이전 블로그 게시물에서는 다음 사항에 대해 이야기했습니다. 애플리케이션에서 잘 설계된 검색을 구현하기 위해 전체 텍스트 검색이 대규모로 더 나은 솔루션인 이유. 이번 2부에서는 반전 인덱스에 대해 자세히 알아보고 분석기, 토큰화 도구, 필터가 검색 결과를 어떻게 형성하는지 살펴보겠습니다.
전체 텍스트 검색은 텍스트를 검색하는 것이므로 로그, DNA의 유전자, 자체 데이터 구조는 물론 언어까지 색인하고 검색하는 것은 중요하지 않습니다. 기본적으로 모두 거의 동일한 방식으로 작동합니다.
자체 사용자 지정 구조가 있는 경우에도 FTS를 사용할 수 있는 방법을 예로 보여드리기 위해 Apple이 마침내 Shazam을 인수했다는 사실을 활용하여 Shazam과 유사한 가상의 앱을 만들어 봅시다. 하지만 Shazam처럼 음악의 작은 조각을 듣는 대신 사용자에게 휘파람을 불어달라고 요청할 것입니다.
잠깐만요... 왜 전체 텍스트 검색이 필요한가요?
사용자가 노래의 일부분을 잘못 휘파람을 불 수도 있으므로 "멜로디의 작은 블록"으로 분할한 다음 라이브러리와 일치시켜야 합니다. 라이브러리에 수천 또는 수백만 곡의 노래가 있다고 가정하면(Apple과 Spotify 라이브러리에는 3천만 곡이 넘습니다), "%멜로디%"와 같은 단순한 좋아요로는 합리적인 시간 내에 결과를 얻을 수 없습니다.
반전 인덱스는 특정 멜로디 블록이 포함된 모든 노래를 쉽게 찾을 수 있기 때문에 이 작업에 적합한 도구인 것 같습니다. 아직 이 개념에 익숙하지 않다면 다음을 확인하세요. 이전 블로그 게시물 에 대해 알아보세요.
파슨스 코드
가장 먼저 해야 할 일은 노래 라이브러리를 텍스트로 변환하는 것입니다. 이를 위해 파슨스 코드의 움직임에 따라 음악을 식별하는 데 사용되는 표기법입니다. 피치 위아래로:
- * = 첫 번째 톤을 참조합니다,
- u = "위로", 음표가 이전 음표보다 높을 때 사용합니다,
- d = "아래로", 음표가 이전 음표보다 낮을 때 사용합니다,
- r = "반복", 음표가 이전 음표와 음정이 같을 때 사용합니다.
파슨스 코드를 사용하여 "반짝반짝 작은 별"는 다음과 같이 변환됩니다. *르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르.
노래 전문은 다음과 같습니다:
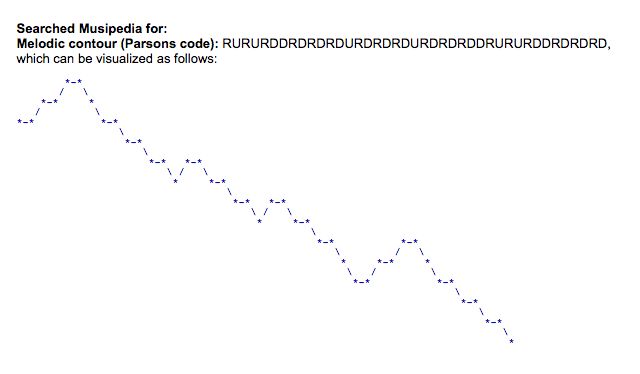
파슨스 코드를 사용한 시각화입니다:
분석기
반전 색인을 만들려면 먼저 텍스트를 더 작은 부분으로 나누고, 소문자로 변환하고, 관련 없는 단어를 제거하는 등 텍스트를 준비해야 합니다. 준비/분석 단계는 일반적으로 인덱스 생성 를 사용하여 쿼리가 실행되기 전에 변환합니다. 이렇게 하면 대상 텍스트와 일치하는 용어가 모두 정확히 동일한 변환을 거쳤음을 보장할 수 있습니다.
이러한 변환을 담당하는 코드를 분석기라고 하며, 분석기는 크게 토큰화기와 필터라는 두 가지 주요 카테고리로 분류합니다.
토큰화 도구
언어를 다룰 때 표준 토큰화 도구는 텍스트를 단어로 분할합니다. 프랑스어 l'amour나 영어의 'I'm'처럼 공백 이외의 문자도 고려해야 하므로 관용구에 따라 토큰화 전략이 약간 달라집니다.
카우치베이스 FTS에서는 표준 토큰라이저가 대부분의 경우 바로 작동하지만, 다음과 같은 토큰라이저도 제공합니다. HTML 및 기타 몇 가지 데이터 구조. 따라서 항상 가장 적합한 것을 사용하고 있는지 확인하는 것이 좋습니다.
