Tayeb Chlyah는 고성능 대규모 애플리케이션, 마이크로서비스 및 NoSQL 데이터베이스에 대한 탄탄한 경험을 갖춘 Java 수석 아키텍트입니다. 그는 Couchbase용 오픈 소스 Java 라이브러리 두 개를 개발했습니다.
소개
모든 성공적인 개발자는 최첨단 신기술과 새로운 트렌드에 대한 최신 정보를 파악하고, 이를 시도하고, 사용해보고, 프로젝트에 적용할 수 있는지, 어떻게 개선할 수 있는지 살펴봐야 합니다.
하지만 매일 새로운 기술과 프레임워크가 탄생하는 급변하는 세상에서 어떻게 이를 달성할 수 있을까요?
Java 풀스택 개발자라면 운이 좋으세요. JHipster는 새로운 기술을 가장 빠르게 파악할 수 있는 솔루션입니다. 그것은 요만 제너레이터스캐폴딩 시스템으로, 웹 개발에서 최고의 프레임워크 중 하나를 결합한 완벽한 애플리케이션을 생성하는 데 도움이 됩니다: 스프링 부트 백엔드와 앵귤러 또는 리액트 프론트엔드.
물론 다음을 사용할 수 있습니다. 스프링 이니셜zr를 사용하거나 모든 것을 직접 구현할 수도 있지만, 이러한 조합을 성공적으로 구현하는 것은 전혀 쉬운 일이 아닙니다. 각 개념을 연구하는 데 많은 시간을 할애해야 하고, 비용이 많이 들고 오류가 발생하기 쉬운 테스트를 잊지 않고 모든 것을 하나로 묶어야 합니다. 그리고 무엇보다도, 그것은 당신을 낙담시키거나 기껏해야 프레임워크 중 하나에 집중하도록 강요할 수 있습니다.
JHipster는 모범 사례, 방법론 및 전략을 사용하여 완벽하게 테스트된 애플리케이션을 빠르고 쉽게 빌드합니다. 다양한 옵션(아키텍처 - 모놀리스 또는 마이크로서비스; 데이터베이스 - SQL 또는 NoSQL; 보안 - 세션, JWT 또는 OAuth2 인증; 기타 - 웹소켓, 캐시, 도커, 쿠버네티스...)를 통해 최고의 기술을 시도해보고 사용 사례에 가장 적합한 조합을 선택할 수 있습니다.
오늘은 가장 중요한 새로운 아키텍처 개념인 마이크로서비스와 Couchbase를 사용한 NoSQL에 대해 집중적으로 살펴보겠습니다.
왜 카우치베이스인가요?
Couchbase는 NoSQL 문서 지향 데이터베이스입니다. 문서 데이터베이스를 사용하면 스키마가 없는 설계로 데이터를 자유롭고 쉽게 변경할 수 있습니다. 또한 전체 구조를 단일 문서에 저장할 수 있어 불필요한 조인을 피할 수 있으므로 읽기 및 쓰기 작업이 자연스레 빨라집니다.
Couchbase는 빠른 키-값 저장소와 강력한 쿼리 엔진, 그리고 내장된 인덱서를 통해 JSON 문서용 SQL과 유사한 언어인 N1QL로 데이터를 쿼리할 수 있습니다. 마스터가 필요 없는 분산 아키텍처로 확장하기가 매우 쉽습니다. 타사 캐시 없이도 초당 수백만 건의 작업을 수행할 수 있습니다. 또한 Couchbase에는 내장된 전체 텍스트 검색, 분석 엔진, 완벽한 모바일 솔루션이 함께 제공됩니다.
왜 마이크로서비스인가?
마이크로서비스 아키텍처는 애플리케이션을 소규모의 모듈식, 느슨하게 결합된 서비스 집합으로 구축하는 데 초점을 맞춘 소프트웨어 시스템 개발 패턴으로, 지속적인 배포, 테스트 가능성, 확장성 및 향상된 결함 격리를 용이하게 해줍니다. 각 서비스는 서로 다른 언어로 작성될 수 있고 서로 다른 데이터 저장 기술을 사용할 수 있으므로 여러 기능 팀을 중심으로 개발을 구성할 수 있습니다.
하지만 마이크로서비스에는 몇 가지 어려움이 따르는데, 애플리케이션을 서비스로 분해하는 것은 매우 복잡할 수 있으며, 이는 매우 예술적인 작업입니다. 개발자는 또한 분산 시스템의 추가적인 복잡성을 처리해야 합니다.
