저는 이제 막 데이터 흐름을 자동화하는 도구인 NiFi를 사용하기 시작했습니다. 마이그레이션, 동기화 및 기타 유형의 데이터 처리를 위한 도구입니다. Couchbase의 신규 고객 중 하나인 신시내티 레즈에서 소개해 주었습니다.
이 게시물에서는 Reds가 NiFi를 사용하는 용도에 대해 설명하고 SQL Server에서 Couchbase Server로 아주 기본적인 데이터 흐름을 시작하고 실행하는 방법을 보여드리겠습니다.
니파이와 레드
뉴욕 레드삭스는 경기 당일 그레이트 아메리칸 볼 파크에서 티켓을 스캔하는 모습을 비주얼라이제이션으로 만들고자 합니다.
데이터 팀은 경기에 대한 실시간 데이터를 저장하는 데 사용되는 SQL Server 데이터베이스에 액세스할 수 있습니다. 게이트에서 티켓을 스캔할 때마다 데이터가 이 데이터베이스에 저장됩니다. (이 데이터베이스는 할인 및 기타 데이터도 추적합니다).
Reds는 SQL Server에서 직접 데이터를 쿼리할 수도 있지만, 게임 시간이 많은 동안 실시간으로 시각화하면 시각화 속도가 느려지거나 데이터베이스에 너무 많은 부하가 걸리거나 둘 다 발생할 수 있습니다. 대신 해당 데이터를 Couchbase 클러스터에 복사하고 이 클러스터를 시각화의 백엔드로 사용하고자 합니다.
데이터를 카우치베이스로 옮기는 방법에는 여러 가지가 있지만, Reds는 이미 오픈 소스 Apache NiFi와 SQL Server를 사용하고 있으므로 이 프로젝트에도 동일한 조합을 사용할 수 있다면 이상적일 것입니다. 다행히도 NiFi는 이미 Couchbase를 지원하므로 매우 쉽게 할 수 있습니다.
NiFi 및 Couchbase 시작하기
로컬에서 NiFi 실험을 시작하기 위해 저는 Docker를 사용하기로 결정했습니다. Docker 호스트 내에서 각각의 인스턴스를 쉽게 스핀업할 수 있습니다:
- 카우치베이스 서버 (물론)
- Apache Nifi (도커 허브 링크)
- Microsoft SQL Server (Linux의 경우 - Reds가 Linux용 SQL을 사용하는 것 같지는 않지만 비슷합니다)
Docker를 사용할 필요는 없지만, 바로 시작하고 실행하여 생산성을 높이는 것이 매우 쉬웠습니다.
다음은 제가 Docker 이미지를 실행하는 데 사용한 명령어입니다:
|
1 2 3 4 5 |
docker run -d --name db55beta -p 8091-8094:8091-8094 -p 11210:11210 couchbase:5.5.0-beta docker run -d --name NiFi -p 8080:8080 apache/nifi:latest docker run -d -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=<use a strong password here>' -p 1433:1433 microsoft/mssql-server-linux:2017-latest |
SA_PASSWORD에 입력하는 비밀번호에 유의하세요. 필수 SQL Server의 강력한 비밀번호 요구 사항을 충족해야 합니다. 그렇지 않으면 SQL Server를 사용할 수 없으며 약 20분 동안 약간의 좌절감과 혼란을 겪게 됩니다.
SQL Server로 시작하기
SQL Server 관리 스튜디오를 사용하여 Docker(로컬 호스트, 포트 1433)의 SQL Server 인스턴스에 연결했습니다. 아직 Reds의 실제 서버에 액세스할 수 없기 때문에 대략적인 스키마를 직접 만들어 보았습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE [dbo].[TicketCheck]( [Id] [uniqueidentifier] NOT NULL, [FullName] [varchar](100) NOT NULL, [Section] [varchar](10) NOT NULL, [Row] [varchar](10) NOT NULL, [Seat] [varchar](10) NOT NULL, [GameDay] [datetime] NOT NULL, CONSTRAINT [PK_TicketCheck] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[TicketCheck] ADD CONSTRAINT [DF_TicketCheck_Id] DEFAULT (newid()) FOR [Id] GO |
나중에는 이 파일을 삽입 문과 같이 작성합니다:
|
1 2 3 4 5 6 7 |
INSERT INTO TicketCheck (FullName, Section, [Row], Seat, GameDay) VALUES ( 'Joey Votto', '429', 'C', '11', GETDATE() ) |
카우치베이스 설정
Couchbase에 처음 로그인(localhost:8091)하고 클러스터를 생성한 후 두 가지 작업을 수행했습니다:
- "티켓"이라는 버킷을 만들었습니다. 이 버킷에 SQL Server의 데이터를 저장합니다.
