PC 또는 Mac에서 Couchbase 서버를 실행하려면 소프트웨어를 다운로드하고 필요한 모든 Couchbase 서비스가 포함된 클러스터를 스핀업하는 몇 가지 간단한 단계를 거치면 됩니다(https://docs.couchbase.com/server/6.0/getting-started/start-here.html). 소프트웨어와 함께 샘플 버킷이 제공되므로 몇 분 안에 제품을 사용해 볼 수 있습니다.
관계형 데이터베이스를 Couchbase로 마이그레이션해야 하는 경우 사용할 수 있는 커넥터가 있습니다(https://docs.couchbase.com/server/6.0/connectors/intro.html)를 사용하면 목표를 달성할 수 있습니다. 그러나 RDBMS와 Couchbase 데이터베이스 도구에 모두 익숙한 경우 데이터베이스 데이터 내보내기 도구를 활용하고 Couchbase를 사용할 수 있습니다. cbimport 를 사용하여 Couchbase 버킷에 데이터를 로드합니다.
두 접근 방식 모두 데이터베이스 간의 차이로 인해 몇 가지 결정을 내려야 합니다:
- RDBMS 테이블과 카우치베이스 버킷 비교.
- 데이터베이스 기본 키 및 버킷 문서 키.
- 마지막으로 관계형 데이터베이스 스키마를 Couchbase JSON 문서 데이터베이스로 변환하는 방법에 대해 알아보세요.
이 블로그에서는 이러한 차이점에 대해 논의하고 관계형 데이터베이스 스키마를 Couchbase NoSQL 데이터베이스로 변환하기 위해 고려할 수 있는 다양한 전략을 간략하게 설명합니다. 마이그레이션 기술은 많은 RDBMS에 일반화할 수 있지만, 소스 데이터베이스를 쿼리하는 실제 프로세스는 특정 REST API를 활용합니다. 따라서 저는 Oracle과 그 샘플 HR 스키마를 소스 데이터로 사용하고, 데이터 추출을 위해 그 REST 데이터 서비스를 활용하겠습니다.
필요한 도구
이 블로그의 마이그레이션 기술은 Oracle 데이터베이스의 기본 서비스와 Couchbase N1QL 쿼리 언어를 활용합니다. 다른 것은 필요하지 않습니다.
이러한 마이그레이션 기술을 사용하는 방법
제공된 N1QL 스크립트는 문서 유형과 문서 키의 처음 두 가지 문제를 해결합니다. 관계형 스키마를 Couchbase JSON 데이터베이스로 변환하는 경우 이 스크립트는 이 세 가지 시나리오를 다룹니다:
- 테이블에서 문서 유형으로 직접 매핑합니다. 변환이 필요하지 않습니다.
- 부모를 자식 객체로 비정규화합니다.
- 자식 객체를 배열 필드로 부모 객체로 비정규화합니다.
문서 유형 및 문서 키 솔루션이 포함된 위의 시나리오는 관계형 스키마를 JSON 문서 데이터베이스로 변환하는 대부분의 사용 사례를 다룰 수 있습니다.
전제 조건
- HR 샘플 스키마를 사용하여 Oracle 데이터베이스 서버에 액세스합니다.
- 버킷을 만들어야 하는 카우치베이스 데이터베이스에 액세스합니다. cbhr 를 오라클 HR 스키마 마이그레이션 대상으로 지정합니다.
단계
- REST 데이터 서비스 액세스를 위해 Oracle 스키마를 사용하도록 설정합니다.
- Couchbase 서버를 설정하고 버킷을 구성하여 Oracle HR 데이터를 수신하도록 합니다.
- 마이그레이션 요구 사항에 맞는 데이터 모델 변환 기술을 결정하세요.
- N1QL 스크립트를 편집하고 실행하여 데이터를 마이그레이션합니다.
HR 스키마가 포함된 Oracle 데이터베이스
오라클 HR 스키마는 오라클 설치에서 사용할 수 있습니다. 스키마를 배포하려면 오라클 설명서를 참조하세요. https://docs.oracle.com/cd/E11882_01/server.112/e10831/installation.htm#COMSC001
REST 서비스용 Oracle 스키마 사용
기본적으로 Oracle REST 데이터 서비스는 스키마에서 사용하도록 설정되어 있지 않습니다. HR 스키마에 대해 이를 활성화해야 합니다.
