소개
Couchbase 전체 텍스트 검색(FTS)은 여러 배열을 색인하고 배열에 여러 필터 술어를 사용하여 쿼리를 실행하는 데 매우 적합합니다. 이 글에서는 여러 배열을 쿼리해야 하는 예제 사용 사례를 살펴보면서 배열 인덱싱에 GSI(글로벌 보조 인덱스)보다 FTS를 사용할 때의 이점을 보여드리겠습니다. FTS 다중 배열 인덱스를 생성하고 Couchbase Server 6.5에 도입된 새로운 SEARCH() 함수를 사용하여 N1QL로 인덱스를 쿼리할 것입니다.
여행 샘플 버킷
이 문서에서는 다음과 같이 참조할 것입니다. 설치 가능한 여행 샘플 데이터 세트 를 추가할 수 있습니다. 여행 샘플 버킷에는 항공사, 노선, 공항, 랜드마크, 호텔 등 여러 가지 문서 유형이 있습니다. 각 문서 유형에 대한 문서 모델에는 다음이 포함됩니다:
- 기본 키 역할을 하는 키
- 문서를 식별하는 ID 필드
- 문서의 종류를 식별하는 유형 필드입니다.
이 글의 예제에서는 호텔 문서를 사용합니다. 아래 샘플 문서를 통해 호텔 문서의 구조에 대한 아이디어를 얻을 수 있습니다:

그림 1 - 호텔 문서 샘플
문제
이 예는 사용자가 특정 이름을 가진 사람이 리뷰를 남기거나 좋아요를 누른 호텔을 검색하는 사용 사례입니다. 이를 위해서는 호텔 문서 모델 내의 배열인 공개 좋아요와 리뷰 모두에 대해 호텔 문서를 쿼리해야 합니다:

그림 2 - 샘플 호텔 문서의 "public_likes" 및 "reviews" 배열
먼저 이 사용 사례를 N1QL과 GSI(글로벌 보조 인덱스)로 구현하는 방법을 살펴봅시다. Ozella라는 이름의 사용자가 좋아요를 누르거나 리뷰를 남긴 호텔을 찾으려면 쿼리는 다음과 같이 작성할 수 있습니다:
|
1 2 3 4 5 6 |
SELECT name, address, city, country, phone, public_likes, reviews FROM `travel-sample` WHERE type="hotel" AND (ANY l IN public_likes SATISFIES l LIKE "%Ozella%" END OR ANY r IN reviews SATISFIES r.author LIKE "%Ozella%" END); |
이 쿼리에 적합한 인덱스를 만들어야 합니다. 호텔 문서에 대한 관심 배열을 모두 색인하는 이와 같은 색인을 만들 수 있습니다:
|
1 2 3 4 |
CREATE INDEX idx_hotel_public_likes_review_author ON `travel-sample` (DISTINCT ARRAY `l` FOR l IN `public_likes` END, DISTINCT ARRAY `r`.`author` FOR r IN `reviews` END) WHERE `type` = 'hotel'; |
이 방법은 작동하지 않으며 그림 3에 표시된 오류가 발생합니다:
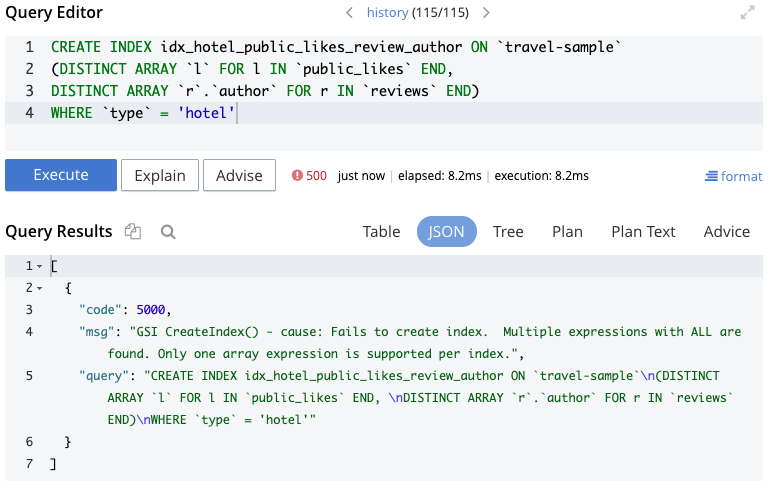 그림 3 - 다중 배열을 사용한 인덱스 생성 오류
그림 3 - 다중 배열을 사용한 인덱스 생성 오류
케샤브 머시는 블로그 게시물에서 다음과 같이 썼습니다. 검색 및 구조 N1QL(SQL) 개발자가 Search를 사용해야 하는 7가지 이유 (문제 #6), 카우치베이스에서 N1QL 사용, "배열 내부를 검색하는 동안 최상의 성능을 얻으려면 다음을 수행해야 합니다. 배열 키로 인덱스 생성. 배열 인덱스에는 각 배열 인덱스당 하나의 배열 키만 가질 수 있다는 제한이 있습니다. 따라서 여러 배열 필드가 있는 고객 개체가 있는 경우 단일 인덱스를 사용하여 모든 필드를 검색할 수 없으므로 쿼리 비용이 많이 듭니다." Keshav가 이 글에서 언급했듯이, 이는 일반적으로 데이터베이스의 b-tree 인덱스가 갖는 한계입니다.
