현장 엔지니어로서 저는 고객과 함께 일하면서 종종 고객들이 카우치베이스 기능을 '즉시 사용 가능한' 접근 방식으로 제공합니다.
제가 보기에 더 창의적으로 사용되는 기능 중 하나는 다음과 같습니다. 글로벌 보조 지수(GSI) 파티션에 대해 알아보겠습니다. 먼저 GSI와 쿼리, 그리고 파티셔닝에 대해 알아보고 속도를 높이기 위해 파티셔닝에 대해 설명하겠습니다.
글로벌 보조 인덱스란 무엇인가요?
카우치베이스 문서에 따르면, 다음과 같이 설명합니다. 글로벌 보조 인덱스 (GSI)에서 만든 쿼리를 지원합니다. 쿼리 서비스 를 문서 내 속성으로 설정할 수 있습니다. 광범위한 필터링이 지원됩니다.
글로벌 보조 인덱스는 다음을 제공합니다:
-
- 고급 확장: GSI는 기존 워크로드의 영향을 받지 않고 선택한 노드에 독립적으로 할당할 수 있습니다.
- 예측 가능한 성능: 키 기반 작업은 많은 수의 인덱스가 있는 경우에도 예측 가능한 낮은 지연 시간을 유지합니다. 인덱스 유지 관리는 데이터 변이 워크로드가 많은 경우에도 키 기반 작업과 경쟁이 되지 않습니다.
- 지연 시간이 짧은 쿼리: GSI는 인덱스 서비스 노드에 독립적으로 파티셔닝합니다: 데이터의 해시 파티셔닝을 따라 vBuckets로 분할할 필요가 없습니다. GSI는 모든 데이터 서비스 노드에 대한 광범위한 팬아웃이 필요하지 않으므로 GSI를 사용하는 쿼리는 클러스터가 확장되는 경우에도 지연 시간이 짧은 응답 시간을 달성할 수 있습니다.
- 독립 파티셔닝: 인덱스 서비스는 파티션 독립성을 제공합니다: 데이터와 그 인덱스는 서로 다른 파티션 키를 가질 수 있습니다. 각 인덱스는 고유한 파티션 키를 가질 수 있으므로 특정 쿼리와 일치하도록 각각을 독립적으로 파티션할 수 있습니다. 새로운 요구 사항이 발생하면 애플리케이션은 기존 쿼리의 성능에 영향을 주지 않고 새로운 파티션 키로 새 인덱스를 생성할 수도 있습니다.
GSI 파티셔닝
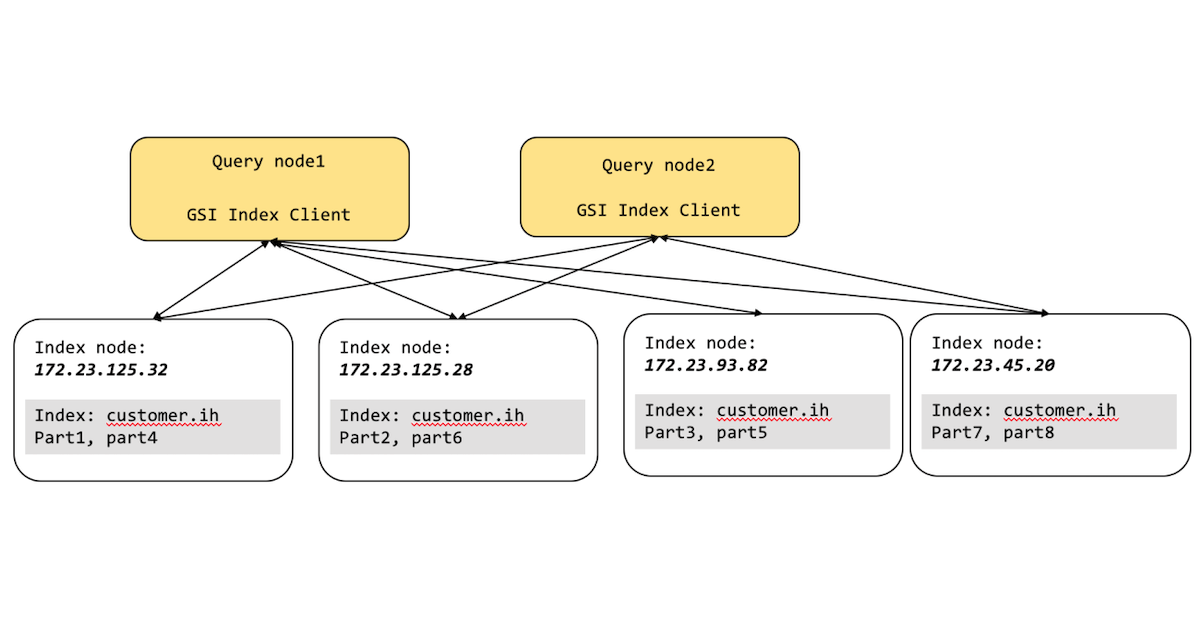
위의 다이어그램에서 쿼리-색인 오케스트레이션은 애플리케이션 개발자뿐만 아니라 Couchbase 관리자를 위해 쿼리 서비스 및 색인 서비스에서 원활하게 처리됩니다.
