애플리케이션 개발자의 주된 관심사는 애플리케이션에 가장 효율적인 쿼리를 설계하는 것입니다. 애플리케이션이 데이터베이스로 푸시하는 데이터의 무결성을 보장하고 애플리케이션에 필요한 데이터를 검색할 수 있는 가장 효율적인 쿼리를 구성하고자 합니다. 많은 경우 애플리케이션 성능은 개발 주기의 나중 단계로 연기됩니다. 성능 요구 사항을 충족하기 위해 쿼리 재작성을 포함하는 인덱스 설계에 대한 권장 사항을 제공할 수 있는 데이터베이스 성능 전문가에게 맡기는 경우가 많습니다. 그러나 쿼리의 성능을 이해하면 생산성이 크게 향상되고 개발자가 개발 주기 초기에 더 성능이 뛰어난 솔루션을 찾는 데 도움이 될 수 있습니다.
데이터베이스 공급업체는 이러한 문제를 잘 알고 있으며, 엔터프라이즈급 RDBMS에는 데이터베이스 도구 세트의 일부로 성능 조정 기능이 포함되어 있습니다.
Couchbase 6.5(DP)의 새로운 기능인 Couchbase N1QL 인덱스 어드바이저는 이제 N1QL 쿼리 문에 대한 GSI 인덱스에 대한 권장 사항을 제공합니다. 이 기능의 주요 목표는 쿼리 응답 시간을 최적화하기 위한 인덱스를 추천하는 것입니다. 개발자는 권장 인덱스를 생성하고 개발 주기 초기에 쿼리가 어떻게 수행되는지 확인할 수 있으므로 생산성을 높일 수 있습니다. 또한 DBA는 느리게 실행되는 쿼리를 주기적으로 검토하여 시스템 성능을 개선할 수 있습니다.
Couchbase 인덱스 어드바이저를 사용하는 방법은 인덱스 어드바이저 이해 그리고 인덱스 어드바이저 사용 시작 섹션을 참조하세요. 나머지 섹션에서는 완료된 요청에서 인덱스 어드바이저를 사용하는 팁과 자주 사용하지 않는 인덱스를 식별하는 방법을 비롯하여 인덱스 어드바이저가 권장 사항에 도달하는 방법에 대한 자세한 내용을 설명합니다.
인덱스 어드바이저 이해
데이터베이스 성능는 잘 관리하기 어려운 작업이지만 데이터베이스 공급업체에게는 잘 알려진 문제입니다. SaaS와 DBasS의 출현은 데이터베이스 성능 문제는 서비스의 일부일 뿐이며, 문제를 진단하고 해결하는 능력과 관련하여 자동화되어야 한다는 것을 의미합니다. 저희 개발팀은 이러한 비전을 향한 구성 요소를 만들기 위해 열심히 노력해 왔습니다.
Couchbase Index Advisor는 개발자와 DBA가 애플리케이션의 성능 튜닝 측면을 관리할 수 있도록 해주는 N1QL ADVISE 구성의 일부입니다. Index Advisor의 작동 방식을 이해하려면 Couchbase 데이터 플랫폼의 주요 데이터 검색 기술을 이해해야 합니다:
- 키-값 - 키를 사용할 수 있는 경우 데이터 서비스에 대한 빠르고 직접적인 데이터 액세스 방식입니다. 이 액세스 방법에는 카우치베이스 인덱싱 서비스가 포함되지 않습니다.
- 인덱싱 서비스(GSI) - 애플리케이션이 빠른 N1QL 쿼리를 수행할 수 있게 해주는 확장 가능한 서비스입니다. GSI는 분산 아키텍처를 활용하며 Couchbase 클러스터의 독립적인 노드 세트에 인덱스를 저장합니다.
- 검색(FTS) - 키워드 및 퍼지 검색을 제공하는 전체 텍스트 검색 서비스입니다. 모든 카우치베이스 서비스와 마찬가지로 FTS는 카우치베이스 클러스터 전체에 걸쳐 설정할 수 있는 분산 서비스입니다.