이제 두 개의 개별 배열 인덱스를 사용해 보겠습니다. 이 쿼리를 지원하는 인덱스는 다음과 같이 보일 수 있습니다. Couchbase N1QL 인덱스 어드바이저Couchbase 6.5의 새로운 (DP) 기능입니다:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX adv_DISTINCT_public_likes_type ON `travel-sample`(DISTINCT ARRAY `l` FOR l in `public_likes` END) WHERE `type` = 'hotel'; CREATE INDEX adv_DISTINCT_reviews_author_type ON `travel-sample`(DISTINCT ARRAY `r`.`author` FOR r in `reviews` END) WHERE `type` = 'hotel'; |
이 두 인덱스를 사용하면 쿼리는 5개의 결과(hotel_26020, hotel_10025, hotel_5081, hotel_20425, hotel_25327)와 다음 실행 계획으로 성공적으로 실행됩니다:

그림 4 - 다중 인덱스(GSI)를 사용한 실행 계획
JSON에서도 마찬가지입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 |
{ "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "1.321µs" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "3.034µs", "servTime": "1.037859ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "2.235µs" }, "~children": [ { "#operator": "UnionScan", "#stats": { "#itemsIn": 1646, "#itemsOut": 904, "#phaseSwitches": 5107, "execTime": "1.32474ms", "kernTime": "113.495553ms" }, "scans": [ { "#operator": "DistinctScan", "#stats": { "#itemsIn": 4004, "#itemsOut": 813, "#phaseSwitches": 9641, "execTime": "1.381997ms", "kernTime": "69.065425ms" }, "scan": { "#operator": "IndexScan3", "#stats": { "#itemsOut": 4004, "#phaseSwitches": 16021, "execTime": "19.678094ms", "kernTime": "30.973177ms", "servTime": "17.461885ms" }, "index": "adv_DISTINCT_public_likes_type", "index_id": "288083a758973630", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "range": [ { "high": "[]", "inclusion": 1, "low": "\"\"" } ] } ], "using": "gsi", "#time_normal": "00:00.037", "#time_absolute": 0.037139979000000004 }, "#time_normal": "00:00.001", "#time_absolute": 0.0013819969999999998 }, { "#operator": "DistinctScan", "#stats": { "#itemsIn": 4104, "#itemsOut": 833, "#phaseSwitches": 9881, "execTime": "2.475034ms", "kernTime": "80.914158ms" }, "scan": { "#operator": "IndexScan3", "#stats": { "#itemsOut": 4104, "#phaseSwitches": 16421, "execTime": "8.610445ms", "kernTime": "52.02497ms", "servTime": "22.586149ms" }, "index": "adv_DISTINCT_reviews_author_type", "index_id": "cca7f912cab1a4c6", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "range": [ { "high": "[]", "inclusion": 1, "low": "\"\"" } ] } ], "using": "gsi", "#time_normal": "00:00.031", "#time_absolute": 0.031196594 }, "#time_normal": "00:00.002", "#time_absolute": 0.002475034 } ], "#time_normal": "00:00.001", "#time_absolute": 0.00132474 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 904, "#itemsOut": 904, "#phaseSwitches": 3733, "execTime": "2.887995ms", "kernTime": "8.826606ms", "servTime": "170.010321ms" }, "keyspace": "travel-sample", "namespace": "default", "#time_normal": "00:00.172", "#time_absolute": 0.172898316 }, { "#operator": "Parallel", "#stats": { "#phaseSwitches": 1, "execTime": "6.134µs" }, "copies": 2, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "3.621µs" }, "~children": [ { "#operator": "Filter", "#stats": { "#itemsIn": 904, "#itemsOut": 5, "#phaseSwitches": 1824, "execTime": "279.461548ms", "kernTime": "85.245883ms" }, "condition": "(((`travel-sample`.`type`) = \"hotel\") and (any `l` in (`travel-sample`.`public_likes`) satisfies (`l` like \"%Ozella%\") end or any `r` in (`travel-sample`.`reviews`) satisfies ((`r`.`author`) like \"%Ozella%\") end))", "#time_normal": "00:00.279", "#time_absolute": 0.279461548 }, { "#operator": "InitialProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "7.156613ms", "kernTime": "357.453351ms" }, "result_terms": [ { "expr": "(`travel-sample`.`name`)" }, { "expr": "(`travel-sample`.`address`)" }, { "expr": "(`travel-sample`.`city`)" }, { "expr": "(`travel-sample`.`country`)" }, { "expr": "(`travel-sample`.`phone`)" }, { "expr": "(`travel-sample`.`public_likes`)" }, { "expr": "(`travel-sample`.`reviews`)" } ], "#time_normal": "00:00.007", "#time_absolute": 0.007156613 }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "12.167µs", "kernTime": "98.849µs" }, "#time_normal": "00:00.000", "#time_absolute": 0.000012167 } ], "#time_normal": "00:00.000", "#time_absolute": 0.000003621 }, "#time_normal": "00:00.000", "#time_absolute": 0.000006134 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0000022349999999999998 }, "#time_normal": "00:00.001", "#time_absolute": 0.0010408930000000002 }, { "#operator": "Stream", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "939.145µs", "kernTime": "182.523171ms" }, "#time_normal": "00:00.000", "#time_absolute": 0.000939145 } ], "~versions": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#time_normal": "00:00.000", "#time_absolute": 0.000001321 } |
이 예제에 사용되는 단일 노드 클러스터에서는 5개의 결과 문서를 반환하는 데 약 190-200밀리초의 쿼리 경과 시간이 소요됩니다. 계획에서 볼 수 있듯이, 우리가 만든 두 개의 배열 인덱스 각각을 사용하는 두 개의 IndexScan3 연산자가 있고, 각 인덱스 스캔 결과에 대한 DistinctScan이 있으며, 그 다음에는 UnionScan이 있습니다. UnionScan은 1646개의 문서에 대한 #itemsIn 값과 904개의 문서에 대한 #itemsOut 값을 보여주고, Fetch 연산자도 904개의 문서를 가져오며, 마지막으로 Filter 연산자를 사용하면 #ItemsOut 값 5를 얻습니다. 쿼리에서 반환된 문서가 5개라는 점을 고려하면 904개의 문서를 가져오는 것은 낭비이며, 실제로 5개만 필요한데 905개의 문서를 가져오는 데 전체 경과 시간 중 약 170밀리초가 소요됩니다.
