새로운 기술을 사용하기 시작하려는 사람들에게 가장 큰 장벽 중 하나는 보통 학습 곡선입니다. 종종 새로운 프로젝트를 시작할 때 초반의 마찰을 피하기 위해 이미 알고 있는 것을 사용하게 되는 경우가 많습니다.
저는 대부분의 경력을 Java 개발자로 일해 왔으며 지난 몇 년 동안 저는 JPA + 스프링 부팅 + 롬복 + 스프링 데이터 조합을 사용했지만 여전히 저를 괴롭히는 한 가지는 관계 매핑이었습니다.
JPA는 데이터베이스에서 불필요한 데이터를 로드하는 것으로 유명하며, 시간이 지남에 따라 일부 엔터티를 다시 방문하여 몇 가지 관계를 EAGER에서 LAZY로 변경해야 합니다. 불필요한 조인을 많이 피할 수 있으므로 성능이 크게 향상될 수 있지만 공짜로 제공되는 것은 아닙니다. 새로운 지연 객체가 필요할 때마다 이를 로드하려면 많은 리팩터링을 수행해야 합니다.
이 일반적인 패턴은 항상 저를 괴롭혔는데, 스프링 데이터와 카우치베이스가 연결될 수 있다는 사실을 알게 되었을 때 정말 기뻤습니다(전체 문서 보기). 관계형 데이터베이스에서 하는 것처럼 프로그래밍할 수 있으면서도 Couchbase의 모든 속도와 N1QL의 강력한 기능을 활용할 수 있는 두 세계의 장점을 모두 누릴 수 있습니다. 간단한 프로젝트를 설정하는 방법을 살펴보겠습니다.
Spring 데이터, Spring Boot 및 Couchbase 설정하기
전제 조건:
- 이미 Couchbase가 설치되어 있다고 가정하고, 설치되어 있지 않다면 다음과 같이 하세요. 여기에서 다운로드
- 저도 롬복을 사용하고 있으므로 IDE에 롬복의 플러그인을 설치해야 할 수도 있습니다: E클립 그리고 IntelliJ 아이디어
먼저, 내 프로젝트를 복제할 수 있습니다:
|
1 |
git clone https://github.com/deniswsrosa/couchbase-spring-data-sample.git |
로 이동하거나 스프링 부팅 이니셜zr 를 클릭하고 종속성으로 Couchbase와 Lombok을 추가합니다:
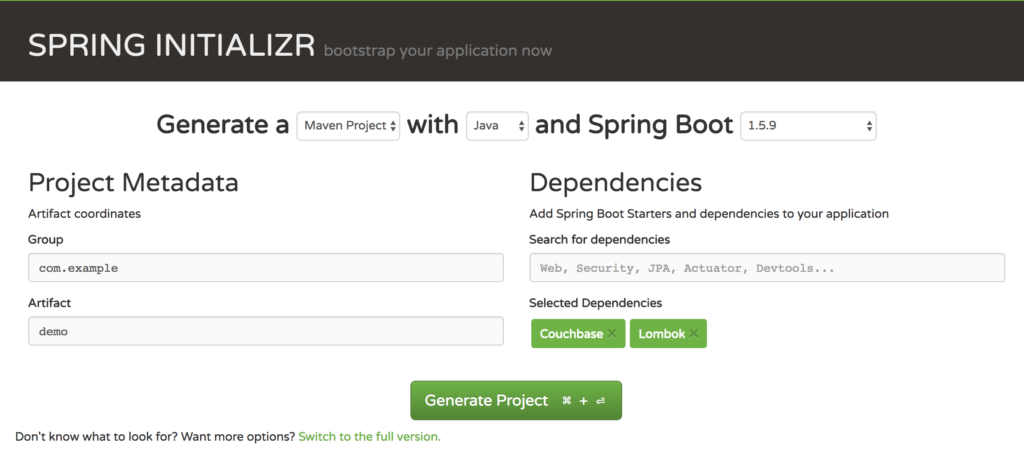
참고: 롬복은 필수 종속 요소는 아니지만 코드 기반을 크게 줄이는 데 도움이 됩니다.