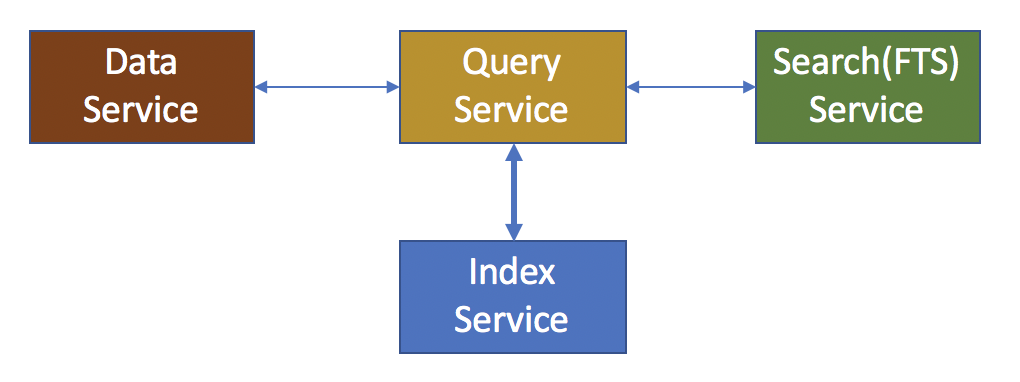
N1QL 쿼리는 위의 모든 서비스를 활용하여 쿼리 결과를 애플리케이션에 전달합니다. 그러나 v6.5(DP)의 인덱스 어드바이저는 인덱스 서비스(GSI)에서 관리하는 인덱스만 추천합니다. 인덱스 어드바이저는 USE KEYS를 통한 데이터 서비스 검색 기법이나 N1QL SEARCH_QUERY() 및 SEARCH() 함수를 통한 검색(FTS) 서비스를 평가하지 않습니다.
인덱스 어드바이저 사용 시작
앞서 말씀드렸듯이 Index Advisor는 데이터베이스 성능 조정을 위해 소개하는 일련의 기능 중 첫 번째 기능입니다. 인덱스 어드바이저는 애플리케이션 성능을 최적화할 수 있는 인덱스를 체계적으로 식별하고 키 순서에 대한 권장 모범 사례를 사용하여 인덱스를 생성할 수 있도록 도와줍니다. 실제로 인덱스 어드바이저는 쿼리에 대해 이미 작동 중인 인덱스가 있는 경우에도 권장 사항을 제공할 수 있습니다.
다음을 사용하여 N1QL 인덱스 어드바이저 사용을 시작할 수 있습니다:
N1QL - 조언 [인덱스]
|
1 2 3 4 5 6 7 |
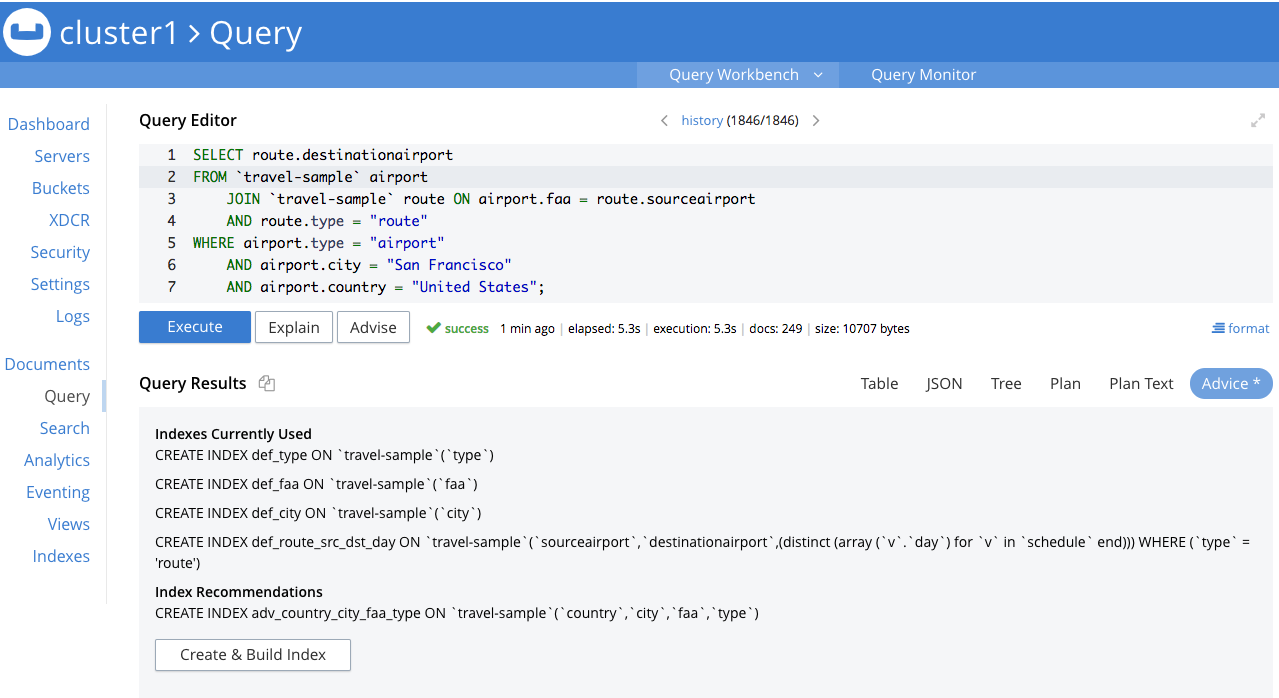
ADVISE SELECT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
[ { "#operator": "Advise", "advice": { "#operator": "IndexAdvice", "adviseinfo": [ { "current_indexes": [ { "index_statement": "CREATE INDEX def_city ON `travel-sample`(`city`)" }, { "index_statement": "CREATE INDEX def_type ON `travel-sample`(`type`)" }, { "index_statement": "CREATE INDEX def_faa ON `travel-sample`(`faa`)" }, { "index_statement": "CREATE INDEX def_route_src_dst_day ON `travel-sample`(`sourceairport`,`destinationairport`,(distinct (array (`v`.`day`) for `v` in `schedule` end))) WHERE (`type` = 'route')", "index_status": "THIS IS AN OPTIMAL COVERING INDEX." } ], "recommended_indexes": { "covering_indexes": [ { "index_statement": "CREATE INDEX adv_faa_country_city_type ON `travel-sample`(`faa`,`country`,`city`) WHERE `type` = 'airport'" } ], "indexes": [ { "index_statement": "CREATE INDEX adv_faa_country_city_type ON `travel-sample`(`faa`,`country`,`city`) WHERE `type` = 'airport'", "recommending_rule": "Index keys follow order of predicate types: 1. equality, 8. flavor for partial index." } ] } } ] }, "query": "SELECT route.destinationairport\nFROM `travel-sample` airport\n JOIN `travel-sample` route ON airport.faa = route.sourceairport\n AND route.type = \"route\"\nWHERE airport.type = \"airport\"\n AND airport.city = \"San Francisco\"\n AND airport.country = \"United States\";" } ] |
현재 인덱스 이 섹션에는 쿼리 플래너가 이 쿼리에 사용할 모든 기존 인덱스가 나열됩니다. 또한 쿼리 플래너가 커버링 인덱스로 사용하는 인덱스에 대한 추가 정보도 제공합니다.
추천 색인 - 이 섹션에는 인덱스 어드바이저가 권장하는 모든 인덱스가 나열되어 있습니다. 커버링 인덱스 권장 사항은 데이터 서비스에서 추가 가져오기 없이 쿼리가 작동할 수 있도록 하는 인덱스입니다. 반면, 인덱스 섹션에는 술어 절에 도움이 되는 인덱스만 표시됩니다. 이 두 섹션에는 정보가 중복될 수 있지만 인덱스 키가 동일한 경우 인덱스 이름이 동일하다는 점에 유의하세요.
또한 해당 인덱스를 추천한 이유도 제공합니다.
쿼리 워크벤치에서 조언 사용
조언 버튼을 클릭하여 쿼리에 대한 인덱스 어드바이저 출력을 얻습니다.
N1QL ADVISE는 SELECT, DELETE, UPDATE 및 MERGE에 대한 쿼리를 지원합니다. 다음에 대한 인덱스 권장 사항을 제공합니다:
- WHERE 절을 술어로 지정합니다.
- 인덱스 조인, ANSI 조인, 인덱스 네스트, ANSI 네스트 및 ANSI 병합에 대한 조인 조건 ON 절입니다.
- UNNEST의 배열 인덱스와 WHERE/ON 절의 배열 술어.
- FROM 절에 사용되는 경우 하위 쿼리.
인덱스 어드바이저의 작동 방식
인덱스 어드바이저의 작동 방식을 설명하기 위해 다음 접근 방식을 사용하겠습니다.
- 쿼리에 가장 적합한 인덱스가 무엇인지 추측하기 어려울 수 있는 일반적인 쿼리 구성(술어, 조인, 배열, 그룹화 기준)이 있는 예제를 선택하겠습니다.
- 쿼리 계획을 검토하여 현재 쿼리에 대해 옵티마이저가 수행할 작업을 파악합니다.
- 쿼리 성능을 개선하기 위해 어떤 인덱스를 만들지 수동으로 결정합니다. 이는 일반적인 애플리케이션 개발자의 술어 및 조인 필드 인덱스에 대한 이해를 기반으로 합니다.