JHipster는 마이크로서비스의 복잡한 문제를 대부분 처리합니다: 다음을 통한 서비스 검색 및 구성 영사 또는 J힙스터 레지스트리 (넷플릭스 유레카, Spring Cloud 구성 서버및 모니터링 대시보드), 다음을 사용하여 로드 밸런싱을 수행합니다. 넷플릭스 리본내결함성, 내결함성 넷플릭스 히스트릭스를 통한 중앙 집중식 로깅 및 모니터링 제이힙스터 콘솔 (Elasticsearch, Logstash 및 Kibana 개인화된 스택) 등입니다.
양조장 마이크로서비스 만들기
전제 조건:
얀 글로벌 추가 제너레이터-집스터
API 게이트웨이 생성
마이크로서비스 아키텍처에서 다양한 서비스에 액세스하기 위해서는 API 게이트웨이. 마이크로서비스의 입구입니다. HTTP 라우팅(넷플릭스 줄) 및 로드 밸런싱(넷플릭스 리본), 서비스 품질(넷플릭스 히스트릭스), 보안(스프링 보안) 및 API 문서(Swagger) 모든 마이크로서비스에 대해.
터미널 창에서:
|
1 2 3 4 5 |
mkdir couchbase-jhipster-microservices-example cd couchbase-jhipster-microservices-example mkdir gateway cd gateway jhipster |
만들려는 애플리케이션의 유형과 포함할 기능에 대해 묻습니다. 사용 가능한 옵션에 대한 자세한 내용은 다음에서 확인할 수 있습니다. 제이힙스터 웹사이트. 다음 답변을 사용하여 카우치베이스가 지원되는 게이트웨이를 생성하세요.
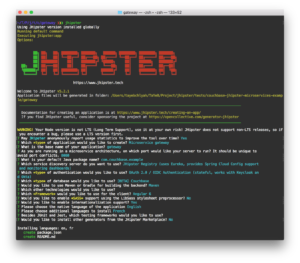
양조장 마이크로서비스 애플리케이션 생성하기
In 카우치베이스-집터-마이크로서비스-예제를 생성하고 양조장 디렉터리를 생성한 다음 jhipster를 실행하여 다음 답변과 함께 Couchbase 데이터베이스로 마이크로서비스를 생성합니다:
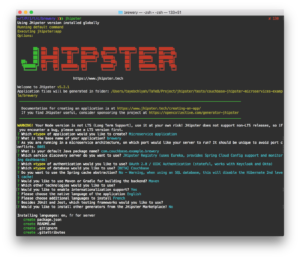
양조장 엔티티 생성
파일 만들기 brewery.jh in 카우치베이스-집터-마이크로서비스-예제 디렉토리에 다음 JDL (제이힙스터 도메인 언어):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
entity Beer { name String required, category String required, description String, style String, brewery String, abv Float, ibu Integer, srm Integer, upc Integer, updated LocalDate } entity Brewery { name String required, description String, address String required maxlength(200), city String, code String, country String, phone String pattern(/[0-9- .]+/), state String, website String, updated LocalDate } |
호출기로 맥주 페이지 매기기
무한 스크롤로 양조장 페이지 매기기
터미널 창에서 다음 명령을 실행합니다:
|
1 2 3 4 5 |
cd brewery jhipster import-jdl ../brewery.jh cd ../gateway jhipster entity brewery jhipster entity beer |
파일을 덮어쓰라는 메시지가 표시되면 항상 a라고 답하세요.