이제 버킷 구성을 정의해 보겠습니다. application.properties file:
|
1 2 3 4 |
spring.couchbase.bootstrap-hosts=localhost spring.couchbase.bucket.name=test spring.couchbase.bucket.password=couchbase spring.data.couchbase.auto-index=true |
여기까지입니다! 이미 다음을 사용하여 프로젝트를 시작할 수 있습니다:
|
1 |
mvn spring-boot:run |
엔티티 매핑
지금까지 우리 프로젝트는 아무것도 하지 않습니다. 첫 번째 엔티티를 생성하고 매핑해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
@Document @Data @AllArgsConstructor @NoArgsConstructor @EqualsAndHashCode public class Building { @NotNull @Id private String id; @NotNull @Field private String name; @NotNull @Field private String companyId; @Field private List<Area> areas = new ArrayList<>(); @Field private List<String> phoneNumbers = new ArrayList<>(); } |
-
- @Document: 엔티티를 정의하는 카우치베이스의 어노테이션은 다음과 유사합니다. 엔티티 를 추가합니다. 카우치베이스는 자동으로 다음과 같은 프로퍼티를 추가합니다. _class 를 문서에 추가하여 문서 유형으로 사용하세요.
- @Data: 롬복의 어노테이션, 게터 및 세터 자동 생성
- @AllArgsConstructor: 롬복의 어노테이션, 클래스의 모든 필드를 사용하여 생성자 자동 생성, 이 생성자 테스트에 사용되었습니다..
- 노아르그 생성자: 롬복의 어노테이션, 인수가 없는 생성자 자동 생성(스프링 데이터에 필요)
- @EqualsAndHashCode: 롬복의 어노테이션, 자동 생성 등호 및 해시코드 메서드도 테스트에 사용되었습니다.
- @NotNull: 예! Couchbase에서 javax.validation을 사용할 수 있습니다.
- @Id: 문서의 핵심
- @Field: Couchbase의 주석은 다음과 유사합니다. 칼럼
Couchbase에서 엔티티 매핑은 매우 간단하고 직관적이며, 여기서 가장 큰 차이점은 필드 엔티티는 3가지 다른 방식으로 사용됩니다:
- 단순 속성: 다음과 같은 경우 id, 이름 그리고 companyId, 의 필드 와 매우 유사하게 작동합니다. 칼럼 를 입력합니다. 문서에 간단한 속성이 생성됩니다:
|
1 2 3 4 5 |
{ "id": "building::1", "name": "Couchbase's Building", "companyId": "company::1" } |
- 배열: 전화 번호의 경우 문서 내부에 배열이 생성됩니다:
|
1 2 3 |
{ "phoneNumbers": ["phoneNumber1", "phoneNumber2"] } |
- 엔티티: 마지막으로 영역의 경우입니다, 필드 처럼 작동합니다. @ManyToOne 관계와 가장 큰 차이점은 Area 엔티티에 아무것도 매핑할 필요가 없다는 점입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@EqualsAndHashCode @AllArgsConstructor @NoArgsConstructor @Data public class Area { private String id; private String name; private List<Area> areas = new ArrayList<>(); } |
리포지토리
리포지토리는 표준 Spring 데이터 리포지토리와 매우 비슷해 보이지만 몇 가지 추가 주석이 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
@N1qlPrimaryIndexed @ViewIndexed(designDoc = "building") public interface BuildingRepository extends CouchbasePagingAndSortingRepository<Building, String> { List<Building> findByCompanyId(String companyId); Page<Building> findByCompanyIdAndNameLikeOrderByName(String companyId, String name, Pageable pageable); @Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and companyId = $1 and $2 within #{#n1ql.bucket}") Building findByCompanyAndAreaId(String companyId, String areaId); @Query("#{#n1ql.selectEntity} where #{#n1ql.filter} AND ANY phone IN phoneNumbers SATISFIES phone = $1 END") List<Building> findByPhoneNumber(String telephoneNumber); @Query("SELECT COUNT(*) AS count FROM #{#n1ql.bucket} WHERE #{#n1ql.filter} and companyId = $1") Long countBuildings(String companyId); } |
- @N1qlPrimaryIndexed: 이 주석 는 현재 리포지토리와 연결된 버킷에 N1QL 기본 인덱스가 있는지 확인합니다.
