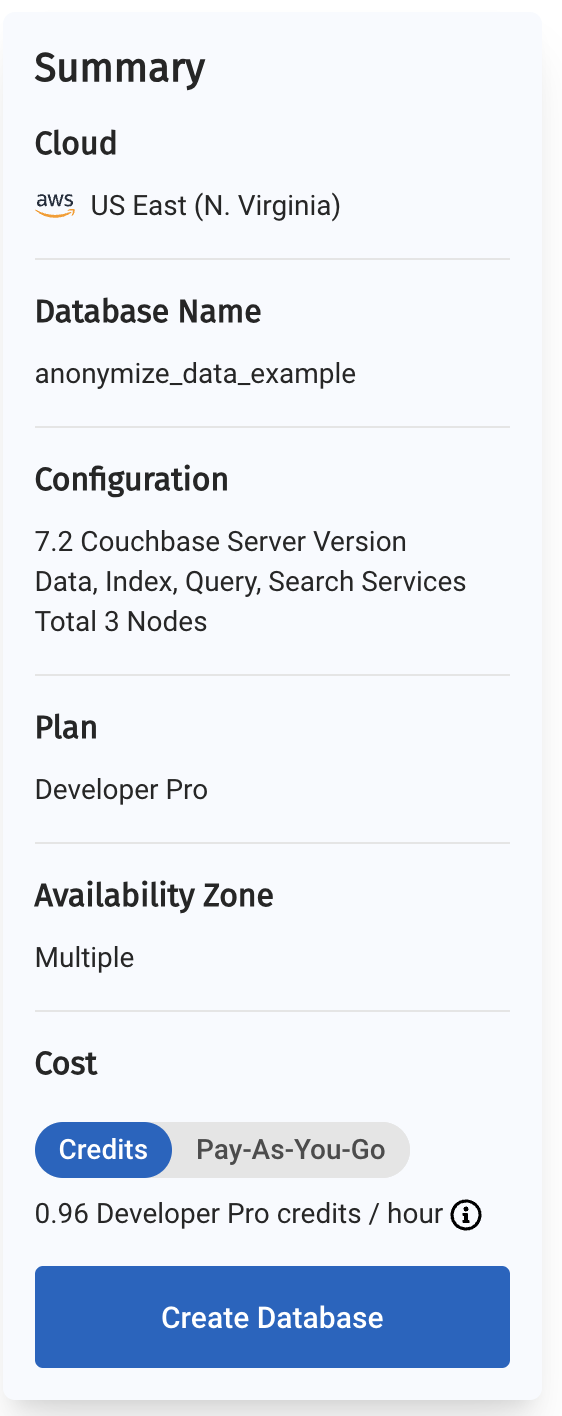 이 작업을 완료하면 Capella 대시보드에서 첫 번째 데이터베이스를 만들 수 있습니다. 이 안내를 위해 데이터베이스 이름을 다음과 같이 지정해 보겠습니다. 익명화_데이터_예시.
이 작업을 완료하면 Capella 대시보드에서 첫 번째 데이터베이스를 만들 수 있습니다. 이 안내를 위해 데이터베이스 이름을 다음과 같이 지정해 보겠습니다. 익명화_데이터_예시.
새 데이터베이스의 요약이 대시보드 왼쪽에 표시됩니다. Capella는 멀티클라우드이며 AWS, Google Cloud 또는 Azure에서 작동할 수 있습니다. 이 예제에서는 AWS에 배포합니다.
데이터베이스를 만든 후에는 데이터베이스를 생성해야 합니다. 버킷. A 버킷 는 데이터가 저장되는 컨테이너입니다. 데이터의 각 항목은 문서는 대부분의 개발자에게 익숙한 구문인 JSON으로 유지됩니다. 버킷 이름은 원하는 대로 지정할 수 있습니다. 그러나 이 안내에서는 이 버킷의 이름을 다음과 같이 지정해 보겠습니다. 익명화된 데이터_예시.