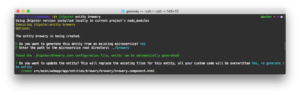
마이크로서비스 아키텍처 실행
아키텍처를 실행하려면 다음을 시작해야 합니다:
- J힙스터 레지스트리
- 키클록오픈 소스 ID 및 액세스 관리 솔루션
- 카우치베이스 서버
- 양조장 마이크로서비스
- 게이트웨이
다행히도, 제이힙스터는 도커-컴포즈 서브 제너레이터 를 사용하면 필요한 모든 서비스를 문제없이 시작할 수 있습니다. 하지만 먼저 애플리케이션을 구축해야 합니다. In 카우치베이스-집터-마이크로서비스-예제:
|
1 2 3 4 5 6 |
cd gateway ./mvnw package -Pprod dockerfile:build -DskipTests cd ../brewery ./mvnw package -Pprod dockerfile:build -DskipTests cd .. mkdir docker-compose && cd docker-compose |
이제 다음을 생성할 수 있습니다. docker-compose.yml 를 사용하여 다음 명령어와 답변을 확인하세요:
|
1 |
jhipster docker-compose |
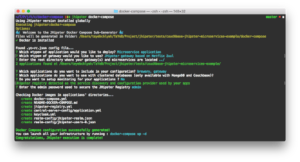
앱이 로컬 키크루크와 함께 작동하도록 하려면 호스트 파일(Windows: C:\윈도우\시스템32\드라이버\등\호스트, Mac/Linux: /etc/hosts)에 다음 줄을 추가합니다:
|
1 |
127.0.0.1 keycloak |
모든 것을 시작하기 전에 충분한 메모리와 CPU로 Docker를 구성했는지 확인한 다음 실행하세요:
|
1 |
docker-compose up |
모든 시작이 완료되면 브라우저를 열어 다음을 수행합니다. 게이트웨이 (https://localhost:8080/)을 클릭한 다음 계정을 클릭하고 로그인합니다.
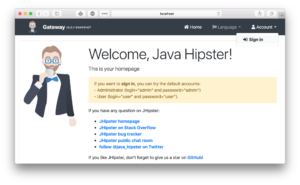
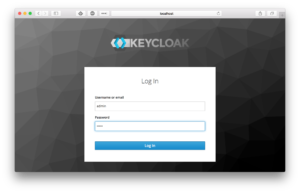
다음으로 리디렉션되어야 합니다. 키클로크를 사용하여 로그인합니다. 관리자 사용자 및 비밀번호를 입력하세요.
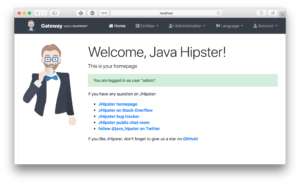
관리 인터페이스를 보고, 언어를 변경하고, 엔티티를 보고 편집할 수 있는 게이트웨이로 돌아옵니다...
제이힙스터-레지스트리
이제 브라우저를 열어 https://localhost:8761/. oauth2 인증의 마법인 키클로크에서 이미 로그인했으므로 자동으로 로그인됩니다.
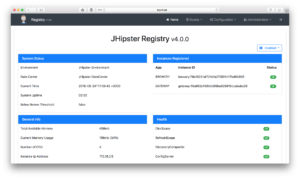
마이크로서비스 애플리케이션의 중추적인 역할을 하는 것 외에도, 마이크로서비스 애플리케이션은 검색 서버 와 함께 유레카 라우팅, 로드 밸런싱 및 확장성을 처리하는 구성 서버와 Spring Cloud 구성 서버 애플리케이션의 런타임 구성을 제공합니다, J힙스터 레지스트리 는 애플리케이션 인스턴스, 상태, 메트릭 및 로그를 시각화할 수 있는 관리 서버이기도 합니다.
어떻게 작동하나요?
데이터베이스에 액세스하기
먼저 brewery-couchbase 인스턴스에 액세스해야 합니다. 이렇게 하려면 도커-컴포즈/도커-컴포즈.yml 를 사용하여 관리 인터페이스 포트를 다음과 같이 게시합니다:
|
1 2 3 4 5 6 7 8 |
brewery-couchbase: build: context: ../brewery/src/main/docker dockerfile: couchbase/Couchbase.Dockerfile environment: - BUCKET=brewery ports: - 8091:8091 |
변경 사항을 적용해 보겠습니다. 도커-컴포즈 디렉터리로 이동합니다:
|
1 |
docker-compose up -d |
모든 것이 완료되면 다음에서 Couchbase 관리 인터페이스를 엽니다. https://localhost:8091/을 클릭한 다음 관리자 사용자 및 비밀번호 를 비밀번호로 입력합니다. 열기 양조장 버킷 문서.
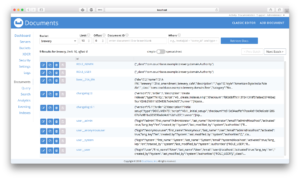
카우치무브
보시다시피 버킷에 이미 일부 문서가 채워져 있습니다: JHipster는 다음을 사용하여 부트스트랩 문서를 채웁니다. 카우치무브에서 광범위하게 영감을 얻은 Couchbase용 Java 데이터 마이그레이션 라이브러리입니다. 플라이웨이구성보다 단순성과 관습을 강력하게 선호하기 때문입니다.