- 그런 다음 Couchbase Index Advisor를 실행하고 권장 사항을 염두에 둔 권장 사항과 비교합니다.
- 권장 인덱스를 만듭니다.
- 새 쿼리 계획을 검토하고 변경 사항을 평가합니다.
예제 쿼리
이 쿼리는 미국 산호세시에 있는 모든 공항에서 일요일에 운항하는 항공편이 있는 항공사별 노선 수를 검색합니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT airline.name, airport.airportname, COUNT(1) FROM `travel-sample` airport INNER JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" INNER JOIN `travel-sample` airline ON route.airline = airline.iata AND airline.type = "airline" WHERE airport.type = "airport" AND airport.city = "San Jose" AND airport.country = "United States" AND ANY x in route.schedule SATISFIES x.day =0 END GROUP BY airline.name, airport.airportname |
쿼리 계획
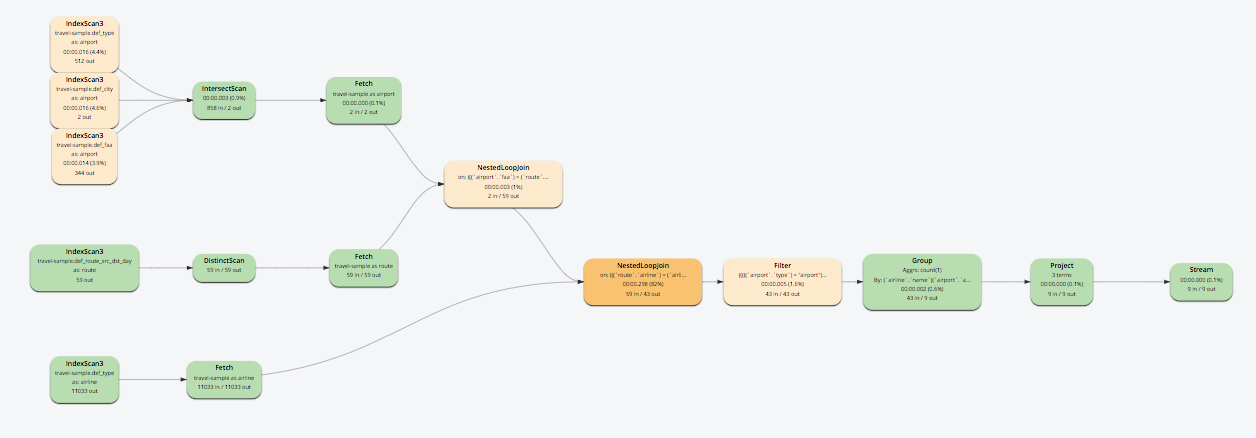
- 쿼리에는 5개의 인덱스가 사용되었습니다.
- 문서 유형 '공항'의 술어에는 'city', 'type', 'faa'의 세 가지 인덱스가 사용되었습니다.
- 'route'와 'airport' 간의 조인을 위해 'sourceairport' 필드의 문서 유형 'route'에 대해 하나의 인덱스가 사용되었습니다. 이 경우 기존 인덱스 'def_route_src_dst_day'는 선행 키가 'sourceairport'이기 때문에 사용되었습니다.
- 'type'에 대한 기본 부분 인덱스인 문서 유형 '항공사'에 대한 하나의 인덱스입니다.
- 'airport' - 'route' 및 'route' - 'airline'의 두 문서 NestedLoop 조인입니다. 그러나 'route'의 'def_route_src_dst_day' 인덱스 외에는 나머지 조인을 지원하는 다른 인덱스가 없습니다. 따라서 이러한 조인은 효율적이지 않습니다.
- 항공사별 노선 수를 집계하는 최종 집계도 있었습니다.
- 2.1초 만에 쿼리 완료
쿼리 성능을 개선하려면 어떻게 해야 하나요?
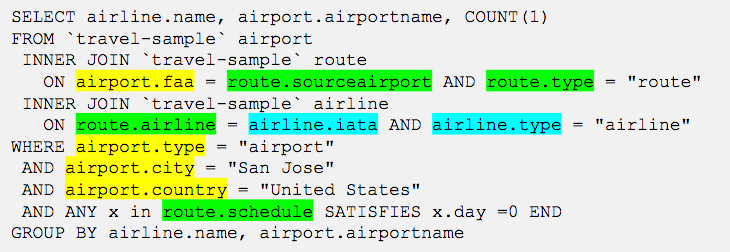
- '공항' 문서에는 두 개의 술어('도시' 및 '국가')와 '유형'에 대한 맛 술어가 있습니다. 또한 공항 'faa' 열은 'route'에 대한 조인에도 사용됩니다. 따라서 세 개의 개별 인덱스를 사용하는 대신 '공항' 문서에 ('도시', '국가') [action_1]에 대한 부분 인덱스가 있어야 합니다. 'airport.faa' 필드도 별도의 인덱스를 사용하거나 기본 공항 인덱스의 일부를 사용하면 이점을 얻을 수 있습니다.
