N1QL에 대한 인덱스: 또는 주문 규모 속도 향상을 얻은 방법
Couchbase 4.0에서는 JSON 문서에 SQL과 유사한 쿼리를 제공하는 유연한 쿼리 언어인 N1QL 쿼리 언어를 도입했습니다.
N1QL에 대해 이야기할 때마다 대화 성능 측면에서 무엇을 기대할 수 있는지, 쿼리를 최적화할 수 있는 옵션은 무엇인지 등 성능에 대한 질문은 항상 열려 있습니다.
첫 번째 대답은 "사용 사례와 데이터의 형태에 따라 달라집니다"일 가능성이 높지만 솔직히 큰 도움이 되지 않습니다.
이 블로그 게시물에서는 성능에 대한 질문에 좀 더 자세히 답하고 실행 시간 측면에서 실제 수치를 제시하며 쿼리를 최적화하여 더 나은 성능을 얻는 방법을 보여드리려고 합니다.
배경 스토리
Couchbase는 여러 내부 도구와 애플리케이션에서 N1QL을 사용하며 지난 주에 매우 중요한 사실을 발견했습니다!
N1QL을 사용할 때는 인덱스를 생성하는 것이 매우 중요합니다!
소규모 애플리케이션에서 하나의 속성에 하나의 인덱스를 추가하면 실행 시간이 +2분에서 2초로 변경되었습니다. 쿼리 자체는 변경되지 않았고 인덱스만 변경되었습니다!
참고: 위의 쿼리 시간은 단일 N1QL 쿼리가 아니라 상대적으로 저전력 VM에서 애플리케이션의 여러 쿼리 시퀀스에 대한 시간입니다.
쿼리의 예상 실행 시간은 쿼리 복잡성 및 시스템, Couchbase 서버 및 하드웨어에 따라 크게 달라집니다.
따라서 보다 정확한 답변을 제공하려면 테스트 벤치가 필요합니다. 다양한 시스템에서 실행할 수 있는 잘 정의된 테스트 세트를 통해 주어진 설정에 대한 실제 성능 메트릭을 확인할 수 있습니다. 이러한 방식으로 실제 시스템과 쿼리에 대한 측정값을 제공할 수 있습니다.
따라서 N1QL이 빠르다는 주장만 하지 말고 실제 시스템에서 테스트해 볼 수 있습니다.
테스트 벤치 만들기
첫째, 성능은 측정하기 어렵습니다. 측정하는 것도 어렵지만, 진짜 문제는 무엇을 테스트하고 있는지 잊어버려서 '스톱워치'를 언제 시작하고 언제 다시 멈춰야 하는지도 잊어버리는 경우가 많다는 점입니다.
따라서 테스트를 실행할 때는 테스트가 측정하려는 대상과 공정하고 반복 가능하며 비교 가능한 방식으로 측정하는 방법을 정의하는 것이 중요합니다.
우리의 경우, 인덱스를 사용할 때와 사용하지 않을 때 사전 정의된 N1QL 쿼리의 실행 시간 차이를 측정하고자 합니다.
네트워크 지연, 부트스트랩 시간, SDK 성능, 설정/정리 시간 등과 같은 플랫폼별 지연과는 무관하게 N1QL 쿼리의 실제 실행 시간에만 관심이 있습니다.
즉, 이 특정 성능 테스트에서는 두 시나리오에서 쿼리 실행 시간 외에는 아무것도 무시하고 있습니다!
다행히도 쿼리 실행 시간을 측정하는 것은 매우 쉽습니다! 모든 카우치베이스 서버 응답에는 측정 요청에 대한 모든 메트릭이 포함된 객체입니다.
|
1 2 3 4 5 6 7 8 9 10 |
"Metrics": { "elapsedTime": "1.7900093s", "executionTime": "1.7900093s", "resultCount": 0, "resultSize": 0, "mutationCount": 0, "errorCount": 0, "warningCount": 0 } |
위의 메트릭에는 다음이 포함됩니다. 실행 시간 이 값은 네트워크 지연 시간, 플랫폼 코드 실행 시간 등과 무관하게 Couchbase Server에서 실행되는 시간을 나타냅니다. 이것이 바로 우리에게 필요한 것입니다!