REST 호출을 실행할 사용자로 로그인합니다. 이 예제에서는 다음과 같이 로그인합니다. hr를 클릭하고 다음 스크립트를 실행합니다.
|
1 2 3 4 5 6 7 8 |
BEGIN ORDS.ENABLE_SCHEMA( p_enabled => TRUE , p_schema => 'HR' , p_url_mapping_type => 'BASE_PATH' , p_url_mapping_pattern => 'hr' , p_auto_rest_auth => FALSE); commit; END; |
참조: https://blogs.oracle.com/oraclemagazine/get-your-rest-post-your-sql
https://:8080/ords/hrrest/employees/에서 REST 호출로 오라클을 쿼리할 수 있는지 확인합니다.
참고: 기본적으로 Oracle REST 지원 SQL 서비스는 꺼져 있습니다. REST 사용 SQL 서비스 설정을 구성하려면 다음을 참조하십시오. REST 사용 SQL 서비스 설정 구성.
Couchbase 서버 준비
Couchbase 서버 설정에는 두 가지 단계를 완료해야 합니다.
- 다음과 같은 이름으로 버킷을 만듭니다.
cbhr. 버킷의 크기는 마이그레이션하려는 데이터의 양에 따라 달라집니다. - 카우치베이스 서버 설정에서 CURL() 함수 액세스를 사용하도록 설정했는지 확인하세요.

3. 또한 기본 인덱스를 만들어야 합니다. cbhr 버킷을 추가하여 N1QL이 마이그레이션의 일부로 버킷을 쿼리할 수 있도록 합니다.
|
1 |
CREATE PRIMARY INDEX `#primary` ON `cbhr` |
데이터 모델 변환
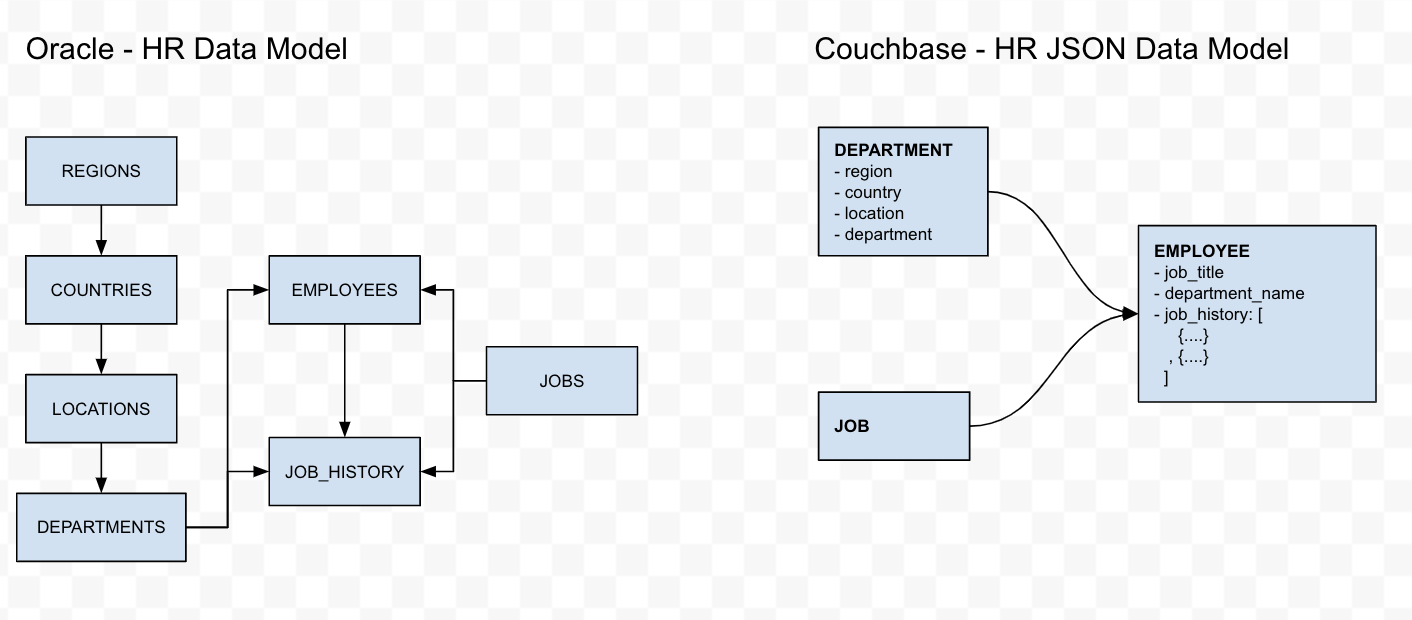
관계형에서 NoSQL로 마이그레이션하는 것은 큰 작업이며, 이 블로그에서는 각 데이터베이스의 장단점을 다루지 않습니다. 그러나 데이터가 저장되는 방식에 차이가 있으므로 이러한 변경 사항을 어떻게 관리할지 결정해야 합니다. 이 블로그의 N1QL 스크립트는 다음과 같은 전략을 사용하여 Oracle HR 스키마를 다음과 같은 Couchbase JSON 데이터 모델로 변환합니다:
- 지역, 국가, 위치는 부서의 직간접적인 상위 엔티티입니다. 따라서 부모/조부모/증조부모를 부서 엔터티로 비정규화할 수 있습니다. 이렇게 하면 쿼리에서 이러한 정보가 필요할 때 JOIN의 필요성이 줄어듭니다. 또한 Employees 및 Job_History와 같은 다른 연관된 엔터티에는 부서_id라는 참조만 있습니다. 따라서 지역, 국가 및 부서의 위치에 대한 정보를 Couchbase JSON 모델에서 '부서' 개체로 비정규화하는 것이 좋습니다.
- Jobs 엔티티에는 급여 규모에 대한 정보가 포함됩니다. 이는 민감한 데이터일 수 있습니다. 따라서 이 개체를 변환하지 않고 직접 마이그레이션할 것입니다.
- 직원 엔티티에는 직원의 중요한 속성인 job_id 및 department_id와 같은 기타 관련 정보가 포함되어 있습니다. 직책과 부서 이름을 '직원' 개체로 비정규화하는 것이 좋습니다.
- Job_History 개체는 실제로는 Employees 개체의 하위 개체입니다. 따라서 직원의 작업 이력을 '직원' 개체에 포함하는 것이 합리적입니다.
표와 문서 유형
카우치베이스에서는 테이블의 개념이 적용되지 않습니다. 모든 문서는 하나의 버킷에 저장할 수 있습니다. 유형 필드를 사용하여 문서 유형을 구분할 수 있습니다. 이는 Couchbase NoSQL 데이터베이스의 서로 다른 문서 간에 스키마 제한이 없기 때문에 가능합니다.
포함된 스크립트에서 이 문제를 처리합니다. doc_type 필드에 소스 테이블 이름 값을 입력합니다.
|
1 |
SELECT 'employee' doc_type ... FROM hr.employees... |
기본 키 매핑
Oracle 테이블에는 일반적으로 기본 키가 있으며, HR 스키마에서 이를 확인할 수 있습니다. Couchbase 문서에도 기본 키가 필요합니다. 하지만 모든 Oracle 테이블 데이터는 하나의 Couchbase 버킷에 저장되므로 Couchbase에서 이러한 문서 유형의 키 값을 구분할 수 있는 방법이 필요합니다.
포함된 스크립트는 이 문제를 해결하기 위해 doc_key 오라클 HR 테이블 이름과 해당 기본 키 값을 사용합니다.
|
1 |
SELECT 'employee:' ||e.employee_id doc_key FROM hr.employees ... |
카우치베이스 JSON 문서와 관계형
관계형 스키마를 NoSQL로 변환하는 방법에 대한 딱딱하고 빠른 규칙은 없습니다. 모든 테이블을 각각의 고유한 doc_type 필드에 입력합니다.
