참고: 이 블로그 게시물은 Matthew Revell의 MongoDB에서 Couchbase Server로 이동하기
이 가이드는 애플리케이션의 데이터 저장소를 MongoDB에서 다음과 같이 이동하는 개발자 중심 가이드입니다. 카우치베이스 서버. 관계형 데이터베이스에서 Couchbase로 마이그레이션하는 데 관심이 있으시다면, Laurent의 PostgreSQL에서 이전하기 위한 가이드앞으로 SQL Server 마이그레이션 관련 포스팅을 작성할 예정입니다.
이 가이드에서 모든 사례를 다루지는 않지만 마이그레이션을 계획할 때 고려해야 할 사항에 대한 지침을 제공합니다. 다음에 대해 자세히 알아보고 싶으신 경우 왜 이 마이그레이션을 수행하거나, 이 마이그레이션을 수행한 Couchbase 고객에 대해 알아보세요, Viber 확인.
현재 몽고DB를 사용 중이고, Node와 함께 몽구스 ODM을 사용 중인 경우, 다음은 Connect 2016 컨퍼런스의 Ottoman.js를 사용한 MongoDB에서 마이그레이션에 대한 비디오.
버전
이 가이드는 카우치베이스 서버 4.5 및 몽고DB 3.4용으로 작성되었습니다.
주요 차이점
카우치베이스 서버와 몽고DB는 모두 하나 또는 여러 대의 서버에서 작동할 수 있는 문서 저장소입니다. 그러나 이 두 가지는 상당히 다른 방식으로 접근합니다.
MongoDB에서 Couchbase Server로 마이그레이션을 시작할 때 다음과 같은 차이점을 고려해야 합니다:
|
카우치베이스 서버 |
MongoDB |
|
|
데이터 모델 |
문서, 키-값 |
문서 |
|
쿼리 |
N1QL(JSON용 SQL), 보기 매핑/축소, 키-값 |
애드혹 쿼리, 매핑/축소 집계 |
|
동시성 |
낙관적 잠금 및 비관적 잠금 |
낙관적 및 비관적 잠금(WiredTiger 사용) |
|
확장 모델 |
분산 마스터-마스터 |
복제본 세트가 있는 마스터-슬레이브 |
데이터 모델
카우치베이스 서버는 문서 저장소이자 키-값 저장소입니다.
모든 문서에는 문서 내용을 가져오고 설정하는 데 사용할 수 있는 키가 있으므로 모든 것은 키-값으로 시작됩니다. 하지만 문서 내용을 색인하고 쿼리하여 Couchbase Server를 문서 데이터베이스로 사용할 수 있습니다. 참고: Couchbase를 일반 키-값 저장소로 사용하는 데 관심이 있다면 다음 블로그 포스팅을 읽어보세요. 카우치베이스를 사용하여 JSON이 아닌 데이터 저장하기.
BSON과 JSON의 차이점
애플리케이션이 MongoDB에 JSON 형식의 문서를 저장하고 있을 가능성이 높으므로 여기서부터 시작하겠습니다.
MongoDB는 바이너리 JSON과 유사한 형식인 BSON 형식으로 데이터를 저장합니다. 마이그레이션 시 주요 차이점은 BSON이 추가 유형 정보를 기록한다는 것입니다.
다음과 같은 도구를 사용하여 MongoDB에서 데이터를 내보내는 경우 몽고 수출를 입력하면 도구는 해당 유형 정보를 확장 JSON이라는 형식으로 보존하는 JSON을 생성합니다.
확장 JSON의 예시를 살펴보겠습니다:
|
1 2 3 4 5 |
{ "myInt": { "$numberLong": "123" } } |
보시다시피 확장 JSON은 여전히 유효한 JSON입니다. 즉, Couchbase Server를 사용하여 저장, 색인, 쿼리 및 검색할 수 있습니다. 그러나 애플리케이션 계층에서 추가 유형 정보를 유지 관리해야 합니다(예를 들어, 위 예제에서 확장 JSON은 긴 정수를 문자열로 저장하고 있습니다).