인덱스 분할은 대규모 문서 인덱스를 여러 노드에 분할하여 분산시킴으로써 쿼리 성능을 향상시킵니다. 이 기능은 Couchbase Server Enterprise Edition에서만 사용할 수 있습니다. 다음과 같은 이점이 있습니다:
-
- 인덱스 크기가 커짐에 따라 수평으로 확장할 수 있는 기능.
- 기존 쿼리를 변경할 필요가 없는 쿼리 투명성.
- 파티션을 병렬로 스캔할 수 있으므로 대규모의 집계 쿼리에 대한 쿼리 대기 시간이 단축됩니다.
- 지연 시간이 짧은 범위 쿼리를 제공하면서 필요에 따라 인덱스를 확장할 수 있습니다.
자세한 내용은 다음을 참조하세요. 인덱스 파티셔닝에 대한 카우치베이스 문서.
인덱스 파티셔닝은 위에서 언급한 대로 인덱스 관리를 더 쉽게 만들어주는 많은 기능을 제공하지만, 인덱스 파티셔닝을 다음과 같은 용도로 사용해 보십시오. 더 보기 단순한 파티셔닝이 아닌가요?
인덱스 파티셔닝에 대해 자세히 알아보기
이 블로그 게시물에서는 기본적인 사용 사례에 중점을 두겠습니다. 해시별 파티션 는 인덱스 크기와 성능을 지시하고 정량화할 수 있는 매우 강력한 기능입니다.
인덱스 파티셔닝에는 저장 공간, 성능 또는 확장성을 관리하기 위해 인덱스를 사용자 정의할 수 있는 여러 가지 훌륭한 기능이 있습니다.
분할 인덱스를 만드는 가장 간단한 방법은 문서 키를 분할 키로 사용하는 것입니다:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX idx_pe1 ON `travel-sample`(country, airline, id) PARTITION BY HASH(META().id); SELECT airline, id FROM `travel-sample` WHERE country="United States" ORDER BY airline; |
함께 메타().id 를 파티션 키로 지정하면 인덱스 키가 모든 파티션에 균등하게 분배됩니다. 모든 쿼리는 모든 파티션에서 적격 인덱스 키를 수집합니다.
범위 쿼리를 위한 파티션 키 선택하기
애플리케이션에는 분할된 인덱스의 범위 쿼리 대기 시간을 최소화할 수 있는 분할 키를 선택할 수 있는 옵션도 있습니다.
예를 들어 쿼리에 필드에 기반한 동일성 술어가 있다고 가정해 보겠습니다. 소스공항 그리고 목적지공항. 인덱스도 인덱스 키에 의해 분할된 경우 소스공항 그리고 목적지공항로 설정하면 쿼리는 주어진 쌍에 대해 단일 파티션만 읽으면 됩니다. 소스공항 그리고 목적지공항.
이 경우 애플리케이션은 낮은 쿼리 대기 시간을 유지하면서 필요에 따라 파티션된 인덱스를 확장할 수 있습니다.
적격 파티션을 선택하기 위해 파티션 키가 선행 인덱스 키일 필요는 없습니다. 선행 인덱스 키가 술어의 파티션 키와 함께 제공되면 쿼리에서 인덱스 스캔을 위한 적격 파티션을 선택할 수 있습니다. 다음 예는 주어진 쌍의 소스공항 그리고 목적지공항.
쿼리 동일성 술어와 일치하는 파티션 키를 사용하여 파티션 인덱스를 생성합니다:
|
1 2 3 4 5 6 7 |
# Lookup all airlines with non-stop flights from SFO to JFK CREATE INDEX idx_pe2 ON `travel-sample` (sourceairport, destinationairport,stops, airline, id) PARTITION BY HASH (sourceairport, destinationairport); SELECT airline, id FROM `travel-sample` WHERE sourceairport="SFO" AND destinationairport="JFK" AND stops == 0 ORDER BY airline; |
파티션 수
인덱스 파티션의 수는 인덱스가 생성될 때 고정됩니다.
