이 문서에서는 데이터 구조와 이 구조가 Couchbase Server 7.0 범위 및 컬렉션 기능과 함께 작동하는 방식을 소개합니다.
데이터 구조란 무엇인가요?
카우치베이스 데이터 구조는 데이터베이스 인터페이스의 언어를 프로그래밍 언어에 맞춰 조정하는 API 기능입니다.
데이터 구조는 NoSQL 시스템 개발자를 위해 데이터 모델을 단순화하는 데 도움이 됩니다. 데이터 구조는 데이터를 빠르고 효율적으로 저장하고 검색하기 위한 기본적인 데이터 관리 단위입니다. 문서 데이터베이스 및 기타 키-값 데이터베이스는 쿼리 사용 사례를 위해 이 데이터의 인덱싱을 지원하는 경우가 많습니다.
NoSQL 애플리케이션 개발 간소화
전체 JSON 문서와의 상호 작용은 필요하지 않습니다. 예를 들어 소프트웨어 개발자에게 필요한 것은 목록의 단일 항목뿐인 경우입니다. 데이터베이스 연결을 인증한 후 간단한 가져오기 또는 설정 함수만 있으면 됩니다.
다양한 데이터 구조 함수를 통해 이러한 네이티브 프로그래밍 객체에 액세스할 수 있습니다:
- 문서 - 전체 JSON 계층형 문서 지원
- 하위 문서 - 문서 내 객체의 하위 집합
- 카운터 - 증분하는 단일 정수
- 맵 - 키-값 사전 매핑
- 목록/컬렉션 - 항목의 색인화 및 정렬된 목록
- 세트 - 목록 항목의 고유한 값 세트
- 대기열 - 목록 항목에 대한 선입선출 액세스
직접 데이터 액세스 방법
카우치베이스는 간단한 함수를 통해 원자 단위의 데이터로 노출할 수 있는 유연한 JSON 문서로 데이터를 관리합니다. 예를 들어 다음과 같이 할 수 있습니다.문서의 하위 구성 요소를 에칭합니다, 목록에 번호가 매겨진 항목을 만들거나 값을 정렬된 목록에 추가합니다. 데이터 문서가 지속되고 클러스터에 배포된 후에는 해당 ID 이름을 직접 호출할 수 있습니다.
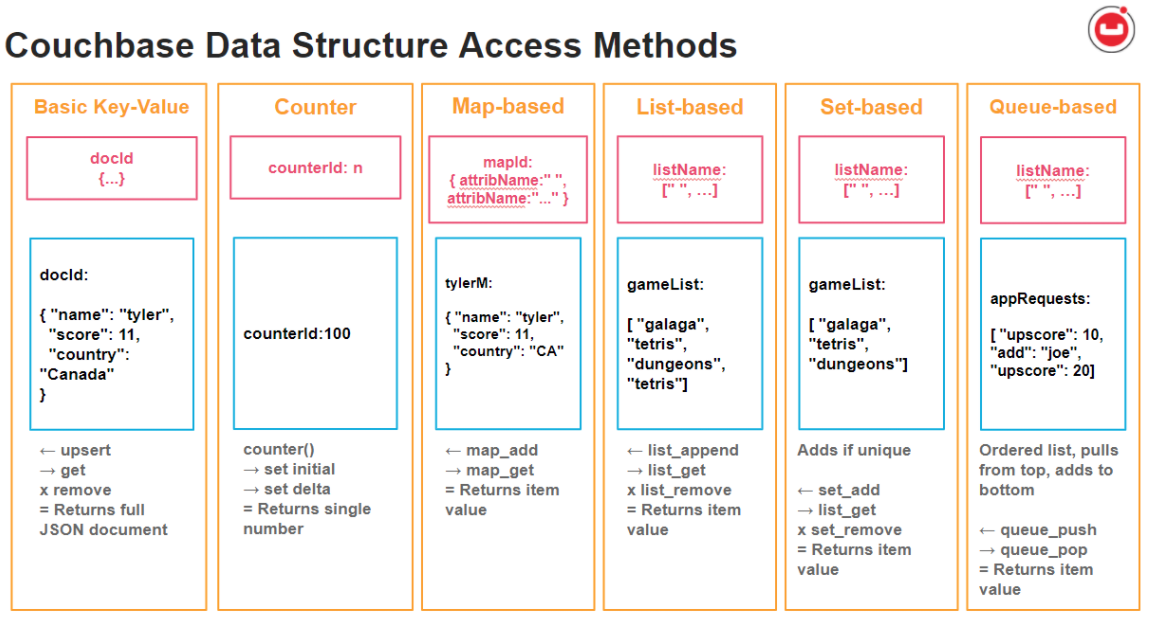
카우치베이스 데이터 구조 유형 및 JSON 샘플 요약.