솔루션
반면, FTS 반전 인덱스는 여러 배열에 대해 쉽게 생성할 수 있으며 여러 배열의 필드를 검색해야 하는 경우에 적합합니다. 호텔 문서에서 public_likes 배열과 reviews 배열 내의 작성자 필드 모두에 대한 FTS 인덱스를 만들어 보겠습니다.
인덱스 생성 단계:
- 전체 텍스트 검색 UI에서 '색인 추가'를 클릭합니다.
- 인덱스 이름(예: "hotel_mult_arrays")을 지정하고 여행 샘플 버킷을 선택합니다.
- 여행 샘플 버킷의 각 문서에는 문서의 유형을 나타내는 "type" 필드가 있으므로 "JSON 유형 필드"를 "type"으로 설정해 두세요.
- 유형 매핑 아래에서:
- 모든 호텔 문서를 검색해야 하므로 "+ 유형 매핑 추가"를 클릭하고 유형 이름으로 "호텔"을 지정합니다.
- 사용 가능한 분석기 목록은 유형 이름 필드 오른쪽에 있는 풀다운 메뉴를 통해 액세스할 수 있습니다. 이 사용 사례의 경우, 유형 매핑이 인덱스에서 기본 분석기를 상속하도록 '상속'을 선택한 상태로 둡니다.
- 호텔 공개 좋아요를 검색하고 작성자 필드를 검토해야 하므로 '지정된 필드만 색인화'를 선택합니다. 이 옵션을 선택하면 문서에서 사용자가 지정한 필드만 호텔 유형 매핑의 색인에 포함됩니다(매핑은 동적이 아니므로 모든 필드를 색인화할 수 있는 것으로 간주됩니다).
- 확인을 클릭합니다.
- 호텔 유형 매핑이 있는 행에 마우스를 올려놓고 + 버튼을 클릭한 다음 "하위 필드 삽입". 이렇게 하면 public_likes 배열이 인덱스에 개별적으로 포함될 수 있습니다. 다음을 지정합니다:
- 필드를 클릭합니다: 색인할 필드의 이름인 'public_likes'를 입력합니다.
- 유형으로 설정합니다: public_likes 배열의 텍스트로 설정합니다.
- 로 검색할 수 있습니다: 현재 사용 사례의 필드 이름과 동일하게 유지합니다. 대체 필드 이름을 나타내는 데 사용할 수 있습니다.
- 분석기를 사용합니다: 유형 매핑에서 수행한 것과 같습니다, 이 사용 사례의 경우 "상속"을 선택한 상태로 두십시오. 유형 매핑이 기본 분석기를 상속하도록 설정합니다.
- 색인 확인란을 선택합니다: 이 확인란을 선택해 두면 필드가 색인에 포함됩니다. 이 확인란을 선택 취소하면 색인에서 필드가 명시적으로 제거됩니다.
- 저장 확인란을 선택합니다: 이 설정을 선택하면 검색 결과에 필드 콘텐츠가 포함되어 결과에서 일치하는 표현식을 강조 표시할 수 있습니다. 인덱스를 테스트하는 데 유용하지만 인덱스 크기가 증가하므로 강조 표시가 필요하지 않은 경우 Prod에서는 권장되지 않습니다.
- "_모든 필드에 포함" 확인란을 선택합니다: 사용 사례 요구 사항이 여러 필드를 검색하는 것이므로 이 확인란을 선택된 상태로 둡니다.
- "용어 벡터 포함" 체크박스를 선택합니다: 인덱스 개발 및 테스트 중에 결과를 강조 표시할 수 있도록 이 옵션도 선택된 상태로 둡니다.
- 문서 값 확인란을 선택합니다: 이 설정을 선택 취소합니다. 이 설정은 필드 값을 인덱스에 저장하여 검색 패싯과 필드 값에 따른 검색 결과 정렬을 지원하지만 이 사용 사례에서는 둘 다 필요하지 않습니다.
- 확인을 클릭합니다.
- 호텔 유형 매핑이 있는 행에 마우스를 올려놓고 + 버튼을 클릭한 다음 "자식 매핑 삽입". 이렇게 하면 리뷰 하위 문서 배열이 색인에 포함될 수 있습니다. 속성 이름 "reviews"를 입력하고, 분석기 드롭다운에서 "상속"을 선택한 상태로 두고, "지정된 필드만 색인"을 선택한 다음 확인을 클릭합니다.