이제 데이터베이스와 버킷을 모두 만들었으므로 데이터베이스 액세스 자격 증명을 만들고 Lambda 함수에서 사용할 연결 URL을 가져올 준비가 되었습니다.
로 이동하여 연결 섹션에 있는 아카펠라 대시보드의 연결 문자열.
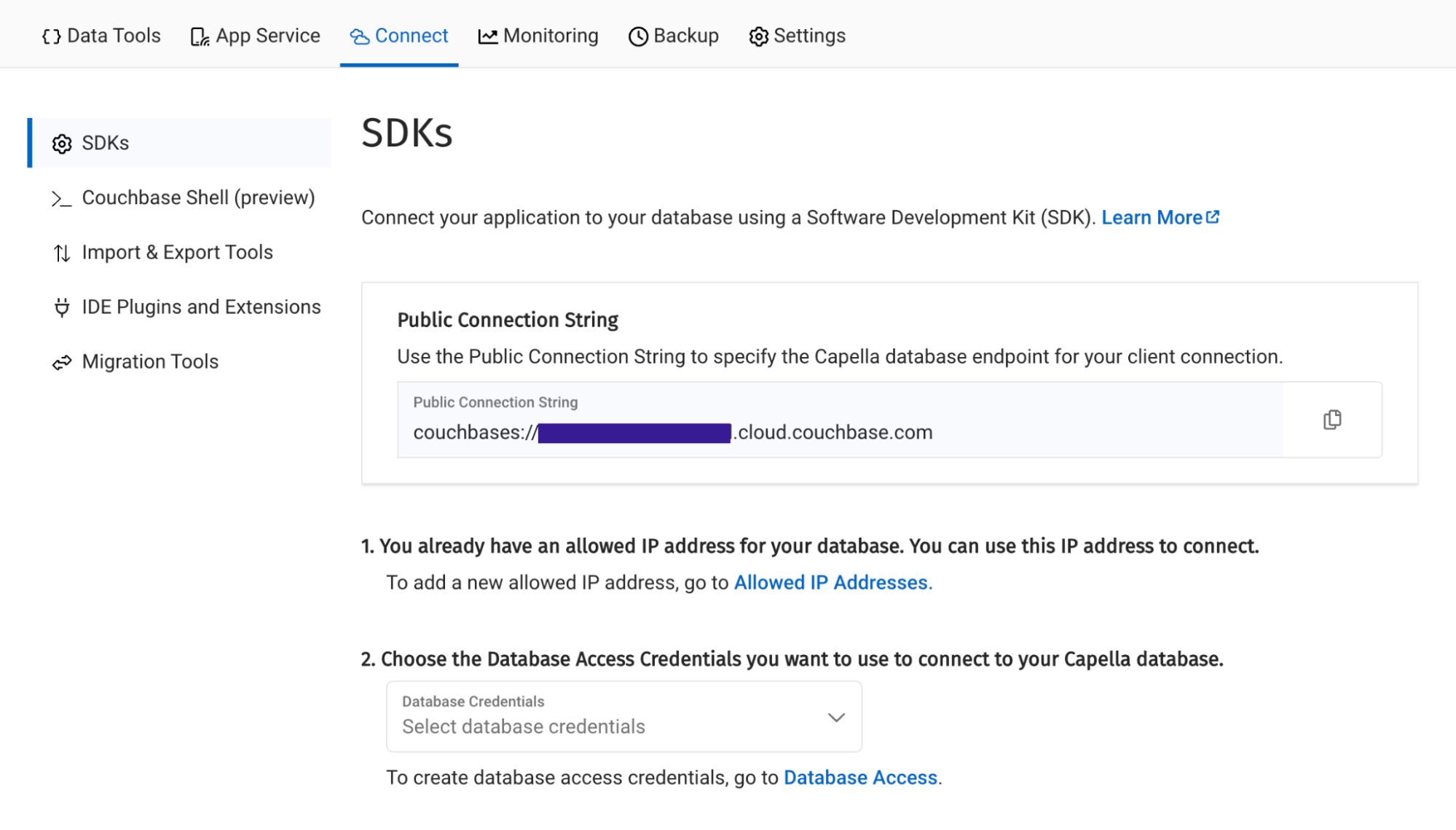
그런 다음 데이터베이스 액세스 링크를 클릭합니다. 이 섹션에서 Lambda 함수가 데이터베이스 인증에 사용할 자격증명(사용자 이름과 비밀번호)을 만들 수 있습니다. 자격 증명을 생성한 특정 버킷으로 범위를 지정하거나 계정의 모든 버킷과 데이터베이스에 대한 권한을 부여할 수 있습니다. 어떤 경우든 읽기 및 쓰기 액세스 권한이 모두 있는지 확인해야 합니다.