- @ViewIndexed: 이 주석 를 사용하면 디자인 문서의 이름과 보기 이름은 물론 사용자 지정 맵과 축소 기능을 정의할 수 있습니다.
위의 리포지토리에서 우리는 카우치베이스 페이징 및 정렬 저장소를 추가하여 쿼리의 페이지 매김을 지정할 수 있습니다. 페이지 가능 매개변수를 메서드 정의의 끝에 추가합니다.
기본적으로 리포지토리이기 때문에 모든 Spring 데이터 키워드 같은 FindBy, 사이, IsGreaterThan, 좋아요, 존재등을 지원합니다. 따라서 사전 지식이 거의 없어도 Couchbase 사용을 시작하고도 생산성을 높일 수 있습니다.
이미 알고 계시겠지만, 완전한 N1QL 쿼리와 비슷하지만 구문 설탕이 몇 가지 있습니다:
- #(#n1ql.bucket): 이 구문을 사용하면 쿼리에서 버킷 이름을 하드코딩하지 않아도 됩니다.
- #{#n1ql.selectEntity}: 구문-설탕에 SELECT * FROM #(#n1ql.bucket):
- #{#n1ql.filter}: 구문-설탕을 사용하여 문서를 유형별로 필터링하는 것은 엄밀히 말하면 class = 'myPackage.MyClassName' (_class 는 스프링 데이터에서 카우치베이스로 작업할 때 문서에 자동으로 추가되어 유형을 정의하는 어트리뷰트입니다.)
- #{#n1ql.fields} 는 엔티티를 재구성하는 데 필요한 필드 목록(예: SELECT 절의 경우)으로 대체됩니다.
- #{#n1ql.delete} 는 다음에서 삭제 문으로 대체됩니다.
- #{#n1ql.반환} 는 엔티티를 재구성하는 데 필요한 반환 절로 대체됩니다.
N1QL의 멋진 기능 중 일부를 보여드리기 위해 리포지토리의 두 가지 방법을 조금 더 자세히 살펴보겠습니다: 전화 번호로 찾기 그리고 findByCompanyAndAreaId:
전화 번호로 찾기
|
1 2 |
@Query("#{#n1ql.selectEntity} where #{#n1ql.filter} AND ANY phone IN phoneNumbers SATISFIES phone = $1 END") List<Building> findByPhoneNumber(String telephoneNumber); |
위 사례에서는 단순히 전화번호로 건물을 검색하고 있습니다. 관계형 세계에서는 거의 동일한 작업을 수행하려면 일반적으로 2개의 테이블이 필요합니다. Couchbase를 사용하면 모든 것을 단일 문서에 저장할 수 있으므로 "건물"을 로드하는 속도가 다른 RDBMS를 사용할 때보다 훨씬 빨라집니다.
또한 다음과 같은 방법으로 쿼리 성능을 더욱 빠르게 향상시킬 수 있습니다. 전화 번호 속성에 인덱스 추가하기.
회사별 및 지역 ID 찾기
|
1 2 |
@Query("#{#n1ql.selectEntity} where #{#n1ql.filter} and companyId = $1 and $2 within #{#n1ql.bucket}") Building findByCompanyAndAreaId(String companyId, String areaId); |
위의 쿼리에서 우리는 기본적으로 임의의 하위 노드(Area)를 제공하는 루트 노드(Building)를 찾으려고 합니다. Area에는 다른 영역의 목록도 포함될 수 있으므로 데이터는 트리로 구조화됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@EqualsAndHashCode @AllArgsConstructor @NoArgsConstructor @Data public class Area { private String id; private String name; private List<Area> areas = new ArrayList<>(); } |
이러한 유형의 쿼리는 관계형 데이터베이스로 작업할 때 가장 비용이 많이 들고 복잡한 작업 중 하나이며, 대부분의 경우 루트 노드를 찾거나 손으로 또는 유니온 그리고 연결된 사람.