기본적으로 각 인덱스에는 8개의 파티션이 있습니다. 관리자는 다음에서 파티션 수를 재정의할 수 있습니다. 인덱스 생성 시간.
파티션 배치
분할된 인덱스가 생성되면, 사용 가능한 인덱스 노드에 걸쳐 파티션이 구분됩니다. 새 인덱스를 배치하는 동안 인덱서는 각 파티션의 크기가 같다고 가정하고 각 노드의 리소스 가용성에 따라 파티션을 배치합니다.
예를 들어, 인덱서 노드가 다른 노드보다 사용 가능한 메모리가 더 많으면 이 인덱서 노드에 더 많은 파티션이 할당됩니다. 인덱스에 복제본이 있는 경우 복제본 파티션은 동일한 노드에 배치되지 않습니다.
또는 다음 예제와 유사한 명령을 사용하여 노드 목록을 지정하여 배치에 사용할 수 있는 노드 집합을 제한할 수 있습니다:
노드의 특정 포트에 분할 인덱스를 생성합니다:
|
1 |
CREATE INDEX idx_pe12 ON `travel-sample`(airline, sourceairport, destinationairport) PARTITION BY KEY(airline) WITH {"nodes":["127.0.0.1:9001", "127.0.0.1:9002"]}; |
인덱스가 노드가 저장할 수 있는 것보다 큰 경우가 있기 때문에, 인덱스 파티셔닝의 원래 의도는 클러스터의 여러 파티션, 즉 노드에 걸쳐 "큰" 인덱스를 확장하는 것이었습니다.
하지만 일부 고객은 GSI 파티션을 다른 방식으로 바라봅니다.
제가 더 자주 보는 사례 중 하나는 노드 간 워크로드 분산으로 파티셔닝을 사용하는 것입니다. 인덱스 자체는 크지 않지만 인덱싱된 모든 파티션을 여러 노드에 분산하면 인덱스를 병렬로 스캔할 수 있는 파티셔닝의 아키텍처를 활용할 수 있습니다! 이렇게 하면 인덱스 스캔이 단일 파티션이 아닌 모든 파티션/노드에 고르게 분산됩니다.
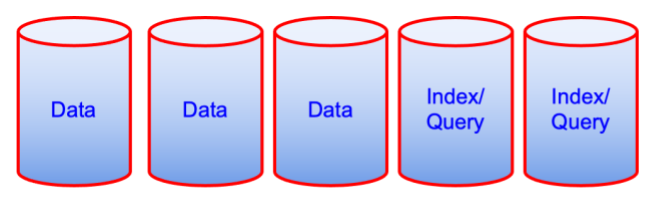
일부 고객은 데이터, 인덱스, 쿼리 등의 서비스를 함께 배치하여 인덱스/쿼리와 같은 서비스를 별도의 노드로 분리하는 것에 비해 성능 저하가 없는 경우도 있습니다. 이 접근 방식에 대한 한 가지 주의 사항은 이러한 모든 서비스가 운영 체제 자체와 함께 실행될 수 있는 충분한 CPU, 메모리 및 디스크 공간이 있는지 확인하는 것입니다.
데이터 및 인덱스 서비스는 메모리에 제한이 있으며 클러스터 설정을 통해 할당량을 정의합니다. 쿼리 서비스는 메모리 제한이 없지만 메모리를 사용합니다. 카우치베이스 관리자는 데이터 및 인덱스 서비스의 사용 가능한 메모리와 할당량을 알고 있어야 하며, 쿼리 서비스 및 OS를 위한 충분한 여유 메모리를 확보해야 합니다.
이전
이후
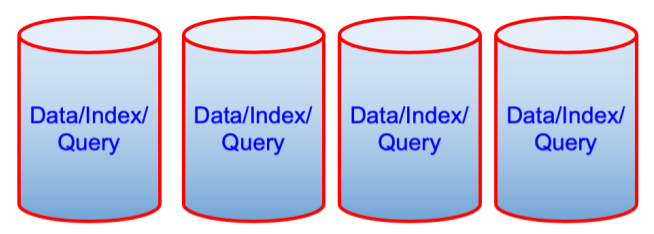
위의 두 다이어그램은 성능의 관점에서 보면 직관적이지 않은 것처럼 보일 수 있지만, 소유 비용의 관점에서 보면 기계 한 대가 줄어든 것입니다. 때로는 그것이 원동력이 되기도 합니다.