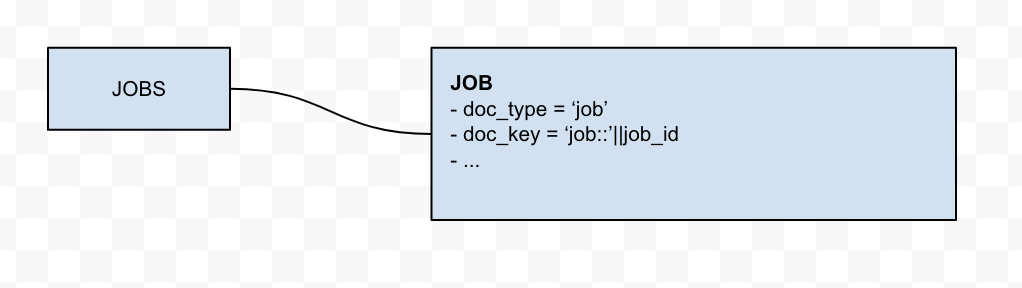
표를 문서로 바로 이동
이것은 가장 간단한 경우로, 가장 간단한 경우는 doc_type 그리고 doc_key 에 Couchbase 문서가 추가됩니다. 관계형 개체는 마이그레이션 프로세스 중에 어떤 변환도 필요하지 않습니다.
|
1 2 3 4 5 6 7 8 9 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("https://<your_server_ip>:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'job' doc_type, 'job:'||j.job_id doc_key, j.* FROM jobs j" , "user":'HR:oracle'} ) r UNNEST r.items[0].resultSet.items as ndoc |
참고:
- UPSERT는 카우치베이스 버킷의 결과에 영향을 주지 않고 쿼리를 다시 실행할 수 있도록 하는 데 사용됩니다.
- N1QL CURL 명령은 오라클 서버에서 처리할 쿼리를 사용하여 오라클 Rest 데이터 서비스에서 REST 엔드포인트를 호출합니다.
- N1QL CURL은 배열 필드에 쿼리 결과 집합이 있는 JSON 문서를 반환합니다. r.items[0].resultSet.items.
- N1QL 쿼리는 UNNEST 명령을 사용하여 r.items[0].resultSet.items 배열을 사용하여 각 Oracle 레코드를 별도의 JSON 문서로 반환합니다.
- N1QL UPSERT는 각 문서를 Couchbase에 삽입합니다. cbhr 버킷.
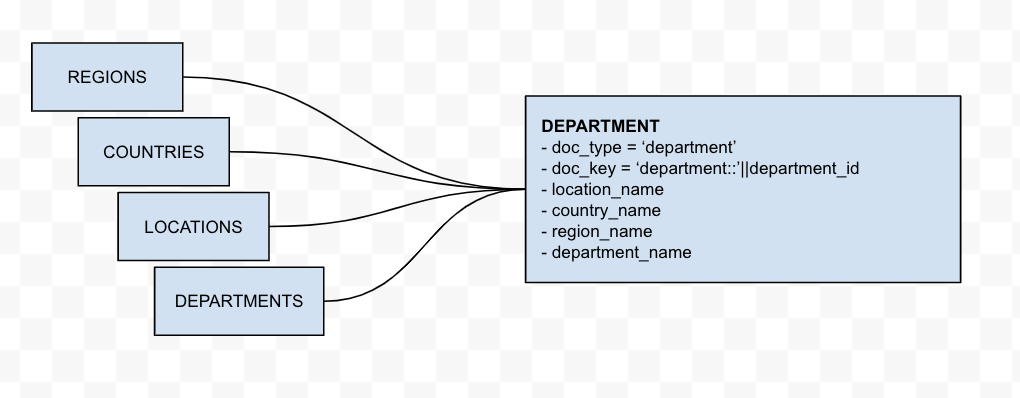
비정규화
이 변환은 여러 Oracle 테이블을 단일 개체로 결합합니다. 이 예에서 Regions, Countries 및 Locations 테이블은 직접적인 상위-하위 관계를 가지므로 상위 필드를 하위 개체에 추가할 수 있습니다. 최종 결과는 위치, 국가 및 지역을 포함하는 단일 부서 개체가 됩니다. 이 변환은 단일 단계 프로세스입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
UPSERT INTO cbhr (KEY doc_key, VALUE ndoc) SELECT ndoc.doc_key , ndoc FROM CURL( "<your_database_server_ip>:8080/ords/hr/_/sql" , { "request":"POST","header":"Content-Type: application/sql" , "data": "SELECT 'department' doc_type, 'department:' ||d.department_id doc_key, d.department_id, d.department_name, d.manager_id , l.* , c.country_name, r.* FROM departments d INNER JOIN locations l ON d.location_id=l.location_id INNER JOIN countries c ON l.country_id = c.country_id INNER JOIN REGIONS r ON c.region_id = r.region_id" ,"user":'HR:oracle'} ) res UNNEST res.items[0].resultSet.items as ndoc |
참고:
- UPSERT는 카우치베이스 버킷의 결과에 영향을 주지 않고 쿼리를 다시 실행할 수 있도록 하는 데 사용됩니다.