또는 확장 JSON을 Couchbase Server로 가져오기 전(또는 가져온 후)에 표준 JSON으로 변환할 수도 있습니다. N1QL 쿼리의 경우 이 작업은 비교적 간단하지만 지루할 수 있습니다. 다음은 위의 "myInt" 필드를 표준 JSON 숫자 필드로 변환하는 예제입니다:
|
1 2 3 |
UPDATE `default` SET myInt = TONUMBER(myInt.`$numberLong`) WHERE myInt.`$numberLong` IS NOT MISSING |
그 결과는 다음과 같습니다:
|
1 2 3 |
{ "myInt": 123 } |
비 JSON 데이터
몽고DB와 카우치베이스 서버 모두 불투명 바이너리 데이터를 저장할 수 있습니다.
바이너리 데이터의 내부 표현은 둘 간에 크게 다르지만, MongoDB에 저장하던 바이너리 데이터를 Couchbase Server에 계속 저장할 수 있습니다.
가장 큰 차이점은 카우치베이스 서버는 최대 20MB 크기의 바이너리를 저장할 수 있는 반면, 몽고DB는 매우 큰 파일을 여러 문서로 분할하는 편리한 계층을 제공한다는 점입니다.
데이터베이스에 대용량 바이너리를 저장하는 것에 반대하는 강력한 주장이 있습니다.. 대용량 바이너리가 많은 경우 전용 오브젝트 스토리지 서비스를 사용하여 바이너리를 저장하고 Couchbase를 사용하여 해당 바이너리의 메타데이터를 보관하는 것을 고려할 수 있습니다.
아키텍처
샤딩
카우치베이스 서버는 클러스터의 노드 간에 해시 공간을 자동으로 분배하여 데이터를 샤딩하고 수평적으로 확장합니다.
그런 다음 문서의 키를 사용하여 해당 문서가 해시 공간의 어느 위치에 있는지, 즉 클러스터의 어느 노드에 있는지 결정합니다. 개발자는 클라이언트 SDK를 통해 이 과정을 추상화할 수 있습니다.
몽고DB를 사용하려면 샤딩 방법과 샤드 키를 선택해야 합니다. 샤드 키는 문서 내부의 인덱싱된 필드로, 클러스터에서 문서가 있는 위치를 결정합니다.
여기서 가장 큰 차이점은 Couchbase Server는 모든 샤딩을 자동으로 처리하는 반면, MongoDB는 샤딩 방법과 샤드 키를 사용자가 선택할 수 있다는 점입니다. 애플리케이션이 클러스터 전체에 걸쳐 특정 데이터 배포에 의존하는 경우, Couchbase에서 사용하는 해시 기반 배포를 허용하도록 애플리케이션을 조정해야 합니다.
해시 기반 샤딩은 MongoDB에 비해 확장을 크게 간소화합니다. 개발자의 입장에서는 이것이 자신과 상관없고 운영상의 문제라고 생각할 수도 있습니다. 하지만 소프트웨어 사용량이 늘어날 경우 Couchbase Server에 더 쉽게 의존할 수 있다는 의미이기도 합니다.
복제 및 일관성
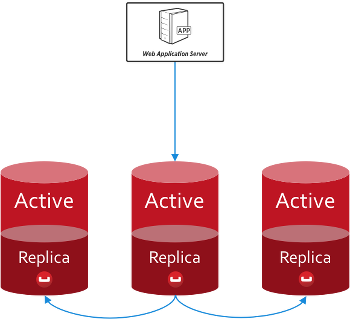
카우치베이스 서버는 각 문서의 활성 복사본 하나를 유지한 다음 최대 3개의 복제본을 유지하며, 버킷 전체 또는 작업별로 복제본 수를 구성할 수 있습니다.