이제 대기열 서비스에서 메시지를 수신할 때마다 호출할 람다 함수를 만들 준비가 되었습니다.
람다 함수 만들기
모든 애플리케이션은 수집할 수 있는 PII가 다르며, 애플리케이션이 운영되는 지역에 따라 데이터를 저장하기 전에 제거해야 하는 항목에 대한 요구 사항도 다를 수 있습니다. 이 예에서는 모든 메시지의 IP 주소와 성을 제거한 후 Couchbase로 전송합니다.
데이터를 살균하는 기능 자체는 매우 간단합니다:
|
1 2 3 4 5 |
function anonymizeData(data) { data.user.last_name = ''; delete data.user.ip_address; return data; } |
이 기능입니다, 익명화데이터에서 호출됩니다. 핸들러 함수를 사용하세요. 코드에 익숙하지 않은 경우 핸들러 함수는 AWS Lambda가 SQS 대기열에서 들어오는 메시지를 처리하고 데이터를 변환하여 Couchbase에 저장하는 데 사용됩니다. 기본 실행 코드는 반드시 exports.handler.
그리고 핸들러 함수는 람다 함수의 구성에 설정된 환경 변수에서 Couchbase 자격 증명과 연결 문자열을 가져옵니다. Lambda 함수에 대한 환경 변수 설정에 대한 자세한 지침은 AWS 문서. 그런 다음 함수는 SQS에서 받은 메시지를 구문 분석하고 익명화데이터 기능을 사용할 수 있습니다. 마지막으로 업서트 데이터를 카우치베이스 버킷에 넣습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
exports.handler = async (event) => { console.log('Starting Lambda function'); if (!event.Records || !Array.isArray(event.Records)) { throw new TypeError('event.Records is not iterable'); } const connectionString = process.env.COUCHBASE_CONNECTION_STRING; const username = process.env.COUCHBASE_USERNAME; const password = process.env.COUCHBASE_PASSWORD; const bucketName = process.env.COUCHBASE_BUCKET_NAME; try { const cluster = await couchbase.connect(connectionString, { username: username, password: password }); console.log('Connected to Couchbase cluster'); const bucket = cluster.bucket(bucketName); const collection = bucket.defaultCollection(); for (const record of event.Records) { console.log('Processing record:', record); const payload = JSON.parse(record.body); const transformedData = anonymizeData(payload); console.log('Transformed data:', transformedData); await collection.upsert(transformedData.record_id, transformedData); console.log('Data upserted:', transformedData.record_id); } } catch (error) { console.error('Error during processing:', error); throw error; } }; |
AWS CLI를 사용하여 Lambda 함수를 설정하려면 새 Lambda 함수를 만들고 필요한 IAM 역할 및 핸들러를 지정해야 합니다. 방법은 다음과 같습니다:
|
1 2 3 4 |
aws lambda create-function --function-name AnonymizeDataExampleFunction \ --package-type Image \ --code ImageUri=<your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest \ --role arn:aws:iam::<your-account-id>:role/<your-lambda-execution-role> |
다음을 교체해야 합니다. <your-account-id>, <your-region>및 <your-lambda-execution-role> 를 실제 AWS 계정 ID, 리전 및 Lambda 함수에 대해 생성한 IAM 역할의 ARN으로 대체합니다. 이 명령은 AWS ECR에 게시할 Docker 이미지를 사용하도록 Lambda 함수를 설정합니다.