여기에서 다음과 같은 마법의 키워드를 사용하여 이 문제를 해결할 수 있습니다. WITHIN.
서비스
기본적으로 평소와 같이 서비스에 리포지토리를 삽입하고 사용하지만, 다음 방법을 사용하여 Couchbase의 특정 리포지토리 기능에 추가로 액세스할 수 있습니다. getCouchbaseOperations()
모든 것이 작동 중
서비스 사용은 사용자가 기대하는 대로 이루어집니다:
|
1 |
buildingService.findById("building::1") |
|
1 2 3 4 |
Building bulding = new Building("bulding::1", "Couchbase Building", "company::1", new ArrayList<>(), new ArrayList<>()); buildingService.save(building); |
|
1 |
buildingService.findByCompanyIdAndNameLike("company::1", "Cou%", 0); |
통합 테스트 클래스를 확인하세요. 빌딩 서비스 통합 테스트 를 클릭하세요.
궁금한 점이 있으면 다음 주소로 트윗해 주세요. @deniswsrosa 에 질문하거나 포럼
훌륭한 블로그입니다! 저는 스프링과 스프링 부팅을 처음 사용합니다. 그리고 CouchBase 를 설정하고 있습니다. 내 컴퓨터에서 로컬로 카우치베이스를 실행하고 있지만 버킷에 대한 암호를 제공하는 조항을 찾지 못했습니다. 따라서 내 애플리케이션을 실행할 때 InvalidPasswordException이 발생합니다: 버킷의 비밀번호가 일치하지 않습니다.
이 문제를 해결하는 방법을 알려주시겠어요?
안녕하세요 Kn,
가장 쉬운 방법은 버킷과 이름이 같은 사용자를 만든 다음 다음 튜토리얼을 따르는 것입니다.
https://www.couchbase.com/couchbase-spring-boot-spring-data/
여러 사용자가 동일한 버킷에 액세스하도록 하려면 AbstractCouchbaseConfiguration 클래스를 구현해야 합니다.
https://stackoverflow.com/questions/53177777/couchbase-6-0-springboot-invalidpasswordexception
나는 카우치베이스와 스프링 데이터, 스프링 부팅 구현에 대해 꽤 새로운 것입니다. 전체 문서를 읽지 않고 하위 문서를 업데이트, 삽입 및 제거하기 위해 문서 하위 문서 API를 사용하고 있습니다. 하위 문서의 경로를 코딩하고 하위 문서에서 직접 변경 작업을 수행 할 수 있습니다. 문서 하위 문서 API의 장점 중 하나는 전체 문서를 잠그지 않고 하위 문서에서 작업할 수 있다는 것입니다(제 사용 사례에서).
스프링 데이터와 스프링 부트를 사용하여 동일한 결과를 얻으려면 어떻게 해야 하나요? 스프링 데이터는 N1QL 쿼리와 함께 작동하고 문서 하위 문서 API는 Json과 함께 작동하는 POJO에서 큰 차이가 있습니다.
하위 문서 API 문서를 참조하세요: https://docs.couchbase.com/java-sdk/2.7/subdocument-operations.html
안녕하세요, 무라릭,
하위 문서는 키로 문서를 가져오기 때문에 일반적으로 더 빠릅니다. 하지만 Spring 데이터는 훨씬 더 생산적입니다.
스프링 데이터를 사용하면서도 하위 문서 작업을 수행할 수 있습니다. yourRepository.getCouchbaseOperations().getCouchbaseBucket()을 호출하면 현재 사용 중인 Bucket 객체에 액세스할 수 있습니다.
SSL을 통해 연결하고 스프링 데이터 카우치베이스에서 필드 암호화를 사용할 수 있나요?
안녕하세요 데니스, 저는 오픈 시스템 기술을 매우 처음 접하고 있으며 프로젝트가 어떻게 실행되는지 이해하려고 노력하고 있습니다. 카우치베이스를 설치하고 하나의 문서를 만들었고 콘솔에서 실행중인 서버를 볼 수 있습니다.