즉, 정상적인 작업 중에는 문서에 쓰고 읽을 때마다 동일한 실시간 사본을 처리하게 됩니다. 따라서 충돌하는 버전의 문서를 처리할 필요가 없습니다. 복제본은 활성 사본을 사용할 수 없을 때만 작동합니다.
개발자는 문서의 배포와 복제가 추상화되어 있습니다. 버킷에 대한 연결을 사용해 쓰고, 읽고, 쿼리하면 데이터가 저장된 위치를 SDK가 정확하게 처리합니다. 복제 세트나 샤딩 체계를 고려할 필요가 없습니다.
만약 당신이 CAP 정리를 사용하면 일관성을 선호하는 것이 가용성에 영향을 미친다는 것을 알 수 있습니다. 노드에 장애가 발생하면 클러스터가 적절한 복제본을 활성 상태로 승격할 수 있도록 잠시 동안 활성 문서를 사용할 수 없게 됩니다. 코드에서는 실패한 작업을 다시 시도하기만 하면 됩니다.
인덱싱
카우치베이스 서버는 크게 두 가지 유형의 인덱스를 제공합니다:
- GSI: 글로벌 보조 지수
- 뷰: 맵 축소 쿼리에 의해 생성됩니다. 두 가지 유형의 인덱스를 서로 다르게 생성하고 관리한다는 점에서 구현상의 세부 사항 이상의 차이가 있습니다. 대부분 GSI 인덱스를 사용하여 MongoDB 인덱스를 복제합니다.
노드 유형
MongoDB 서버가 한 대 이상으로 늘어나면 라우터 프로세스를 도입하고 서버를 구성해야 합니다.
Couchbase Server에서는 이 두 기능이 모두 클라이언트 SDK에 있습니다. 애플리케이션에서 클러스터에 연결하면 SDK는 클러스터에서 각 샤드가 있는 위치에 대한 맵을 수신합니다. 그러면 클러스터의 모양이 변경될 때마다 Couchbase Server가 클러스터 맵을 자동으로 업데이트합니다. 그런 다음 각 요청은 애플리케이션 서버에서 관련 Couchbase 노드로 직접 이루어집니다.
클러스터가 커지면 특수 데이터, 쿼리 및 인덱싱 노드를 실행하도록 선택할 수 있습니다. 다차원 스케일링에 대해 자세히 알아보기.
이 모든 과정은 개발자에게 투명하게 공개됩니다.
버킷 및 컬렉션
Couchbase Server와 MongoDB 모두 데이터 집합을 문서 그룹으로 나눌 수 있습니다: Couchbase에는 버킷이 있고 MongoDB에는 컬렉션이 있습니다.
MongoDB 컬렉션은 관계형 테이블과 동등한 범위이지만, Couchbase Server 버킷은 관계형 데이터베이스에 더 가깝다고 할 수 있습니다.
이 구분이 중요한 이유는 일반적으로 단일 Couchbase 클러스터에 버킷을 10개 이상 사용하지 않기 때문입니다. 따라서 네임스페이스로는 적합하지 않습니다. 대신 비슷한 유형의 문서 간에 구성 및 모델링 결정을 공유하는 방법으로 사용됩니다.
이는 크게 두 가지 결과를 초래합니다:
- 문서 네임스페이스를 지정하는 다른 방법이 필요합니다.
- 언제 새 버킷을 만드는 것이 적절한지 생각해 보아야 합니다.
여러 버킷을 사용해야 하는 경우
먼저 버킷에 리소스를 할당하는 방법에 대해 생각해 볼 필요가 있습니다. 크게 두 가지를 고려해야 합니다:
- RAM
- 보기 및 인덱스.
버킷을 만들 때 각 컴퓨터의 RAM의 일부를 버킷에 할당합니다. 버킷에 할당하는 RAM은 해당 데이터의 작업 세트와 각 문서와 연결된 몇 바이트의 메타데이터를 저장할 수 있을 만큼 충분히 커야 합니다.