Python 예제는 이러한 데이터 구조 유형의 기본 사용법을 보여주기 위해 사용되었지만 모든 SDK 언어가 지원됩니다. 서문 코드, 임포트 등은 이 글 끝에 있는 전체 코드 예제를 참조하세요.
키-값 액세스
일반 KV 운영 포함 get 그리고 set/업서트 함수를 사용할 수 있습니다. JSON 호환 문서는 특정 문서 ID로 저장되거나 업데이트됩니다.
|
1 2 3 |
>>> db.upsert("docId", { "name": "tyler", "score": 11, "country": "CA" }) >>> sb.get("docId").content '{ "name": "tyler", "score": 11, "country": "CA"}' |
카운터
더 간단한 방법은 명명된 카운터 객체 를 저장하는 단일 정수 값입니다. 항목이 호출되면 초기 값이 정의된 다음 증분됩니다. 이 간단한 방법은 애플리케이션 전반에서 전역적으로 숫자를 증가시키는 데 적합합니다.
|
1 2 3 4 5 |
>>> db.counter("currentScore",delta=1,initial=0).value # Creates at 0 0 >>> db.counter("currentScore").value # Adds 1 1 |
지도 기반 액세스
맵(일명 사전)은 값이 있는 객체 키를 할당합니다. 값은 지도 항목 는 모든 JSON 호환 객체일 수 있습니다. 한 번의 호출로 새 맵과 값 조합을 생성하고 자체 문서에 저장할 수 있습니다.
예를 들어 사용자 프로필 맵에는 사용자 아이디가 있을 수 있습니다. 해당 사용자 프로필에는 고유한 이름의 매핑이 여러 개 있을 수도 있습니다. 그 안에 이름이나 주소와 같은 정보입니다. 각각은 다른 항목과 독립적으로 관리할 수 있습니다.
|
1 2 3 |
>>> db.map_add("tylerM","name","Tyler", create=True) >>> db.map_add("tylerM","country","Canada") |
이 경우 지도의 ID는 기본 KV 가져오기 기능을 통해서도 액세스할 수 있습니다.
|
1 2 3 |
>>> db.get("tylerM").content {'name': 'Tyler', 'country': 'Canada'} |
지도의 존재 여부를 확인하고 항목을 제거하거나 가져올 수 있는 지도별 기능도 있습니다.
목록 기반 액세스
기타 JSON 객체 및 값 는 JSON을 전혀 사용하지 않고도 간단한 목록 구조로 저장할 수 있습니다. 목록 함수는 목록에 항목을 추가하고 색인 번호를 사용하여 다시 꺼낼 수 있습니다.
목록 ID와 새 값을 모두 한 번에 입력합니다. 제거하거나 검색하려면 목록 ID와 항목 색인 번호가 필요합니다. 전체 목록은 KV로 액세스할 수도 있습니다. get 함수입니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
>>> db.list_append("gameList","galaga",create=True) >>> db.list_append("gameList","tetris") >>> db.list_append("gameList","dungeons") >>> db.list_get("gameList",0) 'galaga' >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'tetris'] |
목록에 중복되는 항목 값은 허용되며, 목록에 중복되는 항목 값은 list_prepend 옵션도 사용할 수 있습니다.
