비즈니스 애플리케이션에 자주 등장하는 데이터 구조는 계층적 데이터 구조입니다. 계층 구조는 종종 동일한 개체 간의 상위-하위 관계를 캡처합니다. 예를 들어 회사 구조는 직원 간의 보고 라인을 캡처합니다. 비즈니스 조직은 모회사와 자회사 간의 관계를 캡처합니다. 영업의 지역 계층 구조. 재무 애플리케이션의 계정 장부.
계층 구조의 자체 참조 특성으로 인해 관련 데이터와 함께 구조를 효율적으로 쿼리하는 것은 특히 성능 관점에서 RDBMS에 어려운 과제일 수 있습니다. 이 글에서는 기존 RDBMS가 계층형 쿼리를 처리하는 방법에 대해 설명합니다. 그리고 이를 처리해야 하는 과제와 이 문제를 Couchbase N1QL과 Couchbase GSI에서 어떻게 유사하게 해결할 수 있는지에 대해 설명합니다.
애플리케이션의 계층 구조
계층 구조로 정보를 수집하는 주된 이유는 정보에 대한 이해를 높이기 위해서입니다. 회사 보고 구조는 조직 관리 방식에 도움이 될 뿐만 아니라 각 그룹의 효율성을 측정하고 최적화할 수 있는 구조를 제공하기 위해 고안되었습니다. 대규모 조직에서 영업 성과는 종종 개인 수준뿐만 아니라 영업팀 수준에서도 평가됩니다. 