- 리뷰 하위 매핑이 있는 행에 마우스를 올려놓고 + 버튼을 클릭한 다음 "하위 필드 삽입". 이렇게 하면 검토 하위 문서 배열의 작성자 필드가 색인에 포함될 수 있습니다. 다음을 지정합니다:
- 필드를 클릭합니다: 색인할 필드의 이름인 '작성자'를 입력합니다.
- 유형으로 설정합니다: 작성자 필드의 텍스트로 이 설정을 그대로 둡니다.
- 로 검색할 수 있습니다: 현재 사용 사례의 필드 이름과 동일하게 유지합니다. 대체 필드 이름을 나타내는 데 사용할 수 있습니다.
- 분석기를 사용합니다: 유형 매핑에서 수행한 것과 같습니다, 이 사용 사례의 경우 "상속"을 선택한 상태로 두십시오. 유형 매핑이 기본 분석기를 상속하도록 설정합니다.
- 색인 확인란을 선택합니다: 이 확인란을 선택해 두면 필드가 색인에 포함됩니다. 이 확인란을 선택 취소하면 색인에서 필드가 명시적으로 제거됩니다.
- 저장 확인란을 선택합니다: 이 설정을 선택하면 검색 결과에 필드 콘텐츠가 포함되어 결과에서 일치하는 표현식을 강조 표시할 수 있습니다. 인덱스를 테스트하는 데 유용하지만 인덱스 크기가 증가하므로 강조 표시가 필요하지 않은 경우 Prod에서는 권장되지 않습니다.
- "_모든 필드에 포함" 확인란을 선택합니다: 사용 사례 요구 사항이 여러 필드를 검색하는 것이므로 이 확인란을 선택된 상태로 둡니다.
- "용어 벡터 포함" 체크박스를 선택합니다: 인덱스 개발 및 테스트 중에 결과를 강조 표시할 수 있도록 이 옵션도 선택된 상태로 둡니다.
- 문서 값 확인란을 선택합니다: 이 설정을 선택 취소합니다. 이 설정은 필드 값을 인덱스에 저장하여 검색 패싯과 필드 값에 따른 검색 결과 정렬을 지원하지만 이 사용 사례에서는 둘 다 필요하지 않습니다.