쿼리를 실행하기 전에 쿼리를 실행할 테스트 데이터가 필요합니다. 얼마나 많은 테스트 데이터가 있는지는 테스트 결과에 큰 영향을 미칠 수 있으므로 모든 테스트 실행에 대해 구성할 수 있어야 합니다.
테스트 데이터를 생성하는 방법은 테스트에 전혀 중요하지 않으며, 생성하는 데 걸리는 시간도 중요하지 않습니다. 중요한 것은 가능한 한 실제 데이터를 반영해야 하므로 데이터의 형태입니다. 그 외에는 데이터 생성 방법과 소요 시간에서 높은 수준의 자유가 있습니다.
대부분의 경우 문서의 크기와 모양이 다양하다고 가정하는 것이 좋습니다. 카우치베이스는 문서의 모양에 영향을 받지 않습니다. 카우치베이스는 값을 가리키는 키만 '인식'합니다. 크기는 다른 주제이므로 데이터 집합의 문서는 크기가 다양해야 합니다.
몇 가지 다른 문서를 모방하는 방법은 다음과 같습니다. 유형 속성을 추가합니다. 다시 말하지만 모양은 카우치베이스에서 중요하지 않지만, 카우치베이스의 유형 속성을 사용하면 동일한 문서 구조를 공유하더라도 서로 다른 유형의 문서를 모방할 수 있습니다.
이제 테스트 데이터 기준을 다음과 같이 요약할 수 있습니다:
- 문서의 크기는 다양해야 합니다.
- 문서는 동일한 JSON 구조를 공유할 수 있습니다.
- 문서의 콘텐츠는 고유해야 합니다.
- 문서에는
유형속성을 변경하여 데이터 집합의 다른 문서를 모방할 수 있습니다.
이를 염두에 두고 JSON 문서 구조를 다음과 같이 정의해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "Id": "GUID", "type": "perfTest", "IndexedType": "person + #", "NoneIndexedType": "person + #", "Day": 1->29, "Month": 1->12, "Year": 2015, "TextSmall": "100->250 random chars", "TextMedium": "200->500 random chars", "TextLarge": "700->1000 random chars", "TextExtraLarge": "1200-1500 random chars" } |
위의 문서 구조는 테스트 문서를 나타냅니다. 각 문서의 크기는 모든 문서의 텍스트... 속성에 임의의 크기와 값이 지정됩니다. 이렇게 무작위로 크기와 내용을 지정함으로써 각 문서는 실제 시스템에서 실제 문서와 가장 유사하게 모방할 수 있습니다.
실제 시스템에는 둘 이상의 문서 유형이 포함될 가능성이 높으므로 인덱싱된 유형 동일한 문서 구조가 시스템에서 다른 문서 유형을 모방할 수 있습니다.
속성 인덱싱된 유형 는 몇 가지 다른 예측 가능한 값을 취할 수 있습니다: person1, person2, person3 그리고 person4. 네 가지 값은 네 가지 다른 문서를 모방하는 데 사용됩니다. 더 많은 '유형'을 추가할 수도 있지만 이 테스트에서는 4개로 충분합니다.
그리고 유형 속성을 사용하면 테스트가 완료되었을 때 테스트 문서를 쉽게 검색하고 삭제할 수 있으며 항상 perfTest.
Couchbase Server에서 버킷에 문서를 로드하는 방법은 여러 가지가 있습니다. 한 가지 옵션은 문서를 미리 만들어서 버킷에 로드하는 것입니다. cbbackup 그리고 cbrestore 도구.
또 다른 옵션은 테스트 데이터를 즉석에서 생성하는 것입니다. 데이터를 로드하는 다른 방법도 생각해낼 수 있을 것 같습니다. 이 단계는 성능에 중요하지 않다는 점만 기억하세요! 가장 쉬운 방법을 선택하세요.