집합 기반 액세스
'집합' 데이터 구조 를 사용하면 목록에서 고유 값을 더 쉽게 관리할 수 있습니다. 새 값은 아직 존재하지 않는 경우에만 추가됩니다. 따라서 기존 목록에서 값을 검색하고 비교할 필요성이 줄어드는 대신, 한 번의 호출로 모든 작업이 수행됩니다.
|
1 2 3 4 |
>>> db.set_add("gameList","tetris") # Trying to add tetris twice is ignored >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'horizon'] |
대기열 기반 액세스
큐 데이터 구조 는 특정 순서로 항목을 유지하는 또 다른 유형의 목록입니다. 애플리케이션은 목록 끝에 새 항목을 쉽게 추가할 수 있습니다. 그런 다음 목록의 항목을 목록의 맨 위로 끌어올린 다음 목록에서 제거할 수 있습니다.
예를 들어 어떤 종류의 작업 관리 프로그램에서 요청이 목록에 '대기'되어 애플리케이션이 호출할 때 선입선출(FIFO) 방식으로 작동해야 하는 요청을 처리하고 있을 수 있습니다.
각 값은 모든 JSON 객체가 될 수 있으므로 다른 맵, 목록 등을 포함할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
>>> db.queue_push("appRequests",{"updatescore":10},create=True) >>> db.queue_push("appRequests",{"adduser":"joe"}) >>> db.queue_push("appRequests",{"updatescore":20}) >>> db.get("appRequests").content [{'updatescore': 20}, {'adduser': 'joe'}, {'updatescore': 10}] >>> db.queue_pop("appRequests") # Value is returned as it is removed from list {'updatescore': 10} >>> db.get("appRequests").content # First value is now removed [{'updatescore': 20}, {'adduser': 'joe'}] |
경우에 따라 편의를 위해 집합이나 대기열을 사용할 수도 있지만, 필요에 따라 언제든지 돌아가서 목록이나 KV 함수를 사용하여 코드를 통해 직접 추가/제거하고 관리할 수 있습니다.
한 걸음 더 깊이 - 하위 문서
더 깊은 계층 구조의 JSON 문서에서 특정 하위 개체를 쿼리하고 싶을 때는 어떻게 해야 하나요? 지도 및 목록 함수는 단일 문서 호출에서 하위 항목에서 추출할 수 없습니다. 물론 전체 문서를 요청하여 애플리케이션에서 처리할 수는 있지만 이는 불필요하게 비효율적입니다.
카우치베이스 SDK는 하위 문서 다음용 API 더 깊은 수준의 값에 대한 단일 업데이트/조회 요청을 할 수 있습니다.
예를 들어 사용자 프로필 가 있을 수 있습니다. 주소 에 대한 하위 항목과 매핑 거리, 도시및 국가. 노멀 맵 함수로는 액세스할 수 없지만 대신 하위 문서 API를 사용할 수 있습니다.
몇 가지 강력한 하위 문서 함수가 있지만 여기서는 빠른 검색 예제만 여기서는 lookup_in 함수입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
>>> import couchbase.subdocument as SD >>> db.map_add("tylerM","contact", {"address":{"country":"Canada","city":"Vancouver"}}) >>> country = db.lookup_in("tylerM",[SD.get("contact.address")]) >>> country.content_as[str](0) "{'country': 'Canada', 'city': 'Vancouver'}" >>> country = db.lookup_in("tylerM",[SD.get("contact.address.country")]) >>> country.content_as[str](0) 'Canada' |
데이터 구조와 함께 범위 및 컬렉션 사용
도입 범위 및 컬렉션 in Couchbase 7.0 를 사용하면 문서 관리의 모든 측면을 보다 세밀하게 제어할 수 있습니다. 범위는 버킷에 있는 모든 문서의 하위 집합이고 컬렉션은 범위의 하위 집합입니다.
이러한 주제 전반에 대한 자세한 내용은 블로그를 참조하세요. 컬렉션 소개 - 카우치베이스 서버 6.5의 개발자 프리뷰.
범위와 컬렉션이 이미 존재해야 합니다. 웹 콘솔의 버킷 정의 페이지에서 도구를 사용하여 새 컬렉션을 만드세요.