- 확인을 클릭합니다.
- 마지막으로 '기본' 유형 매핑 옆의 확인란을 선택 취소합니다. 기본 매핑을 활성화된 상태로 두면 사용자가 적극적으로 유형 매핑을 지정했는지 여부에 관계없이 버킷의 모든 문서가 색인에 포함됩니다. 호텔 문서만 필요하며 이전에 추가한 호텔 유형 매핑에 의해 포함됩니다.
- 나머지 접힌 패널(분석기, 사용자 지정 필터, 날짜/시간 파서 및 고급)은 기본값으로 충분합니다.
- 인덱스 복제본은 클러스터가 n+1 노드에서 검색 서비스를 실행하는 경우 1, 2 또는 3으로 설정할 수 있습니다. 단일 노드 개발 환경에서는 기본값인 0을 유지합니다.
- 인덱스 유형의 경우, 새로 생성되는 모든 인덱스에는 기본값인 "버전 6.0(Scorch)"이 적합합니다. Scorch는 디스크의 인덱스 크기를 줄이고 인덱싱 및 변경 처리를 위한 연산자 성능에서 향상된 MongoDB를 제공합니다.
- 인덱스 파티션은 기본값인 6으로 그대로 둘 수 있습니다.
- 이 시점에서 인덱스 생성 페이지는 다음과 같이 표시되어야 합니다. 에서 캡처한 마지막 프레임 그림 5. "색인 생성"을 클릭하여 프로세스를 완료합니다.
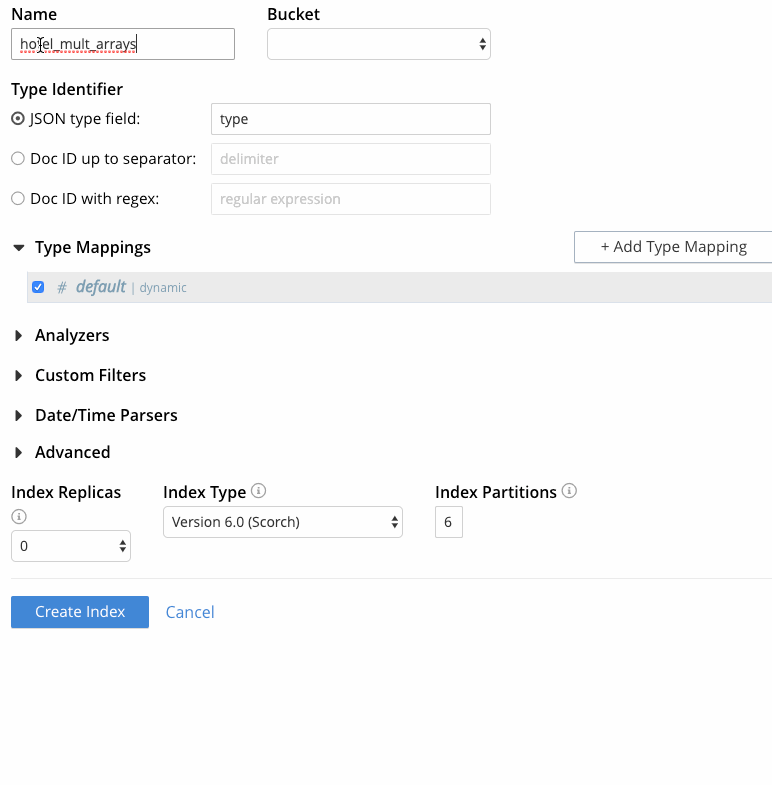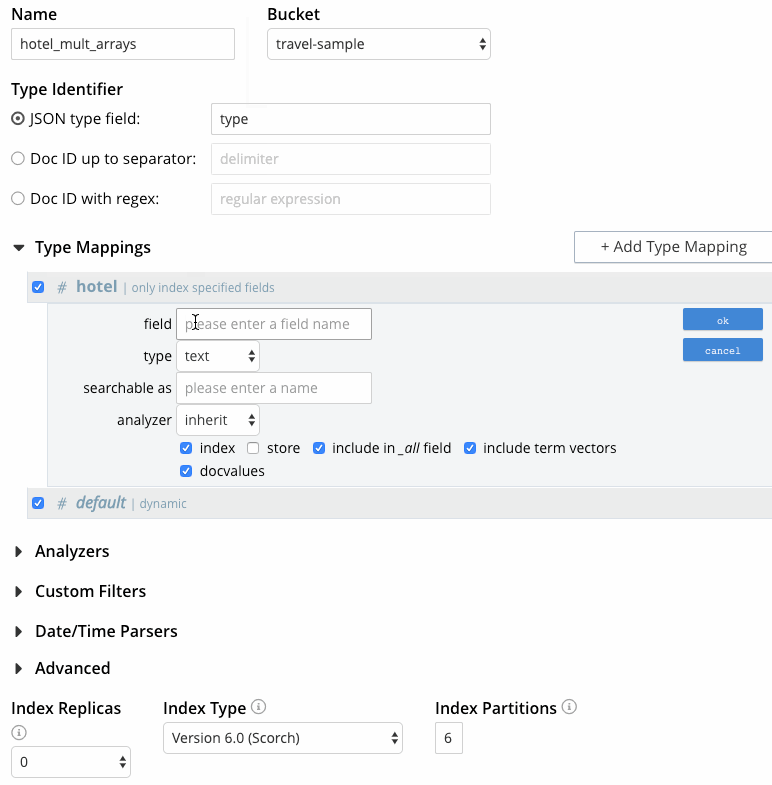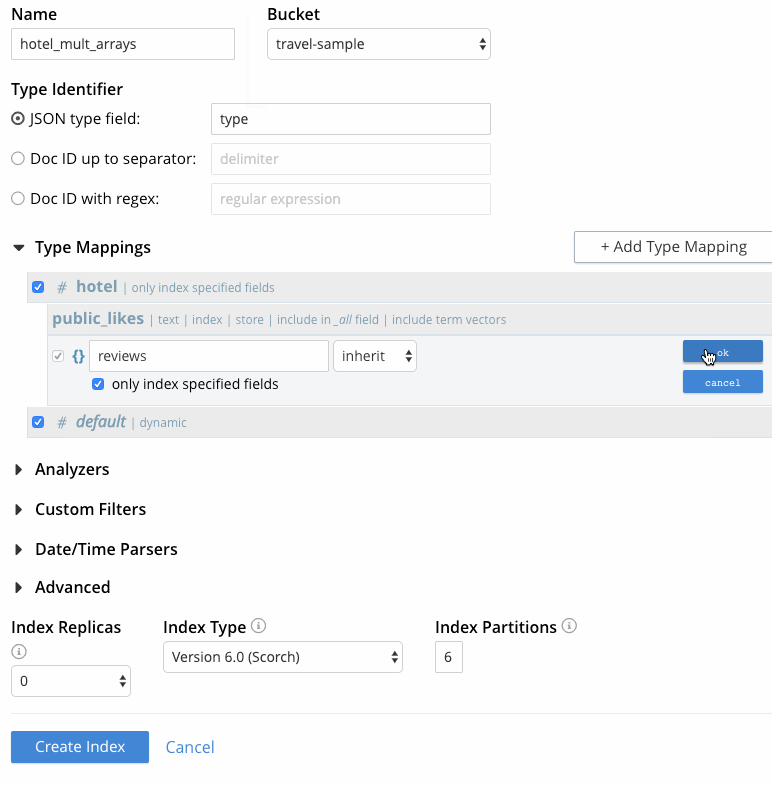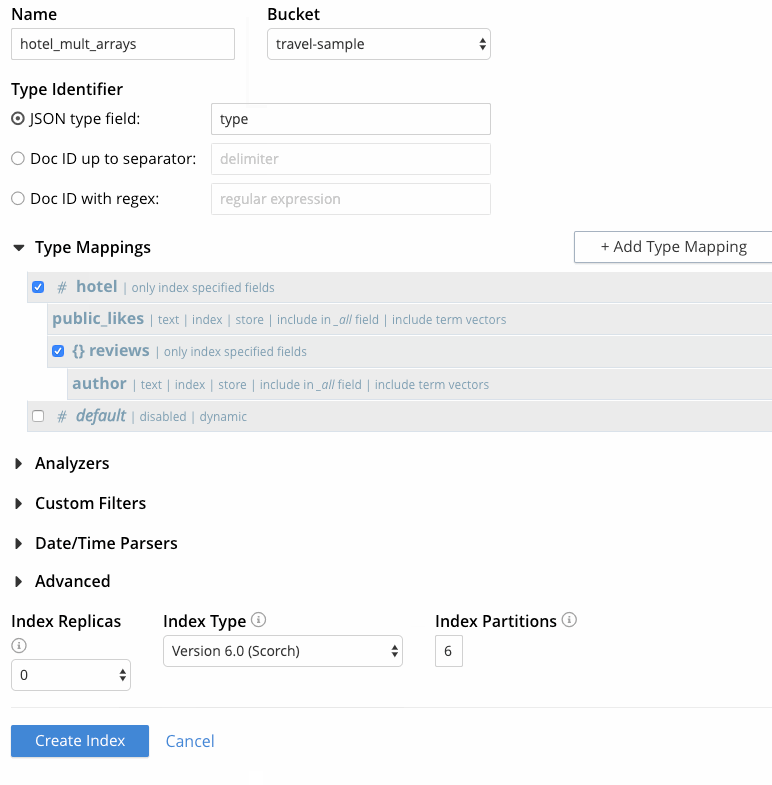
그림 5 - 다중 배열로 FTS 인덱스 만들기
참고: REST API를 통해 이 인덱스를 생성하는 데 사용되는 JSON 페이로드는 부록을 참조하세요.