위의 정의가 마련되었으므로 테스트 벤치에 대한 단계를 정의할 준비가 되었습니다:
- 시스템을 알려진 상태로 가져오기
- 로드 테스트 데이터
- 테스트 데이터 쿼리 및 실행 시간 측정
- 인덱스 만들기
- 테스트 데이터 쿼리 및 실행 시간 측정
- 시스템을 알려진 상태로 가져오기
- 결과 인쇄
구현
1단계
N1QL 데이터 조작 기능은 아직 프리뷰 버전이지만 지금 바로 사용할 수 있습니다. 따라서 데이터 정리가 매우 간단해집니다:
|
1 |
"DELETE FROM `default` d WHERE d.type = 'perfTest' RETURNING d.Id |
인덱스는 다음을 사용하여 삭제할 수 있습니다. DROP 명령을 사용합니다:
|
1 2 3 |
DROP INDEX `default`.`index_1` USING GSI; DROP INDEX `default`.`index_2` USING GSI; DROP INDEX `default`.`index_3` USING GSI; |
카우치베이스 서버는 다음과 같은 경우 오류를 반환합니다. DROP 명령은 존재하지 않는 인덱스에 대해 실행됩니다. 인덱스가 존재하는지 여부를 확인하면 이 문제를 해결할 수 있습니다:
|
1 2 3 |
SELECT * FROM system:indexes WHERE name='index_1'; SELECT * FROM system:indexes WHERE name='index_2'; SELECT * FROM system:indexes WHERE name='index_3'; |
2단계
N1QL 데이터 조작 기능을 계속 사용하여 임의의 데이터 집합을 만드는 것도 가능하지만, 코드로 문서를 만드는 것보다 조금 더 복잡할 수 있습니다.
테스트 벤치 코드는 .NET을 사용하여 구현되며 문서는 다음 C# 스니펫을 사용하여 생성됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
private static void GenerateDocuments() { int rounds = numberOfTestDocuments > batchSize ? numberOfTestDocuments / batchSize : 1; int testDocsPerLoop = rounds > 1 ? batchSize : numberOfTestDocuments; Random ran = new Random(); for (int n = 0; n < rounds; n++) { var docs = new Dictionary<string, dynamic>(); for (int i = 0; i < testDocsPerLoop; i++) { string id = Guid.NewGuid().ToString(); string postFix = ran.Next(1, 4).ToString(); var doc = new { Id = id, type = "perfTest", IndexedType = "person" + postFix, NoneIndexedType = "person" + postFix, Day = ran.Next(1, 29), Month = ran.Next(1, 12), Year = "2015", TextSmall = new string( Enumerable.Range(0, ran.Next(100, 250)).Select(item => (char)ran.Next(44, 126)).ToArray()), TextMedium = new string( Enumerable.Range(0, ran.Next(200, 500)).Select(item => (char)ran.Next(44, 126)).ToArray()), TextLarge = new string( Enumerable.Range(0, ran.Next(700, 1000)).Select(item => (char)ran.Next(44, 126)).ToArray()), TextExtraLarge = new string( Enumerable.Range(0, ran.Next(1200, 1500)).Select(item => (char)ran.Next(44, 126)).ToArray()) }; docs.Add(id, doc); } ClusterHelper .GetBucket("default") .Upsert<dynamic>(docs); Console.Write("."); } } |
이 방법은 내부 루프와 외부 루프를 사용합니다. 내부 루프는 업로드 배치 크기를 정의합니다. 외부 루프는 카우치베이스 서버에 업로드할 배치의 수를 정의합니다.
루프는 대용량 데이터 세트를 업로드할 때 프로그램이 메모리 부족으로 실행되지 않도록 하기 위해 추가되었습니다.
3단계
테스트 문서를 Couchbase Server에 업로드한 후에는 테스트의 첫 번째 부분을 실행하고 실행 시간을 기록할 차례입니다:
|
1 |
SELECT * FROM `default` WHERE IndexedType='person3' AND Month > 5 AND Day < 20 |
테스트에 사용된 문서 수에 따라 이 쿼리가 시간 초과될 수 있습니다. 제 시스템에서는 500,000개의 문서에 대해 이 쿼리를 실행하면 시간 초과가 발생합니다. 15만 개의 문서에는 약 15초의 쿼리 시간이 소요됩니다.
4단계
이제 인덱스를 만들 차례입니다:
|
1 2 3 |
CREATE INDEX `index_1` ON `default`(IndexedType) USING GSI; CREATE INDEX `index_2` ON `default`(Month) USING GSI; CREATE INDEX `index_3` ON `default`(Day) USING GSI; |
그리고 인덱스 생성 명령은 동기식이며 보조 인덱스가 생성되고 준비되면 반환됩니다. 즉, 이 명령은 테스트의 문서 수와 컴퓨터의 크기에 따라 완료하는 데 시간이 걸릴 수 있습니다.