- N1QL CURL 명령은 오라클 서버에서 처리할 쿼리를 사용하여 오라클 Rest 데이터 서비스에서 REST 엔드포인트를 호출합니다.
- N1QL CURL은 배열 필드에 쿼리 결과 집합이 있는 JSON 문서를 반환합니다. r.items[0].resultSet.items.
- N1QL 쿼리는 UNNEST 명령을 사용하여 r.items[0].resultSet.items 배열을 사용하여 각 Oracle 레코드를 별도의 JSON 문서로 반환합니다.
- N1QL UPSERT는 각 문서를 Couchbase에 삽입합니다. cbhr 버킷.
비정규화 - 부모 개체에 자식 레코드를 배열 필드로 추가하기
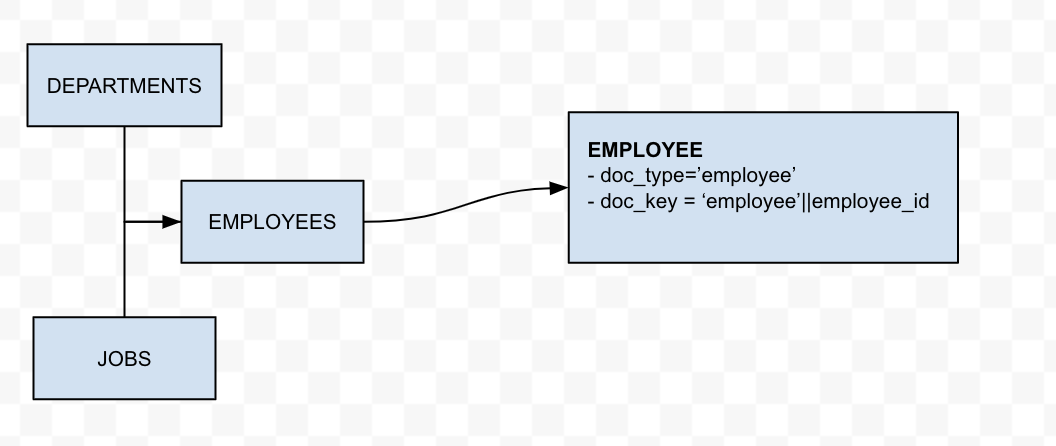
NoSQL 데이터베이스의 주요 기능 중 하나는 배열을 사용한다는 점입니다. Couchbase NoSQL 데이터베이스는 JSON 형식으로 문서를 저장하며, 여기서 필드는 배열이 될 수 있습니다. 이 연습에서는 상위 EMPLOYEES 테이블에 JOB_HISTORY 테이블을 추가하겠습니다. 이렇게 하면 효과적으로 새로운 job_history 배열 필드를 EMPLOYEE 문서에 추가합니다.
이 변환은 2단계 프로세스. 첫 번째 단계는 직원 데이터를 마이그레이션하는 것입니다. 두 번째 단계는 직원 데이터는 이미 Couchbase에 있는 cbhr 버킷에 대한 오라클 쿼리를 사용하여 job_history.