- 사용자를 만들었습니다. 또한 버킷에 대한 적절한 권한과 함께 "티켓"이라는 이름의 버킷을 생성합니다. 사용자의 이름이 버킷과 같은 것이 중요합니다.
같은 이름의 사용자를 만들어야 하는 이유는 NiFi Couchbase 프로세서가 약간 오래되었기 때문이므로 이 방법은 해결 방법입니다. NiFi는 아직 Couchbase의 새로운 RBAC 기능을 처리하도록 업데이트되지 않았습니다. Apache Nifi 참조 5054호 에서 자세한 내용을 확인하세요.
NiFi 설정
NiFi는 웹 기반의 시각적 데이터 흐름 도구입니다. 저는 개발자로서 코드와 명령줄에 익숙하지만, 시각적인 인터페이스가 있으면 정말 유용하게 사용할 수 있습니다.
Docker를 사용하는 경우 다음을 방문하세요. localhost:8080/NiFi. 그래프 종이처럼 보이는 큰 시트가 표시되고 그 위에 몇 개의 도구 모음/창이 있습니다.
잠시 설명을 건너뛰고 제가 구축한 전체 데이터 흐름을 보여드리겠습니다:
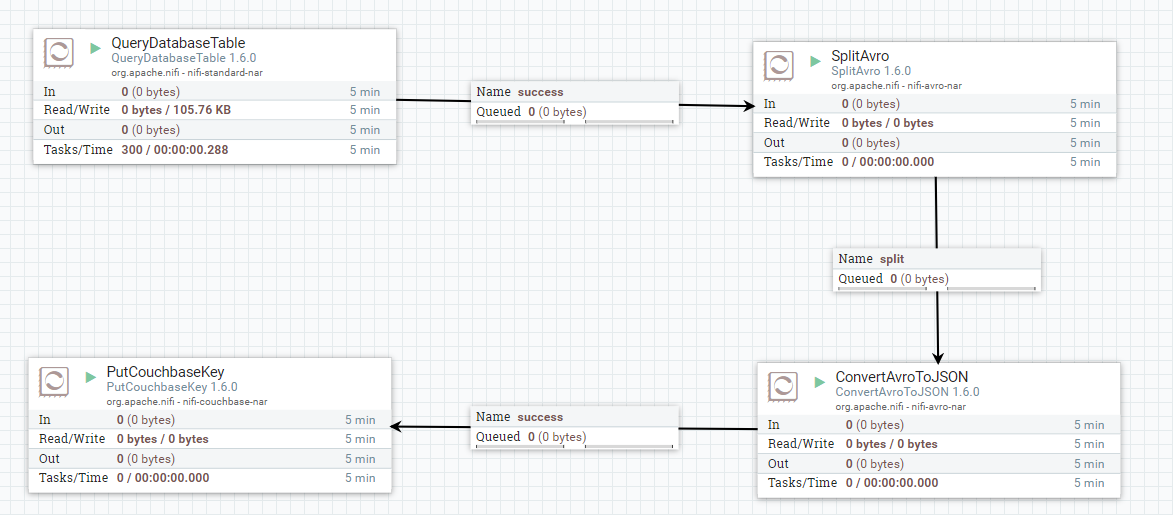
단계별로 설명해 드리겠지만, 저는 NiFi 전문가가 아니라는 점을 염두에 두시기 바랍니다.