- 'route' 문서에는 술어가 없지만 'sourceairport' 필드가 있는 'airport'에 대한 조인이 있습니다. 이 열의 인덱스가 조인에 도움이 될 것이며, 이미 'def_route_src_dst_day' [action_2] 인덱스가 있으므로 이 조인에는 아무런 작업이 필요하지 않습니다.
- 'route' 문서에는 'airline' 필드에 'airline'에 대한 조인도 있습니다. 따라서 'route' 문서('airline') [action_3]에 대한 인덱스가 있어야 합니다.
- 'airline' 문서에도 술어가 없지만 'iata' 필드가 있는 'route'에 대한 조인이 있습니다. 따라서 '항공사' 문서('iata') [action_4]에 또 다른 인덱스가 필요합니다.
- route.schedule 배열에 술어가 있습니다. 따라서 이것에도 인덱스가 필요합니다. 'route' 문서 (DISTINCT ARRAY x.day FOR x in schedule END) [action_5].
따라서 이 쿼리에 대해 4개의 추가 인덱스를 생성하는 5가지 액션 포인트를 생각해냈습니다. 인덱스 어드바이저가 무엇을 추천하는지 살펴봅시다.
인덱스 어드바이저를 실행하여 결과 확인
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
[ { "#operator": "Advise", "advice": { "#operator": "IndexAdvice", "adviseinfo": [ { "current_indexes": [ { "index_statement": "CREATE INDEX def_city ON `travel-sample`(`city`)" }, { "index_statement": "CREATE INDEX def_type ON `travel-sample`(`type`)" }, { "index_statement": "CREATE INDEX def_faa ON `travel-sample`(`faa`)" }, { "index_statement": "CREATE INDEX def_route_src_dst_day ON `travel-sample`(`sourceairport`,`destinationairport`,(distinct (array (`v`.`day`) for `v` in `schedule` end))) WHERE (`type` = 'route')" }, { "index_statement": "CREATE INDEX def_type ON `travel-sample`(`type`)" } ], "recommended_indexes": { "covering_indexes": [ { "index_statement": "CREATE INDEX adv_faa_city_country_type_airportname ON `travel-sample`(`faa`,`city`,`country`,`airportname`) WHERE `type` = 'airport'" }, { "index_statement": "CREATE INDEX adv_iata_type_name ON `travel-sample`(`iata`,`name`) WHERE `type` = 'airline'" } ], "indexes": [ { "index_statement": "CREATE INDEX adv_country_faa_city_type ON `travel-sample`(`country`,`faa`,`city`) WHERE `type` = 'airport'", "recommending_rule": "Index keys follow order of predicate types: 1. equality, 8. flavor for partial index." }, { "index_statement": "CREATE INDEX adv_airline_sourceairport_DISTINCT_schedule_day_type ON `travel-sample`(`airline`,`sourceairport`,DISTINCT ARRAY x.day FOR x in schedule END) WHERE `type` = 'route'", "recommending_rule": "Index keys follow order of predicate types: 1. equality, 5. array predicate, 8. flavor for partial index." }, { "index_statement": "CREATE INDEX adv_iata_type ON `travel-sample`(`iata`) WHERE `type` = 'airline'", "recommending_rule": "Index keys follow order of predicate types: 1. equality, 8. flavor for partial index." } ] } } ] }, "query": "SELECT airline.name, airport.airportname, COUNT(1)\nFROM `travel-sample` airport\nINNER JOIN `travel-sample` route ON airport.faa = route.sourceairport\n AND route.type = \"route\"\nINNER JOIN `travel-sample` airline ON route.airline = airline.iata\n AND airline.type = \"airline\"\nWHERE airport.type = \"airport\"\n AND airport.city = \"San Jose\"\n AND airport.country = \"United States\"\n AND ANY x in route.schedule SATISFIES x.day =0 END\nGROUP BY airline.name, airport.airportname" } ] |
현재 색인 섹션
이는 계획에서 제공한 것과 동일합니다. 쿼리는 5개의 인덱스를 사용합니다.