즉, 기업은 비즈니스 성과를 더 잘 이해할 수 있도록 계층적 구조로 정보를 정리합니다. 이러한 목표를 달성하기 위해서는 계층적 데이터를 효율적으로 쿼리할 수 있는 수단이 필요합니다.
회사 계층 구조 표현
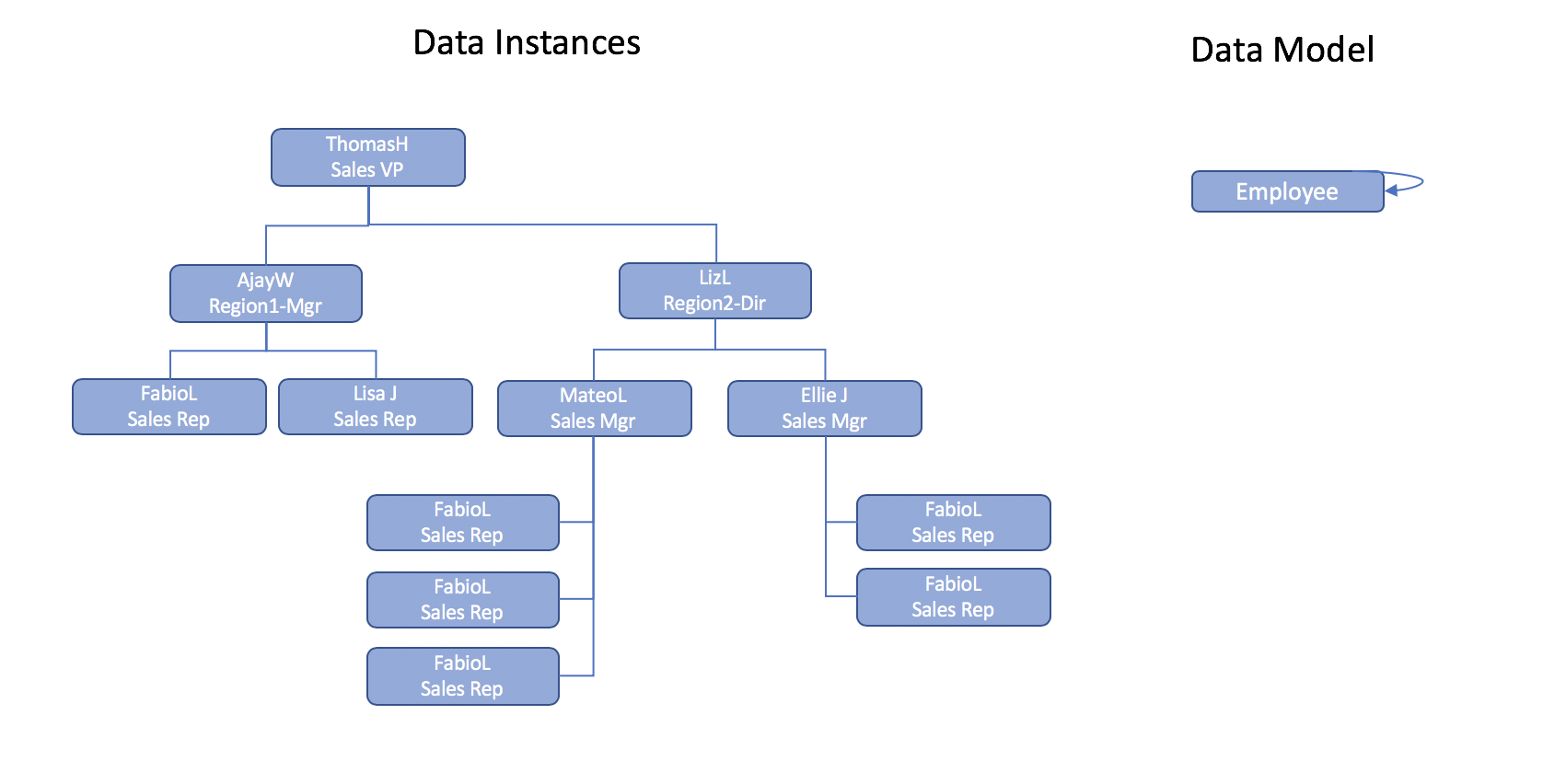
데이터베이스 데이터 모델은 계층 구조를 효율적으로 캡처할 수 있지만, 계층 데이터와 관련 정보를 쿼리해야 할 때 어려움이 발생합니다.
이 요구 사항을 고려하세요: ThomasH-영업 부사장까지 보고하는 모든 영업 담당자의 총 판매 주문 금액을 가져옵니다.
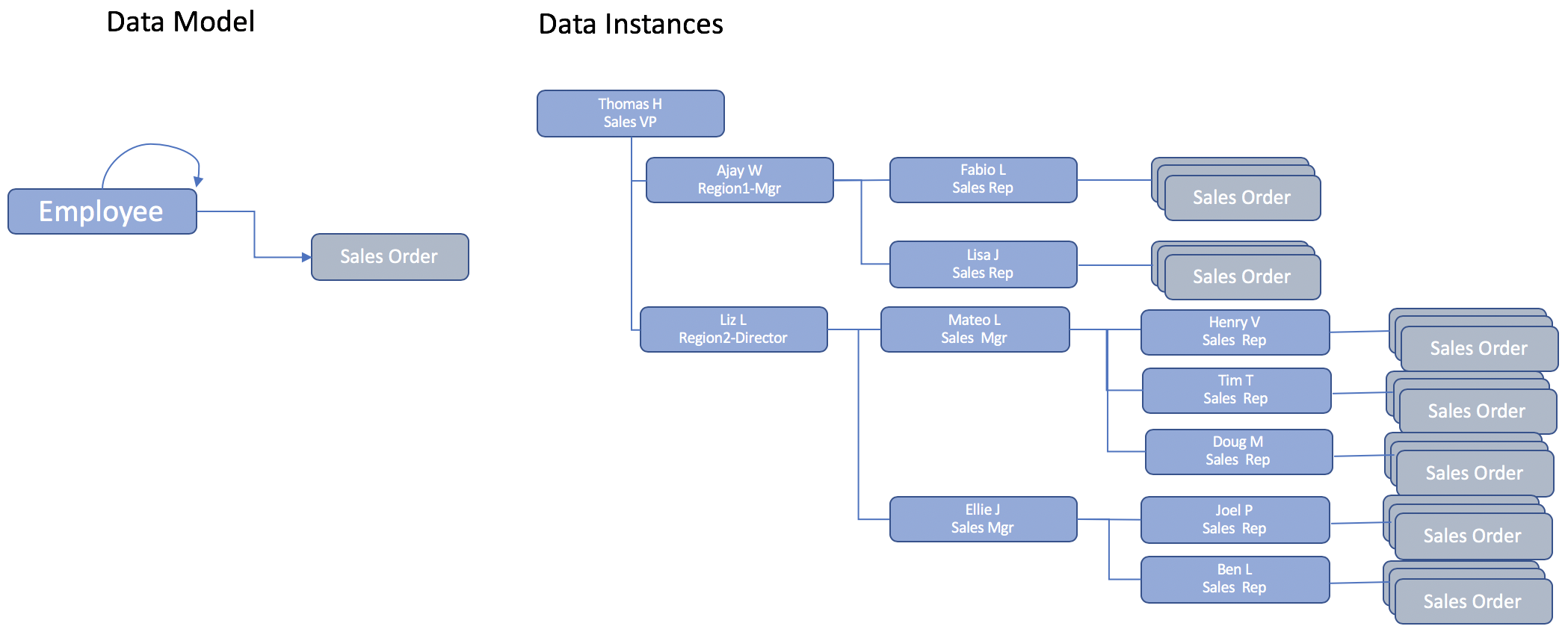
데이터 모델은 비교적 단순합니다. 영업 조직의 계층적 특성은 보고 계층 구조에 내재된 동적 구조를 암시합니다. Region1 지역을 총괄하는 AjayW는 영업 팀원들을 직접 관리합니다. 반면, Region2에서는 Liz L이 두 명의 매니저를 관리하고, 이들이 다시 영업팀을 관리합니다. 이는 대부분의 애플리케이션 데이터 계층 구조에서 일반적입니다.