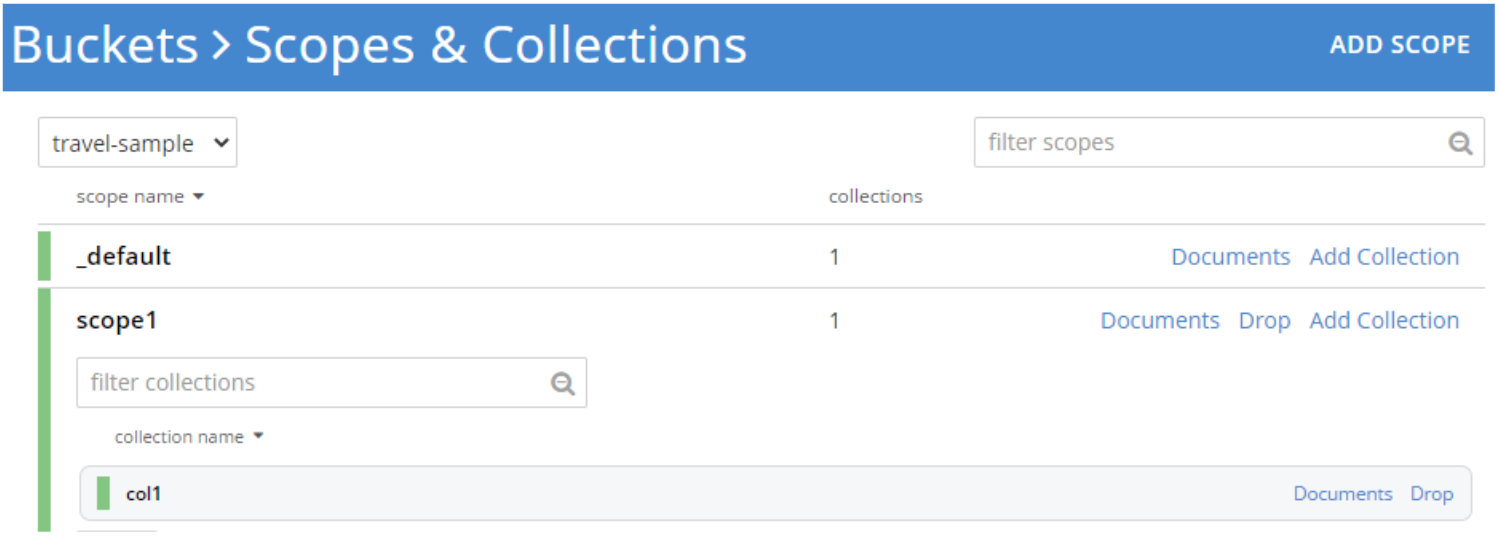
위의 코드 예제에서는 특정 범위 또는 컬렉션 대신 기본 범위를 사용했습니다. 버킷 수준 연결은 사용할 범위/컬렉션을 정의합니다. 이 글의 마지막 부분에 범위와 관련된 전체 코드 예제 링크가 포함되어 있습니다. 다음은 이러한 매개변수를 지정하는 예제입니다:
|
1 |
dbscoped = cluster.bucket('travel-sample').scope('scope1').collection('col1') |
이 코드는 버킷에 대해 "default_collection" 옵션을 선택하는 대신 특정 범위와 컬렉션을 사용합니다. 대신 db 객체를 사용하려면 dbscoped 객체를 대신 사용하여 데이터 작업을 수행할 수 있습니다.