다음에서 변경 로그 파일을 살펴볼 수 있습니다.
|
1 |
brewery/src/main/resources/config/couchmove/changelog directory: |
- V0.1__initial_setup 디렉토리: 사용자 및 권한 문서가 포함되어 있으며, 다음에서 사용합니다. 스프링 보안 를 사용하여 사용자를 인증합니다.
- V0__create_indexes.n1ql: 필요한 인덱스를 생성합니다.
플라이웨이 또는 리퀴베이스 SQL 데이터베이스의 경우, 카우치무브 유지 변경 로그 문서에 저장하여 실행된 변경 로그를 추적합니다.
스프링 부트 및 스프링 데이터 카우치베이스
JHipster는 스프링 부트 2 애플리케이션 및 용도 스프링 데이터 를 사용하여 관계형 및 비관계형 데이터베이스에 액세스합니다. 저희의 경우에는 Spring 데이터 카우치베이스 를 사용하여 Couchbase Server 데이터베이스와의 통합을 제공합니다. 그러나 작동 방식을 개인화함으로써 훨씬 더 발전했습니다:
기본적으로 스프링 데이터 카우치베이스는 다음을 사용합니다. N1qlCouchbaseRepository.java 에만 N1QL을 활용하는 페이징 또는 정렬 findAll 작업을 사용합니다. 다른 모든 작업은 조회수 의 구현에서 볼 수 있듯이 SimpleCouchbaseRepository.java. 뷰 인덱스는 항상 디스크에서 액세스되므로, 뷰 인덱스는 공연자.
JHipster가 이 동작을 어떻게 개선하는지 살펴봅시다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
@Configuration @Profile("!" + JHipsterConstants.SPRING_PROFILE_CLOUD) @EnableCouchbaseRepositories(repositoryBaseClass = CustomN1qlCouchbaseRepository.class, basePackages = "com.couchbase.example.brewery.repository") @Import(value = CouchbaseAutoConfiguration.class) @EnableCouchbaseAuditing(auditorAwareRef = "springSecurityAuditorAware") public class DatabaseConfiguration { ... @Bean public Couchmove couchmove(Bucket couchbaseBucket) { log.debug("Configuring Couchmove"); Couchmove couchMove = new Couchmove(couchbaseBucket, "config/couchmove/changelog"); couchMove.migrate(); return couchMove; } ... } |
데이터베이스 구성 클래스는 Couchmove 마이그레이션을 구성하고 시작하며, 사용자 지정 기본 클래스를 사용하여 Couchbase 리포지토리도 활성화합니다: CustomN1qlCouchbase저장소
|
1 2 3 4 5 6 7 8 |
public class CustomN1qlCouchbaseRepository<T, ID extends Serializable> extends N1qlCouchbaseRepository<T, ID> { ... @Override public <S extends T> S save(S entity) { return super.save(populateIdIfNecessary(entity)); } ... } |
이 클래스는 저장하기 전에 문서 ID를 자동 생성하도록 기본 리포지토리를 확장하고, 모든 작업에 N1QL을 사용할 수 있도록 다음과 같이 구현합니다. 사용자 지정N1ql저장소 인터페이스:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
@NoRepositoryBean public interface N1qlCouchbaseRepository<T, ID extends Serializable> extends CouchbasePagingAndSortingRepository<T, ID> { @Query("#{#n1ql.selectEntity} WHERE #{#n1ql.filter}") List<T> findAll(); @Query("SELECT count(*) FROM #{#n1ql.bucket} WHERE #{#n1ql.filter}") long count(); @Query("DELETE FROM #{#n1ql.bucket} WHERE #{#n1ql.filter} returning #{#n1ql.fields}") T removeAll(); default void deleteAll() { removeAll(); } } |
ID는 다음을 사용하여 자동으로 생성됩니다. 생성된 가치 접두사를 사용하여 주석을 추가합니다. IdPrefix 주석은 기본적으로 클래스 이름이며, 이 주석은 __ 구분 기호.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
@Document public class Brewery implements Serializable { private static final long serialVersionUID = 1L; public static final String PREFIX = "brewery"; @SuppressWarnings("unused") @IdPrefix private String prefix = PREFIX; @Id @GeneratedValue(strategy = UNIQUE, delimiter = ID_DELIMITER) private String id; ... } |
테스트
앞서 JHipster에서 생성된 애플리케이션은 단위 및 통합 테스트하지만 통합의 경우 어떻게 작동할까요?