RDMBS 접근 방식
계층형 데이터를 쿼리하기 위해 Oracle 및 SQLSever와 같은 기존 RDBMS는 단일 쿼리가 계층형 직원 구조를 재귀적으로 횡단할 수 있도록 CONNECT BY / START WITH 구문을 제공합니다.
|
1 2 3 4 5 6 7 8 |
Query: Sales orders generated by members who report up to ThomasH-Sales VP</strong></span> SELECT e.EmpID, e.Name, e.ManagerID, sum(o.orderVal) FROM employee e INNER JOIN sales_order o ON o.EmpID = o.EmpId START WITH EmpID = 101 CONNECT BY PRIOR EmpID = ManagerID GROUP BY e.EmpID, e.Name, e.ManagerID; |
위의 쿼리는 간단해 보이지만, CONNECT BY 구현의 재귀적 특성으로 인해 인덱스를 사용하면 쿼리 성능을 개선하기 어렵습니다. 이러한 이유로 이 기법은 대량의 데이터가 있는 시스템의 애플리케이션 개발에서는 널리 사용되지 않습니다. 대신, 엔터프라이즈 애플리케이션은 보다 예측 가능한 쿼리 성능을 위해 미리 평탄화된 객체 구조를 사용합니다. 평탄화된 계층 구조 기법은 아래의 Couchbase N1QL 섹션에 설명되어 있습니다.
카우치베이스 N1QL
최상의 쿼리 성능을 얻으려면 N1QL 애플리케이션은 평탄화된 계층 구조를 사용해야 합니다. 이 접근 방식은 더 예측 가능한 성능을 제공할 뿐만 아니라 Couchbase GSI를 더 잘 활용할 수 있습니다. 아래 다이어그램은 직원 개체와 같은 자체 참조 계층 구조의 플랫화 변환의 예를 보여줍니다. 아래에 계층 구조를 평탄화하는 데 사용할 수 있는 Python 코드 스니펫도 포함되어 있습니다. 이 코드의 플랫화_계층 함수는 자체 참조하는 계층적 JSON 객체를 가져와 동일한 키 공간에 다른 유형 값을 가진 두 개의 새 객체를 생성합니다.