인덱스에 대해 쿼리를 테스트합니다:
- 전체 텍스트 검색 UI에서 인덱싱 진행률이 100%로 표시될 때까지 기다린 다음, 인덱스 이름 "hotel_mult_arrays"를 클릭합니다.
- 'Ozella'라는 사용자의 좋아요 또는 후기가 있는 호텔을 검색하려면 '이 색인 검색...' 텍스트 상자에 'Ozella'를 입력한 후 검색을 클릭합니다. 색인된 두 필드가 모두 기본 필드 "_all".
- 결과는 (그림 6과 유사하게) 일치하는 각 문서의 키와 강조 표시된 일치 필드와 함께 표시됩니다. 반환된 문서 ID는 이전 N1QL 쿼리에서 반환된 것과 동일합니다.
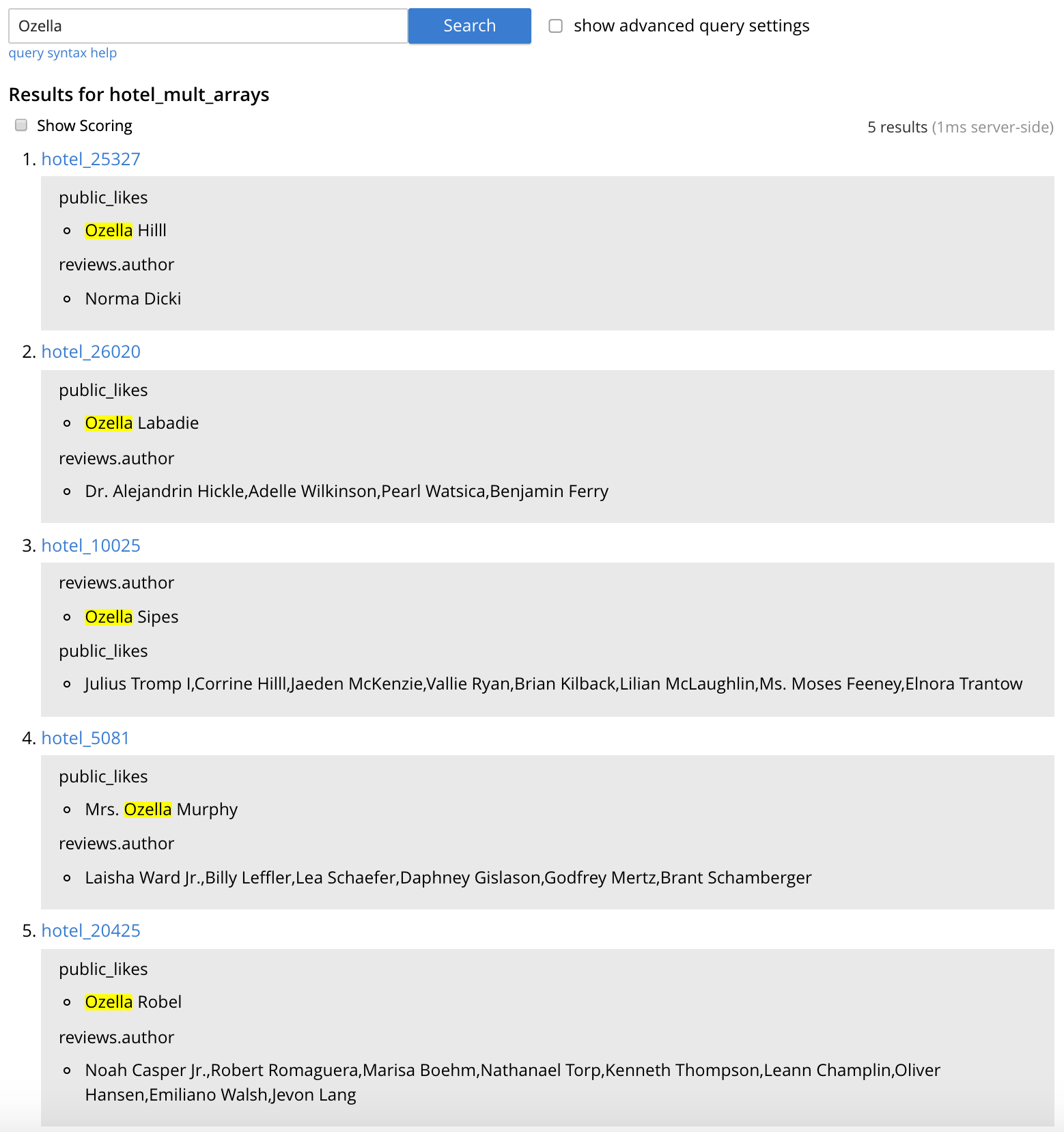
그림 6 - "Ozella"에 대한 "hotel_mult_arrays" 검색 결과 색인화
이것은 2개의 배열 키에 대한 단일 인덱스이며, 앞서 언급했듯이 b-트리 기반 인덱스에서는 절대 할 수 없는 작업입니다. 이제 SEARCH() 함수를 사용하여 N1QL 쿼리에서 이 FTS 인덱스를 활용해 보겠습니다. 쿼리는 다음과 같이 보일 수 있습니다:
|
1 2 3 4 5 |
SELECT name, address, city, country, phone, public_likes, reviews FROM `travel-sample` AS t USE INDEX(hotel_mult_arrays USING FTS) WHERE t.type="hotel" AND SEARCH(t, {"query": {"match":"Ozella"}}, {"index":"hotel_mult_arrays"}); |
쿼리에 대해 몇 가지 주의해야 할 사항이 있습니다:
- USE INDEX...USING FTS 절은 GSI 인덱스가 아닌 FTS 인덱스를 사용하도록 지정하므로 이 쿼리는 인덱스 서비스를 사용하지 않습니다. (문서)
- FTS 인덱스는 사용자 지정 유형 매핑을 사용하므로 쿼리에는 WHERE 절에 일치하는 유형이 지정되어 있어야 합니다(t.type="hotel").
- FTS 인덱스 이름은 SEARCH() 함수의 "index" 필드에 힌트로 지정되지만 USE INDEX 절이 "index" 필드에 제공된 힌트보다 우선하므로 이는 선택 사항입니다. (문서)
생성한 FTS 인덱스를 사용하여 N1QL 쿼리가 성공적으로 실행되고 5개의 결과(hotel_5081, hotel_26020, hotel_10025, hotel_20425, hotel_25327)와 다음 실행 계획을 반환합니다:

그림 7 - 다중 인덱스(FTS)를 사용한 실행 계획
JSON에서도 마찬가지입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
{ "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "18.8µs" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "32.1µs", "servTime": "3.421ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "122.8µs" }, "~children": [ { "#operator": "IndexFtsSearch", "#stats": { "#itemsOut": 5, "#phaseSwitches": 23, "execTime": "239.3µs", "kernTime": "84.5µs", "servTime": "3.9146ms" }, "as": "t", "index": "hotel_mult_arrays", "index_id": "7a28a8346fad6118", "keyspace": "travel-sample", "namespace": "default", "search_info": { "field": "\"\"", "options": "{\"index\": \"hotel_mult_arrays\"}", "outname": "out", "query": "{\"query\": {\"match\": \"Ozella\"}}" }, "using": "fts", "#time_normal": "00:00.004", "#time_absolute": 0.0041539 