상위 문서
|
1 2 3 4 5 6 7 8 9 10 11 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("https://192.168.1.117:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'employee' doc_type, 'employee:' ||e.employee_id doc_key, e.* , j.job_title, d.department_name FROM employees e INNER JOIN jobs j ON e.job_id = j.job_id INNER JOIN departments d ON e.department_id = d.department_id" , "user":'HR:oracle' }) r UNNEST r.items[0].resultSet.items as ndoc |
자식 레코드는 상위 문서에서 배열 필드로 표시됩니다.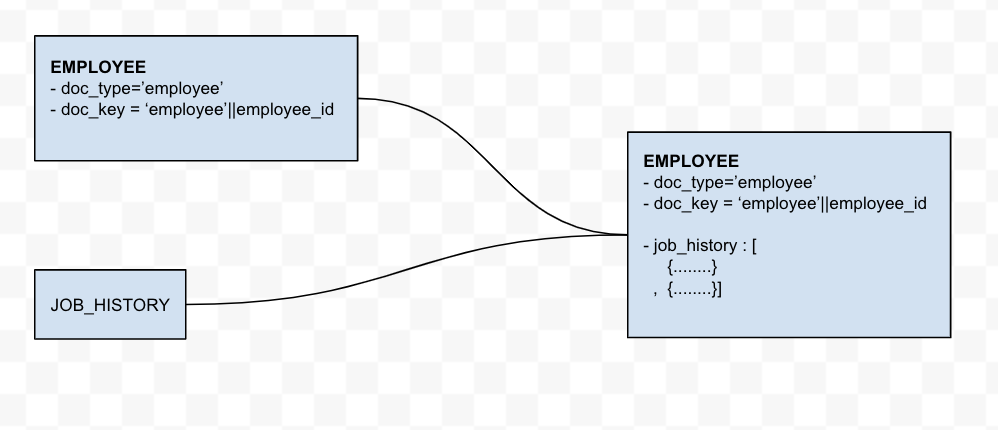
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MERGE INTO cbhr e USING ( SELECT ndoc.employee_id, ARRAY_AGG(ndoc) all_jobs FROM CURL( "https://<your_database_server>:8080/ords/hr/_/sql" , {"request":"POST","header":"Content-Type: application/sql" , "data": "SELECT h.employee_id, h.start_date,h.end_date, h.job_id, j.job_title, h.department_id FROM job_history h INNER JOIN jobs j ON h.job_id=j.job_id" , "user":'HR:oracle' } ) res UNNEST res.items[0].resultSet.items as ndoc GROUP BY ndoc.employee_id ) source ON KEY 'employee:'||to_string(source.employee_id) WHEN MATCHED THEN UPDATE SET e.job_history = source.all_jobs |
참고:
- N1QL 쿼리는 MERGE 명령을 사용하여 다음과 같은 문서를 결합합니다. cbhr 버킷의 doc_type 는 직원 오라클의 CURL REST 읽기에서 SELECT의 결과와 함께 job_history.
- 이 쿼리는 N1QL ARRAY_AGG를 사용하여 모든 작업을 다음과 같이 그룹화합니다. employee_id.
- MERGE는 다음을 사용합니다. 'employee:'||to_string(source.employee_id) 를 두 결과 집합을 일치시키는 키로 지정합니다.
제한 사항
N1QL CURL()이 검색할 수 있는 데이터의 양에는 제한이 있습니다. 현재 최대 크기는 64MB로 설정되어 있으며 수정할 수 없습니다. 대용량 Oracle 테이블을 마이그레이션하려는 경우 이는 많은 양이 아닙니다. 하지만 Oracle은 마이그레이션 프로세스를 더 작은 청크로 나눌 수 있는 OFFSET 및 FETCH NEXT를 지원합니다.
또한 이 블로그의 주된 목적은 관계형 스키마를 Couchbase JSON 문서 데이터베이스로 마이그레이션할 때 고려해야 할 사항과 마이그레이션 프로세스에서 직접 관계형 스키마를 변환하는 데 N1QL이 어떻게 도움이 되는지를 강조하기 위함입니다.
질문이나 피드백이 있으면 아래에 댓글을 남겨 주세요.
안녕하세요 Binh, 이것은 훌륭하고 매우 도움이되지만 크기 조정에서 CURL의 한계를 알기 때문에 OLAP 모델에 10 개의 서로 다른 조인이있을 때 Oracle에서 Couchbase로 일괄로드하는 대량의 데이터 마이그레이션 작업을 처리하는 방법을 알고 싶습니다. 이에 대한 의견을 공유해 주세요. Oracle ORDS를 사용하는 프로세스를 복제하려고하지만 OFFSET 및 FETCH를 사용하여이를 처리하는 방법을 잘 모르겠습니다.
고마워요
Debashis,
블로그에 관심을 가져주셔서 감사합니다. Oracle "OFFSET 및 FETCH {FIRST |NEXT} ..." 절을 활용하려면 스크립팅 언어(예: Python 및 Couchbase SDK)를 사용해야 합니다. 여기서는 Oracle 레코드 집합을 반복합니다. 이 포럼 게시물을 참조하세요. https://www.couchbase.com/forums/t/oracle-to-couchbase/22044 를 참조하여 프로그래밍 방식으로 이를 달성할 수 있는 방법을 제안해 주세요.
고마워요,
-binh