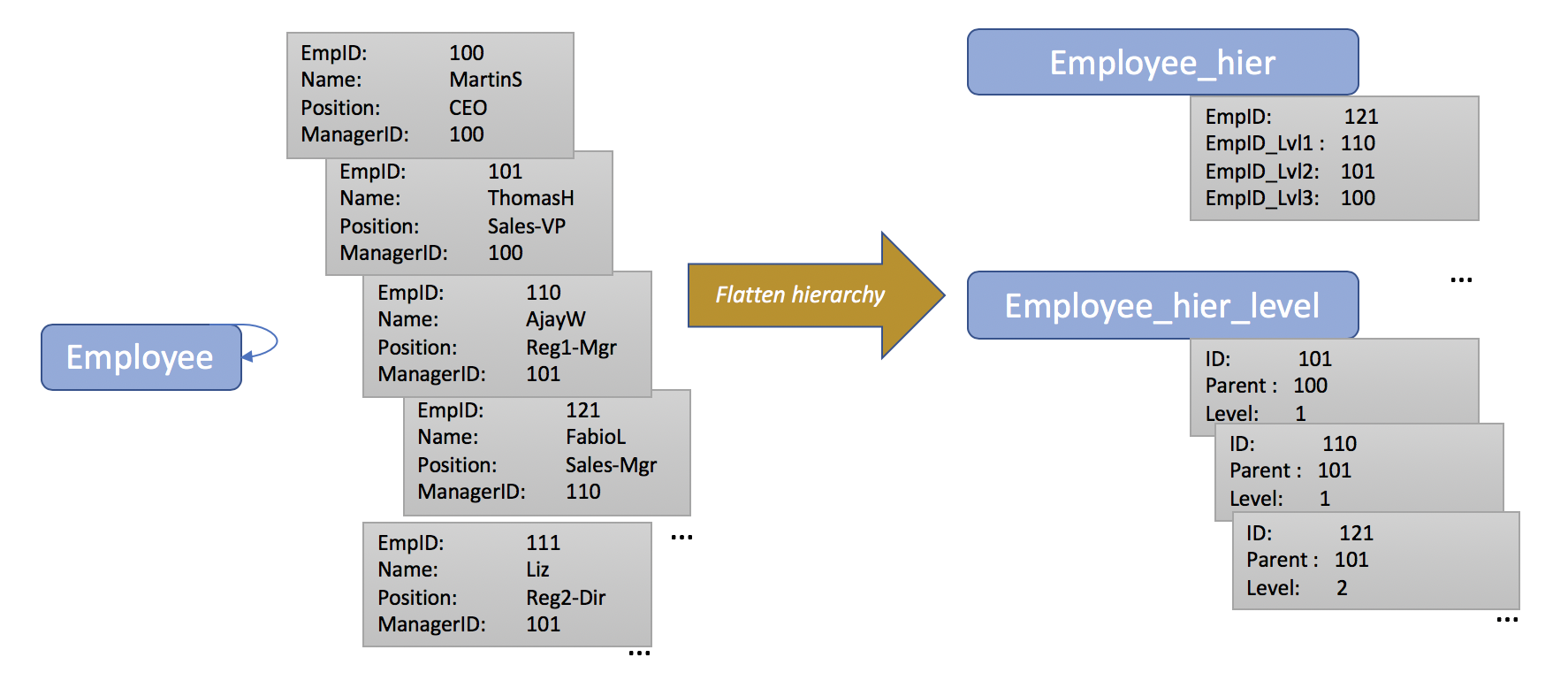
- 그리고 object_hier 구조는 각 수준별로 쿼리 결과를 롤업할 수 있는 집계된 BI 쿼리와 함께 작동합니다.
- 그리고 object_hier_level 구조는 특정 노드의 모든 하위 개체를 반환하는 CONNECT BY/START WITH 절과 동일한 결과를 제공합니다. 이것이 바로 쿼리 솔루션을 제공하기 위해 N1QL 쿼리에서 사용할 객체입니다.
|
1 2 3 4 5 6 7 8 9 10 |
N1QL Query: Sales orders generated by members who report up to ThomasH-Sales VP SELECT e.id,sum(a.value) FROM crm a INNER JOIN ( SELECT uhl.id FROM crm uhl WHERE uhl.type ='_employee_hier_level' AND uhl.parent='101') e USE HASH(probe) ON a.owner = e.id WHERE a.type='sales_order' GROUP BY e.id |
추천 GS 지수:
|
1 |
CREATE INDEX `crm_employee_hier_level` ON `crm`(`parent`) WHERE (`type` = "_employee_hier_level") |
참고:
- 기본 쿼리는 모든 판매 주문을 검색합니다.
crm유형 값이 'salesorder'인 버킷 - 이 쿼리는 사용자101에 보고하는 모든 직원 ID, 즉 ThomasH-SalesVP를 검색하는 다른 쿼리(N1QL 6.5 기능)와 해시 조인(HASH JOIN)을 수행합니다.
- 추가 커버링 인덱스도 쿼리 성능을 향상시킬 수 있습니다.