이제 Lambda 함수를 Docker 이미지로 패키징하여 AWS ECR 서비스에 게시할 준비가 되었습니다.
ECR에 도커 이미지 배포하기
AWS ECR에 Docker 이미지를 배포하려면 먼저 Linux/amd64 플랫폼용 Docker 이미지를 빌드합니다. 이렇게 하면 Lambda 함수의 x86_64 아키텍처와의 호환성을 보장할 수 있습니다. 우리는 도커파일 를 실행하여 필요한 도구와 종속 요소를 설치하고, 작업 디렉터리를 설정하고, 필요한 파일을 복사하고, 종속 요소를 설치하고, Lambda 함수 코드를 복사합니다. 그리고 도커파일 는 람다 함수를 실행하는 명령도 지정합니다.
다음은 도커파일:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
FROM public.ecr.aws/lambda/nodejs:18 # Install necessary tools and dependencies RUN yum -y install gcc-c++ tar gzip findutils # Set the working directory WORKDIR /var/task # Copy package.json and package-lock.json COPY package*.json ./ # Install dependencies RUN npm install # Copy the function code COPY index.js ./ # Command to run the Lambda function CMD [ "index.handler" ] |
도커파일이 준비되면 지정된 플랫폼으로 도커 이미지를 빌드합니다:
|
1 |
docker build --platform linux/amd64 -t anonymize_data_example_image . |
이미지를 빌드한 후에는 AWS ECR 리포지토리에 적절하게 태그를 지정합니다:
|
1 |
docker tag anonymize_data_example_image:latest <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Docker 이미지를 ECR로 푸시하려면 먼저 AWS CLI를 사용하여 ECR 레지스트리에 로그인하여 로그인 자격 증명을 얻습니다:
|
1 |
aws ecr get-login-password --region <your-region> | docker login --username AWS --password-stdin <your-account-id>.dkr.ecr.<your-region>.amazonaws.com |
자격 증명이 준비되면 Docker 이미지를 ECR 리포지토리에 푸시합니다:
|
1 |
docker push <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
마지막으로 람다 함수를 업데이트합니다. 익명화 데이터 예제 함수 를 사용하여 ECR의 새 Docker 이미지를 사용해야 합니다. 여기에는 이미지 URI를 지정하고 새로 푸시된 Docker 이미지에서 코드를 실행하도록 Lambda 함수가 구성되어 있는지 확인하는 작업이 포함됩니다:
|
1 |
aws lambda update-function-code --function-name AnonymizeDataExampleFunction --image-uri <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
이 단계를 수행하면 Docker 이미지가 AWS ECR에 성공적으로 배포되고 Lambda 함수가 새 이미지를 사용하도록 업데이트되어 애플리케이션이 Couchbase에 저장하기 전에 PII를 살균할 수 있습니다. 이 설정을 통해 데이터 처리가 개인정보 보호 요건을 준수하는 동시에 AWS와 Couchbase의 강력한 기능을 활용할 수 있습니다.
SQS 서비스 설정
메시지 발신자와 람다 함수 간의 데이터 흐름을 원활하게 하려면 Amazon SQS 대기열을 설정해야 합니다. SQS 대기열은 Lambda 함수에서 처리될 때까지 메시지를 수신하고 저장하는 버퍼 역할을 합니다. 다음은 AWS CLI를 사용하여 SQS 대기열을 설정하고 이를 Lambda 함수의 트리거로 만드는 방법입니다.
먼저 새 SQS 대기열을 만듭니다. 이 대기열은 애플리케이션인 메시지 발신자로부터 사용자 데이터가 포함된 메시지를 수신합니다.
|
1 |
aws sqs create-queue --queue-name AnonymizeDataExampleQueue |
대기열을 만들면 대기열의 URL을 받게 됩니다. 이 URL은 대기열에 메시지를 보내고 람다 함수의 트리거로 구성하는 데 필요합니다.