파티셔닝을 위한 다른 전략은 무엇인가요? 일반적으로 쿼리는 지연 시간 및 처리량뿐만 아니라 SLA 및 사용 사례의 특수성에 따라 결정됩니다. 예를 들어 일부 고객은 보고를 위해 하루에 한두 번 쿼리를 실행합니다. 이 경우 반드시 고성능이 필요하나요? 그렇지 않습니다. 이러한 유형의 쿼리에 가장 적합한 전략은 무엇일까요?
서로 다른 20개의 쿼리가 있다고 가정해 보겠습니다. 어디 절을 사용하여 특정 위치에서 하루에 생성되는 송장 수를 찾는 쿼리를 만들 수 있습니다. 송장 쿼리를 위해 각 위치에 대해 20개의 서로 다른 인덱스를 만드는 것이 현명할까요? 전체적으로 동일한 데이터를 사용하는 다른 쿼리(중복 데이터라고도 함)가 있다면 어떻게 해야 할까요? 일부 데이터는 국가별 데이터로, 10개의 위치가 같은 국가에 있을 수 있습니다.
제품 디스플레이와 같이 자주 실행되는 쿼리이거나 애플리케이션의 중요한 부분이라면 전용 인덱스가 적합할 수 있습니다. 하지만 이 경우에는 하나의 큰 인덱스가 저장 공간과 리소스 효율성이 더 높을 수 있습니다. 따라서 인덱스 파티션이 더 적절할 수 있습니다.
명령 및 쿼리 책임 분리(CQRS)
파티션을 더 효율적으로 사용하는 또 다른 예는 쓰기가 작업을 지배하는 쓰기 중심 워크로드입니다. 한 가지 패턴은 CQRS(명령 및 쿼리 책임 분리)입니다.
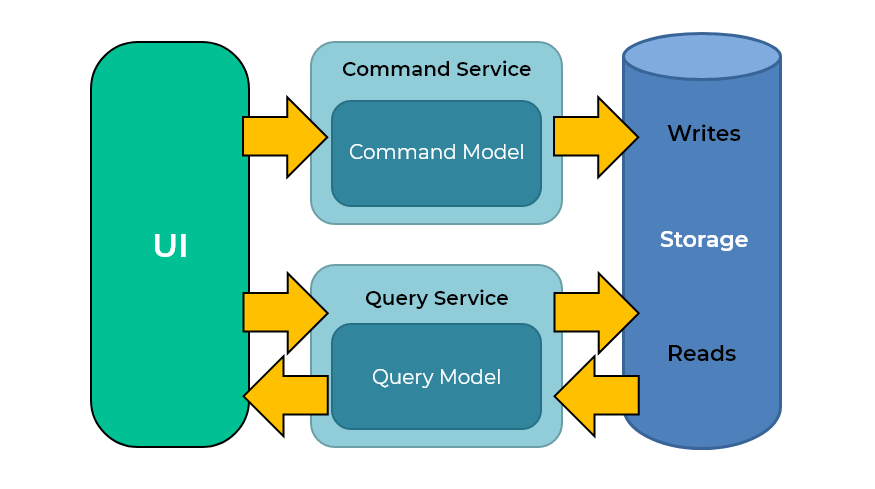
많은 문서가 데이터베이스에 기록되고 빠른 쿼리가 필요한 곳입니다. 일반적으로 애플리케이션과의 사용자 상호 작용, 클릭 수 등과 같은 애플리케이션 이벤트가 여기에 해당합니다. 이러한 이벤트는 대량으로 작성되고 자주 쿼리됩니다. 인덱스 파티셔닝을 사용하면 문서 키를 인덱스에 쓰는 작업이 한 노드에 집중되지 않고 인덱스 노드 전체에 분산되어 균형을 이룹니다. CQRS는 인덱스 파티션의 좋은 사용 사례입니다.
결론
글로벌 보조 인덱스 파티셔닝의 몇 가지 용도에 대해서만 살펴보았습니다. 이는 특정 사용 사례에 맞게 조정할 수 있는 GSI의 과소평가되고 잘 사용되지 않는 기능 중 하나입니다.
자세히 알아보기 카우치베이스 문서의 글로벌 보조 인덱스(GSI).