높은 수준에서 보면 이러한 각 상자는 '프로세서'입니다. 각 상자는 어딘가에서 데이터를 가져와서 어떤 방식으로든 데이터를 처리한 다음 다른 곳에 데이터를 씁니다. 이러한 데이터의 '흐름'은 외부 소스나 NiFi 대기열에서 가져오거나 외부 소스에 기록될 수 있습니다. 각 프로세서는 "시작" 및 "중지"될 수 있습니다.
데이터베이스 연결 풀링 서비스
프로세서를 만들기 전에 NiFi에 사용할 데이터베이스에 대해 알려주세요.
그래프 용지 위에 '작동' 창이 떠 있습니다. 설정 아이콘을 클릭하여 NiFi 플로우 구성 창을 불러옵니다.
컨트롤러 서비스 탭을 살펴보세요. 저는 이것을 프로세서가 연결할 수 있는 외부 데이터 소스의 모음이라고 생각합니다. 두 개의 컨트롤러 서비스를 추가하겠습니다. 하나는 SQL Server용이고 다른 하나는 Couchbase용입니다.
DBCPConnectionPool
추가하려면 "+" 버튼을 클릭합니다. SQL Server부터 시작하겠습니다. DBCPConnectionPool을 찾아 "추가"를 클릭합니다. 목록에 나타납니다. 톱니바퀴 아이콘을 클릭하고 속성 탭으로 이동합니다:
- 데이터베이스 연결 URL - 다음과 같은 값을 입력합니다.
JDBC:SQL서버://172.17.0.4. - 데이터베이스 드라이버 클래스 이름 - SQL Server를 사용하는 경우, 다음과 같습니다.
com.microsoft.sqlserver.jdbc.SQLServerDriver - 데이터베이스 드라이버 위치 - 입력
file:///usr/share/java/mssql-jdbc-6.4.0.jre8.jar. NiFi는 이 드라이버를 기본적으로 제공하지 않습니다(적어도 Docker 이미지는 제공하지 않습니다). Microsoft에서 이 드라이버 다운로드 를 다운로드하여 NiFi 서버의 /usr/share/java 폴더에 넣습니다(도커 cp저처럼 Docker를 사용하는 경우). - 데이터베이스 사용자 그리고 비밀번호 - 연결에 필요한 SQL Server 자격 증명입니다.
추가한 후에는 이를 사용하려면 '활성화'(번개 아이콘 클릭)해야 합니다. 나중에 변경해야 하는 경우 먼저 비활성화해야 합니다.
카우치베이스클러스터서비스
다음으로 NiFi에 Couchbase에 대해 알려주세요. 다시 "더하기" 버튼을 클릭하여 추가합니다. CouchbaseClusterService를 찾습니다. 다시 속성 탭으로 이동합니다. 다음과 같은 속성이 하나 있을 것입니다. 연결 문자열. 다음과 같이 입력합니다. couchbase://172.17.0.3. 그런 다음 이 탭에서 "더하기" 버튼을 클릭하고 "티켓의 버킷 비밀번호"라는 새 속성을 만듭니다. 속성 이름은 다음과 같은 형식이어야 합니다. "의 버킷 비밀번호". 이 속성의 값은 이전에 생성한 Couchbase 사용자의 비밀번호여야 합니다.
이제 NiFi는 SQL Server와 Couchbase에 대해 알고 있습니다. 이제 이를 활용해 보겠습니다.
쿼리 데이터베이스 테이블
데이터의 소스인 SQL Server부터 시작하겠습니다. 더 구체적으로는 SQL Server의 테이블입니다. 그리고 더 구체적으로, 해당 테이블의 새 데이터 행만 정의하겠습니다(나중에 정의하는 방법에 대해 자세히 설명합니다).
먼저 왼쪽 상단의 '프로세서' 아이콘을 그래프 용지로 드래그합니다. 그런 다음 QueryDatabaseTable 프로세서를 찾아 "추가"를 누릅니다. 이 시점에서 보드에 몇 가지 구성이 필요함을 나타내는 경고 아이콘과 함께 프로세서가 표시됩니다.
이 프로세서를 두 번 클릭하면 세부 정보를 불러올 수 있습니다. 저는 주로 '속성' 탭에 관심이 있습니다. 이 탭에서는 이 프로세서에 연결할 데이터베이스와 데이터 쿼리 방법을 알려주려고 합니다:
관심 있는 속성입니다:
- 데이터베이스 연결 풀링 서비스 - 앞서 생성한 DBCPConnectionPool을 선택합니다.