그러나 Java가 couchbase와 어떻게 통합되는지 확인하고 싶어서 프로젝트를 가져와서 mvn 새로 설치를 수행했지만 다음과 같은 인증 오류가 발생했습니다:
2019-05-21 20:14:31.776 WARN 9672 - [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 인증 실패.
2019-05-21 20:14:31.777 WARN 9672 - [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : 다시 연결하는 동안 오류가 발생했습니다:
-05-21 20:14:31.778 WARN 9672 - [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 엔드포인트에 연결할 수 없습니다. 4096밀리초 지연 후 재시도합니다:
2019-05-21 20:14:35.922 WARN 9672 - [ cb-io-19-1] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 인증 실패.
2019-05-21 20:14:36.020 WARN 9672 - [ cb-io-19-2] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 인증 실패.
2019-05-21 20:14:36.021 WARN 9672 - [ cb-io-19-2] c.c.client.core.endpoint.Endpoint : 다시 연결하는 동안 오류가 발생했습니다:
2019-05-21 20:14:36.029 WARN 9672 - [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 인증 실패.
2019-05-21 20:14:36.030 WARN 9672 - [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : 다시 연결하는 동안 오류가 발생했습니다:
2019-05-21 20:14:36.362 WARN 9672 - [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 인증 실패.
2019-05-21 20:14:36.363 WARN 9672 - [ cb-io-19-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 엔드포인트에 연결할 수 없습니다. 32밀리초 지연 후 재시도합니다:
제가 놓친 단계가 있다면 조언해 주시겠습니까? 카우치베이스 로컬 호스트 서버를 가져 오는 것과 관련하여 몇 가지 설정을해야합니까, 아니면 카우치베이스 종속성이 누락되었는지 / 전혀 모르겠으니 조언 해주세요.
안녕하세요 데니스, 저는 오픈 시스템 기술을 매우 처음 접하고 있으며 프로젝트가 어떻게 실행되는지 이해하려고 노력하고 있습니다. 카우치베이스를 설치하고 하나의 문서를 만들었고 콘솔에서 실행중인 서버를 볼 수 있습니다.
그러나 Java가 couchbase와 어떻게 통합되는지 확인하고 싶어서 프로젝트를 가져와서 mvn 새로 설치를 수행했지만 다음과 같은 인증 오류가 발생했습니다:
2019-05-21 20:14:31.776 WARN 9672 - [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : [null][KeyValueEndpoint]: 인증 실패.
2019-05-21 20:14:31.777 WARN 9672 - [ cb-io-17-3] c.c.client.core.endpoint.Endpoint : 다시 연결하는 동안 오류가 발생했습니다:
제가 놓친 단계가 있다면 조언해 주시겠습니까? 카우치베이스 로컬 호스트 서버를 가져 오는 것과 관련하여 몇 가지 설정을해야합니까, 아니면 카우치베이스 종속성이 누락되었는지 / 전혀 모르겠으니 조언 해주세요.
절대, 신경 쓰지 마세요, 해결책을 찾았습니다 :) 하지만 앞으로 더 많은 의구심이 생길 것입니다 ...
StackOverflow에 질문을 올리면 제가 답변해 드릴 수 있습니다.
안녕하세요 로사,
저는 Spring 데이터로 Couchbase를 처음 사용하지만 R&D를 기반으로 CRUD 작업을 쉽게 수행 할 수 있습니다. 여전히 나는 "key":{"empty": "false"}가 목록 값을 저장하는 동안 발생합니다.
또한 위에서 다음과 같이 설명했습니다.
private List 전화 번호 = 새로운 ArrayList();
그리고,
배열을 사용할 수 있습니다: 전화 번호의 경우 문서 내부에 배열이 생성됩니다:
다음과 같이 : -
{
"전화 번호": ["phoneNumber1", "phoneNumber2"]
}
하지만 항상 다음과 같이 저장됩니다 :- "key":{"empty": "false"}.
> 하지만 항상 다음과 같이 저장됩니다 :- "key":{"empty": "false"}.
이 문제는 스프링 데이터 카우치베이스 4.0.2에서 수정되었습니다.
안부