추천 색인 섹션 - "색인"
이 섹션에서는 모든 인덱스를 술어 관점에서 나열합니다. JOIN에는 ON 필드가 있으며, 이 필드도 술어로 취급됩니다. 이제 권장 인덱스를 검토해 보겠습니다.
- adv_country_faa_city_type 켜기
여행 샘플(국가,faa,도시) 어디유형= 'airport' - 키 순서를 제외하고는 [action_1]에서 확인한 것과 동일한 인덱스입니다. 이 술어들은 모두 동일성을 사용하므로 여기서 키 순서는 중요하지 않습니다. - adv_airline_sourceairport_DISTINCT_schedule_day_type 켜기
여행 샘플(항공사,소스공항,DISTINCT ARRAY x.day FOR x in schedule END) WHERE유형= 'route' - 여기서 인덱스 어드바이저가 수행한 작업은 [action_2, action_3, action_5]를 단일 인덱스로 결합한 것입니다. - adv_iata_type 켜기
여행 샘플(iATA) 어디유형= '항공사' - [action_4]에서 식별한 것과 동일한 인덱스입니다.
추천 색인 섹션 - "커버 색인"
이 섹션에는 모든 커버링 인덱스 권장 사항이 나열되어 있습니다. 참고 사항 커버링 인덱스는 실행이 데이터 서비스에서 추가 가져오기를 수행할 필요가 없는 문서에 대한 쿼리를 충족하는 데 사용되는 인덱스입니다..
- adv_faa_city_country_type_공항명_공항명 켜기
여행 샘플(국가,faa,도시,공항명) 어디유형= '공항' - 인덱스 어드바이저가 추천 인덱스에 route.airportname 필드를 추가했습니다 [adv_country_faa_city_type 켜짐].여행 샘플(국가,faa,도시)]. 이렇게 하면 쿼리 서비스가 데이터 서비스에서 경로 문서를 가져올 필요가 없어져 route.airportname - adv_iata_type_name_name ON
여행 샘플(iATA,이름) 어디유형= '항공사' - 인덱스 어드바이저가 추천 인덱스에 airline.name을 추가했습니다 [adv_iata_type ON].여행 샘플(iATA) 어디유형= 'airline']. 이렇게 하면 쿼리 서비스에서 데이터 서비스에서 항공사 문서를 가져와서 airline.name을 투사할 필요가 없습니다.
참고: 커버링 인덱스는 쿼리 서비스가 데이터 서비스에서 추가 가져오기를 수행할 필요성을 줄여주므로 쿼리 성능이 향상됩니다. 그러나 사용자는 사용자 환경의 메모리나 저장 공간과 같은 특정 제약 조건에 따라 커버링 인덱스를 생성할지 여부를 결정해야 합니다.
모든 권장 인덱스를 생성하고 새 쿼리 계획을 검토하세요.
이 연습에서는 해당하는 경우 커버링 인덱스를 사용하여 모든 권장 인덱스를 만들기로 했습니다.
|
1 2 3 4 5 |
CREATE INDEX `adv_faa_city_type_country_airportname` ON `travel-sample`(`faa`,`city`,`airportname`) WHERE ((`type` = "airport") and (`country` = "United States")) CREATE INDEX `adv_sourceairport_airline_DISTINCT_schedule_day_type` ON `travel-sample`(`sourceairport`,`airline`,(distinct (array (`x`.`day`) for `x` in `schedule` end))) WHERE (`type` = "route") CREATE INDEX `adv_iata_type_name` ON `travel-sample`(`iata`,`name`) WHERE (`type` = "airline") |
권장 인덱스 추가 후 쿼리 계획
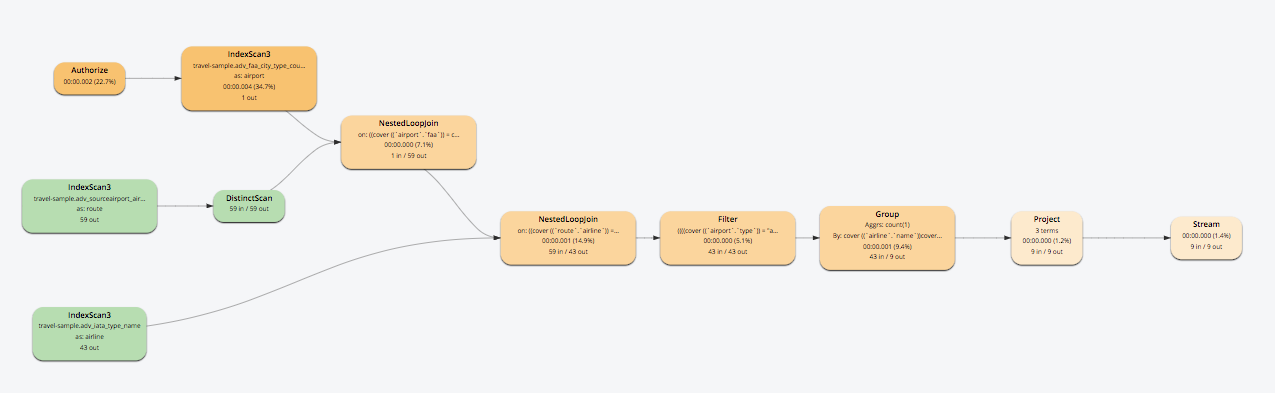
- 이제 쿼리는 5개의 인덱스 대신 인덱스 어드바이저에서 추천하는 3개의 새로운 인덱스를 사용합니다.