- 데이터베이스 유형 - 저는 MS SQL 2008을 선택했는데, 이는 Linux용 MS SQL과 잘 작동하는 것 같지만 MS SQL 2012+ 및 "일반"에 대한 옵션도 있습니다.
- 테이블 이름 - 쿼리할 테이블의 이름을 입력합니다.
티켓 확인를 사용했습니다. - 최대값 열 - 입력했습니다.
게임데이. 이 열은 NiFi가 테이블에서 새/업데이트된 데이터를 찾기 위해 확인하는 열입니다. 자동 증가 필드, 타임스탬프 또는 다른 조합을 사용할 수 있습니다. NiFi 프로세서는 진행하면서 최신 값을 '상태'로 저장합니다.
PutCouchbaseKey
조금 건너뛰고 다른 프로세서를 만들어 보겠습니다. 이번에는 PutCouchbaseKey 프로세서가 될 것입니다. 이 프로세서는 유입되는 데이터를 받아 해당 데이터로 Couchbase 문서를 생성/업데이트합니다.
구성하려면 다음 속성을 설정합니다:
- Couchbase 클러스터 컨트롤러 서비스 - 이전에 생성한 CouchbaseClusterService를 선택합니다.
- 버킷 이름 - 티켓
A 지점에서 B 지점으로 이동
이 시점에서 NiFi는 SQL Server에서 데이터를 가져와 Couchbase에 문서를 넣을 수 있습니다. 이를 마무리하려면 연결해야 합니다. 하지만 아직 해야 할 일이 조금 남아 있습니다. QueryDatabaseTable 프로세서는 "Avro" 데이터를 출력하는데, 이 데이터는 Hadoop용으로 설계되었지만 Spark와 물론 Nifi에서도 사용됩니다. 이 데이터를 Couchbase에 직접 공급할 수도 있지만, JSON이 아닌 바이너리 데이터로 저장됩니다. 따라서 순수한 JSON 형식으로 변환하기 위해 몇 가지 중간 단계가 필요합니다.
그래프 용지에 SplitAvro 프로세서와 ConvertAvroToJSON 프로세서를 추가했습니다.
SplitAvro 프로세서는 (잠재적으로 큰) Avro 데이터 파일을 더 작은 파일로 분할합니다. 꼭 필요한 것은 아니지만, 데이터를 분할하면 데이터를 더 쉽게 보고 디버깅할 수 있으므로 좋은 예방 조치입니다. 이 프로세서의 기본 속성은 괜찮습니다.
ConvertAvroToJSON 프로세서는 지시하는 대로 정확하게 수행합니다. 이렇게 하면 Couchbase용 Avro 데이터가 준비됩니다. 저는 JSON 컨테이너 옵션 속성에서 배열 에 없음. 단일 문서가 포함된 배열이 아닌 일반 JSON 문서만 원합니다.
모든 것을 연결하기
이제 이 네 가지 조각을 제자리에 배치했으니 연결해야 합니다.
먼저 화살표 아이콘이 나타날 때까지 QueryDatabaseTable 위에 마우스를 갖다 댑니다. 이 화살표를 클릭하고 SplitAvro 프로세서로 드래그합니다. 그 사이에 "성공"이라는 이름의 대기열이 나타납니다.
다른 프로세서에서도 이 과정을 반복합니다. 프로세서에는 관계를 정의하는 다양한 종료 지점이 있을 수 있습니다. 예를 들어 SplitAvro와 ConvertAvroToJSON 사이의 연결을 드래그하면 실패, 원본, 분할의 세 가지 선택 사항이 표시됩니다. 이는 프로세서마다 다르지만 대략적인 개념은 다음과 같습니다:
- 실패 - SplitAvro가 변환에 실패하면 데이터를 "실패"로 전송합니다.
- 원본 - SplitAvro는 다음과 같은 방식으로 원본 데이터를 파이프할 수 있습니다.
- 분할 - 실제 분할 데이터는 이런 식으로 진행됩니다. 이것이 ConvertAvroToJSON에 입력해야 하는 데이터입니다.