즉, 데이터 집합에 액세스하는 방식에 따라 데이터 집합마다 다른 양의 RAM을 적절하게 할당할 수 있습니다.
마찬가지로, Couchbase 보기와 인덱스는 MongoDB 맵 축소 쿼리가 단일 컬렉션에서 실행되는 것과 마찬가지로 버킷 내의 문서 전체에서 실행됩니다.
키를 통해서만 액세스하기 때문에 인덱싱이 필요하지 않은 문서가 있고 속도가 다른 문서 그룹이 있는 경우, 첫 번째 데이터 세트에서는 인덱서를 실행하지 않고 나머지 데이터 세트에서는 적절한 간격을 두고 인덱서를 실행하는 것이 현명하다는 것을 알 수 있습니다.
데이터를 여러 버킷으로 나누면 RAM과 인덱서에 필요한 CPU 시간을 모두 효율적으로 사용할 수 있습니다.
전자 상거래 애플리케이션의 예를 들어 저장할 데이터, 프로필, 버킷 구성에서 이에 대응하는 방법을 살펴봅시다.
|
데이터 유형 |
데이터 프로필 |
버킷 프로필 |
|
세션 |
빠른 응답, 키-값 액세스, 예측 가능한 동시 세션 |
일반적인 라이브 세션 수에 맞게 RAM을 늘릴 수 있습니다, 인덱싱 없음 |
|
사용자 프로필 |
사용자가 활동 중일 때는 빠른 응답, 데이터 변경은 느림 |
일반적인 라이브 세션 수에 대한 사용자 프로필에 맞는 RAM, 인덱싱 기준 |
|
주문 데이터 |
최초 생성 후 읽기가 많고 수명이 짧습니다. |
일반적인 라이브 세션 수에 맞는 주문에 맞는 RAM, 인덱싱 기준 |
|
제품 데이터 |
빠른 응답 필요, 무거운 읽기 |
전체 카탈로그에 맞는 RAM, 인덱싱 기준 |
인덱싱을 설정할지 여부를 결정하는 것보다 조금 더 복잡합니다. 그보다는 인덱스 유형을 선택하고 업데이트 속도에 따라 인덱서의 실행 빈도가 결정됩니다. 버킷의 인덱서는 변경되지 않은 문서를 포함해 해당 버킷의 모든 문서에 대해 실행되므로 느리게 움직이는 데이터와 빠르게 움직이는 데이터를 혼합하는 것은 비효율적일 수 있습니다.
문서 네임스페이스 지정
버킷을 네임스페이스로 사용할 수 없다면 서로 다른 유형의 문서를 어떻게 쉽게 구분할 수 있을까요?
조합을 사용해야 합니다:
- 키 이름 지정
- JSON 문서에서 '유형'을 사용합니다.
키 이름에 의미론적 접두사 및 접미사 사용하기 는 문서 네임스페이스를 쉽게 지정할 수 있는 방법으로, 특히 키-값에 Couchbase를 사용할 때 유용합니다.
문서 스키마에 유형을 요구하면 특정 유형의 문서에만 적용되는 쿼리를 만드는 데 필요한 데이터를 얻을 수 있습니다.
프로그래밍 모델
Couchbase Server로 작업하는 방법에는 세 가지가 있습니다:
- 간단한 키-값 액세스: 강력한 일관성, 밀리초 미만의 응답 시간
- 조회수: 맵 축소 쿼리에 의해 생성됨
- N1QL: SQL과 유사한 쿼리(JOIN 사용)
몽고DB를 사용하다 보면 모든 몽고DB 쿼리를 N1QL로 변환하고 싶은 유혹을 느낄 수 있습니다. 그러나 각각의 상대적인 장점을 고려한 다음 필요에 맞는 조합을 사용하는 것이 좋습니다.
키-값 액세스를 사용하면 다음과 같이 먼 길을 갈 수 있습니다. 수동 보조 인덱스.