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "334.8µs", "kernTime": "4.4328ms", "servTime": "1.5272ms" }, "as": "t", "keyspace": "travel-sample", "namespace": "default", "#time_normal": "00:00.001", "#time_absolute": 0.001862 }, { "#operator": "Parallel", "#stats": { "#phaseSwitches": 1, "execTime": "21.1µs" }, "copies": 2, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "49.1µs" }, "~children": [ { "#operator": "Filter", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 26, "execTime": "6.8953ms", "kernTime": "14.8149ms" }, "condition": "(((`t`.`type`) = \"hotel\") and search(`t`, {\"query\": {\"match\": \"Ozella\"}}, {\"index\": \"hotel_mult_arrays\"}))", "#time_normal": "00:00.006", "#time_absolute": 0.0068953 }, { "#operator": "InitialProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "2.3597ms", "kernTime": "20.7458ms" }, "result_terms": [ { "expr": "(`t`.`name`)" }, { "expr": "(`t`.`address`)" }, { "expr": "(`t`.`city`)" }, { "expr": "(`t`.`country`)" }, { "expr": "(`t`.`phone`)" }, { "expr": "(`t`.`public_likes`)" }, { "expr": "(`t`.`reviews`)" } ], "#time_normal": "00:00.002", "#time_absolute": 0.0023597 }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "300µs", "kernTime": "375.9µs" }, "#time_normal": "00:00", "#time_absolute": 0 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0000491 }, "#time_normal": "00:00.000", "#time_absolute": 0.0000211 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0001228 }, "#time_normal": "00:00.003", "#time_absolute": 0.0034531 }, { "#operator": "Stream", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "1.3409ms", "kernTime": "14.8586ms" }, "#time_normal": "00:00.001", "#time_absolute": 0.0013409 } ], "~versions": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#time_normal": "00:00.000", "#time_absolute": 0.0000188 } |
이 예제에 사용되는 단일 노드 클러스터에서는 동일한 5개의 문서를 반환하는 데 쿼리 경과 시간이 약 20밀리초입니다. 계획에서 볼 수 있듯이 IndexFtsSearch 연산자는 있지만 IndexScan3, DistinctScan, UnionScan 또는 IntersectScan 연산자는 없습니다. 이러한 고가의 GSI 연산자가 없으면 전체 쿼리가 훨씬 더 효율적입니다. IndexFtsSearch 연산자는 FTS 인덱스에서 일치하는 문서 5개를 Fetch 연산자에게 보내면 이 5개의 문서만 가져옵니다. 여기서는 5개의 문서와 904개의 문서만 가져오기 때문에 이전 쿼리보다 훨씬 효율적이며, 이는 전체 경과 시간(및 가져오기 연산자의 servTime)을 비교해도 확인할 수 있습니다: 쿼리 1에서 170ms, 쿼리 2에서 1.5ms) 비교에서도 확인할 수 있습니다.