여러 인덱스 대 하나의 인덱스: 독립적인 인덱스가 여러 개 있으면 다른 속성이 누락된 독립 쿼리에서 각 속성을 검색할 때 유용합니다.
그러나 인덱스가 하나만 있으면 별도의 인덱스를 유지 관리해야 하는 오버헤드가 줄어들고 리소스 요구 사항을 줄일 수 있으며, 모든 필터 기준에 적합한 항목을 한 번에 찾을 수 있으므로 쿼리 속도를 훨씬 더 높일 수 있습니다.
세 개의 독립적인 인덱스 대신 이 인덱스를 사용할 수 있습니다:
|
1 |
CREATE INDEX `index_type_month_year` ON `default`(IndexedType, Month, Year) USING GSI; |
또는 심지어:
|
1 |
CREATE INDEX `index_type_month_year` ON `default`(IndexedType, Month, Year) WHERE IndexedType='person3' AND Month > 5 AND Day < 20 USING GSI; |
하지만 이런 유형의 테스트에는 여러 개의 인덱스를 사용하는 것이 더 정확하다고 생각합니다. 항상 단일 인덱스로 테스트를 실행하여 실행 시간의 차이를 측정하고 이 측정값을 사용하여 특정 사례에서 무엇이 최선인지 최종 결정할 수 있습니다.
5단계
인덱스가 생성된 후에는 테스트의 두 번째 부분을 실행하고 실행 시간을 기록할 차례입니다:
|
1 |
SELECT * FROM `default` WHERE IndexedType='person3' AND Month > 5 AND Day < 20 |
참고: 이 쿼리는 3단계에서 사용한 것과 완전히 동일한 쿼리입니다. 쿼리 자체는 변경되지 않았습니다.
제 시스템에서 일반적인 실행 시간은 4ms에서 23ms 사이입니다! 이는 큰 차이입니다! 그렇다면 데이터 세트 크기가 이 측정값에 어떤 영향을 미칠까요? 그 답을 얻으려면 계속 읽어보셔야 합니다.
6단계
모든 테스트 문서를 삭제하고 인덱스를 삭제한 후 시스템을 테스트 실행 전의 알려진 상태로 되돌립니다. 1단계와 동일합니다.
1단계나 6단계 중 어느 하나라도 필요하지 않다고 주장할 수도 있지만, 둘 다 매우 중요합니다. 테스트 실행이 중단되는 경우(취소, 실패 등)를 생각해 보세요.
7단계
마지막 단계이자 가장 흥미로운 단계인 결과물입니다.