쿼리
카우치베이스 서버 제공 사항 N1QL. N1QL은 SQL과 유사한 언어이며 MongoDB에서 쿼리하는 것과는 상당히 다릅니다.
마운틴뷰 지사에서 2년 이상 근무한 직원의 이름을 입사 날짜 순으로 반환하는 예를 살펴보겠습니다:
|
1 2 3 4 5 6 |
SELECT name FROM `hr` WHERE office='Mountain View' AND type='employee' AND DATE_DIFF_MILLIS(startDate, NOW_MILLIS) >= 63113904000 ORDER BY startDate; |
SQL로 작업해 본 적이 있다면 N1QL은 매우 친숙할 것입니다. 비교적 적은 노력으로 MongoDB 쿼리를 N1QL로 변환할 수 있습니다.
쿼리 재작성을 시작하기 전에 N1QL이 제공하는 한 가지 주요 이점을 고려해야 합니다. 조인 를 반환합니다. 위의 쿼리를 사용하여 각 사람의 관리자 이름도 반환해 보겠습니다.
|
1 2 3 4 5 6 7 |
SELECT r.name, s.name AS manager FROM `hr` r JOIN `hr` s ON KEYS r.manager WHERE r.office='Mountain View' AND r.type='employee' AND DATE_DIFF_MILLIS(r.startDate, NOW_MILLIS) >= 63113904000 ORDER BY r.startDate; |
동시성
카우치베이스 서버에서 잠금은 항상 문서 수준에서 이루어지며 두 가지 유형이 있습니다:
- 비관적: 문서가 릴리스되거나 시간 초과가 발생할 때까지 다른 행위자는 해당 문서에 쓸 수 없습니다.
- 낙관적: CAS(확인 후 설정) 값을 사용하여 마지막으로 문서를 건드린 이후 문서가 변경되었는지 확인하고 그에 따라 작업하세요.
낙관적 잠금 가 더 효율적일 수 있지만 때로는 비관적 잠금이 필요할 수 있습니다. 올바른 잠금 유형 선택에 대해 자세히 알아보기.
라이브러리 및 통합
다음이 있습니다. 공식적으로 지원되는 SDK Java, .NET, NodeJS, Python, Go, Ruby 및 C를 포함한 모든 주요 언어에 대해 커뮤니티에서 개발한 클라이언트 라이브러리를 찾을 수 있으며, Erlang을 포함한 언어에 대해서도 찾을 수 있습니다.
마찬가지로 다음과 같은 공식 통합이 있습니다. 스프링 데이터, Spark, Hadoop, Kafka, Talend, Elasticsearch 및 ODBC/JDBC, Linq2Couchbase 에 대한 오스만이라는 NodeJS ODM. 현재 몽고DB용 몽구스를 사용 중이시라면, 다음 내용을 참고하세요. Ottoman.js를 사용하여 MongoDB에서 마이그레이션하는 방법에 대한 비디오.
결론
한 문서 저장소에서 다른 문서 저장소로 이동하는 것은 비교적 간단합니다. 관계형 마이그레이션과 달리 데이터의 큰 형태는 크게 변경할 필요가 없기 때문입니다.
MongoDB에서 Couchbase Server로 애플리케이션을 포팅하는 개발자가 주로 고려해야 할 사항은 다음과 같습니다:
- 컬렉션 네임스페이스를 키 이름 지정 및 문서 유형으로 바꾸기
- N1QL JOIN을 사용하여 쿼리 간소화하기
- 키 값 액세스가 최선의 선택이 될 수 있는 경우를 고려하세요.
MongoDB에서 Couchbase Server로 전환하는 것이 처음은 아닐 것입니다. 이전에 전환한 사람들을 다음에서 찾아볼 수 있기 때문에 좋은 소식입니다. 카우치베이스 포럼.
질문이나 의견이 있거나 부정확한 내용을 발견한 경우 댓글을 남기거나 다음 주소로 문의해 주세요. 트위터의 나.