이상적으로는 Shazam과 같은 앱에서 사용자 정의 n-그램 토큰화기를 만들어야 하지만, 간단하게 하기 위해 기본 토큰화기를 활용해 보겠습니다. 그러기 위해서는 5글자마다 공백을 삽입하여 파슨스 코드를 약간 변경해야 합니다. 그 이유는 사용자가 최소 5음 이상을 연속으로 정확하게 휘파람을 불 수 있다면 이를 '멜로디 블록'으로 간주하고 이를 역 인덱스와 일치시키려고 할 것이기 때문입니다.
따라서 "반짝반짝 작은 별"는 다음과 같이 저장됩니다. *르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르.
필터
카우치베이스 FTS는 다음과 함께 제공됩니다. 다양한 필터의 경우, 가장 인기있는 세 가지 항목은 잠재적으로 to_lower, stop_tokens및 스템머:
- to_lower: 모든 문자를 소문자로 변환합니다. 예를 들어 HTML은 html이 됩니다.
- stop_tokens: 전체 텍스트 검색에 불필요한 것으로 간주되는 토큰(예: 및, is, 및)을 스트림 토큰에서 제거합니다.
- 스템머: 용도 libstemmer를 사용하여 토큰을 단어 어간으로 줄일 수 있습니다. 예를 들어 다음과 같은 단어는 낚시, 낚시및 fisher 은 다음과 같이 축소됩니다. 물고기.
이상적으로는 동일한 데이터에 대해 여러 개의 인덱스가 있어야 하며, 각 인덱스는 특정 특성을 강조하는 데 초점을 맞춘 필터 구성을 사용해야 합니다. 이에 대해서는 다음 글에서 자세히 설명하겠습니다.
Shazam과 유사한 앱의 경우 필터가 필요하지 않을 수도 있지만 결과를 개선하려면 일종의 사용자 정의 필터를 추가할 수도 있습니다. stop_tokens 또는 사용자 지정 문자 필터.
예를 들어, 대부분의 팝송에서 가수는 몇 초 동안 "Ahhhhh" 또는 "Ohhhhh". 파슨스 코드를 사용하면 다음과 같이 번역됩니다. r ("반복", 음표가 이전 음표와 같은 피치인 경우). 따라서 stop_tokens/custom 문자 필터는 10 | 20" 시퀀스를 제거할 수 있습니다.r".
Ex: *르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르 가 *르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르르
이렇게 하면 반복되는 음의 시퀀스로 노래를 찾는 대신 핵심 멜로디로 노래를 식별하여 잘못된 결과를 반환할 가능성이 있습니다.
데이터 쿼리하기
이제 노래 라이브러리가 제대로 색인되었으므로 사용자의 휘파람을 녹음하고, 이를 파슨스 코드로 변환한 다음, 마지막으로 데이터베이스를 쿼리하기만 하면 됩니다. FTS는 데이터 색인에 사용한 것과 동일한 토큰화 도구와 분석기를 사용하여 쿼리 용어를 자동으로 변환합니다.
지금은 쿼리가 단순히 전체 일치 항목에 따라 정렬된 결과를 가져온다고 가정해 보겠습니다.
Ex:
다음과 같은 쿼리 rurur ddrdr 은 잠재적으로 "반짝반짝 작은 별" 노래가 4곡이 포함되어 있습니다:
*rururddrdrdrdurdrdrdrdurdrdrdrururddrdrdrd
데모는 어디에 있나요?
이 블로그 시리즈에서는 다른 유형의 애플리케이션을 구축할 예정이지만, 여기서 설명한 것과 유사한 것을 구현하는 실제 애플리케이션을 사용해보고 싶다면 다음을 확인하세요. 미데미.
결론
이 글의 목표는 다른 유형의 구조를 다룰 때도 토큰화기와 필터의 중요성을 보여드리는 것이었습니다. 각각의 사용 사례에 가장 적합한 것이 무엇인지 이해하려면 관련 공식 문서를 읽어보시길 적극 권장합니다.
이미 FTS에 대해 잘 알고 계신 분이라면 Shazam과 유사한 앱에서 몇 가지 잠재적인 문제를 발견하셨을 것입니다: 사용자가 보통 노래가 시작될 때부터 휘파람을 불지 않기 때문에, 원래 노래를 토큰화한 지점이 아닌 다른 지점에서 휘파람을 토큰화할 수 있습니다. 노래를 5음씩 토큰으로 그룹화하기 때문에 정확한 지점에서 음악과 용어 쿼리를 모두 토큰화할 확률은 5분의 1입니다.
Ex:
“반짝반짝 작은 별“: 루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루
토큰화 "반짝반짝 작은 별“: 루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루루르
사용자의 호루라기: rdrdrdurdurdrdurdrd (노래 중간에 나오는 임의의 부분)
토큰화된 사용자의 호루라기: rdrdr durdr drdur drd
위의 예에서는 2개의 매치(rdrdr 그리고 drdur)를 우연히 발견하면 이 곡의 점수가 심각하게 손상되어 예기치 않은 결과가 발생할 수 있습니다.
전체 텍스트 검색 시리즈
- LIKE %를 피해야 하는 이유 - 파트 2
- 퍼지 매칭 - 파트 3
이 시리즈의 다음 글에서 이 문제와 다른 몇 가지 문제를 해결하는 방법을 살펴보겠습니다. 그동안 궁금한 점이 있으면 다음 주소로 트윗해 주세요. @deniswsrosa