Couchbase의 경우 다음을 사용합니다. 카우치베이스 테스트컨테이너를 확장하는 모듈인 테스트 컨테이너는 JUnit 테스트 기간 동안 모든 Docker 컨테이너를 쉽게 시작할 수 있는 Java 라이브러리로, Couchbase Server의 인스턴스를 자동으로 시작하고 필요한 서비스, 사용자, 버킷 및 인덱스로 구성할 수 있도록 해줍니다.
테스트를 실행하려면 터미널 창에서 다음 명령을 실행합니다:
|
1 |
./mvnw clean test |
일부 데이터 채우기
일부 데이터를 채우기 위해 다음을 활용합니다. 카우치베이스 샘플 버킷. Open 설정 탭을 클릭합니다, 샘플 버킷을 클릭한 다음 맥주 샘플을 선택하고 샘플 데이터 로드.
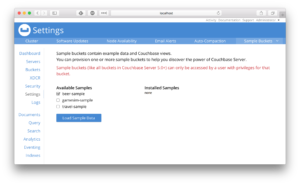
다음에서 데이터 모양을 지정해야 합니다. Spring 데이터 카우치베이스 직렬화 형식으로 변경합니다. 이렇게 하려면 쿼리 탭을 열고 다음 쿼리를 실행합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
INSERT INTO brewery (KEY k, VALUE v) SELECT type || "__" || meta().id as k, { "name": name, "category": category, "description": description, "style": style, "brewery": brewery_id, "abv": abv, "ibu": ibu, "srm": srm, "upc": upc, "updated": STR_TO_MILLIS(updated), "_class" : "com.couchbase.example.brewery.domain.Beer" } as v FROM `beer-sample` WHERE type = 'beer'; INSERT INTO brewery (KEY k, VALUE v) SELECT type || "__" || meta().id as k, { "name": name, "description": description, "address": address[0], "country": country, "website": website, "code": code, "city": city, "phone": phone, "state": state, "updated": STR_TO_MILLIS(updated), "_class" : "com.couchbase.example.brewery.domain.Brewery" } as v FROM `beer-sample` WHERE type = 'brewery'; |
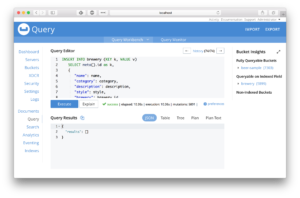
다음은 삽입된 맥주 문서의 예입니다:
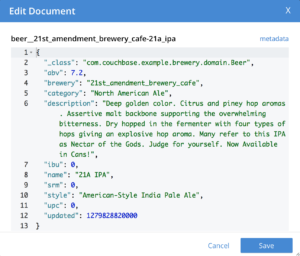
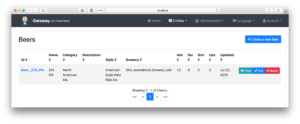
이제 JHipster가 새로 삽입된 문서를 어떻게 처리하는지 살펴봅시다. 다음으로 이동합니다. 게이트웨이, 엔티티을 클릭한 다음 양조장. JHipster는 먼저 20개의 양조장을 로드하고 아래로 스크롤하면 더 많은 양조장을 로드합니다! 다음에 대한 페이지 탐색을 제안합니다. 맥주 엔티티를 생성할 때 이 동작을 선택하기 때문입니다. brewery.jh JDL.
|
1 2 |
paginate Beer with pager paginate Brewery with infinite-scroll |
소스 코드
생성된 애플리케이션의 소스 코드는 다음 링크에서 확인할 수 있습니다. tchlyah/couchbase-jhipster-microservices-예제.
다음 단계는 무엇인가요?
JHipster는 Elasticsearch의 도움으로 다음을 추가하는 옵션을 제안합니다. 검색 기능 를 데이터베이스에 추가할 수 있습니다. 하지만 Couchbase는 즉시 사용 가능한 전체 텍스트 검색 자연어 쿼리를 위한 광범위한 기능을 제공하는 기능입니다. JHipster에 이러한 지원을 구현해보는 건 어떨까요? 도움을 주실 수 있다면 주저하지 마세요. 기여!
궁금한 점이 있으면 다음 주소로 트윗해 주세요. @tchlyah 를 클릭하거나 아래에 댓글을 남겨 주세요.