|
1 2 3 |
dbscoped.list_append("newlist",1,create=True) dbscoped.list_append("newlist",2) |
웹 콘솔에서 문서 페이지를 검토하고 컬렉션 이름으로 필터링하여 사용 중인 컬렉션을 확인합니다:
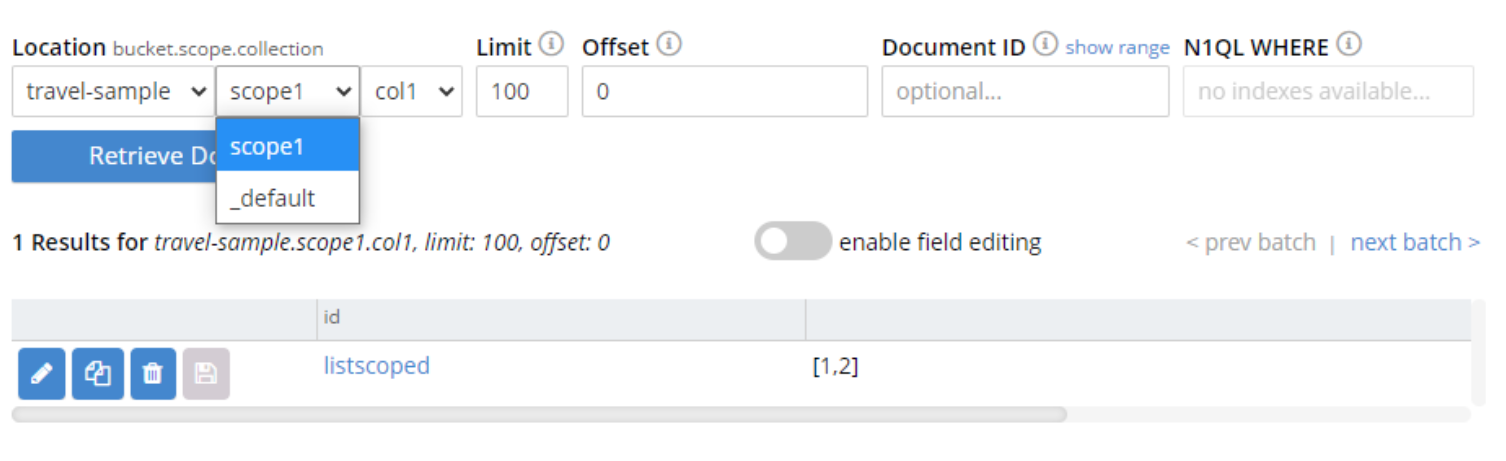
참고: 이 글을 작성할 당시 카운터용 Python API는 범위 사용을 지원하지 않았습니다.
효율적인 SQL 또는 전체 텍스트 검색을 위한 데이터 구조 인덱싱
Couchbase는 키-값(KV) 엔진이나 JSON 데이터 구조를 통해 원시 데이터 구조를 관리하는 것 이상의 기능을 제공합니다. 많은 애플리케이션, 특히 고객 대면 웹 및 모바일 NoSQL 애플리케이션은 다른 애플리케이션과 통합하기 위해 더 정교한 기능이 필요합니다.
Couchbase는 NoSQL 데이터 인덱싱과 SQL 기반 쿼리 서비스를 사용하여 이를 수행합니다. 전체 텍스트 검색.
데이터베이스 인덱싱이란 무엇인가요? 데이터의 일부를 검토하고 문서 내에서 해당 요소를 다시 찾는 방법을 이해하는 것을 의미합니다. 검색은 SQL과 유사한 쿼리 또는 전체 텍스트 검색 요청을 통해 이루어집니다.
다음 포스트에서는 이 두 가지 시나리오를 모두 다루면서 Couchbase 데이터 구조에서 기본 컬렉션의 인덱싱에 초점을 맞출 것입니다.
그동안 인덱싱에 대해 다룬 이 게시물을 참조하세요: NoSQL 데이터베이스 인덱싱 모범 사례.
모든 것을 하나로 모으기
보시다시피 Couchbase를 사용하면 문서, 카운터 및 관련 하위 구성 요소를 매우 간단하게 만들 수 있습니다. 마찬가지로 인덱스를 전략적으로 사용하면 데이터베이스에 액세스할 수 있는 방법이 훨씬 더 다양해집니다.
N1QL 쿼리와 전체 텍스트 검색은 적절하게 매핑된 경우 기본 JSON 배열, 문자열 등을 사용하는 일반적인 방법입니다.
Couchbase는 모든 기능이 포함된 플랫폼이므로 시스템 아키텍처를 크게 간소화할 수 있습니다. 개발자는 많은 작업이나 데이터베이스 관리 없이 바로 시작할 수 있습니다.
- 다운로드 전체 파이썬 코드 예제는 여기에서 확인하세요.
- 데이터 구조 API 문서: Java, .NET, Node.js, 이동, PHP, Python, C, Ruby, Scala
- 하위 문서 운영 문서 (파이썬 SDK)