다음으로 권한 및 트리거를 설정하는 데 필요한 SQS 대기열의 ARN을 가져와야 합니다. 다음 명령을 사용하여 ARN을 검색합니다:
|
1 |
aws sqs get-queue-attributes --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --attribute-names QueueArn |
교체 <your-region> 그리고 <your-account-id> 실제 AWS 지역과 계정 ID를 입력하세요.
출력에는 다음과 같은 내용이 포함됩니다. QueueArn와 같은 모양입니다:
|
1 2 3 4 5 |
{ "Attributes": { "QueueArn": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } } |
이제 Lambda 함수에 SQS 대기열에서 메시지를 읽을 수 있는 권한을 부여해야 합니다. 다음과 같은 이름의 정책 파일을 만듭니다. lambda-sqs-policy.json 를 다음과 같은 내용으로 업데이트합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sqs:ReceiveMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:DeleteMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:GetQueueAttributes", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } ] } |
이 정책을 람다 실행 역할에 적용하세요:
|
1 |
aws iam put-role-policy --role-name <your-lambda-execution-role> --policy-name LambdaSQSPolicy --policy-document file://lambda-sqs-policy.json |
다음으로, 람다 함수의 트리거로 SQS 대기열을 추가합니다:
|
1 |
aws lambda create-event-source-mapping --function-name AnonymizeDataExampleFunction --batch-size 10 --event-source-arn arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue |
이 명령은 SQS 대기열에 도착하는 메시지에 의해 트리거되도록 람다 함수를 설정합니다.
이제 Lambda 함수가 대기열 서비스로 전송되는 모든 메시지를 수신하도록 설정되었습니다. 워크플로우가 완료되었습니다! 이 설정을 통해 개인정보 보호 요건을 준수하면서 사용자 데이터를 효율적으로 처리할 수 있습니다.
로컬에서 구현 테스트
모든 것이 예상대로 작동하는지 확인하기 위해 직접 대기열에 메시지를 보내 워크플로우를 테스트할 수 있습니다. 명령줄에서 다음을 실행합니다:
|
1 |
aws sqs send-message --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --message-body "{\"record_id\": \"purchase_002\", \"item\": \"item_1\", \"user\": {\"first_name\": \"John\", \"last_name\": \"Doe\", \"ip_address\": \"192.168.1.1\"}, \"timestamp\": \"2024-07-01T12:34:56Z\"}" |
이 메시지는 Lambda 함수를 트리거하고, 이 함수는 데이터를 살균한 후 Couchbase 버킷에 데이터를 추가합니다. 메시지에서 보낸 샘플 데이터는 Capella 대시보드에 로그인하거나 VSCode 또는 Jetbrains IDE를 직접 사용할 수 있습니다.
마무리
오늘날 최신 애플리케이션을 구축, 배포 및 유지 관리하는 작업은 엄청난 작업입니다. 가능한 한 애플리케이션의 핵심 비즈니스와 직접적으로 관련이 없는 작업은 단순화하고 추상화하여 엔지니어, SRE 및 관련된 모든 사람의 인지 부하를 줄여야 합니다. 개인정보 보호 규정은 엄격하게 준수해야 하는 주요 항목 중 하나이며, 큰 골칫거리나 업무량 증가를 유발해서는 안 됩니다.
개인 식별 정보와 상호작용하는 모든 애플리케이션과 데이터가 저장된 데이터베이스 사이에 쉽게 배치할 수 있는 자동화된 플러그 앤 플레이 워크플로우를 구축하면 인지 부하를 크게 완화하고 부담을 줄이며 개발 프로세스를 간소화할 수 있습니다. AWS와 Couchbase를 함께 활용하면 실시간 데이터 살균 요구 사항을 충족하여 사용자 무결성과 엔지니어링 생산성을 모두 보장할 수 있습니다.