다른 연결을 사용하면 데이터를 프로세스로 다시 파이프하여 다시 시도하거나 알림 또는 디버깅 프로세서로 파이프할 수도 있습니다.
NiFi 흐름 켜기
프로세서를 시작하려면 해당 프로세서를 클릭한 다음 운영 창에서 '시작' 버튼을 클릭합니다(VCR의 재생 버튼처럼 생겼습니다). 한 번에 하나의 프로세서로만 실험하고 데이터가 대기열에 쌓이기 시작하는 것을 지켜볼 수도 있습니다. 궁극적으로 SQL Server 테이블에 행을 삽입하기 시작하면 Couchbase Server에서 새 문서로 끝나야 합니다.
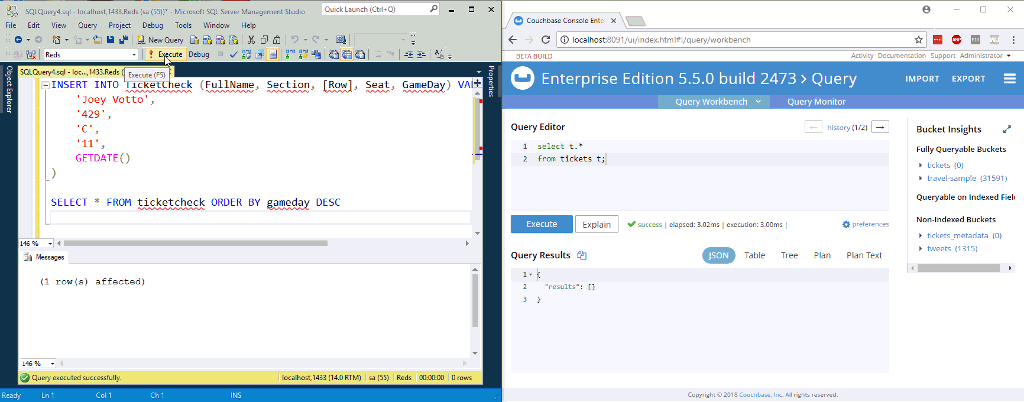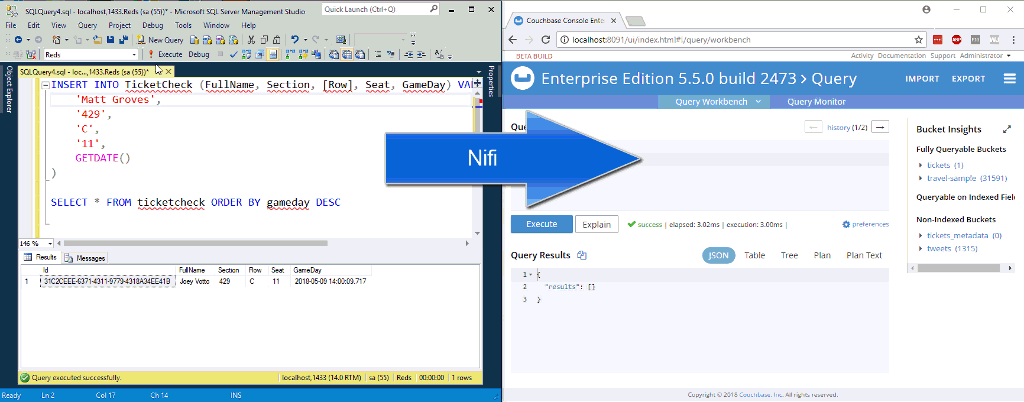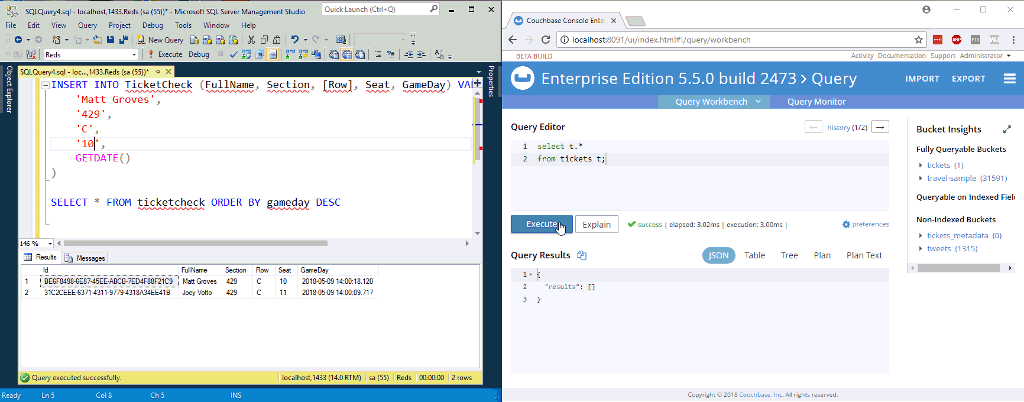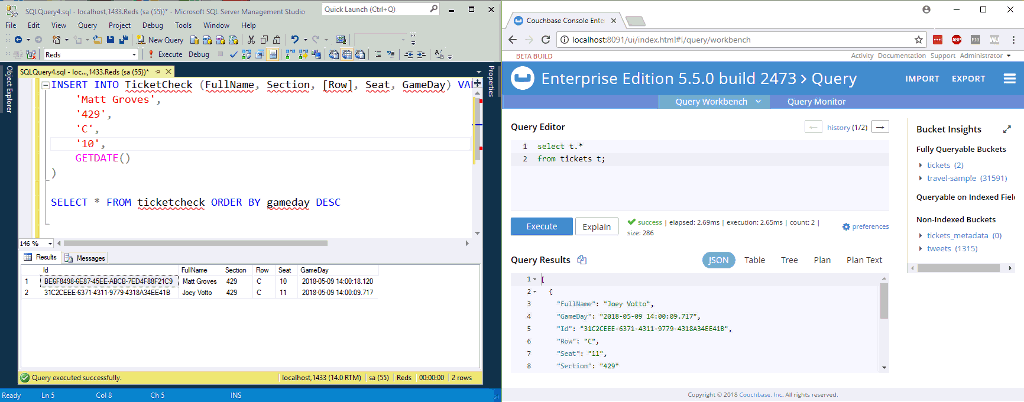
위의 애니메이션에서는 SQL Server의 테이블에 두 개의 새 행을 삽입하고 있습니다. NiFi(사진에 표시되지 않음)가 이를 처리하여 Couchbase에 넣습니다.
요약