- 쿼리는 표현식 및 하위 쿼리 용어에 대한 N1QL 6.5 ANSI JOIN 지원을 사용합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# Python code to flatten a JSON document in Couchbase bucket from couchbase.cluster import Cluster from couchbase.cluster import PasswordAuthenticator from couchbase.exceptions import NotFoundError from couchbase.bucket import Bucket from couchbase.n1ql import N1QLQuery def flatten_hierarchy(cb,bucketname,src_doc_type,num_hier_level,node_id_col, parent_id_col): # Example: flatten_hierarchy(cb,args.bucket,'user',4,'id','managerid') # cb - couchbase bucket handle # bucketname - name of the bucket for the source and target documents # src_doc_type - the type value of the source document # num_hier_level - specifies the number of levels that are needed. Should be the max depth of the hierarchy # node_id - the field name in the document for the key node id # parent_node_id - the parent field # gen_doc_type = '_'+src_doc_type+'_hier' if (num_hier_level > 1): qstr_ins = 'INSERT into '+bucketname+' (KEY UUID(), VALUE ndoc) ' qstr_sel = 'SELECT { "type":"'+gen_doc_type+'"' for i in range(1,num_hier_level+1): qstr_sel += ',"id'+str(i)+'":l'+str(i)+'.'+node_id_col qstr_sel += '} ndoc' qstr_sel_one = ' SELECT '+node_id_col+','+parent_id_col+' FROM '+bucketname+' WHERE type="'+src_doc_type+'"' for i in range(1,num_hier_level+1): if (i==1): qstr_sel += ' FROM ('+qstr_sel_one+') l'+str(i) else: qstr_sel += ' LEFT OUTER JOIN ('+qstr_sel_one qstr_sel += ') l'+str(i)+' ON l'+str(i-1)+'.'+parent_id_col+' = l'+str(i)+'.'+node_id_col try: #q = N1QLQuery(qstring) rows = cb.n1ql_query(qstr_ins+qstr_sel).execute() except Exception as e: print("query error",e) # generate connect by if (num_hier_level > 1): qstr_ins = 'INSERT into '+bucketname+' (KEY UUID(), VALUE ndoc) ' qstr_sel = 'SELECT { "id":ll.child,"parent":ll.parent,"level":ll.level ,"type":"'+gen_doc_type+'_level" } ndoc FROM (' for i in range(1,num_hier_level): if (i>1): qstr_sel += 'UNION ALL ' qstr_sel += 'SELECT id'+str(i+1)+' parent, id1 child,'+str(i)+' level FROM '+bucketname+' WHERE type="'+gen_doc_type+'" and id'+str(i+1)+' IS NOT NULL ' qstr_sel += ') ll' try: rows = cb.n1ql_query(qstr_ins+qstr_sel).execute() except Exception as e: print("query error",e) return |
리소스
6.5의 기능이 마음에 드셨는지, 앞으로 비즈니스에 어떤 도움이 될지 여러분의 의견을 듣고 싶습니다. 댓글을 통해 의견을 공유해 주시거나 포럼.
내부 조인을 사용한 N1QL 쿼리가 더 이상 CB6에서 작성된 대로 작동하지 않습니다.
[
{
"코드": 3000,
"msg": "ANSI JOIN은 키 공간에서 수행해야 합니다. - 어디서 \n 구문 분석 중 오류: 런타임 오류: 잘못된 메모리 주소 또는 nil 포인터 역참조 - 어디서",
"쿼리_프롬_유저": "SELECT uhl.id FROM test uhl \r\nINNER JOIN (SELECT e.id,sum(a.
값) \r\nFROM test a\r\n WHERE a.type='sales_order' ) e ON a.owner = e.id\r\nwhere uhl.type ='_employee_hier_level'\r\n AND uhl.parent='101'\r\nGROUP BY e.id"}
]
또한 키워드
값는 다음과 같아야 합니다.인용또는 구문 오류입니다. 다음과 같은 경우SELECT e.id,sum(a.
값), (SELECT uhl.id FROM test uhl WHERE uhl.type ='_employee_hier_level'AND uhl.parent='101′) e
FROM test a
WHERE a.type='sales_order' 및 a.owner = e.id
e.id 기준 그룹화
작동하지만 사용 해시에 대해 잘 모르겠습니다...
이 쿼리는 새로운 N1QL 6.5 기능인 표현식 용어 및 하위 쿼리 용어에 대한 ANSI JOIN 지원을 사용합니다. 6.5는 5월 말에 베타 버전이 출시될 예정입니다. 초기 빌드에 관심이 있으시면 알려주세요. 데이터 집합을 사용할 수 있도록 하는 방법도 검토 중입니다.
고마워요,
-binh
몇 가지 샘플 JSON 데이터를 제안하는 것도 좋을 것입니다.
Oracle ATP와 MS SQL Server 모두 계층 기능 및 특수 계층 데이터 유형을 제공합니다. CouchBase와의 차이점을 명확히 설명해 주시겠어요? ANSI SQL 및/또는 CouchBase는 다음과 같은 SQL 키워드를 추가하나요? "연결 기준" 및 "수준"? TIA.
안녕하세요 CM27,
카우치베이스 쿼리는 "CONNECT BY" 키워드를 지원하지 않습니다. 관계 탐색 기능은 계획 중에 있습니다. 같은 맥락에서 CONNECT BY는 Oracle 전용 기능인 반면, 재귀적 CTE는 관계 쿼리를 위한 ANSI 접근 방식입니다.
-binh