- 커버링 인덱스를 만들었으므로 쿼리 서비스는 더 이상 데이터 서비스에서 추가 가져오기를 수행할 필요가 없습니다.
- 이제 쿼리가 120ms 만에 완료됩니다. 94% 개선되었습니다.
Index Advisor를 사용하여 워크로드 분석하기
N1QL - ADVISOR( )
인덱스 어드바이저는 ADVISOR() 함수로도 호출할 수 있습니다. 이를 통해 사용자는 다음을 수행할 수 있습니다:
- 여러 쿼리를 전달합니다. SELECT ADVISOR("SELECT ...","SELECT ...","UPDATE...");
- 실제 N1QL 문을 반환하는 하위 쿼리를 전달합니다. 쿼리는 json 문서 구조를 반환하므로 실제 N1QL 문만 반환되도록 하려면 RAW 키워드를 사용해야 합니다.
ADVISOR()를 사용하여 완료된 요청을 쿼리하여 느린 쿼리를 식별합니다.
|
1 2 3 |
/* Retrieve queries that ran longer then 1 secs */ SELECT <strong>ADVISOR</strong>((SELECT <strong>RAW</strong> statement FROM system:completed_requests WHERE trunc(str_to_duration(elapsedTime)/1000000000) > 1)) |
기존의 비효율적인 인덱스 식별
쿼리에 대한 인덱스가 이미 있는 경우에도 인덱스 어드바이저를 실행하면 Couchbase 인덱스 지침에 따라 기존 인덱스가 최적의 인덱스가 아닐 수 있는 경우를 식별하는 데 도움이 될 수 있습니다.
이 예를 생각해 보세요:
|
1 |
SELECT COUNT(1) FROM `travel-sample` t WHERE t.type = “airport” AND t.icao IS NOT NULL AND t.geo.alt < 300; |
그리고 아래 인덱스에서 쿼리가 문제 없이 실행될 수 있습니다:
|
1 |
CREATE INDEX ix1 ON `travel-sample`(`type`,`icao`,`geo`.`alt`) |
하지만 쿼리에 권장되는 인덱스는 다음과 같습니다:
|
1 |
CREATE INDEX adv_geo_alt_icao_type ON `travel-sample`(`geo`.`alt`,`icao`) WHERE `type` = ‘airport’ |
이는 키가 술어 유형 규칙의 순서를 따르는 경우 인덱스의 성능이 더 좋아야 하기 때문입니다:
- 규칙 4. 미만/중간/초과.
- 규칙 6. 널/누락/값이 없어야 합니다.
- 규칙 8. 부분 인덱스에 대한 맛.
권장 인덱스 명명 규칙
인덱스 어드바이저는 특정 명명 규칙을 가진 인덱스를 추천합니다,
- ADV_FIELD1_FIELD2_FIELD3...
배열 인덱스의 경우 배열 인덱스 끝에 밑줄을 추가하여 구분합니다:
- adv_[DISTINCT/ALL]_field1_field1.2_field1.2.3__field2_field3...
인덱스 어드바이저가 이전에 추천했던 인덱스와 다른 방법으로 생성한 인덱스를 인식할 수 있으므로 제공된 인덱스 이름을 그대로 유지하는 것이 좋습니다. 향후 업데이트에서 인덱스 어드바이저는 인덱스 교체를 권장할 수 있지만, 교체하려는 인덱스가 이전에 권장했던 인덱스인 경우에만 그렇게 할 것입니다.