이 블로그 게시물은 NiFi를 시작하는 방법에 대한 배경 지식을 제공합니다. 할 수 있는 일은 많습니다. 다양한 데이터 소스가 있는 기업에서 NiFi는 모든 데이터 흐름을 조율할 수 있는 훌륭한 도구입니다. 카우치베이스 서버도 매우 적합합니다:
- JSON의 유연성으로 거의 모든 소스에서 데이터를 수집할 수 있습니다.
- 메모리 우선 아키텍처는 데이터 흐름의 성능을 극대화하는 데 도움이 됩니다.
- Couchbase의 확장 기능으로 플로우를 오프라인으로 전환하지 않고도 용량을 늘릴 수 있습니다.
저는 이제 막 NiFi를 처음 배웠는데, 그래픽 인터페이스와 시작의 간편함이 벌써부터 마음에 듭니다. 아직 배워야 할 것이 많지만 이 포스팅이 NiFi에서 Couchbase 프로세서를 사용하는 데 도움이 되길 바랍니다.
NiFi와 couchbase를 사용하고 계신다면 여러분의 의견을 듣고 싶습니다. 카우치베이스 커넥터는 업데이트된(5054호 참조), 더 많은 분들의 의견을 들을수록 작업 시간을 정당화하기가 더 쉬워집니다.
카우치베이스에 대해 궁금한 점이 있으시다면 카우치베이스 서버 포럼. NiFi에 대해 궁금한 점이 있으면 Apache Nifi 프로젝트 웹사이트.
위의 모든 사항에 대해 기꺼이 상담해 드리겠습니다. 아래에 댓글을 남기거나 다음에서 저를 찾을 수 있습니다. 트위터 @mgroves.