내 시스템의 결과입니다:
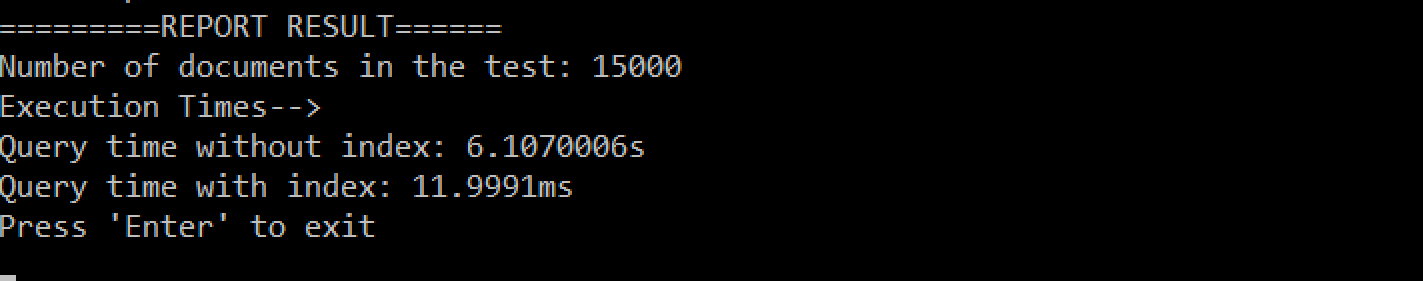
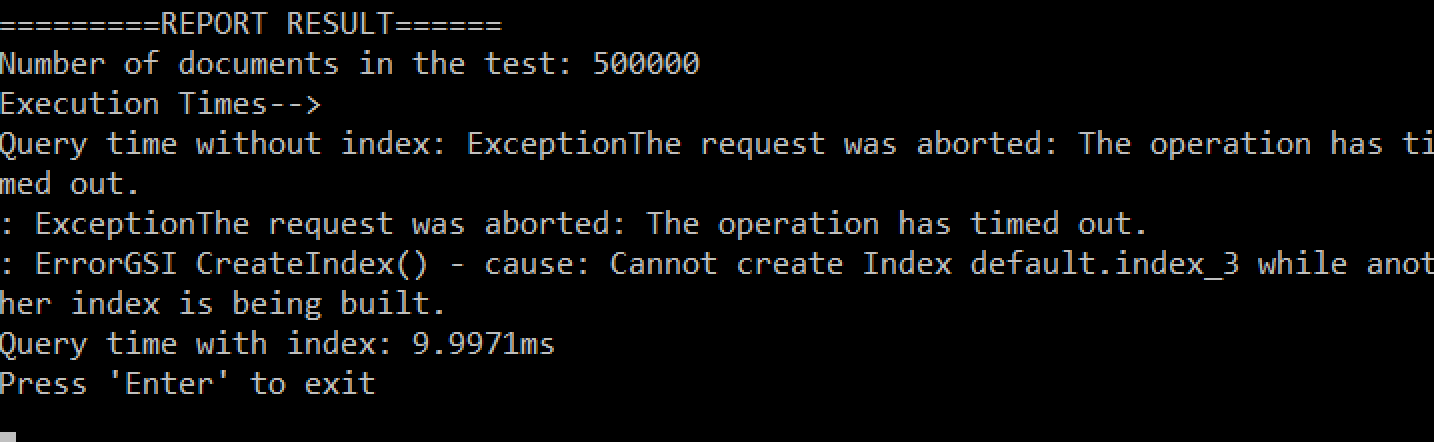
내 시스템의 결과 요약:
맥북 프로 16GB 메모리, 윈도우 10에서 실행되는 카우치베이스 서버, 10GB 메모리의 패러렐즈 데스크톱(카우치베이스 서버에는 2GB 메모리가 부여됨)
- 15.000개의 문서
- NO-index: 15s
- 색인: 7ms
- 500.000개의 문서:
- NO 인덱스: 시간 초과(5초 이상)분)
- 색인: 10ms
관찰, 인덱스를 사용할 때 실행 시간 측면에서 15만 개의 문서나 50만 개의 문서나 큰 차이가 없습니다.
학습, 보조 인덱스를 사용하는 것은 정말 중요하며 쿼리 성능에 큰 도움이 됩니다!
소스 코드
소스 코드는 GitHub에서 찾을 수 있습니다:
이 구현은 시간 초과/오류를 보정하고 작업 실패 및 시간 초과 시 재시도를 시도합니다.
N1QL의 베타 명령을 사용할 때 시간 초과가 자주 발생합니다. 삭제 를 사용하여 대용량 데이터 세트(500,000개 문서)에 대해 테스트했습니다. 이 기능은 아직 프리뷰 버전이므로 출시 시에는 이러한 동작을 예상할 수 없지만, 지금은 이러한 동작을 예상하고 그에 따라 보완할 필요가 있습니다.
벤치마크에 대한 이야기가 있습니다. 상황에 따라 다릅니다.
시스템에서 어떤 성능을 기대할 수 있나요? 상황에 따라 다릅니다! 하지만 이제 설정에 대해 테스트 코드를 실행하여 더 나은 아이디어를 얻을 수 있습니다.
하지만 한 가지는 확실합니다! 보조 인덱스를 만드는 것을 잊지 마세요! 성능이 크게 향상됩니다! 숫자로 말하면 인덱스는 성능을 100~1000배까지 향상시킬 수 있습니다!
인덱스를 사용하면 클러스터의 CPU 사용량에 영향을 미치므로 어떤 인덱스를 구현할지 정확히 고려하고 필요 이상으로 만들지 않는 것이 좋습니다.
한 줄의 코드로는 정말 가성비가 뛰어납니다.)
|
1 |
CREATE INDEX `{INDEX_NAME}` ON `{BUCKET_NAME}`({ATTRIBUTE_NAME}) USING GSI; |
테스트 결과를 아래 댓글에 자유롭게 게시하여 N1QL에서 기대할 수 있는 성능에 대해 더 잘 이해할 수 있도록 도와주세요.