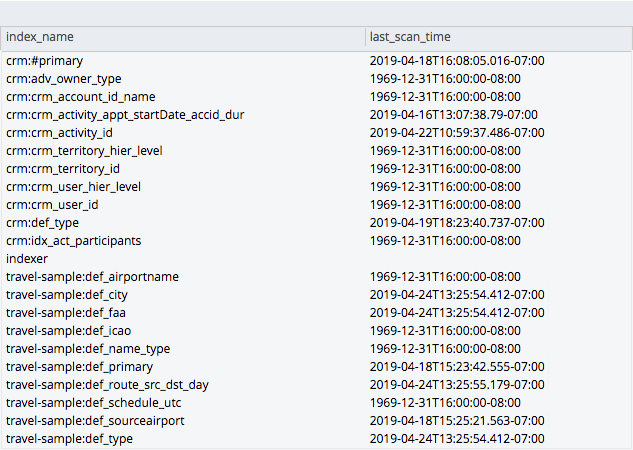
인덱스 통계 마지막 알려진 스캔 시간 사용
데이터베이스에는 일정 기간 동안 다양한 쿼리 요구 사항에 대한 많은 인덱스가 있을 수 있습니다. 그러나 데이터베이스에 인덱스가 누적되면 중복되거나 유사하게 생성된 인덱스가 발생할 가능성이 있습니다. 여기에는 더 이상 사용되지 않는 인덱스도 포함됩니다. 값을 쿼리할 수 있습니다.마지막_알려진_스캔_시간' 인덱스 통계 휴식 엔드포인트에서 인덱스의 상태를 확인한 다음 인덱스를 삭제할지 여부를 결정합니다.
|
1 2 3 4 |
SELECT ARRAY {"index_name":a.name,"last_scan_time":millis_to_str(a.val.last_known_scan_time/1000000)} FOR a IN OBJECT_PAIRS(results) END FROM curl("https://<index_host>:9102/api/v1/stats", {"user":"Administrator:password"}) results |
결과:
요약
애플리케이션 배포 관점에서 인덱스 관리의 필요성은 개발 프로세스의 끝에서 멈추는 것이 아니라 지속적인 작업입니다. 실제로 인덱스 관리에는 자체적인 수명 주기가 있어야 합니다. 시간이 지남에 따라 데이터의 양과 형태가 변할 수 있고, 그 결과 기존 인덱스에 변경이 필요할 수 있기 때문입니다. 경우에 따라서는 쿼리 구성도 수정해야 할 수도 있습니다. 따라서 인덱스 어드바이저는 제품 수명 주기 관리에 있어 매우 중요한 부분입니다.
Couchbase 6.5(DP) 기준 Index Advisor에 대해 주목해야 할 몇 가지 주요 사항
- 지수 유형 - 지수 어드바이저는 GSI 지수만 추천합니다. 기본 지수나 FTS 지수는 추천하지 않습니다.
- 규칙 기반 - 현재 구현에서 인덱스 어드바이저는 술어, 투영 목록 및 키 열 순서를 기반으로 인덱스를 추천합니다. 사실상 쿼리 플래너에서 사용하는 것과 동일한 규칙을 기반으로 합니다. 규칙 기반 데이터베이스 최적화(RBO)와 마찬가지로 인덱스 어드바이저는 키 열의 데이터 분포에 대한 통계를 고려하지 않습니다. 따라서 사용자는 권장 인덱스를 프로덕션 환경에 배포하기 전에 성능 평가를 수행해야 합니다.
- 하위 쿼리 - 인덱스 어드바이저는 쿼리가 FROM 절에 있는 경우에만 하위 쿼리와 함께 작동합니다.
- 다중 키 배열 인덱스 - 인덱스 어드바이저는 술어가 여러 배열 필드를 참조하는 경우에도 배열 인덱스에 대해 단일 키만 추천합니다.
- 파티션 인덱스 - 인덱스 어드바이저는 권장 사항에 파티션 절을 포함하지 않습니다. 인덱스 생성 문을 사용합니다.
- 기존 인덱스 - 인덱스 어드바이저는 기존 인덱스의 재설계를 권장하지 않으며, 기존 인덱스의 삭제를 권장하지도 않습니다. 사용자는 인덱스 마지막 스캔 시간을 사용하여 결정을 내려야 합니다.
리소스
6.5의 기능이 마음에 드셨는지, 앞으로 비즈니스에 어떤 도움이 될지 여러분의 의견을 듣고 싶습니다. 댓글을 통해 의견을 공유해 주시거나 포럼.
[...] 2. 카우치베이스의 어드바이저 서비스를 사용하여 병목 현상을 찾습니다. https://www.couchbase.com/n1ql-index-advisor-improve-query-performance-and-productivity/ [...]