결론
GSI에서는 단일 쿼리에서 여러 배열 인덱스를 혼합하여 일치시킬 수 있지만, FTS에서는 단일 FTS 인덱스에서 여러 배열을 혼합하여 일치시킬 수 있습니다(그리고 FTS에서는 인덱스의 필드 순서와 관련하여 GSI에서처럼 선행 키 문제가 없습니다). 호텔 문서에서 2개의 배열을 쿼리하는 이 간단한 예제에서 보았듯이, N1QL의 새로운 SEARCH() 함수를 사용하면 더 간단하고 성능이 뛰어난 배열 쿼리를 수행할 수 있습니다. 여러 개의 배열을 사용하는 쿼리에도 동일한 개념을 적용할 수 있으며, 이 경우 여러 GSI 배열 인덱스를 사용하는 N1QL 쿼리에 비해 훨씬 더 유리한 결과를 얻을 수 있습니다. 이 접근 방식은 더 적은 시스템 리소스를 사용하고 더 높은 처리량을 제공하므로 전반적인 시스템 효율성이 향상됩니다.
이는 N1QL과 FTS 통합의 장점 중 한 가지 예일 뿐이며, 다른 장점은 아래 참고 섹션의 블로그 게시물에 자세히 설명되어 있습니다.
참조
- 카우치베이스 검색 리소스: https://www.couchbase.com/products/full-text-search
- 카우치베이스 FTS 문서: https://docs.couchbase.com/server/current/fts/full-text-intro.html
- 카우치베이스 N1QL 검색 문서: https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
- 카우치베이스 FTS 블로그 게시물: https://www.couchbase.com/blog/category/full-text-search/
- 카우치베이스 FTS 온라인 교육: https://learn.couchbase.com/store/509465-cb121-intro-to-couchbase-full-text-search-fts
부록
인덱스 정의 JSON: hotel_mult_arrays
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
{ "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "18.8µs" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "32.1µs", "servTime": "3.421ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "122.8µs" }, "~children": [ { "#operator": "IndexFtsSearch", "#stats": { "#itemsOut": 5, "#phaseSwitches": 23, "execTime": "239.3µs", "kernTime": "84.5µs", "servTime": "3.9146ms" }, "as": "t", "index": "hotel_mult_arrays", "index_id": "7a28a8346fad6118", "keyspace": "travel-sample", "namespace": "default", "search_info": { "field": "\"\"", "options": "{\"index\": \"hotel_mult_arrays\"}", "outname": "out", "query": "{\"query\": {\"match\": \"Ozella\"}}" }, "using": "fts", "#time_normal": "00:00.004", "#time_absolute": 0.0041539 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "334.8µs", "kernTime": "4.4328ms", "servTime": "1.5272ms" }, "as": "t", "keyspace": "travel-sample", "namespace": "default", "#time_normal": "00:00.001", "#time_absolute": 0.001862 }, { "#operator": "Parallel", "#stats": { "#phaseSwitches": 1, "execTime": "21.1µs" }, "copies": 2, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "49.1µs" }, "~children": [ { "#operator": "Filter", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 26, "execTime": "6.8953ms", "kernTime": "14.8149ms" }, "condition": "(((`t`.`type`) = \"hotel\") and search(`t`, {\"query\": {\"match\": \"Ozella\"}}, {\"index\": \"hotel_mult_arrays\"}))", "#time_normal": "00:00.006", "#time_absolute": 0.0068953 }, { "#operator": "InitialProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "2.3597ms", "kernTime": "20.7458ms" }, "result_terms": [ { "expr": "(`t`.`name`)" }, { "expr": "(`t`.`address`)" }, { "expr": "(`t`.`city`)" }, { "expr": "(`t`.`country`)" }, { "expr": "(`t`.`phone`)" }, { "expr": "(`t`.`public_likes`)" }, { "expr": "(`t`.`reviews`)" } ], "#time_normal": "00:00.002", "#time_absolute": 0.0023597 }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "300µs", "kernTime": "375.9µs" }, "#time_normal": "00:00", "#time_absolute": 0 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0000491 }, "#time_normal": "00:00.000", "#time_absolute": 0.0000211 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0001228 }, "#time_normal": "00:00.003", "#time_absolute": 0.0034531 }, { "#operator": "Stream", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "1.3409ms", "kernTime": "14.8586ms" }, "#time_normal": "00:00.001", "#time_absolute": 0.0013409 } ], "~versions": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#time_normal": "00:00.000", "#time_absolute": 0.0000188 } |